基于句法和语义的英汉翻译记忆系统
来源:优秀文章 发布时间:2023-01-20 点击:
谢宛玲
(西安医学院,国际合作与交流办公室, 陕西,西安 710021)
翻译记忆是一种基于数据记忆库强大功能,调用已翻译的语料库,对具有复杂性的语言进行翻译的机器翻译手段。翻译记忆系统是基于翻译记忆技术而开发的翻译系统。在进行翻译的过程中,将人工翻译的资料储存于数据记忆库中,然后在下一次翻译时进行调用。对比翻译对象与数据记忆库中的资料,通过匹配度完成对象的替换、给出翻译建议或进行人工翻译等流程,最终完成译文[1-5]。由于专业领域资料的重复率较高,各个行业的重复率低则为20%,高则达70%,所以译者会进行大量无效的重复工作。如果利用翻译记忆技术进行翻译,则可以通过对数据记忆库资料的调用,免除这部分无效的工作,提高工作效率。因此,基于目前的翻译产品市场现状,翻译记忆技术是为数不多的可用于专业翻译的机器翻译技术[6-8]。
与国外翻译市场相比,国内的专业翻译市场中翻译记忆技术还不够普遍。因此,推广翻译记忆技术和开发相关翻译系统和平台,是极具有发展前景的研究方向。笔者开发一种基于句法和语义的英汉翻译记忆系统,对该系统的整体架构、语义计算及句子结构算法以及数据记忆库的设计进行介绍。
图1是本文所涉及的基于句法和语义的英汉翻译记忆系统的整体流程。在利用翻译记忆技术进行翻译前,首先在输入窗口将待翻译的原文输入,然后对所输入的内容进行检索,同时与记忆库中的资料进行对比。依照相似度计算的方法对所输入的内容与记忆库中的内容进行相似度计算,相似度为[0,1]之间。相似度为0,说明二者完全不匹配,这时进行人工翻译,并产生译文,同时将人工翻译的结果储存到记忆库中,以供下次翻译时进行调取;
相似度为1,则说明所输入的内容与记忆库中的内容完全匹配,则机器直接进行翻译并生成译文;
相似度处于0~1,则根据最相似的例句给出相应的译文,然后再通过人工复检对译文进行复用或修改,最后得到满意的翻译结果,并将相应的结果储存到数据记忆库中。
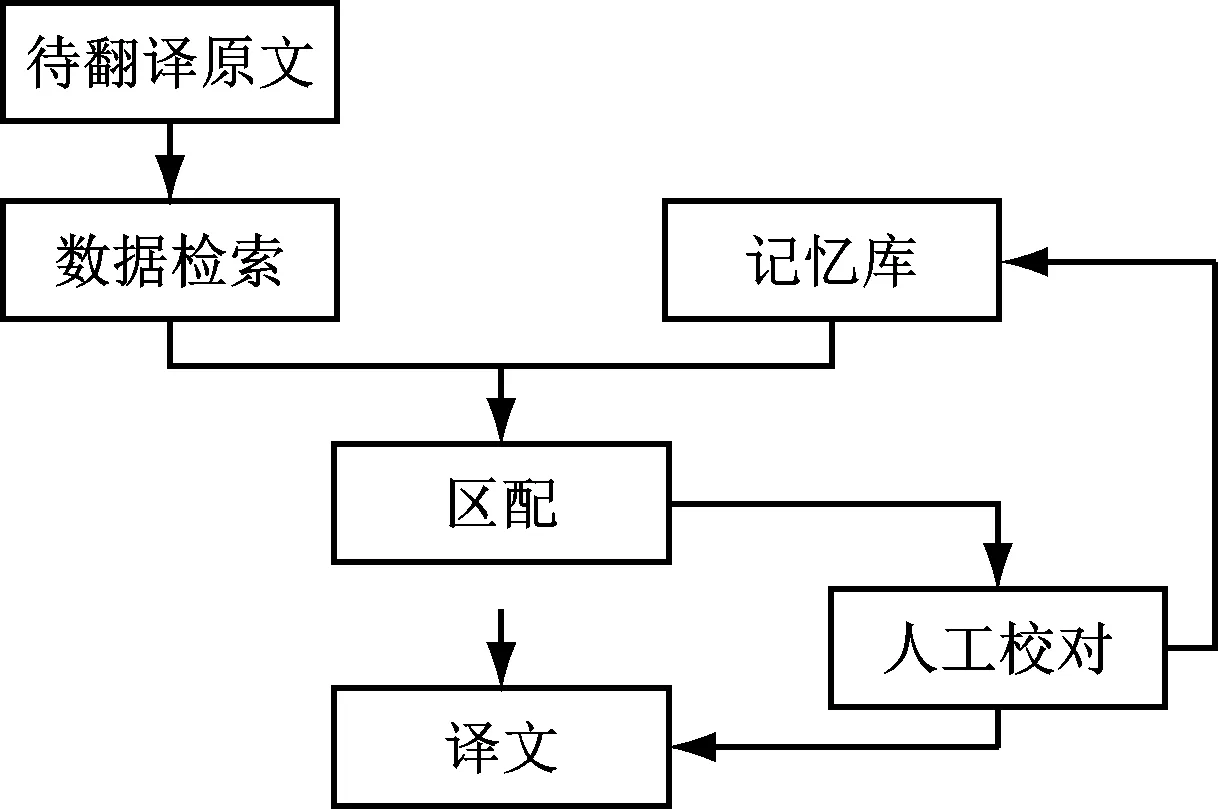
图1 翻译记忆系统的整体流程
本文所设计的翻译记忆系统的语义相似度计算是基于WordNet词典进行计算的。WordNet词汇矩阵模型如表1所示。表1中行代表单词的词义(meaning),列代表单词的词形(form)。矩阵中的表项则说明该单词具有某种词义,例如:T11则说明F1可以表达M1的词义;
存在T11、T12和T15,则说明单词F1、F2和F5均可以表达M1的词义,即F1、F2和F5为同义词;
而同时存在T12和T32则说明单词F2可以同时表达M1和M3的词义,即F2为多义词。

表1 WordNet词汇矩阵模型
在进行语义相似度计算时,利用WordNet中的Similarity1.04软件包中的stoplist对句子中虚词、冠词、介词和代词进行去除。利用stoplist对句子进行逐词扫描,当遇到stopword时,便将其删除。由于所删除的词语一般不会在句子中指代具体的词义,因此不会对句义造成影响,因此不计入相似度的计算中,语义计算的相应代码,如图2所示。

本系统的句子结构比较是通过对句法分析来进行的。通过规则对自然语言进行分析,确定每1个单词或短语的作用以及彼此之间的关系,然后利用句法分析树进行表达。例如“TIFF IFD array has wrong size”的句法分析树如图3所示。首先将句子拆分为名词短语和动词短语;然后再逐级进行拆分,直到确定每1个单词的作用和与其他单词之间的关系。在进行相似度计算时,如果2个句子的句法分析树完全一致,则说明2个句子的结构相同。本系统所采用的分析方法为浅层分析法,仅对名词短语、动词短语等非递归性短语进行分析。这种分析方法的效率较高,且结果也较为准确。句子结构分析的代码如图4所示。本系统利用Apple Pie Parser方法对句法结构进行分析后,过滤掉句子中的单词,然后以字符串的形式对句子的结构进行表示和比较。如果2个句子的字符串结构相同,则说明这2个句子的结构是相同的。

图3 翻译记忆系统的句法分析树

本系统的记忆库含有词汇级别、句子级别和更深层次级别3个级别。其中:词汇级别进行译文生成较为简便,但后期的译文加工较为繁琐;
句子级别的译文加工过程简洁明了,但译文生成较为繁琐;
更深层次级别生成译文时信息量大,后期加工繁琐。由此可见,通常进行记忆库设计时既要考虑前期加工过程,又要考虑后期加工过程,而且要同时兼顾检索和系统管理2个过程。本系统所设计的记忆库结构如表2所示。
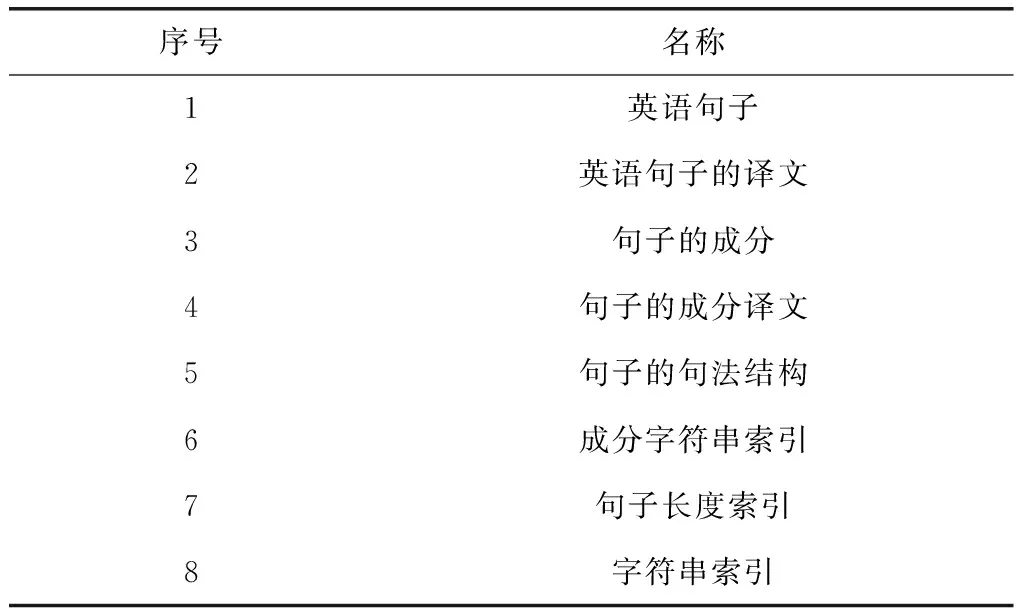
表2 翻译记忆系统的记忆库结构
本系统进行翻译时是基于句子进行翻译的,对句子的句法结构进行分析后,将待翻译的句子与数据记忆库中的资料进行相似度计算,得到[0,1]之间的结果,然后分0、1和(0,1)进行处理。若为0,则直接进行人工翻译;
若为1,则直接进行机器翻译;
若为(0,1)则根据图5的过程进行翻译。利用将“TIFF IFD array entry has wrong size”与“TIFF IFD array entry has invalid value”进行句子结构的相似度计算,然后根据机器翻译结果给出译文;
随后人工对译文进行复检,翻译正确的部分进行复用,翻译不正确的部分进行修改,然后得到最终的译文,并将其储存在数据记忆库中。

图5 翻译记忆系统的翻译过程
本文设计了一种基于句法he语义的英汉翻译记忆系统,并对其翻译流程和关键技术进行了介绍。本文所设计的系统是基于数据记忆库,对待翻译句子的句法结构进行分析,并进行相似度计算,根据不同的计算结果采取不同的处理方式。若与数据记忆库中的句子完全匹配,则直接进行机器翻译给出译文;
若完全不匹配,则通过人工翻译将结果储存于数据库中;
若部分匹配,则先进行机器翻译,再进行人工复检,得到最终译文,并储存于数据记忆库中。这种基于数据记忆库的翻译方法,可以避免人工翻译的重复工作,提高翻译工作的效率,应用前景广泛。