基于Transformer的细粒度图像中文描述
来源:优秀文章 发布时间:2022-12-05 点击:
肖 雄, 徐伟峰, 王洪涛, 苏 攀, 高思华
(1. 华北电力大学(保定) 计算机系, 河北 保定 071003;
2. 中国民航大学 计算机科学与技术学院, 天津 300300)
图像内容描述与图像标注、 图像特征提取、 文本生成等技术密切相关, 是图像和文本交叉融合的多模态任务[1-4], 不仅需要从图像中识别出目标物体, 还需将识别出的目标物体与其语义信息相关联以构成自然语言描述. 近年来, 关于图像内容描述的研究取得了较大进展, 在图像检索[5]、 人机交互[6]、 视觉辅助[7]等领域有广阔的应用前景.
早期图像描述方法主要基于传统机器学习, 在对象检测过程中识别出目标物体和属性, 将其填入预定义的模板以生成描述语句. 随着深度学习在各领域的快速发展, 基于深度学习的图像描述方法也得到快速发展. 深度图像描述模型通常采用编码器-解码器结构[8], 一般使用卷积神经网络(convolutional neural networks, CNN)作为编码器, 循环神经网络(recurrent neural network, RNN)作为解码器. 其中, CNN编码器通常用于提取图像的全局特征生成图像描述. 但这种网络结构存在两个问题:
1) CNN编码器无法有效提取图像的细粒度语义特征, 使模型生成的描述内容较广泛, 不具体;
2) RNN(包括其变种门控循环单元(GRU)[9]等)在解码时生成的词十分依赖前面内容的语义信息, 随着句子长度的增加, 新产生的词与之前的词之间相关性越来越小, 不利于生成长句描述. 图1为数据集ICC图片示例. 由图1可见: 基于GRU解码器不利于生成长句描述, 基于全局特征生成的内容倾向于描述场景, 而忽略了对象之间的关系;
在Transformer(无局部特征)模型生成的描述中, 只概括了“一群”对象, 并未描述目标对象的具体语义信息. 因此, 现有方法在图像中文描述任务上无法实现细粒度语义特征的有效提取.

图1 数据集ICC图片示例1Fig.1 Picture example1 ofICC dataset
针对上述图像描述现有方法不利于生成长句、 缺乏细节语义信息的问题, 本文提出一种具有细粒度语义特征的图像中文描述模型. 为提升学习和表示长句的能力, 该模型基于Transformer实现, 其编码器中, 使用预训练的Inception-ResNet提取全局特征, 对于局部特征, 以预训练的Faster R-CNN进行目标检测, 映射到目标区域后, 再使用Inception-ResNet提取特征. 为增强图像目标区域细粒度语义特征信息的表示, 编码器中的全局特征和局部特征通过多头注意力(multi-head attention, MHA)融合. 在解码器中, 通过对编码器输出的具有细粒度语义信息特征解码, 以生成图像中文描述. 实验结果表明, 多尺度特征的融合使图像注意力倾向于图像目标区域, 丰富了对目标物体的描述. 本文主要贡献如下:
1) 使用自注意力融合全局特征和局部特征的方法, 提取图像目标区域周围具有细粒度语义信息的特征, 以此丰富目标物体的图像描述;
2) 提出完全基于Transformer的图像中文描述模型, 增强了对长句学习和表示的能力;
3) 在数据集ICC上采用多种评价指标进行验证, 本文模型在各项指标上均有不同程度的提升, 此外, 为探索本文模型内部的可解释性, 对融合后的多尺度特征进行了注意力可视化分析.
1.1 图像描述
Xu等[10]在图像描述模型中引入了注意力机制, 编码器从较低的卷积层提取特征, 解码器通过选择所有特征向量的子集选择性地关注图像的某些部分, 但该模型仅在图像特征和文本之间进行注意力学习, 并未关注到图像中具体对象的细节信息. 文献[11]提出了一种基于RNN的多级注意力图像描述模型, 其中一级注意力通过融合图像的局部特征和全局特征表示图像, 二级注意力用于结合图像特征和文本向量, 该模型虽然对图像的语义特征有细粒度的表示, 但其表述长句的能力较差.
1.2 细粒度特征
Lin等[12]使用双线性池化(bilinear pooling)对图像进行细粒度分类. 为获得更多的隐藏特征信息, 其使用不同的CNN提取两种不同尺度的特征, 提取的多尺度特征通过双线性池化进行融合, 但该方法在每个特征位置都要进行大量的向量外积计算, 计算成本较高. Dai等[13]使用多尺度通道注意力模块融合不同尺度的特征, 但该方法并未显著提升图像描述的性能.
1.3 Transformer
Transformer[14]最早应用于自然语言处理, 近年也被广泛应用于计算机视觉领域中, 并取得了较好的效果. 例如:
Carion等[15]使用Transformer进行目标检测时, 通过采用二维位置编码(2-D positional encoding)将位置信息加入到图像中; Dosovitskiy等[16]提出用Vit Transformer对图像进行分类, 该模型将图像分成若干小块, 模仿文本序列作为Transformer的输入.
本文在使用Transformer对图像生成描述时, 对以上两种方法的实验结果表明, 使用二维位置编码[15]的方式对图像添加位置信息, 在与使用一维位置编码的文本向量融合时可能存在耦合问题, 导致解码图像特征时无法有效预测;
而使用分块输入[16]方法, 在解码时, 由于图像输入的语义信息不完整, 不能生成自然语义的描述. 因此, 本文在Transformer基础上使用深度卷积网络提取图像特征作为输入, 并使用一维位置编码为图像特征添加位置信息.
本文提出的模型基于Transformer结构生成图像描述, 主要由N个编码器和N个解码器两部分组成, 模型框架如图2所示. 编码器和解码器内部又包含多个注意力头, 其主要任务是对输入的不同特征进行注意力学习. 其中, 编码器主要任务是对图像特征进行编码, 学习到具有细粒度语义信息的图像特征, 分别使用Inception-ResNet[17]和Faster R-CNN[18]提取全局特征和局部特征, 在加入位置编码后, 通过MHA融合全局特征和局部特征. 解码器对输入的词嵌入向量X添加位置编码, 通过内部的MHA在词嵌入向量和编码器输出的细粒度图像特征之间建立映射关系, 最后经过一个全连接层输出词典中的概率分布, 取其中概率最大的索引生成描述语句.
2.1 图像特征提取
2.1.1 全局特征
对于图像的全局特征Hi,c(x), 使用预训练的Inception-ResNet提取特征, 这是一个由多个卷积网络堆积而成的深度模型. 为匹配Transformer网络的维度, 将提取的1×1×1 536维特征向量通过一个全连接层和ReLU激活层[19]转变为1×1×512维特征向量. 对于一张图像, 其全局特征可表示为Hi,c(x)={x1,x2,…,xL}, 其中xi∈D,L表示特征向量的数量,D表示特征向量的维数.
2.1.2 局部特征
对于图像的局部特征Ibox, 先使用预训练的Faster R-CNN检测目标区域, 将其映射到目标区域, 然后使用Inception-ResNet提取目标区域的局部特征, 同样通过一个全连接层和ReLU激活层进行维度转换. 对于一张图像, 其局部特征可表示为Ibox={Ibox1,Ibox2,…,Iboxn}, 其中boxn表示特征向量的数量.

图2 基于Transformer图像中文描述模型框架Fig.2 Image Chinese caption model framework based on Transformer
2.2 Transformer结构
2.2.1 多头自注意力
在卷积网络中, 使用多个卷积核提取不同的特征, 根据该思想, Transformer[14]提出了多头注意力, 使得特征多样化, 并且能并行运算.
多头注意力中的点积注意力(attention,A)是在一组查询(query,Q)、 键(key,K)、 值(value,V)之间的交互计算, 如图3所示. 其中Q∈d,Kt∈d,Vt∈d,t∈{1,2,…,n}表示键-值对的个数,d表示所有输入特征的维度, 通过计算Q和所有K的点积, 将每个值除以并通过Softmax函数[20]得到每个特征的注意力权重. 在实际应用中, 分别将所有的键-值对都打包成矩阵进行运算. 令K=(k1,k2,…,kn)∈n×d,V=(v1,v2,…,vn)∈n×d,Q=(q1,q2,…,qm)∈m×d, 则点积注意力的计算可表示为
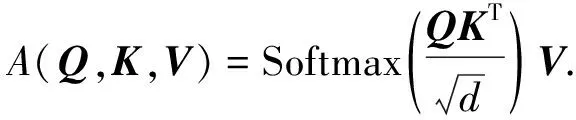
(1)

图3 点积注意力Fig.3 Dot-product attention
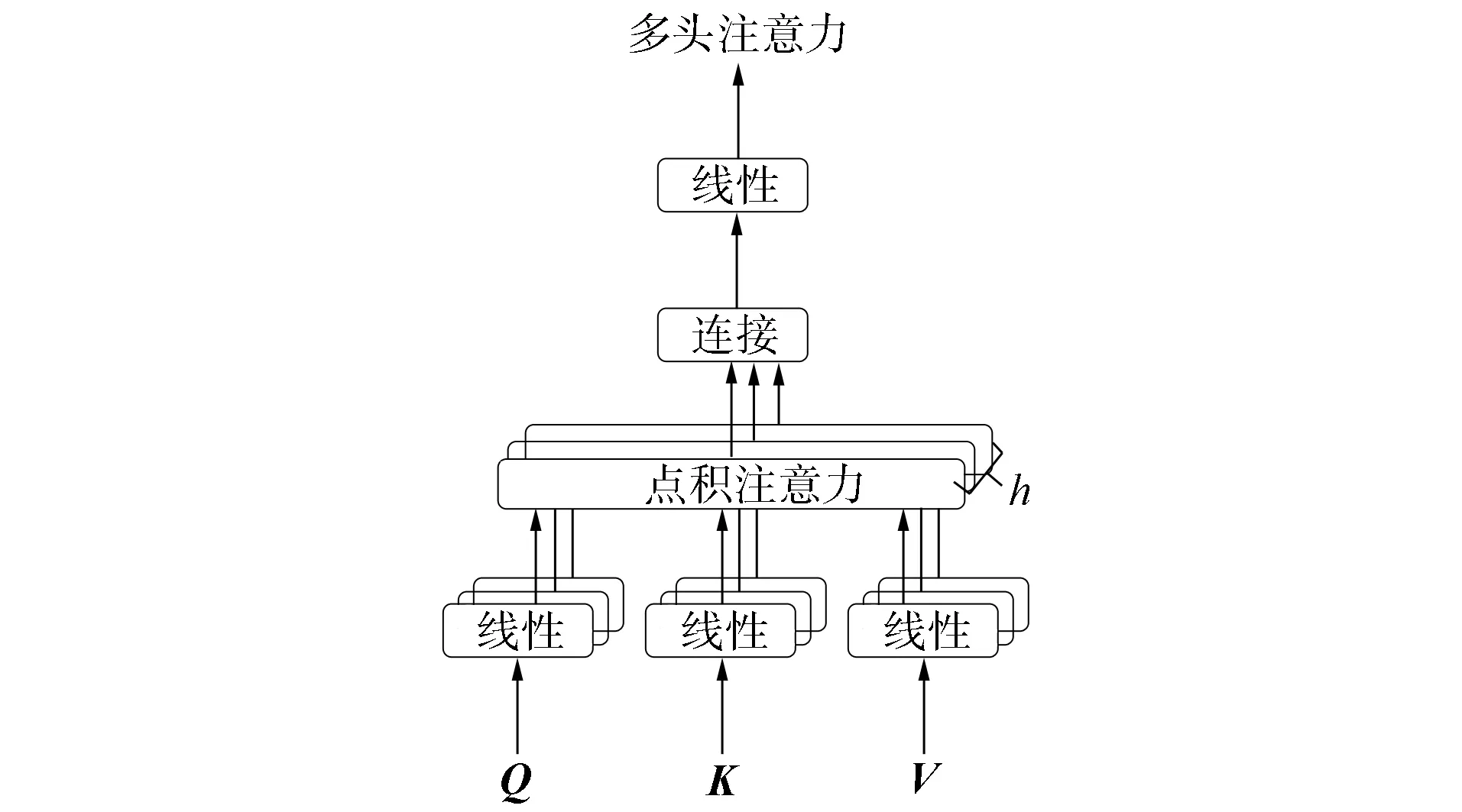
图4 多头注意力Fig.4 Multi-head attention
多头注意力不仅执行这组查询任务, 还包括多个点积注意力函数, 并行建模来自不同表示子空间的不同信息, 如图4所示.多头注意力包含h个平行的头, 每个头都有对应的独立点积注意力函数, 可表示为
MHA(Q,K,V)=Concat(h1,h2,…,hh)Wo,
(2)
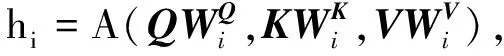
(3)
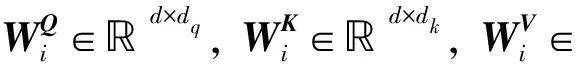
为使Transformer具有非线性, 增加一组前馈网络(feed forward network, FFN), FFN将MHA的输出特征作为输入, 使用两个全连接层进行变换, ReLU和Dropout[21]层的关系可表示为
FFN(x)=FC(Dropout(ReLU(FC(x,4d)),p),d),
(4)
其中输入特征x∈d, 第一个全连接层将x变换成4d维, 第二个全连接层变换成d维, Dropout比例设为0.1, 即p=0.1.
因此, 多头注意力模块在两个输入特征之间进行交互计算, 前馈网络进一步对特征进行非线性变换;
通过这两个模块的组合, 得到了一个深度可叠加的多头注意力模块.利用这种方式, 对图像全局特征和局部特征、 图像特征和文本序列进行自注意力学习.
2.2.2 位置编码
由于Transformer没有递归的输入信息, 因此为使模型中的特征序列在学习过程中保留位置信息, 在序列中加入相对位置信息. 位置编码和输入特征具有相同的维数d, 可直接相加表示.本文使用正弦和余弦三角函数作为位置编码函数, 可表示为
其中pos为当前序列位置,i是维度.这样每个位置的编码都对应三角函数曲线, 波长为2π到10 000×2π, 因此对于任何偏移量k,PEpos+k均可表示为PEpos的线性函数.
2.2.3 编码器
不同图像的局部特征数量可能不同, 为固定特征长度, 在局部特征输入到编码器之前用0 进行填充操作, 使每张图片的局部特征数量相等.在训练过程中, 为防止参数更新受填充特征的影响, 在Softmax操作前, 会添加一个掩码(mask)覆盖这些填充的值. 由于添加的mask值接近负无穷大, 因此在Softmax操作中这些位置的概率无限接近于0.

图5 特征融合点积注意力Fig.5 Feature fusion dot-product attention
在编码器中, 为在训练过程中保留图像特征的位置信息, 在其中加入一维位置编码, 然后输入到多头注意力中. 不同于一般的MHA, 本文提出特征融合点积注意力,Q和K点积得到的注意力权重在局部特征向量的维度上求和, 然后与V交互计算.全局特征和局部特征通过多头自注意力融合作为编码器的输出, 如图5所示, 可表示为
其中Iboxi为当前图像的第i个目标区域特征,Hi,c(x)为图像的全局特征,Wq,Wk,Wv为模型学习的参数.
多头注意力由一个残差子层和一个标准化子层[22]连接, 最后用Zenc作为编码器的输出, 可表示为

(12)
其中Hi,c(x)表示图像的全局特征,F(x)表示一个全连接层, Norm表示一个标准化操作, Dropout比例设为0.1, 即p=0.1.
2.2.4 解码器
图像描述生成是一个语言建模过程.每张图像的描述语句在解码器前进行预处理, 即添加开始标记〈s〉和结束标记〈e〉, 然后使用分词工具进行分词. 每个词生成唯一编号, 整个文档的词根据编号构建成一个字典.
在训练阶段, 用构建的字典表将描述语句转化成数字序列, 并去除结束标记〈e〉, 即{s,v1,v2,…,vn}.为固定特征大小, 将所有序列用0填充到最大长度, 然后通过一个嵌入层转换成词嵌入向量X输入到解码器中;
因为当前序列并未利用位置信息, 所以需在序列中添加位置编码, 使其在训练过程中保留位置信息;
此外需要注意, 当前输入的是整个序列, 为在训练时保有时序性, 需在多头注意力中的序列添加一个上三角为1、 其余为0的掩码, 用于遮挡当前时序中后续标记部分.
在测试推理阶段, 将开始标记〈s〉为头的起始序列输入到解码器, 与编码器类似, 序列用作查询, 编码器输出用作键和值, 在MHA层进行交互计算, 图像和文本关联映射后, 残差子层和标准化子层连接到解码器, 输出一个d维的公共特征向量.一个全连接层使解码器输出转换为一个概率向量Pvocab, 其中vocab表示当前数据集字典表的大小. 本文选择概率最高的索引, 将字典表中索引的词作为当前时间步的输出, 将当前时间的输出依次加入到解码器输入序列中, 直到输出结束标记〈e〉, 最后转换字典表中编号对应的输出序列{s,v1,v2,…,vn,e}生成其图像描述结果.
2.3 损失函数


(13)

3.1 数据集
本文实验所用数据来自数据集ICC[23], 该数据集包含30万张图像, 其中训练集为21万张图像, 验证集为3万张图像, 测试集为6万张图像, 每张图像对应5句中文描述, 如图6所示.

图6 数据集ICC图片示例2Fig.6 Picture example 2 of ICC dataset
3.2 实验环境
本文实验环境基于Tensorflow深度学习框架, 硬件平台为Intel(R) Core(TM) i3-9100F CPU @ 3.60 GHz处理器, 运行内存31 GB, 配置GeForce RTX 2080 Ti 11 GB显卡.
3.3 参数设置
在提取图像特征前, 对图像进行预处理, 将数据集的原始图像缩放至299×299像素大小. Transformer编码器和解码器分别设为6个, 使用8个注意力头. 本文在20 000训练集和1 000验证集上进行实验;
为避免过拟合, Droupout设为0.1;
使用Adam优化算法[24]优化模型参数, batch训练大小设为8, 学习率设为0.000 02, 20轮训练共进行约250 000次迭代训练.
3.4 评价指标
为评估模型的性能, 本文采用图像描述算法中常用的评价指标BLEU(bilingual evaluation understudy)@N[25],METEOR(metric for evaluation of translation with explicit ordering)[26]和CIDEr(consensus-based image description evaluation)[27].
3.4.1 BLEU评价指标
通过计算生成描述和人工描述之间N元词(N-gram)共现的程度, 衡量这两个句子的相似程度, 加权平均后的相似度计算为
其中:Pn为准确度, 与句子长度有关;
hk(ci)为N-gram在生成描述中出现的次数;
hk(sij)为N-gram在人工描述中出现的次数;
BP为惩罚因子;
lc为生成描述ci的长度;
ls为人工描述sij的长度;
本文取N={1,2,3,4},ωn=1/N.
3.4.2 METEOR评价指标
在计算两个句子相似度的同时, 还要考虑同义词的相关信息, 使用同义词库进行辅助计算. 本文采用Chinese Wordnet[28]作为中文同义词库, 计算生成描述在参考描述上的准确率和召回率的调和平均, 计算过程如下:
其中Fpenalty为惩罚因子,ch为描述中连续有序的块,m为匹配上1-gram的个数,P和R分别为准确率和召回率.本文中取α=0.9,γ=0.5,θ=3.
3.4.3 CIDEr评价指标
通过对每个N-gram进行词频-逆文本频率(term frequency-inverse document frequency, TF-IDF)权重计算, 衡量图像描述的一致性. CIDEr主要应用场景为图像描述任务, 计算过程如下:
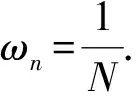
3.5 实验与分析
在数据集ICC上进行测试, 测试结果示例如图7(A)所示, 图中的每张图像都有8句中文描述, 前3句依次为GRU模型、 Transformer(无局部特征)模型以及本文模型生成的描述, 后5句为数据集中的人工描述. 由图7(A)可见, 本文模型能捕捉到图像场景中的细节, 对区域内目标物体的描述更具体, 更接近人工描述的结果. 为探索图像特征在自注意力层内部的可解释性, Abnar等[29]提出了分别取最大值、 平均值和最小值融合多头注意力对其进行可视化. 为体现特征融合模块对图像表征的影响, 在本文编码器中, 取最大值融合多头注意力可视化视觉注意力, 结果如图7(B)所示. 由图7(B)可见, 融合局部特征后, 视觉注意力更容易关注于图像的目标区域周围, 丰富了目标物体的图像描述.

图7 图像中文描述生成示例Fig.7 Image Chinese caption generation example
本文在数据集ICC上比较了GRU,Transformer(无局部特征)和本文模型的3种图像描述生成方法, 评价指标采用BLEU@1,BLEU@2,BLEU@3,BLEU@4,METEOR和CIDEr, 测试结果列于表1. 由表1可见, 本文方法在BLEU@1,BLEU@2,BLEU@3,BLEU@4,METEOR和CIDEr评价指标上均有不同程度的提高.

表1 不同模型在数据集ICC上评价指标的对比
综上所述, 针对传统模型在图像中文描述中存在的问题, 本文提出了一种基于Transformer具有细粒度语义特征的图像中文描述生成方法, 该方法使用多头注意力融合图像的全局特征和局部特征. 通过多头注意力多次聚焦学习图像的目标区域, 在对注意力的可视化发现, 图像的目标区域受到了更强的注意力, 丰富了对图像目标对象的描述. 与其他模型的对比实验结果表明, 本文模型能捕捉到图像场景的细节, 更具体地对区域内的目标物体生成描述, 但可能受对场景或语义对象错误识别的影响.
猜你喜欢 解码器编码器全局 基于ResNet18特征编码器的水稻病虫害图像描述生成农业工程学报(2022年12期)2022-09-09基于改进空间通道信息的全局烟雾注意网络北京航空航天大学学报(2022年8期)2022-08-31领导者的全局观中国医院院长(2022年13期)2022-08-15WV3650M/WH3650M 绝对值旋转编码器传感器世界(2022年4期)2022-08-05WDGP36J / WDGA36J编码器Wachendorff自动化有限公司传感器世界(2022年3期)2022-05-24基于Beaglebone Black 的绝对式编码器接口电路设计*数字技术与应用(2021年1期)2021-03-24基于Android环境下的数据包校验技术分析现代信息科技(2019年18期)2019-09-10落子山东,意在全局金桥(2018年4期)2018-09-26浅谈SCOPUS解码器IRD—2600系列常用操作及故障处理科技创新与应用(2017年26期)2017-09-12做一个二进制解码器中国信息技术教育(2016年13期)2016-09-10推荐访问:中文 图像 描述