视觉深度学习的三维重建方法综述
来源:优秀文章 发布时间:2023-04-10 点击:
李明阳,陈 伟+,王珊珊,黎 捷,田子建,张 帆
1.中国矿业大学 计算机科学与技术学院,江苏 徐州221116
2.中国矿业大学 矿山数字化教育部工程研究中心,江苏 徐州221116
3.中国矿业大学(北京)机电与信息工程学院,北京100083
三维数字内容是虚拟仿真、混合现实等的基本构成要素[1]。三维重建作为计算机图形学的基本问题,在近些年逐渐结合计算机视觉深度学习技术后又得到长足的发展。在基于视觉进行三维重建前,传统三维重建利用传统测量工具和方法对待测物体逐一进行测量,操作困难、繁琐。
得益于光电技术的发展,主动式感知技术进行三维重建的方法取得一些突破[2]。在采集三维图像结构过程中和场景发生互动,比较常用的两个方法是结构光和激光扫描。结构光指设备会主动发出一种提前编辑好的固定的光波,这个光波会因为一些物体表面深度的不同而发生扭曲,通过分析这些光的形变就可以得到物体的表面几何结构。如Kinect仪器和iPhone 手机用的就是结构光的技术。激光扫描是大家比较熟悉的技术,在自动驾驶中应用激光扫描方式比较多。它的原理就是发生一束和多束激光,然后通过计算激光发射和回收的时间差,可以知道与反射点的距离。
由于三维激光扫描仪的价格十分昂贵,Garcia 利用结构光进行三维重建[3],但是得到准确的深度图依旧是十分困难和复杂的一项工作。相比起来,通过视觉方法重建获取目标三维数据,再根据实际需要解算、提取所需信息会更加便捷与可靠[4]。
典型的视觉三维重建方法,例如基于单幅图像三维重建,仅靠单张数码影像提取目标的颜色、形状、共面性等二维、三维几何信息[5]。双目立体视觉技术进行三维重建是通过模仿人眼视觉系统对物体进行三维感知,基本原理是从两个或多个视点观察同一景物,以获取在不同视角下的感知图像,通过三角测量原理计算图像像素间的位置偏差来获取景物的三维信息[6]。相比于主动式感知技术,双目立体视觉技术具有设备简单、成本低和效率高的优势,因此双目立体匹配技术在数十年里是计算机视觉领域中的热点问题,并且获得一系列的进展[1]。
传统的三维重建方法虽然已经广泛地应用于生产生活中,然而传统机器学习方法由于学习方式、学习设备等条件的制约,存在如下难以避免的缺点:传统的三维重建方法需要较多的人力资源进行监督;
同时面对多个形状修改与生成任务时,无法精确地识别对象形状的几何与拓扑结构差异;
出现精细的几何细节时,由于无法实现全局性操作,三维重建的准确性不够高;
由于无法输出各个部件的关系,对3D形状的结构编号进行建模的难度较高。随着深度学习方法的迅速发展,有研究者将其与传统三维重建相结合,取得较好的结果。深度学习在数据处理、几何推断、结构推理、语义理解等多个层次为三维重建带来深刻变革和全新挑战[1]。Eigen 团队[7]是使用深度学习进行深度图估计的开山团队,本文总结自2014 年David 第一次使用卷积神经网络(convolutional neural networks,CNN)进行三维重建开始,深度学习领域基于视觉的三维物体重建最新方法及未来趋势,探讨深度学习是如何实现更加智能、灵活和通用的三维内容生成,实现从三维表征重建到高层几何结构推理的完整建模,如图1 所示。
在三维重建的完整过程中,生成的三维模型采取的数据结构是基于深度学习的三维重建至关重要的基础[8]。三维数据结构的表达方式主要分为:
(1)将三维几何体表示为多视点投影的二维图像;
(2)直接在原始的三维数据上进行描述表示,例如体素、点云、曲面网格、隐式曲面等,如图2 所示。
Su 等人[9]最早设计多视图卷积神经网络(multiview CNN,MVCNN)模型提取二维投影图像的卷积特征,通过多视点融合来实现三维表征学习,并且将物体的三维数据从不同“视角”所得到的二维渲染图作为原始的训练数据。该团队证明用经典、成熟的二维图像卷积网络训练出的模型,对三维物体的识别、分类效果好于用三维数据直接训练出的模型。随后Qi 等人在MVCNN 的基础上,通过增加更多的训练样本和设计新的多分辨率的组件,改进MVCNN的结果[10]。
Maturana 等人最早提出的VoxNet 网络,利用三维卷积神经网络来对被目标物体占用的网格体素进行处理,可以每秒对几百个实例进行标注[11]。Wu 等人[12]直接在三维体素上设计3D ShapeNets 模型进行三维卷积操作,如图3 所示,从原始CAD 数据中学习复杂的3D 形状在不同对象类别和任意姿势中的分布,并自动发现分层组成部分表示。
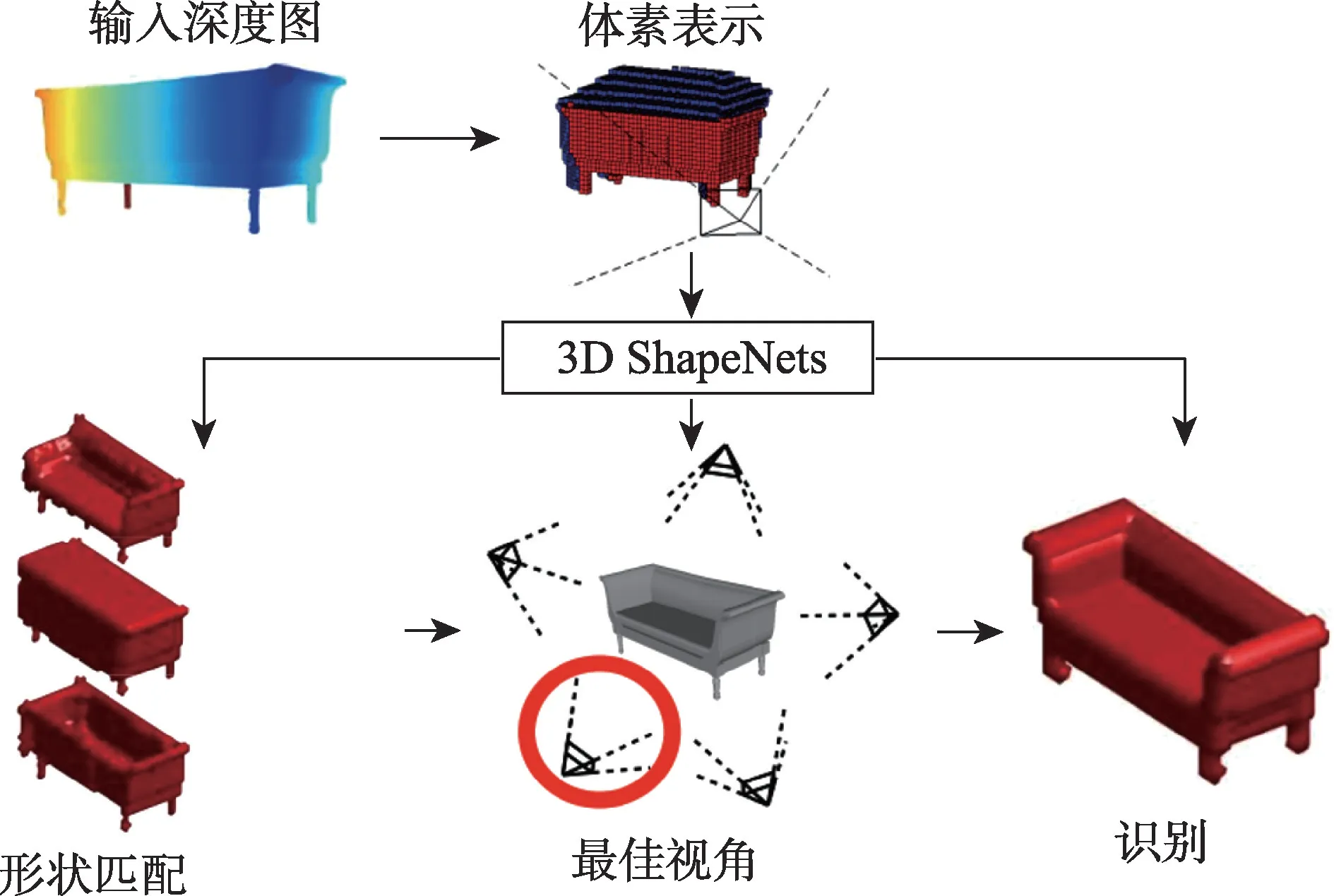
图3 3D ShapeNets示意图Fig.3 3D ShapeNets diagram
体素输出允许使用规则体素网格对三维形状进行参数化。因此,在图像分析中使用的二维卷积可以很容易地扩展到三维。尽管可以得到显著优于传统三维重建方法的结果,但是使用体素作为存储结构,卷积的计算和存储开销非常大。为应对体素存储方法导致的这些问题,Qi 等人[10]在Wu 等人研究的基础上,提升模型的分类精度,避免维数灾难[13]。Li等人[14]将三维形状表示成体素场来解决三维体素表示的稀疏性问题,并提出用一个场探索滤波器取代CNN 中的卷积层来学习特征。微软亚洲研究院的Wang 等人[15]设计O-CNN 以八叉树的数据结构自适应体卷积技术,将对平面的计算限定在平面的附近。该方法有效地将八叉树信息和CNN 特征存储到图形存储器中,大幅度节省体素计算的开销。
Qi 等人设计一种直接对三维点云进行卷积操作的新型神经网络PointNet[16],如图4 所示,其分类网络以N个点为输入,进行输入变换和特征变换,通过最大池化来聚合点特征,输出是K个分类分数。分类网络保证了输入点的置换不变性,获得了比其他模型更好的结果。

图4 PointNet结构:多层感知机Fig.4 PointNet structure:multilayer perceptron
在计算机图形学领域中,三角形网格是最通用的三维几何表示[1]。Sinha 等人[17]将三维形状参数化到球形表面,进而将球形表面投影到八面体后展开成二维平面,最后采用卷积神经网络从二维平面中学习特征表示。Rakotosaona 等人[18]提出从点云中重建三角形网格。现有的基于学习的网格重建方法大多单独生成三角形,因此很难创建流形网格。首先估计每个点周围的局部测地线邻域,利用2D Delaunay三角剖分的属性从流形表面元素构建网格。该方法与当前重建具有任意拓扑结构的网格的方法相比可以实现更好的整体流形。
深度隐式曲面函数(deep implicit functions surface,DIF)是三维形状表示的一种方法,因结构紧凑,表示能力强,在三维视觉领域越来越受欢迎。但与其他模型不同,如何在DIF 表示的形状之间推理出密集的对应关系或其他语义关系仍然是一个难题。Mescheder 团队[19]提出基于深度学习的三维重建新方法Occupancy Networks,将三维表面隐式表示为深度神经网络分类器的连续决策边界,且对于从单个图像、嘈杂的点云和粗糙的离散体素网格进行三维重建的挑战性任务都取得优秀的成果。Zheng 等人[20]提出全新的3D 形状表示法DIT(deep implicit templates),如图5 所示。DIF 支持深层隐式表征中的显式对应推理,同时也更具可解释性。
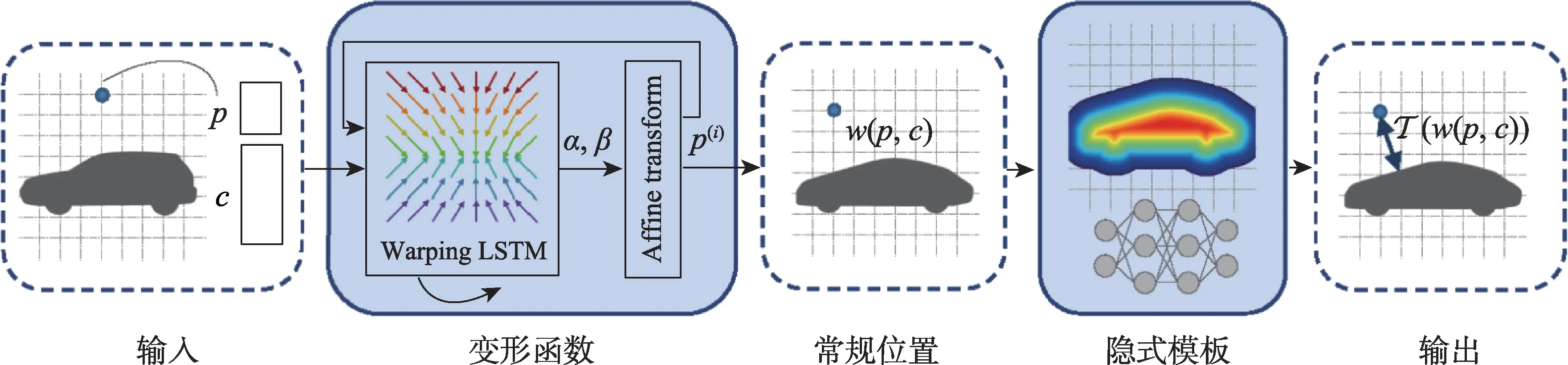
图5 DIT 的显式对应推理过程Fig.5 Explicit correspondence reasoning process of DIT
Erler等人[21]提出Points2Surf模型,这是一种新颖的基于块的学习框架,可直接从没有法线的点云中生成准确的隐式曲面。在不可见的类别上比最先进的方案具有明显的优势,代价是计算复杂,并且在小规模拓扑噪声略有增加。
三维数据结构表达方式总结如表1 所示。

表1 三维数据结构表达方式总结Table 1 Summary of 3D data structure expression
三维数据的深度特征表示给深度学习的三维重建奠定基础。随着数据结构研究的深入,三维重建的网络构建也在不断地发展。根据生成模型的数据结构的不同对网络构建进行分类,还根据训练时的监督情况和对同一物体采用的视角数量(单/多)来进行分类,如表2 所示。

表2 三维表征重建分类Table 2 Classification of 3D representation reconstruction
2.1 基于体素进行三维表征重建
基于体素卷积神经网络构建深度置信网络,美国普林斯顿大学的Wu 等人[12]提出第一个深度三维生成模型3D ShapeNets。基于Wu的工作,Girdhar等人[22]提出一种称为TL 嵌入网络的新架构,可以基于单幅影像处理从二维图像生成三维体素模型。同类型的工作还有,Choy 等人[23]设计一个神经网络架构实现基于体素的物体三维重建,提出一个扩展的标准长短期记忆人工神经网络(long short-term memory,LSTM)[24]框架,称为三维递归重建神经网络。OGN(octree generating networks)[25]直接在体素网格上预测输出,允许使用八叉树来有效地表示八叉空间从而预测更高分辨率的形状。Google的Rezende等人[26]提出一种无监督学习的三维重建模型,可以同时应用于体素和网格三维数据结构。
Stutz 等人[27]提出一种基于弱监督学习的三维形状补全方法。首先在合成数据上经过一次训练,然后使用深度神经网络进行最大似然拟合,从而在不牺牲准确性的情况下实现有效的形状补全,既不需要缓慢优化也不需要直接监督。同样是无监督学习三维重建,Yan 等人[28]提出利用投影变换作为正则化的编-解码器网络进行3D 形状和2D 图像交互。
来自MIT 的Wu等人[29]提出的3D-GAN 首次通过生成对抗网络(generative adversarial networks,GAN)[30]的方式学习得到三维形状空间,实现三维模型的随机生成。与之前取得突破性进展的基于体素卷积神经网络的方法相比,可以合成具有详细几何图形的高分辨率三维体素结构。
同样是MIT 的Wu 等人[31]采用分解思想提出MarrNet,将三维重建转换为先估计2.5D 的草图再估计3D 形状。优点是在2.5D 的草图更容易从2D 图像中生成,同时2.5D 草图的模型转移到真实数据要更简单。
Ji 团队[32]提出SurfaceNet 框架,关键优势在于能够以端到端的方式直接学习光一致性以及表面结构的几何关系,通过计算相机参数和使用体素表示三维物体,实现多视图立体视觉。
Kar等人[33]提出可微分的多视图立体几何(multiview stereo,MVS),如图6 所示,用于学习从多视点图像生成三维几何,为后来大量以MVS 为基础的深度学习工作奠定基础。双目立体视觉技术具有成本低、适用性广的优点,在物体识别、目标检测等方面应用广泛,成为计算机视觉领域的研究热点[34]。Huang团队[35]在MVS 的基础上,提出用于多视图立体重建的深度卷积神经网络DeepMVS,效果优于最先进的传统MVS 算法和其他基于卷积神经网络的方法。但是同年同样是基于MVS,香港科技大学的权龙教授团队[36]提出的MVSNet 在户外数据集Tanks and Temples[37]上取得优异的成绩,采用双目立体匹配的深度估计方法[38],扩展到多张图片的深度估计,使用三维卷积操作基于可微分的单应性变换的代价匹配体(cost volume)。权龙团队又在第二年对MVSNet做出进一步改进[39],将三维卷积神经网络改进为GRU时序网络[40],大幅度降低显存的消耗。

图6 MVSNet网络设计Fig.6 Network design of MVSNet
2.2 基于点云进行三维表征重建
点云可以被视为来自三维点分布的样本,其密度集中在形状的表面附近,点云生成相当于将随机采样点移动到高密度区域。随着三维数据的深度特征表示的发展,在2017 年Qi 团队提出PointNet[16]后,基于体素卷积神经网络去构建深度学习网络逐渐被基于点云和曲面网格的神经网络所取代,之后的模型训练和结果输出大都基于点云和曲面网格。基于PointNet 模型,Fan 团队[41]成功引入点云结构作为三维重建的输出结果,不仅可以在基于单幅图像的三维重建基准上优于最先进的方法,也展现出强大的三维形状补全性能和合理预测的潜力。
Achlioptas 等人[42]针对点云几何数据,引入具有最先进三维重建效果和泛化能力的深度自编码器(autoencoder)[43]网络。通过简单的代数操作实现形状编辑,在原始点云上对Wu 团队提出的3D-GAN 进行显著改进。Yang 等人[44]在PointNet 模型的基础上提出一种新的端到端深度自动编码器FoldingNet 来解决点云上的无监督学习挑战。提出的解码器仅使用具有完全连接的神经网络的解码器大约7%的计算量,实现更高的线性支持向量机(support vector machine,SVM)[45]分类精度。
Yang团队[46]提出使用概率框架(probabilistic framework)构建的生成模型PointFlow,学习一个两级分布层次(two-level hierarchy),其中第一级是形状的分布,第二级是给定形状的点的分布。对形状进行采样并从形状中采样任意数量的点,通过连续的归一化流学习分布的每个级别,以无监督的方式进行三维重建,在点云生成中实现当时最先进的性能。点云三维重建的方法往往会生成模糊的点云并且无法生成孔洞,针对这一问题Kimura 团队[47]提出Chart-PointFlow 生成模型,这是一种基于流的生成模型,具有多个潜在标签并将每个标签都以无监督的方式进行分配用于三维点云,使得提出的模型能够保留边界清晰的拓扑结构。同时ChartPointFlow 使用图表将对象划分为语义子部分,在无监督分割的情况下表现出卓越的性能。Klokov 团队[48]引入一个潜在变量模型,该模型建立在具有仿射耦合层的标准化流的基础上,可以在给定潜在形状表示的情况下生成任意大小的3D 点云。与最近基于连续流的工作相比,Klokov 团队的模型在训练和推理时间方面提供显著的加速,以获得相似或更好的性能。
与MVS 方法大都采用代价匹配体方法不同的是,Chen团队[49]提出PointMVSNet改进多视图立体几何深度框架,将目标场景处理为点云。这种基于点的架构比基于代价匹配体的架构具有更高的准确性、更高的计算效率和更大的灵活性。Luo 等人[50]提出的P-MVSNet 对MVSNet 的改进主要在于首先用一个聚合模块(patch-wise)提取特征的像素级对应信息以生成匹配的置信量,然后混合3D U-Net 从中推断出深度概率分布和预测深度图。
Xie 团队[51]针对无序点云提出基于能量的生成模型Generative PointNet。通过基于马尔科夫链蒙特卡洛(Markov chain Monte Carlo)的最大似然学习进行训练,而无需任何辅助网络的帮助;
不需要任何手工制作的点云生成距离度量,根据能量函数定义的统计属性匹配观察到的例子来合成点云,生成的点云表示三维模型十分适用于点云语义分割。
Spurek 团队[52]提出一种利用超网络特性生成三维点云的新模型HyperCloud,其主要思想是构建一个超网络,经过训练将点从统一的单位球分布映射到3D 形状,允许以生成方式找到3D 对象的基于网格的表示,同时通过最先进的方法提供高质量的点云。Cai团队[53]提出通过在未归一化的概率密度上执行随机梯度上升来生成点云,从而将采样点移向高似然区域[54],直接预测对数密度场的梯度,并且可以使用从基于分数的生成模型改编的简单目标进行训练。Luo 等人[55]将点云中的点视为与热浴接触的热力学系统中的粒子,将点云生成视为学习将噪声分布转换为所需形状分布的反向扩散过程,将点云的反向扩散过程建模为以特定形状为条件的马尔可夫链[56],推导出封闭形式的变分界用于训练并提供模型的实现,取得有竞争力的性能。
2.3 基于曲面网格进行三维表征重建
Groueix 等人[57]提出一种生成三维曲面网格表面的生成框架AtlasNet,将三维形状表示为参数化曲面元素的集合,自然地推断出形状的曲面表示。该方法相比于生成体素网格或点云的方法具有显著的优势,比如更高的准确性、更好的泛化能力,以及在生成任意分辨率的形状时避免内存占用问题。Wang 等人[58]提出Pixel2Mesh 模型,可以从单色图像生成曲面三维三角形网格,通过利用从输入图像中提取的感知特征逐渐变形椭圆体来产生正确的几何形状。该方法不仅定性地生成具有更好细节的网格模型,而且还实现了更高的三维重建精度。Kong 等人[59]采用正交匹配追踪[60]快速选择字典中与投影图像最接近的单个CAD 模型,在合成三维网格重建方面取得了不错的效果。
2.4 基于隐式曲面进行三维表征重建
Chen 等人[61]提出用隐式场来构建形状学习的生成模型(如图7 所示),并引入一种称为IM-NET 的隐式场解码器替换传统解码器进行表示学习和形状生成,得到在生成形状建模、插值和单视图三维重建等任务中领先的结果。Niemeyer 等人[62]提出一种用于隐式形状和纹理表示的可微分渲染[63]公式。其主要观点是,可以使用隐式微分的概念通过分析推导出深度梯度,使人们能够直接从RGB 图像中学习隐式形状和纹理表示。Jiang 等人[64]专为可扩展性和通用性而设计的新三维形状表示设计局部隐式网格。该团队将解码器用作形状优化中的一个组件,在重叠裁剪的规则网格上求解一组潜在代码,以便解码后的局部形状的插值与部分或嘈杂的观察相匹配,证明这种从稀疏点观察进行三维表面重建的方法比替代方法有明显更好的结果。

图7 IM-NET 网络示意图Fig.7 Network diagram of IM-NET
隐式场表示提供有效的三维重建方法,它基于专用于训练集中所有对象的单个神经网络,导致在现实世界中其训练过程和应用十分繁琐。更重要的是,隐式解码器仅采用在体素内采样的点,这会在分类边界产生问题并导致渲染网格内出现空白空间。针对这些问题,Proszewska 团队[65]引入基于区间算术网络的HyperCube 架构,它可以直接处理三维体素,使用超网络范式进行训练以强制模型收敛,允许输入以其凸包坐标表示的整个体素(三维立方体),由超网络构建的目标网络将其分配给内部或外部类别。
三维表征重建总结如表3 所示。

表3 三维表征重建总结Table 3 Summary of 3D representation reconstruction
前文总结的基于深度学习的三维表征重建方法主要针对基于结构无关的几何表示,目的是生成准确的三维表征数据,对模型的拓扑和结构的合理性并没有做过多的关注。大部分此类工作生成的是非结构化的三维物体,但是结构相关的三维表示应是部件相关(part-aware)的[1,69]。结构化的表达对于感知和理解三维物体是很重要的,如物体不同组件的构成、关系等。针对深度学习进行三维模型几何构建的挑战在于如何适应不同的形状变化,包括零件的连续变形以及结构或离散变化,这些变化包括增加、去除或修改形状成分和组成结构。
Li 等人[70]提出GRASS(generative recursive autoencoders for shape structures)模型(如图8 所示),最早将模型用一组具有层级结构的体素来表述三维模型部件,通过递归神经网络编码为一串隐向量特征,然后进行模型混合,最后把层级结构模型复原为连续的模型,使网络学习到部件本身的拓扑和结构特征。基于Li 等人[70]的研究,该递归神经网络模型被Han 等人[71]应用于单幅图像的三维几何结构合成,利用两个独立的全连接层分支,为双线性人脸重建生成独立的系数和子集,实现低成本交互式面部建模。
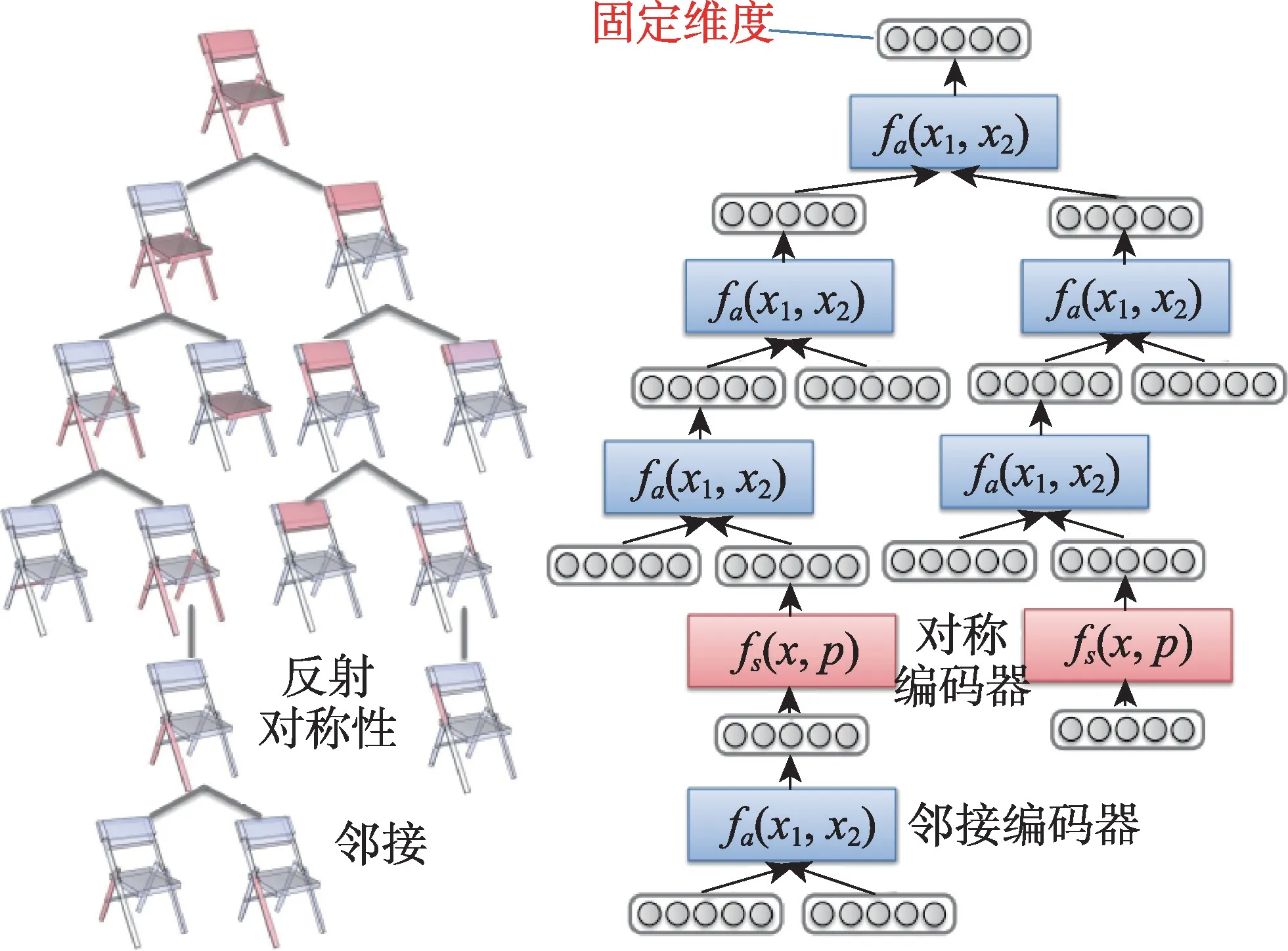
图8 GRASS 模型递归神经网络Fig.8 Neural network recurred by GRASS model
Gao 等人[72]提出生成结构化可变形网格的深度生成神经网络(deep generative network for structured deformable mesh,SDM-NET),一个两级变分自编码器(variational auto encoder,VAE)[43]。该网络联合学习形状集合的零件结构和零件几何形状,确保全局形状结构和表面细节之间的一致性。SDM-NET 在生成具有视觉质量、灵活拓扑和有意义结构的网格方面的优越性,有利于形状插值和其他后续建模任务。Wu 等人[73]同样是使用VAE 构建一种用于3D 形状的结构感知生成模型(structure-aware generative network,SAGNET)。该网络将几何形状和拓扑结构通过自动编码器联合学习并嵌入到潜在空间中,解码器解开特征并重建3D模型的几何和结构。Sitzmann团队[74]提出场景表示网络(scene representation network,SRN),一种连续的具有3D 结构意识的场景表示,可对几何形状和外观进行编码,并将场景表示为连续函数,将世界坐标映射到局部场景属性的特征表示。通过将图像生成为可微分的光线行进算法,SRN 可以仅从2D 图像及其相机姿态进行端到端训练,但是无法获得深度或形状。
Mo 等人[75]提出分层图网络StructureNet,通过图神经网络,提出N元图的顺序不变编码,在网络训练期间联合考虑部件几何和部件间拓扑关系,具有生成新颖、多样且逼真的三维形状以及相关零件语义和结构的能力。第二年,该团队又提出新的网络StructEdit[76],一种以源形状为条件基于编码和解码形状增量的条件变分自动编码器,可以有效和稳健地在多个形状修改和生成任务中学习对普通对象形状的几何和拓扑结构的差异。
Chen 等人[77]设计BSP-Net模型,利用空间数据结构二进制空间分区(binary space partitioning,BSP)对空间进行递归细分以获得凸集表示三维形状的网络。BSP-Net 推断出的凸面可以很容易地提取形成多边形网格,而无需任何等值曲面,同时其生成的网格很紧凑,非常适合表示锐利的几何图形。
Chen 等人[78]提出多分辨率深度隐式函数(multiresolution deep implicit functions,MDIF),一种采用分层表示且同时表示不同层次的细节并允许渐进解码的深度隐函数模型。该模型可以恢复精细的几何细节,同时能够执行形状完成等全局操作;
可以表示具有潜在网格层次结构的复杂3D 形状,将其解码为不同的细节级别,并且还可以获得更好的准确性。
Wu 等人[79]提出PQ-NET(part seq2seq network),一个基于序列化部件组装的三维形状表达和生成网络,以线性结构而非层级结构来表达结构化的三维形状。PQ-NET 一个最大的缺点是并没有输出各个部件之间的关系,例如对称、相邻等。这些关系更容易通过层级结构来表达,但代价是需要足够多的标注数据。Li 等人[80]使用零件感知深度生成网络对三维形状变化进行建模。该网络由一组所有部件的变分自编码器生成对抗网络组成,生成构成完整形状的语义部件,然后对模块进行部件组装成一个合理的结构。通过将零件组成和零件放置的学习委托给单独的网络,降低对3D 形状的结构变化进行建模的难度。
最新的研究将迁移学习3D 数据的预训练引入三维几何重建中来。Eckart 团队[81]提出一种用于3D 自监督表示学习的通用方法,将3D 点轻轻地分割成离散数量的几何分区。该团队在这些软分区中,隐式参数化生成潜在高斯混合模型[82],并且在该生成模型建立的数据似然函数的解释下,形成自监督损失。通过最大化由无监督逐点分割网络形成的软分区的数据可能性,鼓励学习的表示组成丰富的几何信息。
三维模型几何构建方法总结如表4 所示。

表4 三维模型几何构建方法总结Table 4 Summary of 3D model geometry construction methods
4.1 体素补全
Dai团队[83]最早通过体积深度神经网络和三维形状合成的组合来进行三维补全。引入一个由3D 卷积层组成的3D 编码预测网络推断出低分辨率但完整的输出。在测试时将这些中间结果与来自真实目标的三维几何相关联。最后提出一种基于块匹配(Patch-Based)[84]的三维形状合成方法。该方法将来自真实目标的三维几何图形作为粗略网格的约束。这种合成过程使人们能够在获得的全局网格结构的同时重建精细尺度的细节并生成高分辨率输出。Han团队[85]在这种数据驱动方法的基础上,结合全局结构推理网络和局部几何细化网络构建新的深度学习架构。全局结构推理网络包含一个长短期记忆上下文融合模块(long short-term memory-networks for machine reading,LSTM-CF)[86],该模块根据作为输入的一部分提供的多视图深度信息来推断形状的全局结构。在全局结构网络的引导下,局部几何细化网络将缺失区域周围的局部三维补丁作为输入,并逐步产生高分辨率的模型,通过体素编-解码器架构完成三维补全。
4.2 点云补全
Yuan 团队[87]提出一种基于学习的形状完成新方法——点完成网络(point completion network,PCN)。与现有的点云形状补全方法不同,PCN 直接对原始点云进行操作,在没有任何关于底层形状的结构假设或注释情况下设计解码器,保持少量参数的同时生成细粒度的点云。PCN 在具有各种不完整性和噪声水平的输入的缺失区域中生成具有真实结构的密集、完整的点云。
全局表示经常受到不完整点云局部区域结构细节信息丢失的影响,为解决这个问题,Wen 等人[88]提出用于3D点云补全的SA-Net(skip-attention network)模型。Wen 等人提出一种skip-attention 机制,以在缺失部分的推理过程中有效地利用不完整点云的局部结构细节,并且提出一种新颖的结构保留解码器,以实现在不同分辨率下充分利用由跳过注意机制编码的选定几何信息。通过在相同分辨率下使用跳过注意的几何图形,逐步详细说明局部区域来保留上层生成的完整点云的结构。
点云的无序特性会降低高质量3D 形状的生成,因为仅使用潜在代码的生成过程很难捕获离散点的详细拓扑和结构。Wen 团队[89]将形状补全表述为点云变形过程,设计一个新型神经网络来移动不完整输入的每个点以完成点云,其中点移动路径[90]的总距离最短。网络根据点移动的总距离的约束为每个点预测唯一的点移动路径,可以捕捉到不完整形状和完整目标之间的详细拓扑和结构关系,从而提高预测的完整形状的质量。以往的非配对补全方法只注重学习从不完整形状到完整形状的几何对应关系,而忽略反方向的学习。为解决这个问题,Wen 团队[91]又提出Cycle4Completion 网络,通过学习从互补的形状中生成完整或不完整的形状来促进网络理解3D 形状,实现完整形状和不完整形状的潜在空间之间的两个同时循环转换。
Huang 等人[66]提出一种新的基于深度学习的点云精确高保真完成方法PFNet。该方法不同于现有的点云补全网络,它从不完整的点云中生成点云的整体形状,在保留不完整点云的空间布局的同时预测出缺失点云的详细几何结构。
4.3 隐式曲面三维补全
Park 等人[92]引入DeepSDF(deep signed distance functions)模型,将不完整和低质量的三维输入数据进行高质量的形状生成、插值和补全。与之前的工作相比,该方法极大地提升三维形态再生成的性能,同时还将模型大小减少一个数量级。Liu 等人[93]通过引入隐式移动最小二乘法(implicit moving leastsquares functions,IMLS)[94]表面公式将离散点云转换为平滑表面,将IMLS 表面生成结合到深度神经网络中,以继承点云的灵活性和隐式表面的高质量,在三维重建质量和计算效率方面取得突破性进展。
Genova 等人[95]引入局部深度隐函数(local deep structured implicit functions,LDIF)结构化的隐式场,采用多个隐式函数的融合来表示三维几何,同时蕴含几何和拓扑信息。该方法可以实现准确的三维表面重建、紧凑的存储、高效的计算、相似形状的一致性、跨不同形状类别的泛化以及从深度相机观察中进行推断。
三维补全与修复方法总结如表5 所示。
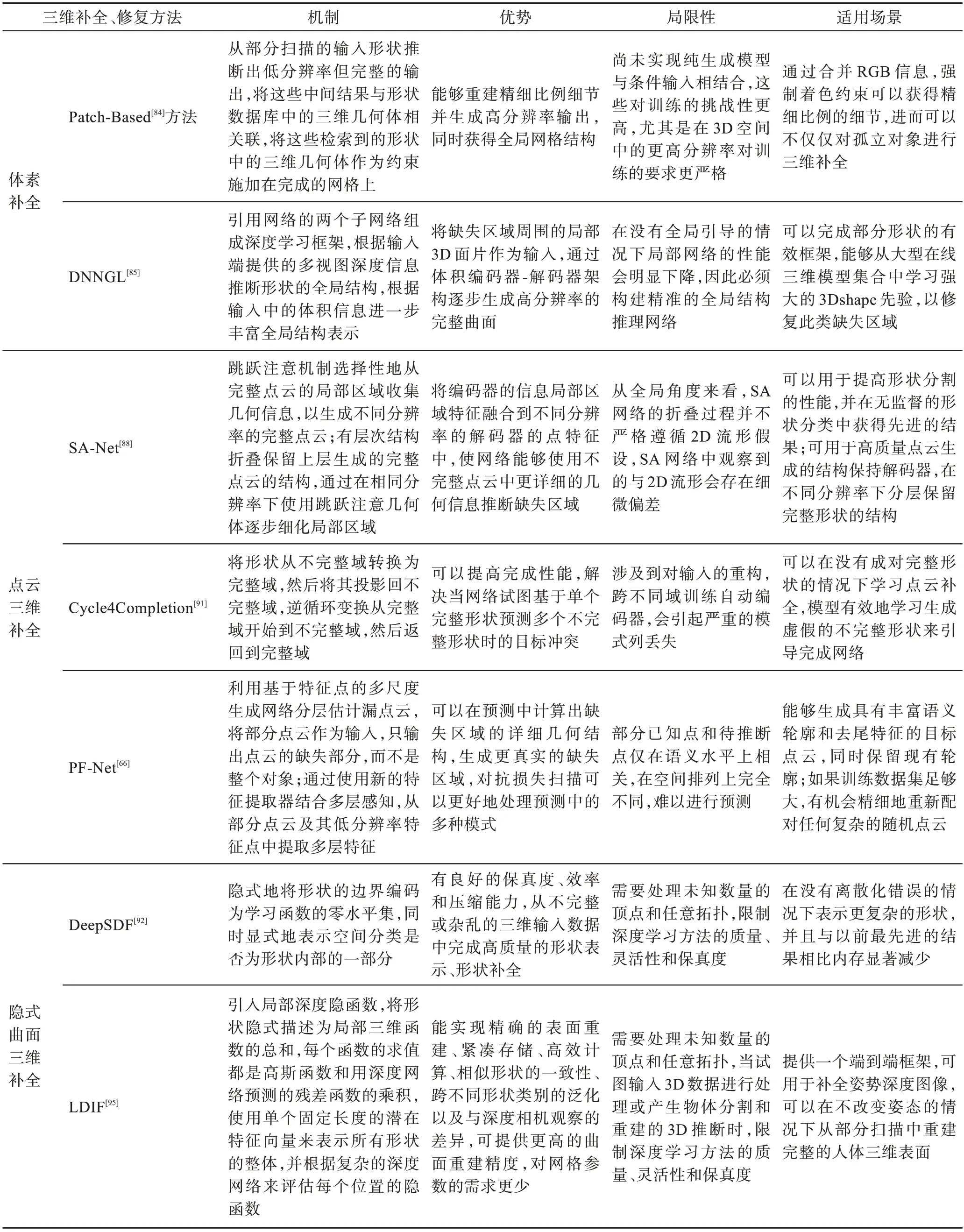
表5 三维补全与修复方法总结Table 5 Summary of 3D completion and repair methods
5.1 身体三维重建
使用深度学习表示对刚性3D 对象进行建模取得重大进展,然而对于动态非刚体重建依旧面临重重挑战。人体是复杂的,人体三维重建最大的挑战在于学习一个能够以看不见的、高度清晰的姿势表达看不见的主体的身体形状变化。
动态人体的自由视角视频有很多应用,包括电影工业、体育直播和远程视频会议。在一些综艺类节目中实现类似子弹时间的特效,对于静态物体,这是可以做到的,一般是对着静止的物体拍一圈图片。为拍摄稠密多视角视频,之前的方法需要昂贵的相机阵列来进行捕捉。视角合成方法主要是神经隐式表示(neural implicit representation,NeRF)[96]的技术手段,实现这个技术的设备特别昂贵,而且使用还很不方便,一般只在电影拍摄时用到。NeRF[96]只能处理静态场景。现在大部分视角合成工作是对每个静态场景训练一个网络,对于动态场景,上百帧需要训练上百个网络,成本很高。并且对于动态场景来说,工作人员无法要求演员静止来让人们给他拍一圈 图。Kinect Fusion 提 出 的Dynamic Fusion[97],使 用单个Kinect进行深度序列拍摄,创造性地将体融合三维重建技术和嵌入式变形图模型的表面非刚性跟踪技术糅合在一起,在GPU 上演算,进而实现实时单视角动态场景三维重建。但是Kinect 传感器同样也存在着设备昂贵、操作复杂的缺点。
Corona团队[98]设计一种新颖的生成模型SMPLicit,用于联合表示身体姿势、形状和服装几何形状。与需要为每种类型的服装训练特定模型的基于深度学习的三维重建方法相比,该模型能够以统一的方式表示不同的服装拓扑,同时控制其他属性,如服装尺寸或松紧或松散,并且在潜在空间的语义上可解释并与服装属性对齐,模型是完全可微的,可用于更大的端到端可训练系统。
隐式曲面首次引入人体三维重建是来自日本的Saito 团队[99]。该团队引入一种高效的隐式表示像素对齐隐式函数,将2D 图像的像素与其对应的3D 对象的全局上下文局部对齐,提出一种端到端的深度学习方法,可用于重建穿着完整衣服的人。该方法可以从单个图像和可选的多个输入图像推断3D 表面和纹理,并且可以生成高分辨率表面,包括大部分看不见的区域,例如人的背部。相比体素表示三维模型,隐式曲面方法的内存效率高,可以处理任意拓扑,并且生成的表面与输入图像在空间上对齐。Chibane 等人[68]提出隐式特征网络IF-Nets 实现三维形态再生成,可以处理多种三维数据结构,以及缺失或稀疏输入数据的完整形状,保留最新深度学习隐式函数的良好特性和它出现在输入数据中的细节,并且可以清晰地重建人体。
将参数化3D 身体模型[100-101]拟合到穿着衣服的人体扫描是容易处理的,而身体拓扑结构与扫描的表面配准通常则不然,因为衣服可能会显著偏离身体形状。基于这一发现,时隔两年,Saito 团队[102]又提出SCANimate(skinned clothed Avatar networks)框架,一种弱监督学习方法。该方法通过在没有基于模板的表面配准的情况下解开铰接变形来将扫描对齐到规范姿势,引入局部姿势感知隐式函数,使用学习的姿势来补全和建模人体。在训练数据有限的情况下,局部姿态调节相比全局姿态嵌入显著降低远程虚假相关性[103]并提高对未知姿态的泛化能力,可以应用于姿势感知外观建模以生成完全纹理化的头像。
Mihajlovic 团队[104]提出一种新型的人体神经占用表示。给定一组骨骼变换(即关节位置和旋转)和空间中的一个查询点,首先通过学习的线性混合蒙皮函数将查询点映射到规范空间,然后通过占用网
络有效地查询占用值,对规范空间中的准确身份和姿势相关变形进行建模。该网络极大程度提高了学习的占用表示对各种人体形状和姿势的泛化能力。
5.2 面部三维重建
人脸建模在视觉计算领域备受关注。在多种场景下,包括卡通人物、社交化身媒体、3D 面部漫画以及与面部相关的艺术和设计都需要进行人体重建,尤其是针对业余三维建模用户,深度学习对于面部低成本交互式人脸三维重建是革命性的。
由于手工建模耗费大量的人力,三维成像仪器也得到长期的研究和发展。基于结构光和激光仪器的三维成像仪是其中的典型代表,这些基于仪器采集的三维模型,精度可达毫米级,是物体的真实三维数据,也正好用来为基于图像深度学习的建模方法提供评价数据库,缺点是仪器的成本太高。
人脸的三维模型以RGB 图像作为输入,重建相应的三维人脸网格。传统方法为使得到的3D 模型更接近真实图像,一般采用图形学中基于栅格化的渲染来进行模型参数的优化。一方面,为尽可能地使模型逼近图像,会采用更高自由度的参数化模型表达人脸的表面纹理;
另一方面,在渲染结果比对上会采用模糊化的方式使渲染结果与图像之间的差异以一种可微分的方式传递给3D 模型。
5.2.1 3DMM 技术
早期基于深度学习的三维人脸重建都是基于三维形变模型(3D morphable model,3DMM)的技术来实现。3DMM 就是一个允许形变的三维模型,原理是将世界上的所有人脸都看作由一个标准的人脸模型经过一些变形而生成。其强大之处在于不是依靠人工,而是给定两组系数,分别是形状系数、颜色系数。不同的3DMM 模型定义的系数有些许差别,如表6 所示,实际上,后面还延伸出一种表情系数。

表6 3DMM 系数定义及其含义Table 6 Definition and meaning of 3DMM coefficient
Zhu 团队[105]最早通过级联卷积神经网络将密集的3D 可变形人脸模型(3DMM)[106]拟合到图像,提出三维密集面部对齐(3D dense facial alignment,3DDFA)的新对齐框架,利用3D 信息在个人资料视图中合成人脸图像。Feng 团队[107]提出直接同时重建3D 面部结构并提供密集对齐,设计一种称为UV 位置图的二维表示,它记录UV 空间中完整人脸的3D 形状,然后训练一个简单的卷积神经网络以从单个2D 图像中对其进行回归。将权重掩码集成到损失函数中,以提高网络的性能,同时不依赖于任何先前的人脸模型,并且可以重建完整的人脸几何形状以及语义。
大部分方法都属于有监督学习,需要大量的标注数据,而带有真实3D 人脸形状的图片是相对比较稀少的,而且这种标注也费时费力,很难完成。基于3DMM 技术,Deng 团队[108]设计一种同时考虑重建的人脸模型渲染得到的图片和输入图片的像素值应尽可能一致,以及重建的人脸模型渲染得到的图片和输入图片的内在特征应尽可能一致的鲁棒的损失函数。Genova 团队[109]提出一种仅使用未标记照片训练从图像像素到3D 可变形模型坐标的回归网络的方法。训练损失基于来自面部识别网络的特征,通过使用可微渲染器预测的面部来即时计算。实现三个目标,鼓励输出分布与可变形模型的分布相匹配的批量分布损失,确保网络可以正确重新解释其自身输出的环回损失,以及多视角身份损失,从多个视角比较预测的3D人脸和输入照片的特征。Tewari团队[110]将卷积编码器网络与用作解码器的专家设计的生成模型相结合,构建新的可微参数解码器。该团队基于生成模型分析性地封装图像形成,将具有精确定义的语义的代码向量作为输入,对详细的面部姿势、形状、表情、皮肤反射率和场景照明进行编码,以无监督的方式进行端到端的训练,使得对非常大的真实世界数据的训练变得可行。
3D 人脸形状重建的关键挑战是在可变形网格和单个输入图像之间建立正确的密集人脸对应关系。以前的人脸三维重建工作严重依赖先验知识(例如3DMM)来减少深度歧义。尽管最近3D 人脸重建取得令人印象深刻的结果,但投影的面部形状更好地与每个面部区域(即眼睛、嘴巴、鼻子、脸颊等)在图像上对应关系仍然有很大改进的空间。
Zhu 团队[111]为进一步减少歧义,提出一种称为强化可微属性的新框架,它比以前的可微渲染更通用和有效。首先从颜色扩展到更广泛的属性,包括深度和面部解析掩码。之后通过一组具有多尺度内核大小的卷积操作使渲染更具可区分性。进一步引入一个新的位于3DMM 之上的自由变形层,以提供先验知识和进行空间外建模。
针对在卡通动漫领域的面部三维重建,Han 团队[71]提出一种基于深度学习的草图用于3D 面部和漫画建模的系统。用户徒手绘制代表面部特征轮廓的不精确的二维线条,基于CNN 的深度回归网络设计用于从2D 草图推断3D 人脸模型。该网络融合输入草图的CNN 和基于形状的特征,并且有两个独立的全连接层分支,为双线性人脸表示生成独立的系数子集。同时该团队还构建具有不同身份、表情和夸张程度的显著扩展的人脸数据库,以促进对人脸建模技术的进一步研究和评估。
Dai 团队[112]提出Scan2Mesh 模型,将非结构化且可能不完整的范围扫描转换为结构化3D 网格表示。将3D 网格生成为一组顶点和面索引,生成模型建立在一系列顶点、边和面的代理损失上。通过卷积和图神经网络架构的组合实现预测数据点和地面实况数据点之间的一对一离散映射,能够预测紧凑的网格表示,实现类似于使用三维建模软件手工创建的三维网格表示。
5.2.2 GAN 技术
利用深度卷积神经网络的强大功能,研究人员已经进行大量工作来从单个图像重建3D 面部结构。然而最新的工作中,纹理特征要么对应于线性纹理空间的组件,要么由自动编码器直接从大量图像中学习。在所有情况下,面部纹理重建的质量仍然无法对具有高频细节的面部纹理进行建模。于是研究人员选择采用一种截然不同的方法,利用生成对抗网络的强大功能,从单个图像重建面部纹理和形状。
同样是基于生成式对抗网络,Gecer 团队[113]训练一个非常强大的面部纹理先验,提出新的基于自我监督回归的方法,利用非线性优化找到最佳潜在参数,在新的视角初始化出具有鲁棒性的人脸并加快拟合过程。
尖端的3D 人脸重建方法使用非线性可变形人脸模型结合基于GAN 的解码器来捕捉人的肖像和细节,但无法生成漫射光照条件下中性表情和皮肤纹理,这对于在变化照明的虚拟环境中三维图像重建是至关重要的。
受到StyleGAN[114]的启发,Piao 团队[115]构建一种从输入三维模型到生成图像的平滑梯度,能够以低精度建模获得渲染质量更高的图像,与此同时,采用生成网络式的渲染器反向传播算法,能够获得更具有图像细节特征的重建人脸3D 模型。设计一个基于3D 人脸几何信息的渲染模块,在保持用随机隐变量生成纹理的同时显示地加入人脸的几何信息。同样是基于StyleGAN,Luo 团队[116]通过将非线性可变形人脸模型嵌入到StyleGAN2 网络中来采用高度稳健的归一化3D 人脸生成器,这使得模型能够生成详细但标准化的面部资产。推理之后是感知细化步骤,该步骤使用生成的资产作为正则化来应对归一化人脸的有限可用训练样本。
与传统的二维深度学习任务一样,基于视觉深度学习的三维重建算法的研究同样也十分依赖于数据集的进步和发展。对于需要监督学习的三维重建算法,三维数据集除需要包含二维图像外,还需要对应的、采用合适的深度特征表示的三维数据。除此以外,无监督学习和弱监督学习同样也依赖于二维图像外部参数,例如摄像机的参数和拍摄位置信息等。
数据集的质量和全面程度极大地影响着深度学习三维重建的发展。对于部分三维数据集,只有很小一部分数据有着对应的、精确的三维模型;
而部分数据集,只有每类目标对应的三维数据,没有相应的二维数据(因为这部分三维数据最初是用来完成三维目标检索等任务的)。当研究人员在选用数据集进行深度学习网络研究时,还需考虑三维数据采用的深度特征表示是否适配网络。
许多研究人员在早期可以选择的数据集并不多的情况下,有些人会通过多种数据集组合到一起进行实验,还有一部分人会对现有的三维图像进行相应的三维几何变换(例如平移、旋转和缩放等)。尽管这些方法丰富了数据集的数量,但还是导致数据集出现不够统一或者相似性变高等问题[8]。还有研究人员在数据集没有二维图像的情况下,从各种视角、姿势和照明条件生成新的2D 或深度图像。这导致在深度学习中需要考虑域适应的问题,即合成图像不同于真实图像,在合成图像上进行训练通常会导致在真实图像测试时性能会发生下降。
数据集的发展依赖着三维重建算法的研究,同样也促进着三维重建算法。选用、组建合适的数据集去进行实验,会极大地帮助深度学习网络研究成功,也是研究结果具备说服力的重要条件之一。表7列举了近年来经常被研究人员采用的数据集及主要参数。

表7 常见的三维重建数据集及其部分参数Table 7 Datasets and parameters of common 3D reconstruction
相比于ImageNet 等千万量级的二维图像数据集,传统的三维形状数据集很小。最早的由Silberman等人[117]提出的NYU 数据集包含1 449 个RGBD 图像,捕获464 个不同的室内场景,并带有详细的注释。
近年来发布的较大的数据集有用于形状分类与检索的ModelNet 数据集[12]和ShapeNet 数据集[120]。ModelNet 数据集[12]包含来自662 类的127 915 个三维形状,其子集Model10 包含来自10 类的4 899 个三维形状,ModelNet40 包含来自40 类的12 311 个三维形状。ShapeNet数据集[120]包含约300 万个形状,其子集ShapeNetCore包含来自55 类的51 300 个形状。
7.1 应用
7.1.1 影像娱乐工业
三维重建在影像娱乐工业领域已经发展很多年。从业人员希望把更多的精力放到游戏或者程序本身的交互上,同时又希望对模型动画有足够的掌控能力,大多数企业需要整理数据量惊人的模型贴图动画资源库,因此压缩建模贴图动画等工作十分重要。
资源库主要还是通用的素材,针对特定要求仍需付出费用和时间进行重新建模,同时还要控制质量。在模型重建方面,研究人员通过三维扫描进行突破,但过程并不顺利。早期三维扫描仪价格昂贵,精度低下,软件配套也并不完备,对于如何处理破面、重叠等问题非常不理想。MeshMixer 技术[130]出来之后,极大促进该技术的整体发展。三维软件在这方面得到比较实用的解决方案,早期的光学扫描,对大尺寸物件基本无解,只能对昆虫之类的小物件进行扫描,而且对于多角度扫描的拼接操作复杂,耗时久。之后,手持扫描的出现极大地提高了精度,不足的是需要贴点,成本高昂,且对不同类型的物件需适配不同型号才能达到较好效果。
同时,人脸三维重建逐渐在影像娱乐工业领域得到广泛应用。最早的三维人脸重建并没有针对人脸本身的特征,而是将成熟的通用三维重建方法应用到人脸重建中。从2016 年开始,电影、游戏厂商开始大规模地采用照片重建进行游戏人物和物品的建立,《如龙》等游戏海量地采用照片重建。
7.1.2 数字孪生与元宇宙
数字孪生指对机械或系统的精确虚拟复制,结合传感器采集的实时数据,尽可能全要素在计算机中映射某项产品、流程或服务。数字孪生系统具备的动态仿真功能,能够对设计模型在制造环节前进行仿真,提前估计可行性、效率性,以及发现问题并反馈至设计进行修改。在这个环节中,三维扫描能够在某些领域,例如汽车油泥模型的设计,提升物理实体和数字实体的转化效率。在以数字孪生驱动的设计中,数字模型是基础。深度学习三维重建具备高效的建模能力,能在几分钟之内快速创建实体的数字模型,并支持导入数字孪生系统。很多大型公司已经在使用数字孪生发现问题并提高效率[131]。
在数字孪生的过程中,缺失或错误的数据和采集频率可能会扭曲结果,掩盖故障。如果为某个物体或系统构建数字孪生体,研究者必须为其各个部分建模。很多数字孪生都需要组合使用,例如一架虚拟飞机可能包含一个三维机身模型、一个三维故障诊断系统和一个三维监测空气和压强的系统。德国生产商西门子为其产品和生产线创建许多数学模型和虚拟表达,其中包括三维几何模型和有限元分析,后者可以追踪温度、应力和应变。故障诊断和生命周期则交由其他模型处理。这些为不同目的所写的软件在被手工整合的时候,如果没有标准或指南,大概率会出现其他错误,就很难验证最终模型的精度。
7.1.3 医学三维重建
在目前图像处理领域中医学三维重建技术得到广泛应用,在医学研究方面具有创新意义,同时在医学教育方面也发挥着指导作用。随着科学技术的进步和不断地更新迭代,三维重建方法对临床医学产生深远影响。
外科手术中的三维重建过程是将患者原始数据导入三维重建软件,再进行三维建模,形成三维可视化模型,为医生提供更丰富更直观的病灶信息,使得医生的诊断结果更精确。基于三维重建模型的手术操作模拟,让医生在术前掌握手术过程,有利于医生提前进行手术风险的评估和手术设计方案的规划。对于经验不足的医生,三维重建可以帮助诊断患者病情,对于患者来说也很容易看明白自己病情的具体情况。除此以外,三维重建还可以作为术中导航。从精准医疗来讲,多一种验证手段保证手术的精准度是可取的,通过三维重建技术建立“逼真”的模型,分割标识出患者病灶区域的肿瘤、血管、神经、骨质等各个组织结构,利于医生观察与诊断,并数字化模拟手术操作过程,以优化手术方案。术前与术后的数字化模拟对比,能够预测手术效果,检验手术设计方案。三维影像在不同科室应用重点略有不同,三维影像可以做量化分析,比如对于肝胆外科进行肝胆切除的应用,术前精准定位占位的分区,评估余肝体积。
在外科之外,三维重建还有许多应用。医疗机器人同样依赖于三维重建的发展。医疗机器人是一种智能型服务机器人,它能独自编制操作计划,依据实际情况确定动作程序,然后把动作变为操作机构的运动。它具有广泛的感觉系统、智能和精密执行机构,从事医疗或辅助医疗工作。在医学美容产业中,三维重建超越传统模拟整形,从各角度立体动态模拟,实现有效沟通,可以直观地看到整形后的效果与对比变化。
7.1.4 文物重建
文物数字化已成为趋势。文物古迹是人类不可再生、不可永生的宝贵资源,是人类文明发展的见证。文物古迹测绘不仅是一种保存文物数据的方法,也是展示人类文明的有效途径。随着科技的发展和文明的进步,文化遗产的三维数字化重建将有更多的应用场景,为弘扬和传承传统文化起到促进作用。
在当今的文化遗产数字化保护领域,利用三维数字化扫描重建和虚拟现实技术已经成为主要的手段。针对不同的对象,为获得最佳的数据内容,需要研究和利用对象的特点,并结合最新的技术成果制定有针对性的技术方案。对于表面色彩信息丰富的对象,为再现真实的形态和表现色彩,目前一般采用三维扫描的方法获取文物高精度点云位置信息,经点云配准、去噪和修补等优化操作得到完整的网格模型,通过数码相机多角度拍摄该文物的纹理图像,经人工贴图技术和纹理映射方式,将纹理图像贴在网格模型对应的位置上,得到最终含纹理信息的数字模型。
近些年得益于民用无人机行业发展,相对于传统航测,利用无人机设备采集大型文物的数字影像的成本大大降低,并且无人机还提供高精度的影像位置信息,简化数据处理流程。利用软件进行三维建模效果很惊艳,如今的摄影测量解决方案已经十分成熟,但是受光照条件影响,在精度和阴影部位等方面仍需要更多改进。
7.1.5 自动驾驶
随着人工智能技术的不断发展,自动驾驶为解决交通拥堵、事故频发等问题提供一种新途径。自动驾驶中如何对道路及障碍物进行准确识别或三维重建成为自动驾驶的一个重要课题。
主动式三维形状获取主要依靠传感器收发数据。激光雷达是自动驾驶中最重要的传感器之一。激光雷达三维点云蕴涵着丰富的空间位置信息,如空间各点之间相邻结构关系、被扫描物体表面的纹理细节等,极大地拓展自动驾驶环境感知方法。三维激光雷达数据模拟生成是自动驾驶汽车虚拟测试中的重要任务。建立高效、真实性强的障碍物三维激光点云仍然是自动驾驶汽车虚拟测试的难点问题[132]。
汽车作为民用消费品,激光雷达传感器费用昂贵,高性能视觉传感器结合视觉算法实现被动式三维重建逐渐走入自动驾驶工业界视野。随着计算机视觉领域三维重建的研究,通过提升算法的性能,提高三维模型的准确率和时效性,逐渐满足现在交通场景的要求。然而在优化视觉三维重建的抗干扰性能和数据处理速度方面仍然有待改善,若是能够充分考虑这些方向,将对自动驾驶汽车的舒适性、安全性、稳定性产生巨大的影响。轻量级三维几何深度生成模型,可用于实时、在线的室外场景导航、建图和语义理解、生成、预测及臆想,是目前三维视觉的研究热点,对于面向语义任务的导航规划具有重要意义。
7.2 未来发展方向
三维深度学习强大的表征学习能力和几何推理能力,为基于单视点图像或不完整几何数据的三维重建或恢复带来实质性推动。目前主流方法大致有两种:一是基于几何推理的判别式模型,训练端到端神经网络,将输入图像或几何数据直接映射到目标三维模型;
二是面向形状空间训练深度生成模型,学习三维对象的形状空间,然后基于度量学习将输入图像或几何数据嵌入到该形状空间中,最后从该嵌入向量解码出三维模型,从而实现对输入的三维重建。
深度学习技术的成功在很大程度上取决于训练数据的可用性,大规模三维数据集的构建是数据驱动三维建模发展的关键。与分类和识别等任务中使用的训练数据集相比,包括图像及其3D 注释的公开可用的数据集很少,且其中多数依赖于基于轮廓的监督,只能重建视觉表征。目前国际上公开的三维数据集已有不少,单个物体和室内外场景都有覆盖,但大多都是国外团队创建的。国内在三维数据集方面的贡献还有待加强,在未具备足够的训练数据的情况下,三维深度学习能力必将受到限制。因此构建充足、精确的三维数据集是一项非常重要的任务。
事实上,三维重建方法的最终目标是能够从任意图像中重建出任意的三维形状。然而,基于学习的技术仅在训练集覆盖的目标种类和对象上表现良好。在2D 图像的表示上,迁移学习取得成功,但如何将这些技术应用于数据结构较少的3D 领域仍不清楚,这将激发人们未来对专门针对3D 数据特质设计的新型任务进行研究。因而未来一个有实际意义的研究方向是将深度学习和迁移学习的技术相结合,以提高后者的普适性。
同时研究人员也期望在未来看到特定种类的知识建模和基于深度学习的3D 重建之间的更多协同作用,以便特定领域的应用。例如当前对人体模型的3D 重建借助拓扑结构与身体相似的衣服,这种方法将不适用于与身体显著偏离的衣服,如裙子等。同时,衣服褶皱往往是随机的,对于特定的姿势,它们会存在不同的排序方式。然而,当前的模型是确定性的,这无法处理类似褶皱的随机的附加变量。针对这一问题,未来的工作可以将表面纹理考虑到反照率、形状和照明中,以实现更逼真的扫描重建。学习服装多样性的生成模型应该是可能的,但需要不同姿势的各种服装的训练数据,这对国内三维数据集的构建又提出较为严格的要求。事实上,人们对专门针对特定类别物体的重建方法越来越感兴趣,如人体(文中已简要介绍)、车辆、动物、树木和建筑物。专门的方法利用先验的和领域特定的知识来优化网络结构及其培训过程,因此它们通常比一般框架执行得更好。然而,类似于基于深度学习的3D 重建,建模先验知识(例如使用高级统计形状模型)需要3D 注释,这对于许多类别的形状(例如野生动物)不容易获得。短期内自动建模无法完全取代人工建模,发挥数据驱动方法的优势,研究智能化的三维获取与重建,需重点关注数据驱动的主动式三维获取,针对形状复杂、成像困难物体(如透明、反光物体)的三维重建,以及数据驱动的语义理解。
结构化三维表征学习是当前三维深度学习的热点。现有方法一般需要较强的监督信息,例如对训练数据进行实例分割和部件标注。如何设计无监督或自监督的深度网络,以无结构三维表示为输入,生成结构化的三维表示,是值得关注的研究课题。
大趋势上,三维重建领域逐渐向着商用化、实用化逐步迈进,对重建的实时性和重建质量,以及对运动和渲染的真实感的要求越来越高;
同时逐步由室内简单环境下的人体三维重建,向着野外复杂环境下的三维重建过渡;
所用设备逐步简单化,从多台昂贵的摄像机向单目摄像机,继而向着消费者级别的单目摄像机,甚至是移动端相机发展;
同时重建目标从单目标向着多目标的方向发展。近年来,越来越有效的自监督学习、无监督学习方法不断涌现。
三维重建是计算机视觉的重要任务之一。本文调查自2014 年以来使用深度学习重建通用对象的三维形状的研究进展,分别以输入数据深度特征表示、网络架构以及它们使用的训练机制进行分类,详细阐述每类方法的发展过程和改进。然后讨论每个类别方法的优缺点及重大改进。同时还梳理近年出现的三维重建新领域,例如三维补全和修复、人体三维重建的发展脉络,并简单进行分类和比较。深度学习三维重建这个计算机视觉新兴领域的数据集体量小,标准混乱,本文对三维数据集的应用场景、重要参数进行总结,同时也期待有更全面、更完善的数据集出现。本文着力于通过深度学习的方法从一幅或多幅RGB 图像中复原物体的3D 几何形状的3D重建,还有许多其他相关问题有着相似的解决方案本文并没有过多地讨论,比如SLAM(simultaneous localization and mapping)[133]、SfM(structure-frommotion)[134]、点云语义分割等,这些领域在过去五年中有很多最新进展,需要单独进行深入调查。
猜你喜欢三维重建人脸形状挖藕 假如悲伤有形状……中学生天地(A版)(2022年11期)2022-11-25有特点的人脸少儿美术·书法版(2021年9期)2021-10-20一起学画人脸小学生必读(低年级版)(2021年5期)2021-08-14基于Mimics的CT三维重建应用分析软件(2020年3期)2020-04-20你的形状新世纪智能(英语备考)(2018年11期)2018-12-29三国漫——人脸解锁动漫星空(2018年9期)2018-10-26火眼金睛小天使·五年级语数英综合(2016年12期)2016-12-09基于关系图的无人机影像三维重建光学精密工程(2016年6期)2016-11-07三维重建结合3D打印技术在腔镜甲状腺手术中的临床应用腹腔镜外科杂志(2016年12期)2016-06-01多排螺旋CT三维重建在颌面部美容中的应用中国医疗美容(2015年1期)2015-07-12推荐访问:重建 综述 深度