融合注意力机制的金属锅圆柱表面缺陷检测
来源:优秀文章 发布时间:2023-04-08 点击:
乔 健, 陈能达, 伍雁雄, 吴 阳, 杨景卫*
(1.佛山科学技术学院 机电工程与自动化学院,广东 佛山 528000;
2.季华实验室,广东 佛山 528200;
3.佛山科学技术学院 物理与光电工程学院,广东 佛山 528000;
随着人们生活质量的不断提高,对日常生活用品的外观及品质提出了更高要求,所以以外观漂亮、坚固耐用及清洁便捷的不锈钢餐厨具备受人们青睐。其中,以圆柱锅为代表的锅类不锈钢产品占整个餐厨具一半以上的份额。圆柱金属锅在抛光加工过程中由于随机可变因素导致擦伤、纹理不均、色差、变形等表面缺陷,产品质量和外观得不到有效保障。同时,圆柱金属锅作为典型多品种、小批量产品,规格种类多、批量小、外观尺寸较大,在产品表面质量检测过程中一直以人工目视检测为主,漏检、误检现象时有发生,效率低、速度慢的目视检测方法严重制约着餐厨具生产加工行业数字化转型的发展进程。
金属圆柱形工件的表面缺陷检测是光学自动检测中的难点,国内外学者开展了大量机器视觉检测装置和算法的研究。其中,圆柱形工件的图像采集装置基本采用旋转机构搭配工业线阵相机[1]或工业面阵相机[2]的设计。近年来,随着计算机视觉技术的快速发展,人们提出了一系列基于深度学习的金属表面缺陷检测方法。Lin等[3]提出基于注意力机制和特征图映射的鲁棒检测方法,解决了X射线检测中铸件缺陷的误检和漏检问题。Sun等[4]在Faster R-CNN主干网络中引入RPN结构,在300毫秒内实现了对单张轮毂缺陷图像的快速检测。由于单阶段目标检测算法中,YOLO系列将目标分类和定位问题转化为回归问题,从首次新增特征融合层的YOLOv3发布为起点,特征融合层成为后续发布的YOLO算法必不可少的组成部分。王宸等[5]通过替换YOLOv3主干网络的激活函数以及对损失函数进行修改,验证集的mAP值为98.94%,检测速度达到76.59 frame/s,基本满足轮毂焊缝的实时在线检测需求。针对金属表面检测中微小缺陷易漏检的状况,程婧怡等[6]利用YOLOv3主干网络Darknet-53结构中的浅层特征图,提取出更多小目标信息,降低了小缺陷的漏检概率,但无法实现实时的快速检测。2021年,旷视科技的Ge[7]公布了YOLOX算法,在动态正样本数量分配以及预测框回归方面展开研究,实现了检测精度的提高,但计算机硬件算力的要求也更高。
在深度学习模型轻量化的研究中,通常采用替换主干特征提取网络[8]、设计轻量网络基础模块[9]、替换轻量化卷积模块[10]、设计运算量较小的卷积运算方式[11]以及通过缩小模型宽度和深度的方式来达到轻量化模型的目的。但上述方法均可能导致模型检测精度的损失,因此研究人员又设法在轻量化模型的基础上融合新的模块,以提高精度。为降低深度学习模型在工业生产现场中的应用难度,本文结合BiFPN[12]跨尺度特征融合思想,通过替换YOLOX特征融合层(Neck)进行模型轻量化,在Neck层融合注意力机制模块,提高模型检测精度。针对目标检测算法在训练过程中正负样本比例严重失衡的问题,提出了基于衰减因子的分类损失函数(Sinusoidal Atten⁃uation focal Loss, SFL),加强难分类正样本的学习,减少易分类负样本对梯度反向传播的影响。结合上述改进策略开展实验,以验证基于融合注意力机制的跨尺度特征融合网络的有效性,实现了金属锅圆柱表面缺陷的高精度快速检测。
基于深度学习的目标检测算法结构通常分为主干网络、特征融合层、预测层以及损失函数部分。本文以YOLOX为基础框架,提出融合注意力机制的跨尺度特征融合网络(Bi-directional YOLOX,BiYOLOX),改进的网络结构如图1所示。本文主要通过设计基于注意力机制的特征融合方式,对BiFPN的各分支特征进行注意力学习,改善对包含目标区域的关注度,提高模型对目标的检测精度。通过引入衰减因子来设计分类损失函数,重新分配正负样本学习权重,由SFL完成正负样本与目标类别的分类,由CIoU Loss[13]完成 目标位置的回归。
如图1所示,维度大小为960×960×3的待检测图像首先经过Focus结构将原始RGB图像的通道数从3扩展为12,并将原来宽高为w,h的特征缩小为w/2,h/2,对输入图像进行2×2的网格化采样,再输入CSPDarknet主干网络进行特征提取;
用于特征融合的Neck层为在分支引入注意力机制的BiFPN网络;
网络头部检测器YoloHead对Neck层得到的3个有效特征层结果进行堆叠,获得包含预测框数量、类别、置信度与坐标位置的特征信息;
网络训练过程中,通过计算模型Loss获得预测框与真实框的偏差,并利用模型Loss更新网络参数。图中,Cls部分为包含物体的种类判断特征点,Reg部分为回归参数判断的特征点,Obj部分为包含物体判断的特征点。其中,Cls和Obj部分通过分类损失函数进行判断,Reg部分则通过回归损失函数进行判断。模型Loss为:

图1 BiYOLOX网络结构Fig.1 Structure of BiYOLOX network
其中:Losscls为每一个特征点所包含物体种类损失,Lossobj为每一个特征点是否包含物体损失,LossIoU为预测框回归损失,ai为各损失权重系数。
2.1 跨尺度特征融合网络
BiFPN是通过改进FPN来实现多尺度的特征融合网络,并对主干网络提取的三个特征层Feat1,Feat2和Feat3进行通道数维度的统一,然后自顶向下和自底向上的双向特征融合。最后,把融合的特征传送至网络头部检测器Yolo⁃Head。BiFPN采用快速归一化(Fast Normalized Fusion, FNF)计算方式对每个输入添加获得额外权重,为不同特征层信息提供单独的学习权重分配,从而缓解由高低分辨率特征信息融合带来的语义鸿沟[14],即有:
其中:wi为可学习的权重,Ii为输入特征;
ε取值[12]为0.000 1,以确保分母不为零并获得较好的训练效果;
为保证获取的权重大于0,更新权重前采用ReLU激活函数进行映射,使得小于0的权值以0输出,大于或等于0的权值按原值输出。
相对于YOLOX使用的路径聚合网络(Path Aggregation Network, PANet)[15],BiFPN在使用规则和高效的连接下,完成信息自上而下的流动,通过削减只有一个入度的节点来去除冗余计算,达到轻量化网络的效果。同时,为避免特征信息丢失,使用CSPNet[16]替换深度来分离卷积进行特征提取。
2.2 注意力机制的特征融合
为在轻量化改进模型中尽量提高模型检测精度,本文在模型Neck层引入注意力机制。深度学习模型的大小通常由主干部分决定,但受制于计算机硬件的算力,需对神经网络深度、宽度和输入分辨率进行平衡,才可使模型表现出更好的性能[17]。文献[18]针对目标背景复杂的问题,在SSD算法中增加通道注意力模块,将算法注意力集中在目标区域的通道,增大目标区域通道的特征响应,减小背景干扰,提高了模型的检测精度。文献[19]为从图像中提取更有效的特征用于后续特征点的提取和描述,将通道注意力模块集成到主干提取网络中,在不增加模型复杂度前提下获得了优良的特征。文献[20]在SENet基础上设计了更轻量的通道注意力模块并融合到主干网络中的CSP模块,该方法增强了主干网络对复杂背景下特征的筛选能力。上述研究表明,网络融合注意力机制模块同样能够影响深度学习模型的性能。根据人类在识别物体时产生的注意力集中现象,注意力机制描述如下:
其中:g(x)表示产生注意力,对应各类注意力机制算法在关注判别性区域的过程,f(g(x),x)表示使用注意力g(x)对输入x进行处理。
为使网络更好地聚焦在感兴趣区域,本文提出在特征信息进行融合前,将来自不同特征层的信息通道拼接,接着进行特征块的注意力学习,使网络学习到每个特征通道和空间的重要性,并重新进行加权,经Split操作恢复为初始维度大小的新特征信息。图2为基于注意力机制的多尺度特征学习方式示意图。

图2 基于注意力机制的多尺度特征学习Fig.2 Multiscale feature learning based on attention mechanism
基于注意力机制的多尺度特征学习计算公式如下:
其中:Fi为输入特征图,Mi为输出特征图,维度为(H,W,C),⊗为基于元素的乘法运算,Concat为拼接操作,Split为切片操作,Attention为注意力机制模块。
通道注意力模块(Channel Attention Mod⁃ule, CAM)、空间注意力模块(Spatial Attention Module, SAM)、模块级联构成的注意力模块(Convolutional Block Attention Module,CBAM)具有优越的性能并得到了广泛应用[21],但其计算量较大。为降低整体注意力机制模块的计算量,增大输出特征感受野,本文利用3个卷积核大小为3×3的卷积代替SAM中7×7卷积操作,把拼接后通道数为2的特征信息降维为单通道。但由于小卷积核的普通卷积操作对提升特征信息感受野的能力有限,引入空洞卷积替换最后一个3×3卷积操作,可增大特征信息感受野。改进的SAM在保留网络对特征空间学习能力的同时,增大特征图的感受野,使输出特征尺度更加丰富,对应结构如图3所示。改进后的CBAM命名为空洞卷积注意力模块(Dilated Convolutional Block Attention Module, Di_CBAM)。

图3 基于空洞卷积的SAM模块Fig.3 SAM module based on dilated convolution
基于3×3卷积的SAM计算公式如下:
其中:σ为Sigmoid激活操作,f3×33表示3个3×3的卷积操作,AvgPool(F)和MaxPool(F)分别表示对特征图F进行平均池化操作和最大池化操作。
2.3 分类损失函数
针对单阶段目标检测算法训练过程中正负样本比例严重失衡的问题,Lin等[22]提出了由标准交叉熵损失函数(Cross Entropy Loss, CEL)改进的聚焦损失函数(Focal Loss, FL)。在CEL中引入权重因子αt,即可解决正负样本不平衡的问题。大多数负样属于易分类样本,正样本通常属于难分类样本。FL的引入可控制难易分类样本学习权重的调制因子,降低了大量易分类负样本在训练中所占的权重。具体表达式如下:
其中:y表示预测样本,当y=0时,预测样本为负样本,当y=1时,预测样本为正样本;
p为预测样本的预测结果对应真实类别的概率;
α∈[0,1],是用于平衡正负样本权重的系数,参数γ∈[0,∞)用于控制难分类和易分类样本的权重,(1-pt)γ为调制因子。
通常预测样本为真的概率越大,易分类样本的学习权重会越小,且衰减较缓慢,而难分类样本的学习权重通常较大。因此,FL会导致网络过多关注难分类样本的学习,使得模型Loss收敛缓慢,优化结果偏离预期。针对难分类正样本的学习,减少易分类负样本对梯度反向传播的影响,根据正弦函数的曲线变化趋势,在FL中引入(0,1]区间内具有非线性衰减趋势的因子s。把改进的损失函数命名为正弦衰减聚焦损失函数(Sinusoidal attenuation Focal Loss, SFL),其 表达式为:
其中:αt,pt和γ的定义与FL中的参数相同,s为正弦衰减因子,且θ∈(0,π]。图4展示了正弦衰减因子s随pt的变化情况,图5展示了本文提到的分类损失函数曲线示例。

图4 正弦衰减因子变化曲线Fig.4 Variation curves of sinusoidal attenuation factor
由图4可知,随着pt的增大,正弦衰减因子s呈下降趋势,并随着参数θ的增大,s的变化范围逐渐变大,模型会增大对难分类样本的学习权重分配。
由图5可知,SFL通过引入具有非线性衰减趋势的因子s,可使模型在侧重学习难分类样本的同时,增大易分类样本的学习权重,并随着样本预测概率的增大,易分类样本学习权重逐渐减小。因此,通过引入参数θ来改变FL调制因子,可加快模型损失的收敛速度,提高整体学习效果。

图5 分类损失函数曲线示例Fig. 5 Example of classification loss function curves
3.1 实验数据集与训练策略
考虑金属锅具生产环境中存在光照变化,以及车间灰尘对镜头的污染等影响,分别采集不同清晰度、亮度以及干扰光源下的图像,图像采集装置如图6所示。

图6 图像采集与检测系统Fig.6 Image acquisition and detection system
根据物理属性和后续修复操作,将高亮反射金属圆柱锅产品常见的柱面缺陷定义为凸起(Bulges, Bu)、指纹油污(Finger print, FP)、黑斑块(Patches, Pa)、凹坑(Pit, Pi)、划痕(Scratch⁃es, Sc)和擦伤(Suface scratch, SS)。CMOS工业面阵相机的分辨率为2 048×1 536像素,实验共采集有效图像样本1 000幅,保证数据集的丰富程度[23]。为降低深度学习模型的训练时间,去除图像中的冗余信息,提高算法在生产现场中的实时性,裁剪部分非光斑与无缺陷区域,统一图像尺寸为960×960像素。同时,定义标记框面积S<322个像素为小型目标,322≤S≤962为中型目标,S>962为大型目标。
使用Vott软件对图像进行处理,数据集以VOC2007格式进行保存,各类别缺陷标注样例如图7所示(彩图见期刊电子版)。其中,红色标注框为凸起、紫色标注框为指纹油污、绿色标注框为黑斑块、青色标注框为凹坑、蓝色标注框为划痕、黄色标注框为擦伤。

图7 金属锅圆柱表面各类缺陷样本Fig.7 Samples of various defects on cylindrical surface of metal pot
随机抽取训练集和验证集,它们与测试集图像的比例为9∶1,其中训练集与验证集抽取比例同为9∶1,即训练集810张,验证集90张,测试集100张。数据集命名为金属锅圆柱表面缺陷数据集,图8展示了该数据集标记框大中小目标数量的分布情况。结合图7展示的样本例可知,数据具有类别不平衡、同一图像存在多个实例、目标尺寸各异的特性。

图8 各类标签的目标数量分布Fig.8 Target quantity distribution of various labels
实验配置为:Intel(R) Core(TM) i5-9300H处理器,运行内存16 GB,图形处理单元NVID⁃IA GeForce GTX 1660 Ti,显存6 GB,安装CU⁃DA 11.0,cuDNN 8.0.5,深 度 学 习 框 架Py⁃torch1.4。模型输入图像尺寸为960×960像素,模型超参数设置如表1所示。

表1 模型超参数设置Tab.1 Model super parameter setting
正式训练前,在金属锅圆柱表面缺陷数据集上进行100个Epoch预训练,使用预训练得到的权重文件进行正式训练。训练过程中,通过Ad⁃amW对训练过程进行优化,利用Cosine schedul⁃er学习率调整策略进行训练,避免网络陷入局部最优的情况,并通过Mosaic算法对网络输入数据进行增强。
3.2 评价指标
为较客观地评价所设计模型的检测效果,实验通过召回率(Recall)、平均精度(Average Preci⁃sion, AP)以及均值平均精度(mean Average Pre⁃cision, mAP)来评估模型的性能。AP用于评价模型对某一类别目标的检测效果,AP值越高,模型检测效果越佳。其计算公式如下:
对于目标检测来说,当预测框与真实框的矩形框交并比IoU值大于某个阈值时,才会将该预测框认定为真样例,因此IoU阈值的选择对于目标检测的效果极为重要。mAP是衡量目标检测算法整体性能的最为全面的评价指标,其公式如下:
其中:n为类别数,AP(i)表示第i个类别的AP值。
经测试,模型的精确率曲线拐点出现在IoU=0.5附近,为观察模型在高IoU阈值设定下的性能表现,实验环节将IoU阈值设为0.5和0.75,记均值平均精度为mAP0.5和mAP0.75。
对于模型计算效率评价,本文采用模型参数量(Params)、浮点运算数(FLOPs)和检测帧率(FPS)来衡量。其中,FPS为计算模型对单张图像的平均检测时间,即:
其中:t为单张960×960像素图像的检测时间。
3.3 实验结果与分析
本文进行了特征融合网络对比实验、损失函数对比实验、注意力机制模块位置消融实验以及与其他轻量化改进模型的性能对比实验。根据已搭建的实验条件,使用金属锅圆柱表面缺陷数据集中的测试集进行性能测试,且实验均采用size为s的模型,即YOLOX_s和BiYOLOX_s。
PANet和BiFPN特征融合网络对比实验中,模型的性能表现如表2所示。本组实验采用IoU Loss[24]作为回归损失函数,以CEL作为分类损失函数。

表2 特征融合网络性能对比Tab.2 Performance comparison of feature fusion network
模型Neck层融合BiFPN后,性能得到明显提升。相比于原YOLOX网络使用的PANet结构,Params减少2.6M,FLOPs下降4.053 G,网络复杂度明显降低。随着Params的减少,FPS得到4.2 frame/s的提升,单张960×960像素图片的检测时间从YOLOX的35.7 ms降低至31.1 ms,并且mAP0.5提升3.54%,达到90.06%。
损失函数对比实验中,为了比较IoU计算方式对BiYOLOX算法检测效果的影响,分别使用IoU Loss,GIoU Loss[25],DIoU Loss[26]和CIoU Loss作为算法的回归损失函数,测试结果如表3所示。其中,模型分类损失函数为FL,且α=0.75,γ=2。
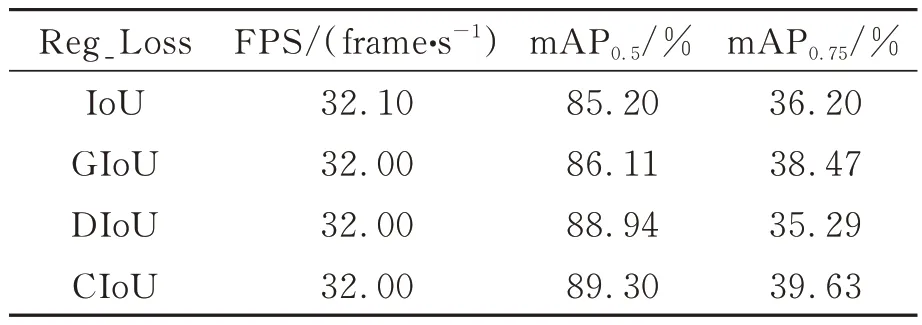
表3 回归损失函数的检测效果对比Tab.3 Comparison of detection effect of regression loss functions
从表3可以看出,使用GIoU Loss,DIoU Loss和CIoU Loss作为BiYOLOX的回归损失函数可进一步提升模型的检测精度,并且保持较高的检测速度。相比于原始的IoU Loss,采用GIoU Loss的mAP0.5和mAP0.75指标分别提升了0.91%和2.27%;
采用DIoU Loss的mAP0.5提升3.74%,mAP0.75下降0.91%。本组实验中,采用CIoU Loss作为回归损失函数的模型在检测精度方面得到了最大提升,mAP0.5和mAP0.75指标分别提升了4.10%和3.43%。
为验证设计的SFL对BiYOLOX算法检测效果的影响,在CIoU Loss作为回归损失函数的情况下进行分类损失函数对比实验,采用4分法划分θ的取值范围,实验结果如表4所示。

表4 分类损失函数的检测效果对比Tab.4 Comparison of detection effect of classification loss functions
由表4可知,所设计的SFL在参数θ=0.5π的设置下,模型获得的mAP0.5最高,相比于相同参数设置下的FL提升了1.35%。当参数θ≥0.75π时,模型的mAP0.5与mAP0.75均会下降。由此可知,在FL中引入正弦衰减因子s能够有效提高模型的检测精度,但当正弦衰减因子s的变化幅度较大时,模型对难分类样本的关注度较高,模型的检测精度会下降。
在分类损失函数对比实验中,根据表4中不同θ设置下的SFL分组实验,对金属锅圆柱表面缺陷召回率数据进行统计,结果如图9所示。
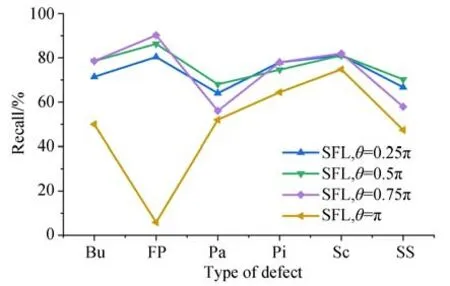
图9 不同θ设置下各类别缺陷的召回率统计Fig.9 Statistics of defect recall rate of each category un⁃der different θ settings
由图9可知,当SFL的参数θ=0.25π时,各类别缺陷的召回率在60%~80%内;
当参数θ=0.5π时,各类别缺陷的召回率在70%~90%内,表现最为均衡;
当参数θ=0.75π时,黑斑块和擦伤缺陷的召回率低于60%,各类别缺陷的召回率在50%~95%内;
当参数θ=π时,相比于同参数设置下的FL,各类别缺陷召回率均有不同程度的下降,指纹油污缺陷的召回率下降最严重,已低于10%。结合图8中的数据集标记框大中小目标数量的分布情况,指纹、黑斑块与擦伤缺陷均有大目标存在,而指纹缺陷在数据集中主要为大目标,因此设置较高的θ值会降低模型对大目标缺陷的识别效果。此外,当θ大于0.75π时,模型增加了难分类样本的学习权重,SFL对系统整体性能的抑制效果较为明显,缺陷的整体召回率偏低。上述实验说明,难易分类样本的学习权重分配策略能够影响模型的召回率,SFL的正弦衰减因子s的变化范围应适中,因此后续实验使用参数θ=0.5π设置下的SFL。
为更深入研究注意力机制模块的引入对模型检测速度和精度的影响,开展了关于注意力机制模块位置的消融实验,结果如表5所示。其中,注意力机制模块的位置参考图1中的加权特征融合位置,Add1表示feat2的浅层特征融合处,Add2表示feat1的深层特征融合处。模型选用CIoU Loss,SFL作为回归损失函数和分类损失函 数,SFL参 数 设 置 为:α=0.75,γ=1,θ=0.5π。FNF表示归一化的加权特征融合,0表示未启用相关模块,1表示启用相关模块。

表5 不同位置融合Di_CBAM的特征融合网络性能对比Tab.5 Performance comparison of feature fusion networks with Di_CBAM introduced at different locations
由表5可知,引入Di_CBAM模块后模型的检测帧率存在明显变化,并且在特征融合过程中使用FNF能够有效提高mAP。其中,模型检测帧率的下降主要由特征层的多层感知机运算引起,由于拼接后的特征通道数变为原通道数的3倍,增加了计算开销,最终导致检测帧率下降。在feat2和feat3层的底层特征融合处引入注意力机制,即图1中的Add3和Add4位置,模型能达到30.84 frame/s的检测速度,并且mAP0.5达到90.92%,说明在此位置引入注意力机制既能维持较高的检测精度,又能保证模型以较快速度运行。
为验证替换特征融合网络、引入注意力机制和设计分类损失函数3个改进策略对模型的耦合影响,开展了消融实验,结果如表6所示。其中,Di_CBAM引入位置位于Add3和Add4处,SFL参数设置为:α=0.75,γ=1,θ=0.5π,0表示未启用相关模块,1则表示启用相关模块。
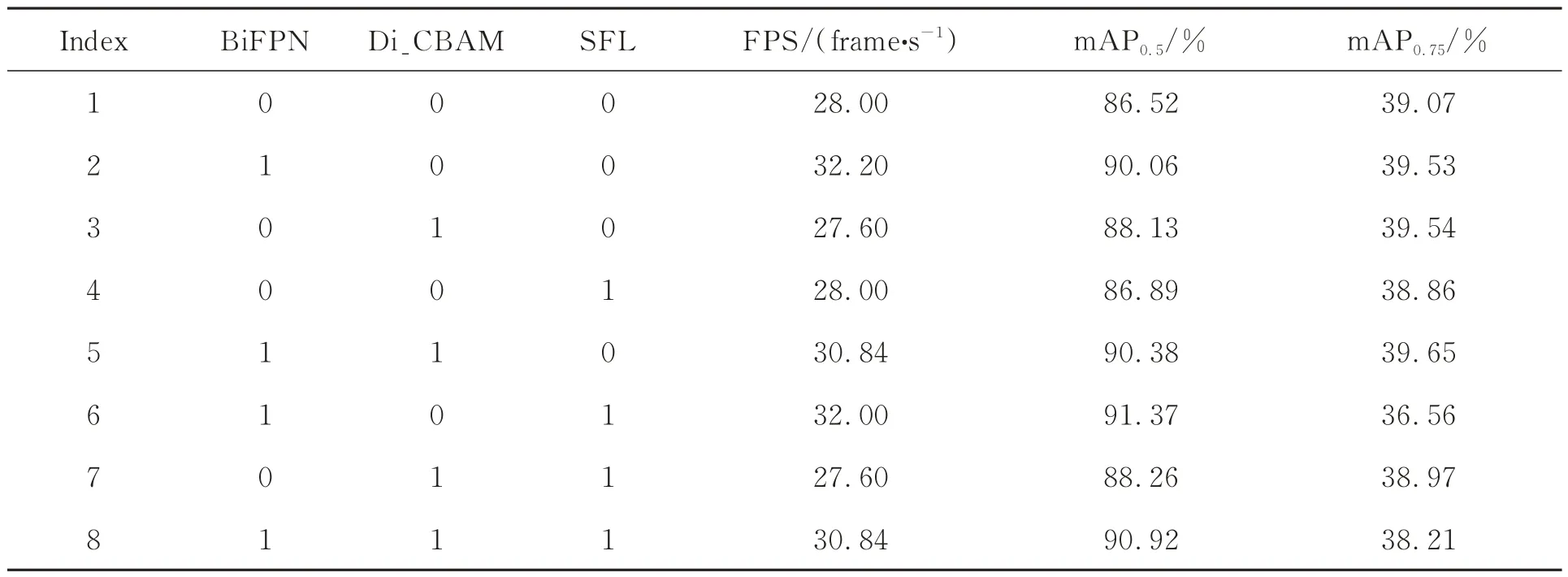
表6 改进策略对模型性能的影响对比Tab.6 Comparison of impact of improvement strategies on model performance
对比表6中的第1组与第4组、第2组与第6组、第3组与第7组实验结果可知,使用SFL不会降低检测速度,能够起到提高mAP0.5和降低mAP0.75的作用。第3组实验单独使用Di_CBAM的模型相对于YOLOX原始模型在检测精度方面提升较明显,mAP0.5和mAP0.75分别提高1.61%和0.47%,但检测速度出现轻微下降,说明引入Di_CBAM虽然会降低模型的检测速度,但能够有效提高模型的检测精度。在第7组同时使用BiFPN和SFL的实验中,检测速度达到32.00 frame/s,mAP0.5达到91.37%,但mAP0.75降至36.56%;
在第8组启用Di_CBAM的实验中,虽然检测速度和mAP0.5指标出现了轻微下降,但能将mAP0.75提升至38.21%,说明同时启用3个改进策略能够确保模型在检测速度和检测精度之间取得平衡。
最后,为验证本文设计的BiYOLOX算法的性能表现,将本文算法与替换卷积操作的轻量化YOLOv3[11]、轻量化特征提取网络的YOLOv5[10]和YOLOX算法进行对比实验。模型性能如表7所示,高亮反射金属锅圆柱表面缺陷的部分检测结果如图10所示。

表7 轻量化改进模型的性能对比Tab.7 Performance comparison of lightweight improved models

图10 高亮反射金属锅圆柱表面缺陷检测结果Fig.10 Detection results of cylindrical surface defects of highlight reflective metal pot
由表7可知,本文设计的BiYOLOX算法相比于列举的轻量化YOLO系列算法,模型的参数量更少、单张图像的检测速度提升明显,并且获得了较高的检测精度。由图10可知,在斑块缺陷检测中,Light-YOLOv3,Light-YOLOv5均存在漏检;
在划痕缺陷检测中,图像右侧的凸起和左下方的划痕缺陷在Light-YOLOv3,Light-YO⁃LOv5和YOLOX算法中被漏检,并且YOLOX算法还漏检了一处凸起缺陷;
在擦伤缺陷检测中,图像左侧的一处缺陷在Light-YOLOv3,Light-YOLOv5和YOLOX算法中均出现漏检,而本文提出的融合注意力机制和SFL的BiYO⁃LOX算法则能够准确定位缺陷目标位置,无错检、漏检情况,并且预测框的置信度普遍高于前者,说明本文设计的SFL能够有效提高模型对目标的分类效果。分析斑块、划痕和擦伤的检测数据可知,Light-YOLOv3,Light-YOLOv5和YOLOX漏检目标的尺寸与位置不一,此现象的出现归结于网络的输出特征层信息不够丰富。实验结果表明,模型通过引入注意力机制学习特征的通道和空间信息,以跨尺度的特征融合方式获得了更丰富的特征信息,对提高金属锅圆柱表面缺陷的检测效果具有积极作用。
本文针对金属锅圆柱表面缺陷高精度快速检测的深度学习模型设计需求,提出了基于注意力机制的轻量化特征融合网络,并利用BiFPN替换YOLOX网络的特征融合层,在降低网络计算资源消耗的情况下提高多尺度特征在通道和空间上的表达。针对训练过程中正负样本不平衡的问题,设计了基于衰减因子的分类损失函数SFL,对难易分类样本的学习权重进行重新分配。完成了在金属锅圆柱表面缺陷数据集上对BiYOLOX与YOLOX的特征融合网络、分类损失函数对比实验和注意力机制模块位置消融实验。实验结果显示,所设计的网络能够有效降低模型参数量和浮点计算数,并提高检测速度和精度,较原始YOLOX的Parames减少2.6M,FLOPs下降4.053 G,模型检测帧率提升至30.84 frame/s,检测精度mAP0.5达到90.92%,实现了金属锅圆柱表面缺陷的高精度快速识别与定位。
猜你喜欢注意力分类样本让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09分类算一算数学小灵通(1-2年级)(2021年4期)2021-06-09用样本估计总体复习点拨中学生数理化·高一版(2021年2期)2021-03-19分类讨论求坐标中学生数理化·七年级数学人教版(2019年4期)2019-05-20推动医改的“直销样本”知识经济·中国直销(2018年8期)2018-08-23数据分析中的分类讨论中学生数理化·七年级数学人教版(2018年6期)2018-06-26教你一招:数的分类初中生世界·七年级(2017年9期)2017-10-13“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13随机微分方程的样本Lyapunov二次型估计数学学习与研究(2017年3期)2017-03-09A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21推荐访问:圆柱 注意力 缺陷