基于数据挖掘的在线学业拖延精准识别及干预实证研究
来源:新东方在线 发布时间:2023-01-22 点击:
胡 琼,姜 强,赵 蔚
(东北师范大学,吉林 长春 130117)
学业拖延是指个体推迟了需要完成的学习任务,最后导致时间不充裕,只能在提交期限前匆忙应付的行为[1]。来世不可待,往事不可追,古今中外拖延现象都是制约人类发展与进步的屏障,据调查显示,至少50%以上的大学生存在学业拖延行为,且这种现象还在持续增长[2-3]。关于拖延带来的危害,古圣先贤早已有所认识,逝者如斯夫和万事成蹉跎的告诫犹在耳边。然而,时至今日,该现象仍普遍存在,其产生的时间压力会降低提交任务的准确性和准时性,不仅会对学业绩效产生负面影响,还会引发疲倦、内疚、焦虑等负面心理体验,对学生的身心健康产生不利影响[4-5]。Paglieri在《Nature》上发表的文章中将拖延描述为流行性病毒,会让个体远离家人和朋友感受孤独,难以按时完成任务,充满负罪感[6]。Fritzsche等发现,学业拖延会降低学生的学业成绩和主观幸福感[7]。Grunschel等研究表明,拖延行为会伴随产生焦虑、愤怒、压力、内疚和不安等情绪,严重者还可能引发睡眠问题或其他疾病[8]。国内学者冯廷勇等也对拖延现象多有关注,探究了拖延形成的认知机制和神经基础[9]。上述内容都说明了关于拖延问题的研究具有重要的科学意义和价值。
精准识别学生的学业拖延倾向是研究的首要问题。目前,识别拖延行为的研究并不存在公认的标准去划分拖延者和非拖延者。现有研究大多采用问卷调查法对学生的拖延倾向进行识别,常见的测验量表包括一般拖延量表(General Procrastination Scale)[10]、Aitken拖延问卷(Aitken’s Procrastination Inventory)[11]和学生拖延评定量表(Procrastination Assessment Scale-Student)[1]等。然而,问卷调查法往往会出现答卷者高估自己的拖延倾向,导致识别结果出现偏差[12]。尽管少量研究尝试采用日记研究法和观察法对拖延行为进行识别,但此类方法存在花费人力物力过多的弊端,难以推广使用。近些年,教育数据挖掘带给在线教育进一步发展的可能,Smith等提到了复杂性网络中大规模数据挖掘的必要性[13]。学生的在线学习行为可以被量化,大量繁杂的数据背后预示着学生在课程中未来的发展走向,收集和分析这些数据,可以精准地挖掘学生的学习行为倾向[14]。
本研究使用教育数据挖掘技术,探索一种精准的方法去识别在线学生拖延倾向,并结合支持向量机、决策树、神经网络、朴素贝叶斯、随机森林和贝叶斯网络六种算法,验证了该方法对学生拖延倾向识别的精准性。最后,结合时间决策模型,对存在学业拖延风险的学生实施个性化教学干预,以减缓学生的拖延倾向。一方面,研究提出的在线学业拖延识别方法能够精准地依据拖延倾向对学生进行划分类别,有助于相关从业者及早发现存在潜在拖延风险的学生;
另一方面,研究验证了早期干预对于学业拖延的有效性,并提供了易行的干预策略。
(一)拖延内涵
拖延在英文中对应的单词是Procrastination,意思是“推迟到明天”,属于中性词。拖延既可能是消极的,也可能是明智的选择策略[4]。但在英国工业革命后,随着人们生活节奏的加快,拖延逐渐被赋予了消极和懒惰的意思。现代汉语词典将拖延界定为“延长时间,不迅速办理”。
从认知和情绪的角度看,简·博克和莱诺拉·袁在《拖延心理学》一书中提及,拖延是个体无理性延迟完成任务,并伴随产生焦虑等不良情绪[15];
Solomon等认为,拖延是个体感受到任务所带来的不适而产生的不必要延迟[1]。从行为角度看,Lay认为拖延是个体延迟必须完成任务的行为[10];
Tuckman将拖延解释为个体推迟或回避计划的行为[16]。另外,也有研究者将拖延视为一种人格特质,如Ferrari认为拖延是个体经常性的、有意的、非必要的延迟开始或结束本应按时完成的任务[17]。其中,最广泛使用的概念是Steel提出的“尽管预期到了拖延会带来更糟的结果,还是自愿推迟预定的行动路线”[2]。本研究将拖延视为一种消极活动,通常以故意和习惯性延迟任务的形式出现,表现为一个人采取行动的意图与观察到的行动表现之间存在的差异[18]。
(二)拖延行为的产生机制
从拖延内涵的多维度不难发现,拖延产生的内部心理机制是极为复杂的。关于此,心理学的不同流派也一直有着不同的见解。从心理动力学的角度看,拖延是个体对死亡本能的抗争和回避无意识死亡焦虑的一种方式[19]。站在行为主义的角度,人类的行为可以因完成任务受到的奖惩而得到强化,因此许多研究者认为拖延是一种习得的习惯,人们倾向于回避厌恶刺激,进而产生了拖延现象[2,20]。认知心理学则认为,拖延是一种应对策略,个体通过这种策略来逃避面对能力缺乏的状况以维持自尊。并在此基础上提出了时间动机理论[21]和时间双维模型[22],从时间角度解释拖延,当个体感受到任务的枯燥无趣、没有价值或目标时间较远时,个体的动机较弱,进而产生拖延行为。
(三)拖延行为与学业表现的关系
无论是在日常教学中,还是在网络学习中,拖延行为都会对学生的学业表现产生一定的负面影响,能够间接预测在线学习投入[23]。具有拖延行为的学生通常会低估完成任务所需的时间,导致没有足够的时间完成任务,最终表现为学业目标和学业成绩的下降[24]。在网络学习环境中,备受关注的高辍学率也与拖延行为相关,25%的学生由于自制力差或拖延症影响了学习进度[25]。大部分学生并未遵守课程的时间安排,而是在考试当天或前一天访问课程,最终影响了学业成绩[26-27]。此外,研究表明拖延行为还对学生的自我效能感、学业情绪等多种学业表现产生消极影响[28-29]。
(四)拖延行为的干预
由于拖延行为与学业表现关系密切,因此如何干预拖延行为从而规避学业风险也是研究的重点。从心理学理论的视角看,拖延被视为一种习得性习惯,从治疗的角度降低学生的拖延倾向。例如,钱铭怡团队[30]和鲍威团队[31]都验证了团体干预对于拖延行为改善的有效性;
赵洪等发现箱庭疗法对于治疗拖延行为是有效的[32];
张泽仑等发现焦点解决短程集体咨询能够改善拖延行为[33];
倪士光等建立起了学习拖延的整体化工作机制模型,提出了养成学习习惯、提高自我效能感、利用团队影响三种方案干预学业拖延[34]。从教育实证研究出发,注重数据的挖掘,将拖延行为聚焦于某门课程,如杨雪等通过实验,验证了电子邮件、学业资源推送、电子徽章等干预措施的有效性[35-36]。也有学者认为,由于教师难以正确分析学习者学业失败的真正原因,因而采取的干预措施效果不佳,如Iryna等研究发现,使用电子邮件实施干预时,复杂的个性化建议会使结果适得其反[37]。
另外,值得关注的是,目前评估学生拖延倾向通常采用量表测评的方法,研究结果的准确性存在偏差[12]。变革教育需要科学依据,教育数据挖掘具有从繁杂的数据中发现教育规律、促进科学决策等优势,可以通过对零散的数据进行整合,精准地对教育的各方面进行分析,使相关从业者能够更加及时地了解信息,推动教育朝着更加科学、智能和个性化的方向发展[38-39]。因此,本研究基于学生在线作业提交数据,采用教育数据挖掘技术设计在线学业拖延识别方法,并结合神经网络、决策树等算法验证该方法的精准性。为进一步探究早期干预能否改善学生的拖延倾向,依据识别结果,以时间决策模型为理论基础,对存在学业拖延的学生实施个性化教学干预,探究研究成果是否有助于减少学生的拖延倾向,规避学业风险,本文提出以下两个研究问题。
(1)在线学业拖延识别方法对于学生拖延倾向划分的精准性如何?
(2)基于时间决策模型的早期个性化干预能否减缓学生拖延倾向?
利用教育数据挖掘技术,在线学业拖延识别方法包括数据采集与预处理、构建学生拖延行为变量和学生的学业拖延倾向聚类等。其中,数据采集与预处理是指结合实证案例,将研究需要使用的学生活动数据从学习管理系统中提取出来,并对采集的活动数据进行清洗和变换,为下一个阶段研究提供数据支撑。构建学生拖延行为变量是指,构建方法借鉴Hooshyar等设计的算法,利用作业发布时间、学生首次查看作业时间、学生提交作业时间和作业截止时间四个变量构建学生作业提交行为的数据集[40]。学生的学业拖延倾向聚类则是选取合适的聚类数,借助K-Means算法对数据集中的作业提交行为进行聚类。
(一)数据采集与预处理
实验数据提取自Moodle平台中东北某大学2020级教育技术学专业学生在“网页设计与开发”课程的活动数据,共有71名学生,数据集涵盖课程1—8周的4次作业任务。授课教师将Moodle平台作为课下与学生互动的手段,要求学生通过平台进行各种在线活动,包括提交作业、同伴评价和自我评价等。其中,每项作业都有教师设定的发布时间和截止时间,学生需要在对应的时间内完成和提交作业。本研究中收集的数据集包括作业发布时间、学生首次查看作业时间、学生提交作业时间和作业截止时间四个变量。
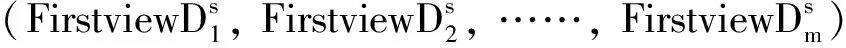
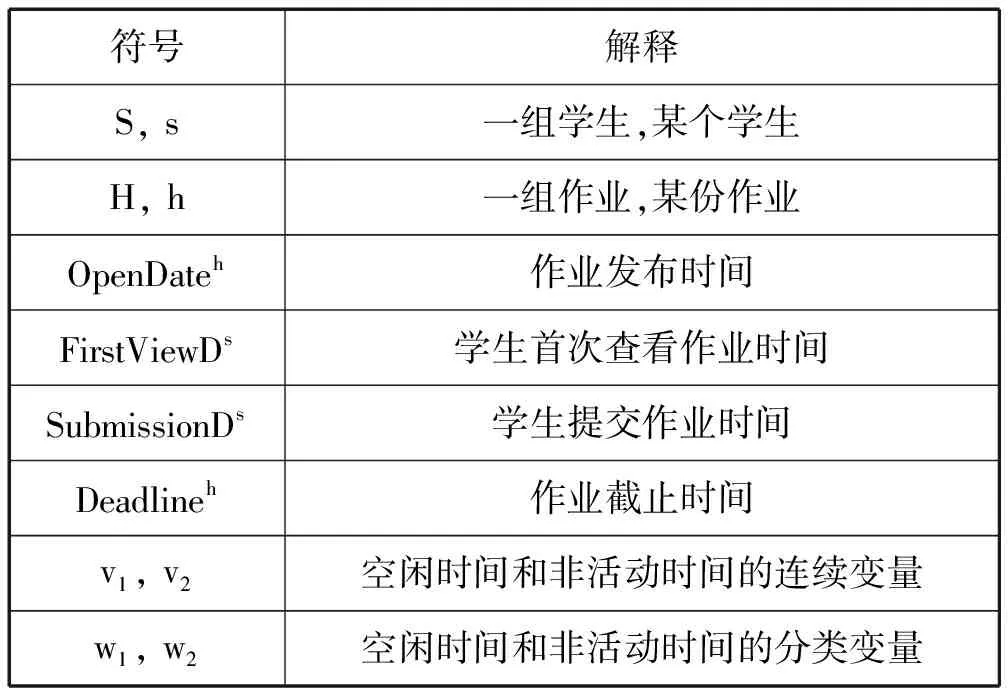
表1 符号解释
(二)构建学生拖延行为变量
每项作业的赋值包括两个变量,即空闲时间和非活动时间的连续变量或分类变量,如公式(1)和(2)所示。将所有作业集合在一起,构建出所有作业的连续变量或分类变量,如公式(3)和(4)所示。
xi=(v1, v2)
(1)
yi=(w1, w2)
(2)
Xj=(x1j, x2j, ……, xij)
(3)
Yj=(y1j, y2j, ……, yij)
(4)
关于变量X和Y的构建算法,如表2所示,需要输入OpenDateh、FirstViewDs、SubmissionDs和Deadlineh四个变量,使用到的变量i和j分别代表作业数量和学生总数,v1和v2分别代表学生的空闲时间情况和非活动时间情况。接着,根据空闲时间情况标记w1是1或0,代表作业是否准时提交。最后,每个学生的非活动时间与非活动时间的中位数作比较,标记w2为1或0,代表学生所用非活动时间较短或较长。

表2 变量X和Y的构建算法
(三)学生的学业拖延倾向聚类
聚类是将一个个数据点划分为若干组的过程,其中相似的数据点被划分在一起。该环节将算法中输出的X和Y进行分组,即将提交作业行为相似的学生划分为一组。研究使用K-Means算法对学生提交作业的行为数据进行聚类分析。该算法需要预先设定聚类数k,确保簇内的相似度较高,而各个簇之间的相似度较低。根据先前的研究,拖延行为划分为3类较为合理,因此本研究选取聚类数k为3[37],聚类结果如图1所示。对于连续变量来说,集群1具有高非活动时间、无空闲时间的特点,说明此类学生查看、得知作业的时间晚,作业提交时间可能超出了提交截止时间,具有强拖延倾向;
集群2具有非活动时间低、空闲时间低的特点,说明此类学生虽然查看作业的时间较早,但提交作业时间与作业提交截止时间距离较近,具有弱拖延倾向;
集群3具有非活动时间中等、空闲时间高的特点,说明此类学生查看作业、得知作业内容的时间位于班级的中等位置,提交作业的时间较早,基本不存在拖延倾向。对于分类变量来说,集群1和集群2均具有非活动时间高、空闲时间低的特点,说明此类学生查看作业的时间较晚,提交作业的时间与作业截止时间的距离较近,具有弱拖延倾向;
集群3具有非活动时间低、空闲时间高的特点,说明此类学生查看作业的时间较早,作业的提交时间也较早,基本不具有拖延倾向。可见,聚类的过程中连续变量表现良好,各簇之间区分度更好,而分类变量簇与簇之间相似,区分度不大。
(四)学业拖延识别方法的精准性验证
目前,数据挖掘领域常用的分类算法包括支持向量机(SVM)、决策树(DT)、神经网络(NN)、朴素贝叶斯(NB)、随机森林(RF)和贝叶斯网络(BN)等。本研究选取以上六种主流算法对学生拖延倾向划分的精准性进行验证,使用真正率(TP)、假正率(FP)、精度(Precision)、召回率(Recall)和F度量(F-measure)作为评价指标,相关计算公式如表3所示。此外,研究在分类的过程中使用10折交叉验证方法,以测试学业拖延识别方法的精准性。

表3 评价指标
将上一阶段学生行为的聚类结果,使用不同分类器进行预测,结果如表4所示。可以看出,无论是使用连续变量还是分类变量,六种分类器的预测精度均达到了70%以上,其中支持向量机效果最佳(达到93%以上),其次是朴素贝叶斯和贝叶斯网络(均达到80%以上),说明了在线学业拖延识别方法的有效性。

表4 不同分类器预测结果
识别学生的在线学业拖延倾向只是研究的开端,最终的目标是帮助他们降低这种可能存在的风险。为探究早期的干预能否减缓学生的学业拖延倾向,研究继续对学生实施干预实验,9—16周为干预实验周,平均每两周提交一次作业。
(一)学生在线学业拖延倾向识别
将非干预周的作业发布时间、学生首次查看作业时间、学生提交作业时间和作业截止时间代入算法,提取输出的变量X,将聚类数k设定为3,使用K-Means算法进行聚类,得到的结果如表5所示。与集群1和集群2相比,集群3中学生的非活动时间较低(v1-avg=0.597),空闲时间较高(v2-avg=0.123),此类学生不存在拖延倾向。集群1中的学生非活动时间占比高(v1-avg=0.948),而空闲时间较低(v2-avg=-0.410),其中部分同学由于未在规定时间内提交作业,空闲时间甚至达到负数,将其认定为具有强拖延倾向。集群2中学生的非活动时间和空闲时间均介于集群1和集群3之间(v1-avg=0.423,v2-avg=0.069),认定为具有弱拖延倾向。
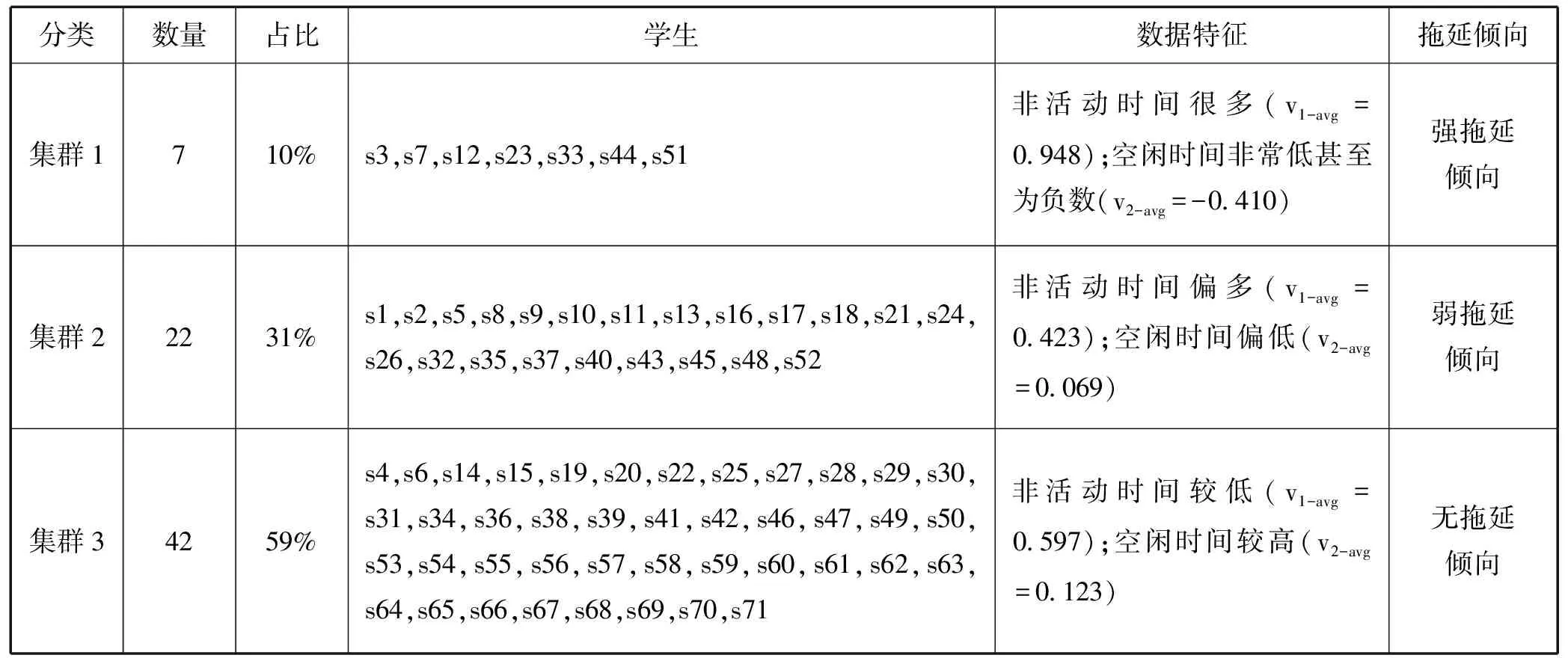
表5 非干预周学生拖延行为聚类结果
(二)基于时间决策模型的干预方法
实验的干预方法以时间决策模型为理论基础。该模型认为,任何拖延行为产生前都需要回答“现在做还是以后做”的问题,所以拖延行为实质上是一个决策问题[41]。该模型提出,是否在某一时间点t执行任务的决策取决于两方面,一是个体在时间点t执行任务的主观体验(愉快或不愉快),二是个体在时间点t对任务远期结果的主观价值。在公式(5)中,E代表期望,V代表价值,Γ代表个体对延迟时间的敏感性,D代表延迟时间,Dengagement表示时间点t与当前时间的间隔,Doutcome表示时间点t与结果兑现日期的时间间隔。当任务被决定延迟后,当下时间与执行任务之间存在时间间隔,因此个体感受到的执行效用也被延迟的时间折扣。而个体对于延迟时间的敏感性将决定个体执行效用的折扣速率。该模型赋予增加执行意愿的效用为正号,减少执行意愿的效用为负号。鉴于只有任务能带来有利结果但执行体验并不愉快,才会产生拖延行为[42]。因此,时间决策模型在解释拖延行为时,主要关注负执行效用、正结果效用的任务,如公式(6)所示。该模型一方面有助于理解拖延行为产生的原因,另一方面也有助于提出干预策略。
(5)
(执行效用) (结果效用)
(6)
(结果效用) (任务厌恶)
在此基础上,实验并行使用学习分析仪表盘自我调节干预和教师干预两种干预方法,干预流程图如图2所示。
根据在线学业拖延识别方法判定学生的拖延强度,可以将学生划分为强拖延倾向、弱拖延倾向和无拖延倾向三类。无拖延倾向的学生直接进入下一轮识别,不实施干预,而具有拖延倾向的学生,采用告知所处风险等级,并结合先前的数据分析结果和时间决策模型来设计学习分析仪表盘和教师的消息提醒,随任务每两周向学生发布一次。其中,学习分析仪表盘主要向学生展示总体概况、学业拖延风险评估、待处理学习任务进度和作业提交情况四个部分,如图3所示。
总体概况显示了学习频率星级评定、学业拖延状态评估和简单的个性化建议,帮助学生迅速了解自己的学习状态;
学业拖延风险评估中,可以根据指针了解自己拖延强度的大小;
待处理学习任务进度中,可以查看自己未完成的作业、评价和测试的提交情况以及班级内同学的完成率,利用同伴的影响力,督促学生完成学习任务[43];
在作业提交情况中,学生可以查看所有的作业提交和评价状态,借助提交的“旗子标识”更加直观地观察开始时间、提交时间和截止时间之间的间隔,从内部驱动学生完成学习任务[44]。
具有强拖延倾向的学生可以按照查看作业的时间划分为两类,针对查看作业时间较晚而导致拖延的学生,在教师信息提醒中标注时间,以提升学生对延迟时间的敏感性(Γoutcome);
针对查看作业较早但仍拖延的学生,在教师信息提醒中提及本次任务的价值和难度情况,帮助学生提高对任务价值(Voutcome)的认识和期望(Eoutcome)水平。针对弱拖延倾向的学生,采用告知其存在的学业风险,并提示其进行时间管理,提升学生对延迟时间的敏感性(Γoutcome),如表6所示。

表6 教师干预信息提醒
(三)基于时间决策模型的干预效果分析
干预后,收集4次学生作业,构建数据集再次代入算法,提取输出的变量X。将聚类数k设定为3,使用K-Means算法进行聚类后,得到的三个集群分组中,集群1与集群2的数据特征十分接近,对于非活动时间,集群1平均达到0.505,集群2平均达到0.591;
对于空闲时间,集群1平均达到0.114,集群2平均达到0.140。集群3的非活动时间平均为0.226,空闲时间平均为0.458。根据这三类集群的数据特征,干预前强拖延倾向的学生人数减少为0。显然将聚类数k仍设定为3并不合理,因此,研究使用k=2对学生的拖延倾向进行重新识别,结果如表7所示。

表7 干预实验周学生拖延行为聚类结果
根据结果可以看出,尽管两个集群的拖延倾向划分为弱拖延倾向和无拖延倾向,但与干预前相比,弱拖延倾向组和无拖延倾向组的学生的平均空闲时间都有所上升,这意味着学生提交作业的时间与作业设定的截止时间间隔越来越长,表明他们的拖延倾向均有所减缓。据数据统计显示,原本处于强拖延倾向组的学生共7人,其中6人变为弱拖延倾向,1人变为无拖延倾向;
原本处于弱拖延倾向组的学生共22人,其中9人变为无拖延倾向,13人未改变分组。此外,由于原本处于强拖延倾向和弱拖延倾向分组的学生改变行为,数据分组的依据也有所改变,原本处于无拖延倾向分组的42人,20人保持不变,22人变为了弱拖延倾向。
为进一步对比各集群学生在干预前后8周提交作业行为的时间变化以及作业质量的高低,研究依据非干预周的聚类结果,基于3类集群作业提交时长(由作业提交时间与作业发布时间做差得到,即“SubmissionDs-OpenDateh”)和作业分数的均值,使用配对样本t检验,结果如表8所示。从作业提交平均时长来看,干预后弱拖延倾向学生的作业提交平均时长(M=6.17,SD=0.17)显著低于干预前学生的作业提交平均时长(M=6.51,SD=0.28),t=4.97,P<0.01;
干预后强拖延倾向学生的作业提交平均时长(M=6.36,SD=0.28)显著低于干预前学生的作业提交平均时长(M=7.41,SD=0.34),t=6.16,P<0.01;
干预后无拖延倾向学生的作业提交平均时长(M=6.01,SD=0.19)与干预前学生的作业提交平均时长(M=6.10,SD=0.24)不存在显著差异(t=1.66,P>0.05)。从作业平均分数来看,干预后弱拖延倾向学生的作业平均分数(M=85.40,SD=2.80)显著高于干预前学生的作业平均分数(M=82.95,SD=1.91),t=-3.83,P<0.01;
干预后强拖延倾向学生的作业平均分数(M=79.28,SD=2.98)显著高于干预前学生的作业平均分数(M=74.57,SD=2.63),t=-3.83,P<0.01;
干预后无拖延倾向学生的作业平均分数(M=88.61,SD=2.35)与干预前学生的作业平均分数(M=88.30,SD=2.57)不存在显著差异(t=-0.65,P>0.05)。数据结果进一步表明,在课程早期对学生实施干预是有效的,能够正确引导学生,减少或控制学生的拖延倾向,进而帮助他们规避学业风险。
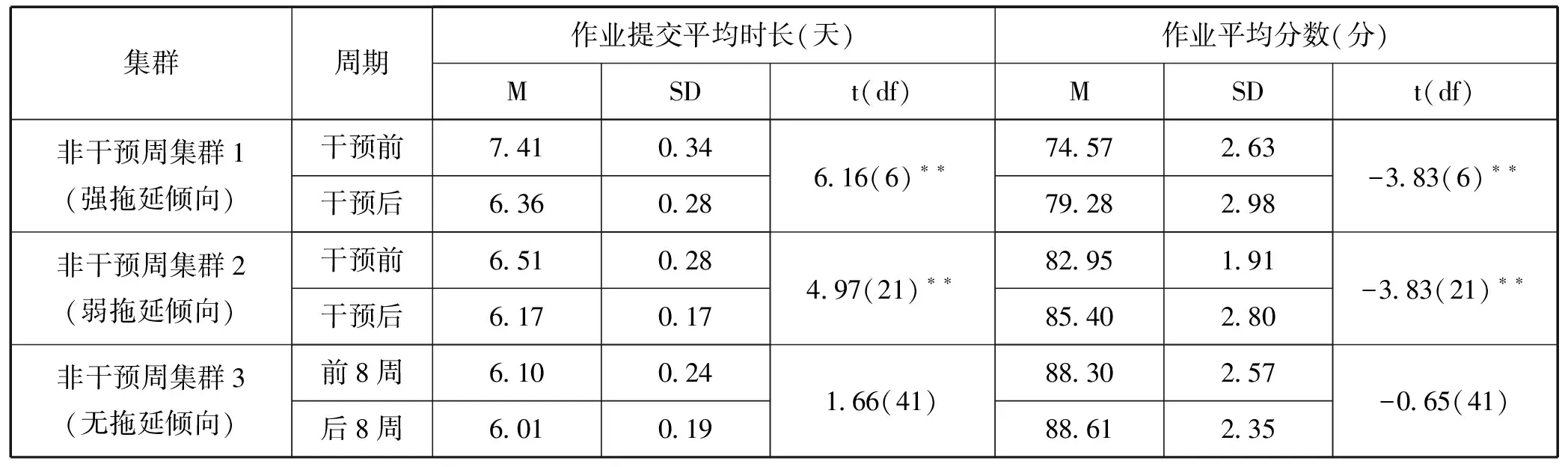
表8 不同集群干预前后的配对样本t检验结果
本文基于学生作业提交数据,利用教育数据挖掘技术设计了一种精准识别学生拖延倾向的方法。并结合支持向量机、决策树等六种算法对该方法进行了验证,结果表明,无论使用连续变量还是分类变量,预测精度均达到70%以上,说明了方法的精准性。在此基础上,研究以识别结果为依据开展干预实验,应用时间决策模型理论,采用学习分析仪表盘自我调节和即时通讯软件教师消息提醒的方法,对存在学业拖延风险的学生实施了个性化教学干预。研究结果发现,早期对学生实施简单的个性化干预能够帮助学生减缓或控制学业拖延倾向,对于规避学业风险具有良好的效果。研究成果较好地缓解了学生学业拖延问题,提高了学业成绩,有助于推动在线教育高质量发展。当然,本研究还存在着一些局限,数据样本不够充分,未来工作应扩大数据样本,进一步验证该方法的有效性;
除了作业提交数据,其他在线学习活动数据如复习学习内容的延迟时间、学生作业互评时间等也可能会影响学业拖延行为的表征,未来的研究可关注这些活动数据的作用。