基于无采样协作知识图网络的推荐系统
来源:华图网校 发布时间:2022-11-15 点击:
蒋雯静,熊 熙,3*,李中志,李斌勇
(1.成都信息工程大学网络空间安全学院,成都 610255;
2.先进密码技术与系统安全四川省重点实验室(成都信息工程大学),成都 610225;
3.四川大学空天科学与工程学院,成都 610065)
随着网络应用程序的规模日渐扩张,互联网平台上的在线内容也呈指数级增长,由此产生的信息超载问题有效地推进了推荐系统的应用:电影推荐、产品推荐、新闻推荐等。在大量面向用户服务的在线平台中,信息消费者追求精准推荐的消费快感,信息生产者则希望推送内容能最大限度匹配用户需求。而推荐系统正是通过充当两者的媒介,一举两得解决了问题。在各种推荐策略中,经典的协同过滤(Collaborative Filtering,CF)方法因其良好的性能被广泛关注,它基于用户历史交互进行偏好分析,为指定用户提供推荐列表或喜好预测。尽管CF 能独立于领域知识自动学习嵌入向量,但其受限于数据稀疏性和冷启动问题。因此,研究者常结合辅助信息来优化推荐性能。
知识图谱(Knowledge Graph,KG)是一种新兴的知识载体,它将文档数据整合成简单易懂的三元组形式,并通过节点之间深层次的语义关联来补偿数据稀疏性。例如,(王家卫,导演,阿飞正传)表明王家卫是《阿飞正传》的导演。KG作为一种有向异构图,节点和边分别对应于不同类型的实体和语义关系。这样的图结构意味着KG 具有很强的关系表示能力和建模灵活性,近年来已经被成功应用于许多领域,如KG 补全、问答系统等。
基于知识图谱的推荐系统正是在这一背景下所提出的新研究问题,强调学习物品(用户)之间的关联性,实现KG辅助优化推荐系统。将KG 集成到推荐系统具有以下优势:1)有利于发现用户深层次的潜在兴趣,进而提升推荐结果的准确性;
2)KG 中丰富的关系类型有效避免了推荐结果的单一性;
3)用户和物品之间的连通性为推荐结果提供了合理的解释。尽管有以上好处,但将KG 中的高维异构信息有效融合到推荐系统具有很大的困难性。一种可取的建模方法是基于知识图嵌入(Knowledge Graph Embedding,KGE)对KG 中的组件进行预处理,学习实体和关系的低维向量,进而直接应用于推荐任务中。但KGE 忽视了图结构信息且学习到的向量不足以描述推荐任务。另一种更直观的方法是基于路径的推荐,直接利用KG 图结构建模关联路径表示。由于需要手动设计元路径,这类方法很难达到最优。
近年来,图神经网络(Graph Neural Network,GNN)及其变体在以知识图谱作为额外信息的推荐任务中取得了巨大了成功。借鉴于GNN 中信息传播的思想,这类方法同时从内容信息和图结构两个方面建模数据,有效克服了以往方法的缺陷。因此,目前针对KG 结合推荐的代表性研究很多沿袭了基于GNN 的技术路线。然而,引入GNN 同样面临以下问题:1)信息传播过程中指数级增长的节点数量导致了巨大的内存和时间成本。为了缓解这种情况,现有的方法通常使用采样策略在训练时保留节点邻居或子图的子集来减轻计算成本。然而,采样操作可能在优化过程引入误差。2)深度图神经网络架构中固有的梯度消失和特征平滑等问题,导致模型训练难度较大。尽管最近一些工作表明能在一定程度上改善这些问题,但广泛的实验证明深度往往不会带来显著的收益性。平衡模型的深度和效率,使图神经网络能处理大规模的网络是现阶段的挑战。
为了缓解上述解决方案的局限性,本文认为开发一个兼具简单性和表达性的基于知识图谱的推荐模型是至关重要的。为此,本文从GNN 的研究中获得灵感,无采样的单个图卷积层有潜力实现本文的目标,但在基于KG 的推荐中还没有得到足够的探索。因此,本文提出了一种名为无采样协作知识图网络(Non-sampling Collaborative Knowledge graph Network,NCKN)的方法。NCKN 配备了协作传播和无采样知识传播两种核心设计来分别学习用户交互中的协作信号和知识嵌入。具体来说:1)在协作传播模块中编码用户交互中的潜在协作信号,并将其同KG 中的辅助信息结合,以获得更具表达性的嵌入向量;
2)鉴于传播过程中的采样误差问题,设计了无采样知识传播层,它通过在单个卷积层使用不同大小的线性聚合器来捕捉深层次的信息,实现高效的无采样预计算。
本文工作的安排如下:
1)提出了一种NCKN 方法,它通过协作传播和无采样知识传播层,将用户交互中的协作信号与KG 中的高阶信息相结合。
2)将NCKN 应用于三种现实世界的音乐推荐、书籍推荐、电影推荐场景。
1.1 基于知识图谱的推荐方法
将知识图谱作为辅助信息集成到推荐系统已被证明有利于缓解数据稀疏性和冷启动问题。一些研究利用KG 中实体的关联性进行嵌入学习,例如:Zhang 等采用TransE(Translating Embedding)学习项目结构信息、内容信息的特征嵌入,并将其统一集成到CF 框架中。Wang 等在DKN(Deep Knowledge aware Network)中将实体嵌入和单词嵌入视为不同的渠道,并通过TransD(Translating embedding via Dynamic mapping matrix)生成新闻嵌入以供推荐。鉴于推荐任务和KGE 任务的高度相关性,Wang 等提出了一种交替学习两种任务的推荐框架。和基于嵌入的方法直接利用KG 中的内容信息不同,另一类研究强调学习KG 中的结构信息,例如:PER(Personalized Entity Recommendation)引入元路径来定义图中路径表示,并利用实体间的连接相似性来提供推荐。Hu 等在FMG(Factorization Machine with Group least absolute shrinkage and selection operator)中建议使用元图来替代元路径,以提供更丰富的连接信息。
综合上述方法,为了充分发挥KG 的有效性,研究者提出了结合内容信息和结构信息的统一方法。这类方法最早在Wang 等的RippleNet(Ripple Network)中得到探索,其借鉴GraphSAGE(Graph SAmple and aggreGatE)中的消息传递模式,首次提出了偏好传播的概念。具体来说,RippleNet 以用户的历史交互节点作为种子集,在KG 中向外扩散并吸收多跳的邻居信息,最终得到更深层次的用户潜在兴趣。同样基于传播的思想,Wang 等提出了一种融合KG 特征与图卷积网络的模型,采用图卷积网络通过KG 中的邻居获得项目嵌入,这使得邻居的信息能够导致推荐任务完成质量的巨大提升。KGAT(Knowledge Graph Attention Network)提出了协作知识图,将用户项二部图与知识图结合在一起,通过GNN 和注意机制在KG 上递归地执行传播来优化实体嵌入。Wang 等通过异构传播分别编码用户交互和辅助信息。鉴于GNN 在信息传播和推理上的自身优势,这类方法能更有效地在推荐任务中引入KG 中的信息。
本文在利用图卷积来优化实体嵌入的基础之上,提出了无采样策略,并与用户交互中的协作信号相结合,以提升推荐结果的准确性。
1.2 图神经网络的应用
本文的方法在概念上启发于图神经网络,并将其扩展为适用于知识图谱的无采样图模型。图神经网络作为当下热门的深度学习模型,在处理复杂的图结构数据时显示出巨大的优势。在早期的关于图神经网络的研究中,诸如图卷积网络(Graph Convolution Network,GCN)、图注意网络(Graph Attention Network,GAT)等模型在训练时使用全批次梯度下降的方法,图中数量庞大的邻居信息和节点特征导致了巨大的内存成本和计算复杂度。为了解决传统方法中可扩展性问题,Hamilton 等在GraphSAGE 中首次提出了结合邻域采样和小批次训练的策略。其核心思想是从训练节点开始,在每一跳随机采样固定数量的邻居节点,持续L
跳,并以节点为中心进行小批次训练。然而,GraphSAGE 在随机采样时部分节点重复出现,可能会增加冗余计算量。为了解决这个问题,不少后续模型集中于研究先进的采样策略,如ClusterGCN(Cluster Graph Convolution Network)和RSage(Recurrent Sampling to gather neighbor nodes)。尽管采样策略有效降低了模型的计算复杂度,但同时也引入了额外的误差,这也是本文的模型重点关注的问题。在一个主流的推荐系统中,假设用户集合U
={u
,u
,…,u
}和项目集合V
={v
,v
,…,v
}。根据用户和项目的历史交互,定义用户反馈矩阵为Y
,其中y
=1 表明用户与项目间存在反馈行为,如点击、转发、评分等,否则为0。但是需要注意,y
为0 并不完全意味着用户对该项目不感兴趣。此外,给定项目知识图谱G
={(h
,r
,t
)|h
,t
∈K
,r
∈R
},其中每个三元组表示实体h
和实体t
间存在关系r
,K
和R
分别对应于实体和关系集合。例如,三元组(刘亦菲,演员,花木兰)陈述了刘亦菲是电影《花木兰》的演员的事实。在实际推荐场景中,项目V
可能与G
中的一个或多个实体存在映射关系。例如,图书《傲慢与偏见》与KG 中的一个实体同名,而标题为“刘亦菲出席花木兰首映礼”的新闻则于“刘亦菲”和“花木兰”多个实体有关。使用A
={(v
,e
)|v
∈V
,e
∈K
} 来表示存在映射关系的集合,其中(v
,e
)表明项目v
可以与知识图中的实体e
对齐。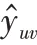
3.1 整体框架
本节详细介绍了所提出的NCKN 模型的架构,如图1 所示,模型分为四个模块:1)嵌入层:通过知识图嵌入方法学习KG 中实体和关系的嵌入向量;
2)无采样知识传播层:在KG传播过程不进行选择性采样,利用单个图卷积层预聚合全部的邻居信息,更新节点特征;
3)协作传播层:将用户交互中的关键协作信号编码为用户和项目的初始偏好,并同KG 中的辅助信息相结合;
4)预测层:依据最终的用户和项目向量,输出预测结果。
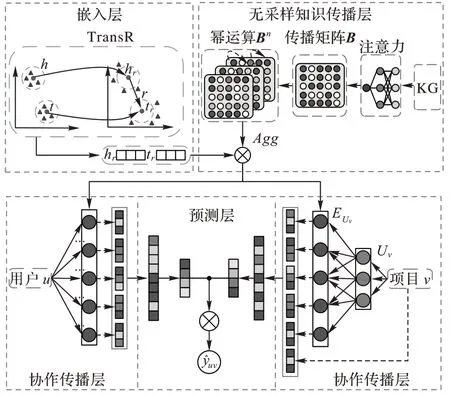
图1 NCKN模型框架Fig.1 Model framework of NCKN
3.2 嵌入层
在保持原有图结构的前提下,利用知识图嵌入方法将KG 中的实体和关系转换为低维的向量表示。在该模块,本文使用了具有良好表现的TransR方法。具体来说,对于每个三元组(h
,r
,t
),考虑到同一关系对应的实体具有不同层面的信息,它将实体和关系分别建模到两个不同空间。其可信度评分函数如式(1)所示: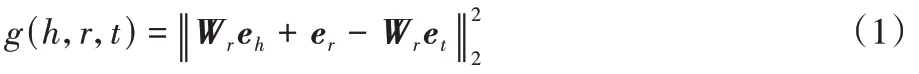
e、e
、e
分别是h
、r
、t
的嵌入向量表示;W
为关系r
的转换矩阵。g
(h
,r
,t
)的值越低意味着三元组的可信度越高;反之,三元组的可信度越低。
损失函数如式(2)所示:
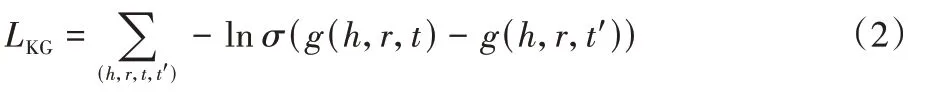
h
,r
,t
′)为对真实三元组(h
,r
,t
)进行随机替换生成的负样本;σ
(·)为Sigmoid 函数。3.3 无采样知识传播层
接下来,本文基于图卷积网络的架构,将不同大小且固定的线性聚合器结合在单个卷积层,便于进行高效的无采样预计算。此外,考虑到实体之间连通性的重要性不同,在传播过程中引入了注意力机制。
请注意,不同于堆叠多个卷积层的深度图神经网络,本文的方法仅通过单个卷积层进行预计算。尽管只使用了浅层的网络,NCKN 通过设计更有效的传播矩阵且考虑所有邻居信息,实现了和深层网络相当的性能。具体来说,该层由三个组件组成:注意力、信息传播、邻居聚合。
3.3.1 注意力
通过关系注意力机制实现π
(h
,r
,t
),如式(3)所示。tanh 是非线性激活函数,注意力分数由关系空间中e
和e
的距离决定。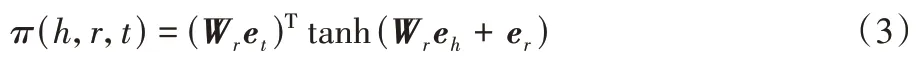
N
为以实体h
为头节点的三元组集合。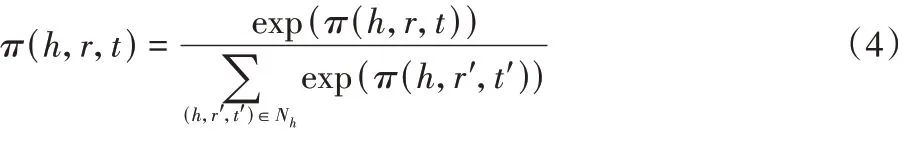
值得注意的是,为了不破坏图聚合操作时高效的预计算,本文方法仅通过训练图的一个小子集来预先确定注意力参数,然后固定它们计算出训练中所使用的传播矩阵。对于注意力模块的进一步改进将作为未来需探索的工作。
3.3.2 信息传播
KG 中的实体和邻居之间有着不同程度的关联性,为了有效扩展用户和项目的潜在偏好,本文在传播过程中考虑节点的高阶邻居信息。如式(5)所示,根据固定的注意力参数,计算出初始传播矩阵。

B
,图操作有效地获取n
跳以内的邻域信息。为了权衡实体邻接信息的完整度与计算邻接矩阵所需时间,设置n
最大值为3。3.3.3 邻域聚合
如式(6)所示,通过在单个卷积层使用不同大小的线性聚合器来捕捉深层次的信息,实现高效的无采样预计算。例如,在线性聚合器CX
中(X
为节点特征矩阵),设置不同幂级数的传播矩阵(C
=B
,C
=B
,…,C
=B
),并将其连接。这个思想类似于卷积神经网络中的初始模块(在同一卷积层结合不同大小的卷积核)。由于CX
可以预计算,该方法考虑传播过程中的所有邻居信息而不进行选择性采样。
3.4 协作传播层
与传统推荐算法中使用独立的潜在向量不同,本文在协作传播层中同时获取用户和项目的初始偏好,以便于同知识嵌入结合得到用户和项目的扩展偏好。
直观来说,用户的历史交互项目能一定程度上表示该用户的偏好。通过将用户历史交互中的相关项目集与KG 中的实体对齐,转换为在KG 中计算的特征集。用户的特征集定义为:
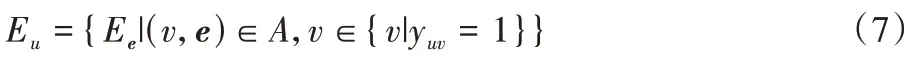
对用户的特征集归一化:

V
为项目v
的协作项目集,表示形式如式(9)所示: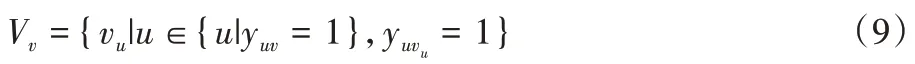
v
的特征集为: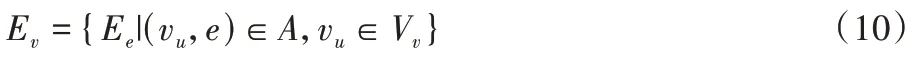
对项目的初始集归一化并加上项目自身对齐实体的特征:
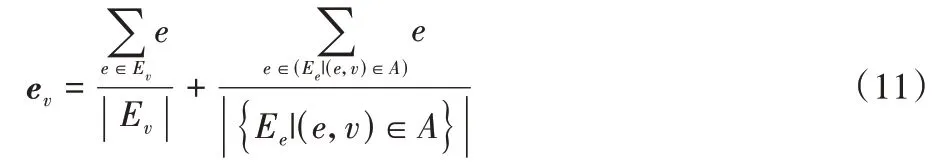
3.5 预测层
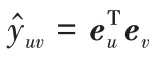
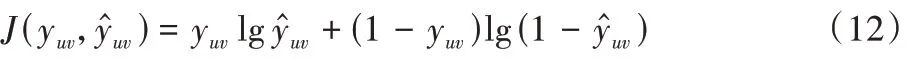
Loss
计算如式(13)所示。其中P
为正样本,P
为负样本。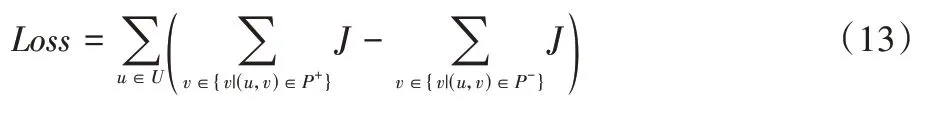
本章将针对音乐、书籍和电影三个真实数据集来评估模型性能,探讨以下研究问题:
1)与已有的基于知识图谱的推荐算法相比,本文提出的模型表现如何?
2)模型中的关键组件和参数设置如何影响推荐结果?
4.1 数据集
本文使用以下三种真实数据集评估模型性能:Last.FM(Music)、Book-Crossing(Book)、MovieLens-20M(Movie),表1给出了相关统计信息。三个数据集均允许公开访问,且规模和稀疏性有所不同。

表1 实验数据集统计信息Tab 1 Statistical information on experimental datasets
1)Last.FM:由Last.FM 在线音乐系统提供的用户听歌行为和项目知识。
2)Book-Crossing:从图书社区统计的读者评分数据(0 到10 不等)。
3)MovieLens-20M:是一个被广泛使用在电影推荐领域的测试数据集,文件中包含了在电影网站上的反馈信息,即用户对每部电影的明确评分(从1 到5 不等)。
鉴于隐式反馈能提供更丰富的交互内容,有利于缓解冷启动问题,本文首先在数据预处理部分将显式反馈转换为隐式反馈。其中1 表示用户正面评分的样本,而0 为从未交互集合中随机采样的负样本。Last.FM 和Book-Crossing 的交互数据稀疏,故未设阈值,MovieLens-20M 正面评分阈值设置为4。
除了对用户和项目的交互数据进行预处理,本文在MicrosoftSatori 中生成每个数据集的项目知识图谱。具体来说,首先从整个KG 中提取置信度高于0.9 的三元组作为子KG。对于确定的子KG,通过匹配头节点和尾节点的名字来收集全部有效的实体id。最后,将项目id映射到KG中的实体中,并在子KG 中匹配对应的三元组集。请注意,为了简化整个过程,本文将排除不存在匹配或存在多个匹配的项目。
4.2 对比算法
BPRMF(Bayesian Personalized Ranking optimizations for Matrix Factorization):一种采用矩阵分解进行优化的经典CF 方法。
CKE(Collaborative Knowledge base Embedding):将CF和多种知识图融合进行训练,分别提取了项目知识图谱中的结构信息、文本信息和视觉信息的特征嵌入。本文仅将结构知识同CF 结合。
PER:利用项目知识图谱中的关系异构性,引入元路径来表示不同关系路径中用户和项目的连通性,并基于路径相似度来推荐项目。本文将元路径定义为项目―属性―项目属性。
RippleNet:最近提出的基于偏好传播的模型。通过将用户历史交互项作为KG 传播中的初始集,在KG 中扩散并聚合多层邻居信息,得到更深入的用户潜在偏好表示。
知识图卷积神经网络(Knowledge Graph Convolutional Networks,KGCN):最先进的将KG 与图卷积神经网络融合的模型,利用图卷积从知识图的邻居中获得丰富的项目嵌入,导致推荐任务完成质量的巨大提升。
KGAT:也是最先进的融合图卷积网络的模型。它将项目知识图和用户交互数据结合组成协同知识图,并在该图结构上递归传播邻居来更新目标节点的嵌入。另外在传播期间使用注意力机制来区分邻居节点的重要性。
4.3 实验设置
对每个数据集,按照7∶2∶1 的比例随机划分为训练集、测试集和验证集。具体来说,针对所选数据集的大小,首先采用保留法将数据集划分为训练集和测试集,通常情况下(非大规模数据集)为8∶2。其次,为了更好地检验模型训练程度,会从训练集中划分一小部分为验证集,即最终比例为7∶2∶1。本方法在以下两个推荐场景中进行评估:1)CTR(Click Through Rate)预测,在训练完成的推荐模型中预测特定用户和项目间的交互概率。2)Top-k
推荐,使用从训练集学习到的推荐模型来选择测试集中指定用户预测概率最高的k
项物品。为了验证这些方法的有效性,本文应用了以下评估指标:1)Precision
:模型推荐项目的准确率。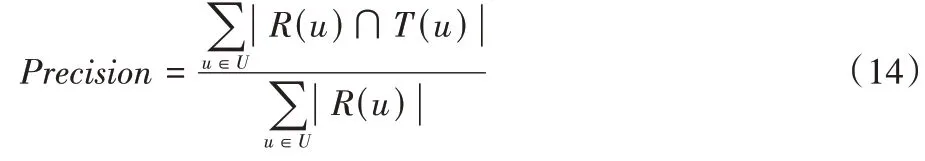
R
(u
)为根据训练集对用户推荐的项目列表;T
(u
)为根据测试集对用户推荐的项目列表。2)Recall
:候选推荐列表的命中率。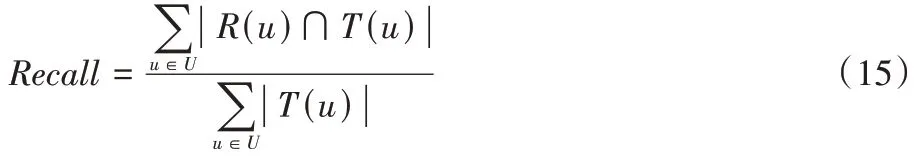
F
1:Precision
与Recall
的加权结合,F
1 的值更能体现模型的性能。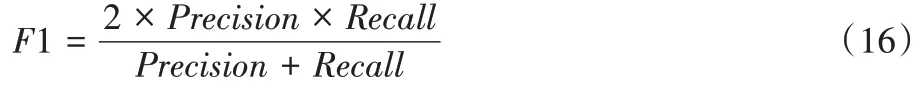
AUC
:用于评估推荐系统将用户喜欢和不喜欢的商品区分的性能。a
为用户喜欢的商品,b
为用户不喜欢的商品,每次比较推荐系统对a
和b
的打分,m
为比较的总次数,m
′为a
的评分大于b
的评分的次数,m
″为a
的评分等于b
的评分的次数,AUC 计算公式如式(17)所示。
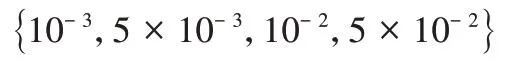
4.4 实验结果对比
在CTR 和Top-k
中的预测结果分别如表2 和图2 所示。根据实验结果,有以下关键结论: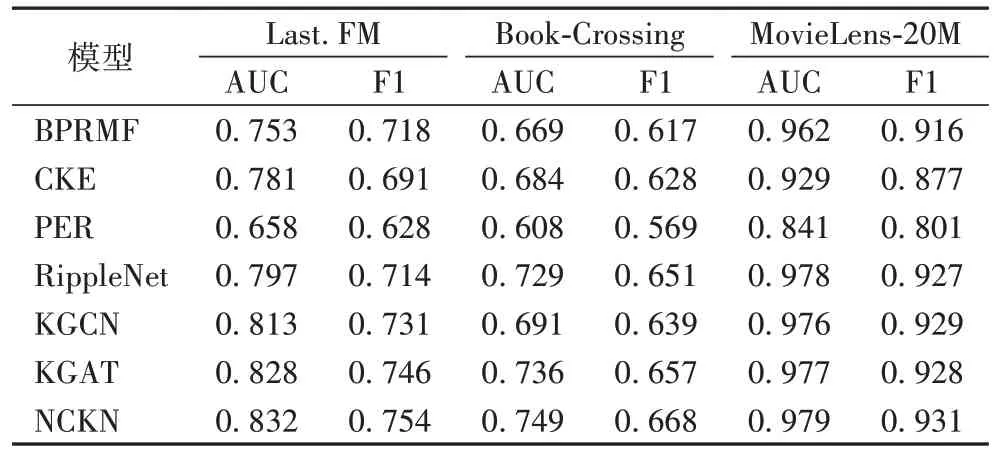
表2 基于AUC和F1指标的CTR预测结果Tab 2 CTR prediction results based on AUC and F1 metrics
从图2 中的结果来看,基于KG 的推荐方法远远优于基于CF 的方法(BPRMF),这说明引入KG 中的额外信息对推荐方法性能有很大的提升。但是,在个别指标上BPRMF 的性能超过了CKE,这表明仅建模KG 中的一阶关系可能无法充分发挥KG 的作用,这同时也验证了NCKN 聚合来自多层高阶邻居信息的有效性。

图2 基于Recall@k指标的Top-k预测结果Fig.2 Top-k prediction results based on Recall@k metric
NCKN 在CTR 预测中取得了显著的结果,基于三个数据集都表现最佳。基于Recall@k
的Top-k
预测中,KGAT 在音乐和图书数据集中性能表现优越,但值得注意的是,在电影数据集中,本文方法NCKN 性能超越了KGAT。本文的推断是:当数据集规模较小且稀疏性大时,KGAT 能作出更准确的预测;但是对于大规模且信息更稠密的电影数据集,KGAT在用户交互图中的高阶传播会引入过多的噪声,而NCKN 使用一阶协作信号和KG 相结合取得了更佳的效果。
通过观察发现所有的方法在三个数据集上的性能排名分别是电影、音乐、书籍。这可能是三个数据集上的用户平均交互数量和KG 中实体的平均链接数量不同导致的。例如,相较于音乐数据集和图书数据集,电影数据集具有更多的交互行为和关系链接数量,其丰富的信息可供推荐模型更准确地学习潜在的特征表示。
与所有的对比方法相比,本文提出的NCKN 在三个数据集上都取得了竞争优势。具体来说,在CTR 预测中,与主流算法RippleNet、KGCN 相比,NCKN 在指标AUC 下平均分别提升了2.71%、4.60%;在F1 指标下平均分别提升了4.17%、3.28%;
在Top-
k
中,NCKN 在电影和书籍数据集中平均提升了5.26%、3.91%。。请注意,NCKN 在音乐数据集上表现不足但仅次于KGAT,因为音乐数据集中KG 平均链接数量太低,NCKN 中的无采样策略无法发挥其最佳效果。与RippleNet 相比,证明了NCKN 不使用采样策略和协作传播的积极意义。4.5 消融实验
本节对模型所涉及的关键参数和方法进行分析。NCKN的特色在于协同传播层和无采样知识图传播层的设计。为了验证这些方法的有效性,进行了消融实验。
本文分别对嵌入向量的维度和传播的最大层数进行参数分析。具体来说:
1)在三个数据集上使用不同维度的嵌入来探索其对于模型的影响,图3(a)显示了直观的结果:在一定范围内,随着嵌入维度d
的增加NCKN 的性能也得以提升,但超过某个值后,性能逐渐下降。这是因为当d
过大时,可能出现过拟合问题。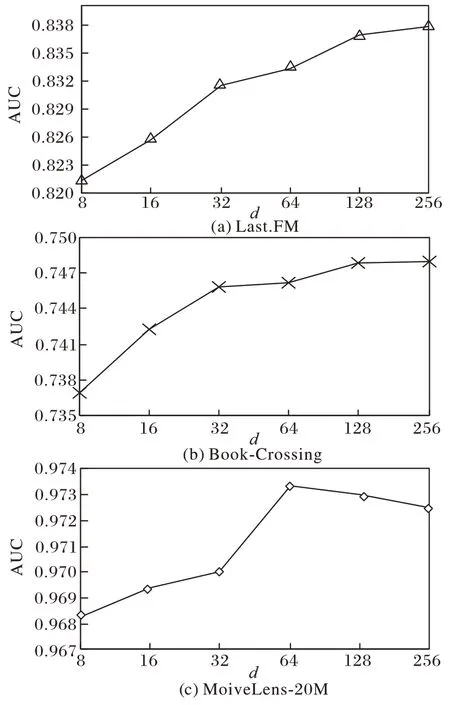
图3 基于AUC的嵌入维度影响Fig.3 Impact of based on AUC embedding dimension
2)为了探索KG 中聚合不同层数的邻域信息的影响,设置信息传播n
跳的最大层数,以研究模型的性能会如何改变。图4 为不同传播层数的实验结果,可以观察到:音乐、书籍、电影分别为3、3、2 时达到最优性能。对这个结果的合理解释是,高阶的邻域信息补充更丰富的潜在信息,但同时也引入了更多噪声,特别是对于数据量很大的电影数据集,合理的传播层数能发挥最佳的效果。
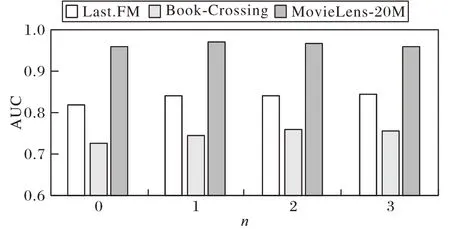
图4 基于AUC的传播层数的影响Fig.4 Impact of number of propagation layers based on AUC
为了证明协作传播层和无采样知识传播层的有效性,本文在模型中使用了两种变体:1)对于协同传播层,采用两层协作传播的变体来进行对比实验,它被称NCKN;
2)对于无采样知识传播层,使用随机采样固定数量邻域节点的变体NCKN来观察模型的表现能力。表3 的结果表明:在三个数据集上,NCKN 的一阶协作传播层比两层协作传播变体具有更优的性能。这说明用户交互中相互作用的模糊性,更高阶的协作传播反而带来了更多的噪声。用户一阶的交互项目能最准确地表示其偏好;
而采用无采样策略的模型相较于使用随机采样策略也取得了优势,这支持了采样机制可能会带来误差的前提。

表3 基于AUC的协作传播和无采样知识传播模块消融实验结果Tab 3 Experimental results of AUC-based ablation of collaborative dissemination and non-sampling knowledge dissemination modules
本文提出了一种无采样协作知识图网络NCKN。NCKN通过单层图卷积网络无采样地预聚合多层邻域信息,并将学习到的KG 嵌入和用户交互中协作信号相结合。
本文考虑在以下两个方面展开未来的工作:1)由于本文专注于研究无采样策略的应用,进一步的研究方向是设计出一个更好的方法融合注意力机制,能够更准确地利用邻域信息;
2)本文的模型为现实场景中的其他辅助信息提供了一个新的思路,比如可以尝试应用于社交网络来提高推荐性能。