基于Excel的模糊筛选系统设计与实现
来源:软件设计师 发布时间:2022-11-18 点击:
王毅敏
(复旦大学 国家级实验教学示范中心,上海 200433)
人类社会自古以来就有处理数据的需求,文明程度越高,需要处理的数据越多、越复杂,所需的处理速度也越快。为此,人们不断改善相关工具来满足数据处理需求。计算机的出现,意味着信息时代来临,人们需要更频繁地与数据打交道。因此,Excel也应运而生。
Excel 为数据处理提供了一个强大的平台,打开该平台,展现给用户的是简洁、友好的操作界面。最上面是一排功能菜单,中间是一些功能组,其中包括一些常用的功能按钮。下面是单元格的编辑区,界面的主要部分是由无数个单元格组成的表格。该界面看似简单,却具有强大的数据处理功能,用户可进行计算、查询、排序、筛选、分类、统计、汇总及图表转换等数据处理工作。Excel 目前已广泛应用于各行各业的日常数据处理。
Excel 在管理信息系统应用方面,以考试和阅卷系统为例,实现了试题管理、自动组卷、自动阅卷与试卷分析功能,还特别实现了操作题的自动阅卷功能,使考试过程更加公平、公正,减少了教师工作量,提高了工作效率。系统采用VBA 等高级语言实现考试过程管理模块、数据库管理模块及阅卷子系统模块功能,但实现过程较为复杂,没有充分利用Excel 现成的函数及功能,且系统升级维护较为困难。
本文介绍利用Excel 提供的工具及函数,无需高级语言编程,即可实现筛选功能,再进一步生成一个模糊筛选系统。在维护模块中,用户可随意进行数据编辑、增加、删除、排序、消除重复项等日常维护操作。
在Excel 的数据输入过程中,为提高数据输入效率,可利用数据验证功能对单元格设置选项,用户可方便地从中选择所需选项。但如果选项数目很多,例如成百上千,则会很不方便。如果让用户输入某个字符,系统通过模糊筛选列出相关选项,从而缩小范围,将会大大方便用户使用。Excel 提供了现成的数据选项功能,但未提供模糊选项功能。因此,本文介绍如何利用Excel 提供的工具及函数,无需编写代码实现上述功能。
要实现该功能,需要有一个辅助区域,以方便对选项数据的处理。该区域处理结果需要放入单元格验证功能的序列选项中,用户才能看到相应结果,以下介绍具体实现过程。
1.1 总体思路
将所有选项数据放在辅助区域中,该区域有数据选项列及模糊筛选列。数据选项列是用户所有选项数据,模糊筛选列是用户感兴趣的选项数据,也是数据选项列的子集。
设计思路如下:最后的目标是从数据选项列中选出所有符合用户要求的数据,放入模糊筛选列中。先判断数据选项列的数据是否与用户输入信息相匹配,如果是,则返回所在单元格地址,否则返回一个很大的值,如65 536。因为与之匹配数据所在单元格的地址可能分散在数据选项列的各处,用排序函数对这些地址从小到大进行排序,使所有小于65 536 的数值都是相关单元格地址,且集中在一起。然后根据这些地址,利用查表函数在数据选项列中取出对应地址单元格的内容,放入模糊筛选列中。65 536这个地址不能在数据选项列中取出任何值,因此返回结果为空。至此,生成了模糊筛选列的结果。根据该结果列出的相应名称,用查表函数取出所有名称放入数据验证功能的序列选项中,则完成了模糊选项设置。具体过程如下:
1.2 实施过程
利用Excel 有关函数FIND、SMALL、OFFSET 等的互相嵌套、数组公式计算及表对象等功能,可完成模糊选项设置的整个过程,以下分4步实现:
(1)确定数据选项列中匹配的数据。用户需要的选项信息全部在数据选项列中,现存放的是大学名称。如用户在选项单元格中输入“河”,在模糊筛选列中,用FIND 函数确定数据选项列中与用户输入信息相匹配的单元格,并将结果存入模糊筛选列中。输入:=FIND(sheet!$a$2,$a$2:$a$63),其中sheet1!$a$2 为用户输入的选项单元格信息,$a$2:$a$63 为数据选项列区域,用数组公式计算结果,如图1 所示。#VALUE!表示对应单元格没有相关字符,如返回的是数字,表示该单元格第N 个字符与用户输入的选项信息匹配。

Fig.1 Determine the matching data in the data option column图1 确定数据选项列中匹配的数据
(2)返回对应单元格行号。可用IF 函数对FIND 函数返回结果进行处理。如果为错误结果,即#VALUE!,表示没有查询到结果,则设置一个很大的值,如65 536 代替行号,否则返回该单元格行号。具体写为:=IF(ISERR(FIND(Sheet1!$A$2,Sheet2!$A$2:$A$63)),65 535,ROW(A2:A63)),其中ISERR 函数返回结果为TRUE 或FALSE,ROW 函数返回数据选项列当前单元格的行号。在模糊筛选列中,65536 对应的是与用户输入信息未匹配的单元格,其它数值是与用户输入信息匹配的单元格行号,ROW(A2:A63)返回该结果。这些行号分散排列,结果如图2 所示。为便于处理,后面需要将这些行号进行集中。

Fig.2 Return to the row numbers of corresponding cell图2 返回对应单元格行号
(3)将行号递增排列。至此,模糊筛选列中的结果是与用户输入信息匹配的对应单元格行号以及65 536 等数据。一般情况下,这些单元格行地址分散在模糊筛选列的各处,为便于处理,需要将相关行号集中在一起。可对行号进行升序排列,便于后面集中按该行号获取名称。
利用SMALL 函数实现排列,嵌套上面的结果,该函数可让数据从小到大进行排列。可以写成=SMALL(IF(ISERR(FIND(Sheet1!$A$2,Sheet2!$A$2:$A$63)),65535,ROW(A2:A63)),ROW()-1),该函数返回的是第N小的数放在相应位置,如最小的放在第一个位置,第二小的放在第二个位置,依此类推。该函数有两个参数,第一个为数据区域,第二个为序号,其中数据区域为前面运行的结果,序号为所在单元格行号,在这里表示第N 小的数。运行结果如图3 所示,B2 单元格为最小的数,依此类推。

Fig.3 Row numbers in ascending order图3 行号递增排列
(4)取出对应行号内容。可以用OFFSET 函数,根据上面升序排列的行号查找工作表中数据获得名称。65 536是一个很大的数值,在这里没有查询结果,返回为空。函数参数说明为:OFFSET(reference,rows,cols,[height],[width]),reference 为起始单元格或单元格区域;
rows 为前面第一个单元格开始的相对行位置;
cols 为前面第一个单元格开始的相对列位置,这里设为0;
[height]、[width]为可选项,是所取单元格行或列的高度或宽度。根据本案例,具体函数可写为:=OFFSET($a2$,SMALL(IF(ISERR(FIND(sheet!$a$2,$a$2:$a$12)),65 536,ROW($a$2:$a$12)),ROW()-2),0,1,0)。也即是说,从$a2$单元格位置的第一行开始,根据上述SMALL 函数嵌套计算的行号结果,从数据选项列中查找到对应地址的单元格内容。所取单元格行方向高度为1,即一个单元格,放入模糊筛选列中,该模糊筛选列中的结果即为模糊筛选后的名称集合。需要说明的是,该函数需要启用数组公式进行计算。如用户输入“河”,在模糊筛选列中集中显示所有包含“河”的名称,如图4所示。

Fig.4 Extract the content of corresponding row number图4 取出对应行号内容
(5)将选项结果放入数据验证功能的序列选项中。上述4 个步骤实现了根据用户输入信息在数据选项列单元格中匹配到相关信息,并通过FIND 函数、SMALL 函数及OFFSET 函数嵌套,将模糊筛选结果放入模糊筛选列中。最后需要将该结果放入数据验证功能序列选项中,供用户选择。这里仍然用OFFSET 函数实现:=OFFSET(Sheet2!B1,1,,A3),Sheet2!B1 是模糊筛选列开始的单元格,A3存放的是模糊筛选列区域中可供选择的选项数目,也即行的高度。如高度计算结果为5,则表示取出连续5 个单元格的区域内容,可用COUNT(FIND(Sheet1!$A$2,Sheet2!$A$2:$A$63))计算得到。COUNT 函数是计数函数,返回的是数值数目,FIND 函数运行过程在上文已有介绍,这里不再赘述。
至此,已完成了将辅助区域中的模糊筛选列数据放入数据验证功能自定义选项的过程。当用户在数据选项的数据单元格中输入某个字符时,如“河”,则可以列出包含“河”字符的所有选项名称,如图5所示。

Fig.5 Fuzzy filtering result图5 模糊筛选结果
上述功能完成后,仍有一个缺陷,即在辅助区域中,数据选项列的数据日常维护很不方便,无法进行增加或删除,否则会报错。原因是数据选项列及模糊筛选列中的单元格都是一个固定区域,在相关函数中也引用了这些固定区域。在用户使用过程中,一些选项数据难免会产生变化,用户需要对这些选项数据进行增加、删除等操作。为了让用户可以自由增加或删除这些选项数据,需要进一步完善相关功能。
Excel 提供了多种方法来解决该问题,在此,可利用表对象自动延展的特性实现功能优化。优化后,用户可对辅助区域数据选项列中的所有名称数据进行排序、编辑、增加及删除等操作,从而十分方便地对这些数据进行日常维护。以下是优化具体步骤:
(1)将数据选项列中的工作表数据转化为表对象。选定数据选项列区域,选中名称为“插入”的选项卡,按下表格组中的表格按钮,从而将选定区域转换成表对象。
(2)确定数据选项列中的所有相关单元格,并返回对应单元格行号。在数据选项列右边最上面的第一个单元格中输入公式。根据用户输入信息,用FIND 函数确定数据选项列中与之相匹配的单元格,该函数公式为:=IF(ISERR(FIND(Sheet1!$B$2,表1[[#数据],[数据选项列]])),65 536,ROW())。与上一节介绍的类似,Sheet1!$B$2 是用户的输入数据,表1[[#数据],[数据选项列]]是表对象的结构化引用。该公式表示选中了一个名称为“表1”的表对象,字段名为数据选项列中的数据部分(不包括字段名)。该数据为所有选项数据,即大学名称。回车后自动生成结果,并增加一列,将列名称自动命名为“列2”。至此,“列2”中的数据是根据数据选项列的数据,经过函数计算后的结果,如图6所示。

Fig.6 Return to the row numbers of corresponding cell图6 返回对应单元格行号
(3)将相关单元格行号递增排列。“列2”中列出的是与查找结果相匹配的单元格行号,显示的是对应数据选项列中单元格的行号,或者用一个很大的数值代替行号,这里采用65 536。现在要对“列2”中的数据进行递增排列整理,即将行号从小到大升序排列。这样做的目的是:可将找到的名称放在最前面,便于集中管理。在“列2”数据列右边第一个单元格中输入公式:=SMALL(表1[[#数据],[列2]],ROW()-2),则系统自动生成“列3”,所列数据是“列2”的升序排列。SMALL 函数可实现将列中数据按从小到大排列,其中表1[[#数据],[列2]]为“列2”中的数据,ROW()-2 为第N 小。如某单元格为第3 行,则ROW()-2 计算结果为1,表示最小,后面依此类推,如图7所示。

Fig.7 Row numbers in ascending order图7 行号递增排列
(4)取出单元格对应行号内容。“列3”中列出的行号是对应选项数据列中的数据名称。因此,可用OFFSET 函数取出选项数据列中的名称,在“列3”数据列右边第一个单元格中输入公式=OFFSET(表1[[#标题],[列1]],[探讨列3]-2,,1,),系统自动生成“列4”。所列数据是“列3”行号对应“列1”的名称,将“列4”名称改为“模糊筛选列”,如图8所示。

Fig.8 Extract to the content of corresponding line number图8 取出对应单元格行号内容
(5)将模糊筛选列中的名称加入选项中。模糊筛选列中的数据是模糊选项功能运行后的结果,该结果是模糊选项单元格中的选项数据。针对模糊选项单元格的数据验证功能输入公式=OFFSET(Sheet3!D:D,2,,B3,),其中Sheet3!D:D,2 表示从sheet3 的D 列第二个单元格开始查询,B3 内容为模糊筛选列中的选项名称数量,计算公式为=COUNT(FIND($B$2,表1[[#数据],[数据选项列]]))。
现输入数据测试一下功能:在模糊选项单元格中输入“东”,点击单元格右边按钮,则列出与“东”相关的大学名称,如“东北林业大学”“东北财经大学”“山东师范大学”等,如图9所示。
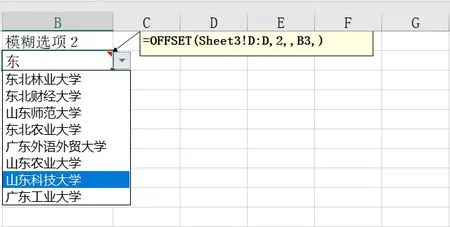
Fig.9 Fuzzy filtering result图9 模糊筛选结果
某单位有40 多个部门,员工有1 万名左右,需要做一个模糊筛选系统。相关数据包括:部门名称、员工姓名、员工工号。部门名称按拼音顺序或按笔划顺序排列,可以进行选择;
员工姓名可进行模糊筛选;
员工工号无须输入,由系统自动确定。具体实现过程如下:
3.1 功能实现
以上介绍了面向用户的功能,如何实现上述功能?这是设计者需要完成的任务,这里简要介绍一下实现思路。
按照用户习惯,首先确定部门,然后确定该部门中的员工,所以可用两层筛选实现。部门名称选项功能可利用Excel 中现成的数据验证功能实现,姓名与部门名称关联,确定部门名称后,再进行模糊筛选确定一组姓名。确定这组姓名中的某个人姓名后,用VLOOKUP 函数查询到结果,由系统自动填入。
如何实现模糊筛选并优化功能,在前文已有介绍,这里介绍一下部门名称与员工姓名的关系。两者是“与”的关系,即两者都存在,才出现最后的模糊筛选结果,并列出在选项列中供用户选择。
表中的“列8”与“列9”用来判断部门名称及员工姓名是否存在,运行结果为TRUE 或FALSE,“列8”“列9”的计算公式分别为:=NOT(ISERR(FIND($N$3,表3[[#数据],[部门]])))以及=NOT(ISERR(FIND($O$3,表3[[#数据],[姓名]])))。根据$N$3 单元格中的部门名称及$O$3 单元格中的姓名查找相应的列,返回结果为TRUE 表示找到,FALSE 表示没有找到。如为空则为TRUE,即为找到。现在$N$3 单元格中的部门名称为空,$O$3 单元格中的姓名也为空,辅助区域结果如图10 所示,即列出所有选项。

Fig.10 Results of auxiliary area图10 辅助区域结果
“列4”中的公式为:=IF([探讨列8]*[探讨列9]*1,ROW(),65536)。根据“列8”及“列9”的结果,进行逻辑“与”运算,如为TRUE,则返回一个结果所在的行号,否则返回一个很大的数值,如65 536(该数字表示无法在表中找到结果)。依据“列4”中的行号,在“列5”及“列6”中按升序排列行号,并查出相应姓名及部门。公式分别为=OFFSET(表3[[#标题],[姓名]],SMALL(表3[[#数据],[列4]],ROW()-2)-2,,1,)及=OFFSET(表3[[#标题],[部门]],SMALL(表3[[#数据],[列4]],ROW()-2)-2,,1,),这是最后选定部门名称及模糊查找员工姓名后的结果,范围已大幅缩小,用户可从中选定一个姓名。一旦选定了姓名,系统利用公式=IFERROR(VLOOKUP(O3,表3[[#数据],[列5]:[列7]],3,FALSE),""),确定员工工号。
现在$N$3 单元格中的选定部门名称为“通信与信息工程学院”,$O$3 单元格中的姓名为空,图11 列出了辅助区域结果,即列出该部门的所有员工姓名。图12 列出了$N$3 单元格部门名称及$O$3 单元格中该部门的所有员工姓名可选名单。
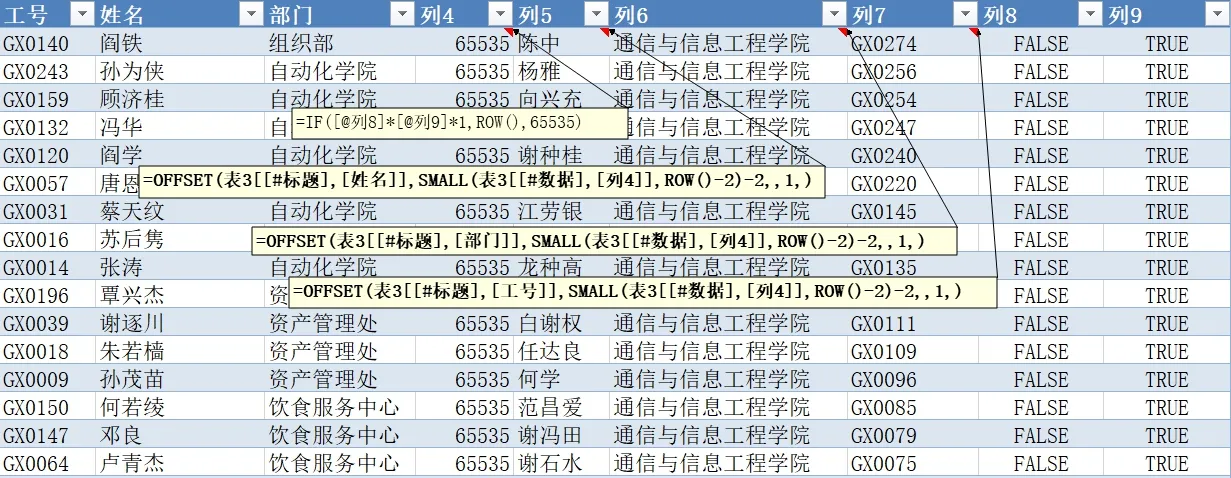
Fig.11 Results of logical operation“and”图11 逻辑“与”运算后的结果

Fig.12 Names of all employees in the selected department图12 选定部门所有员工姓名
由于通信与信息工程学院有教职员工几百名,在$O$3单元格中输入“谢”,运行模糊筛选功能后,列出所有包含“谢”的名单,如图13 所示。从中选定一个员工姓名,$P$3单元格自动确定该员工工号。

Fig.13 Fuzzy filtering result图13 模糊筛选结果
在辅助区域中,工号、姓名、部门是用户数据,后面几列是辅助列,可利用Excel 功能将其隐去。整个数据区域是一个表对象,用户可对这些数据进行日常维护,如增加、删除等,不会对功能有任何影响,这些更新后的数据可在选项列中同步出现。
3.2 功能测试
(1)编辑及增删数据。在实际使用中,选项中的数据不是固定不变的,有时需要进行修改、增加及删除操作。辅助区域已转换成表对象,利用表对象的扩展功能,只需输入选项名称,回车后系统会自动扩展将其加入表对象记录。另外,也可很方便地对数据进行修改。如果用户输入重复的选项数据,可利用表对象删除重复项的功能进行处理。所有修改、增加及删除后的数据,将在用户选项数据的单元格中自动同步更新。
(2)数据排序。辅助区域输入的选项数据很多,可能有几百甚至上千,如果能够按一定的方式排序,将会极大地方便数据管理。由于辅助区域已转换成表对象,可利用表对象排序功能很方便地按拼音或笔划进行升序或降序排列,用户选项数据的单元格中也将自动同步更新。
(3)模糊选项。该单位有上万名员工,有可能会出现姓名相同的情况,但工号一定不会相同。现有两员工姓名都为“韩向权”,一名在办公室,一名在数理学院。选定单位名称为办公室,在姓名列表中为办公室的韩向权。另外,办公室有多位王姓员工,输入“王”,则在姓名列表中列出所有王姓员工。
3.3 应用总结
在该实例中,该单位的员工有近万人,如全部为选项数据,不方便用户使用。这里采用分两层选项的方法,很好地解决了此问题。第一个选项为部门,第二个选项为所属部门员工,从而大幅减少了选项数目,操作上也更适应用户习惯。系统已通过上述测试,运行正常。
Excel 提供了强大的数据处理平台,操作界面友好,用户使用方便。除界面上的功能外,还有500 多个函数及大量现成的加载程序,可协作完成各种数据处理工作。为满足用户的个性化需求,Excel 提供了功能扩展接口及VBA 程序开发环境,前者可加载宏代码或其它相关程序,后者可利用Excel 平台开发用户自己的程序。为充分利用其强大的数据处理能力,Excel 提供了数据导入接口,支持各类数据库文件导入Excel 中进行数据处理,也支持SQL 语言对导入的数据进行预处理。
本文设计了一个模糊筛选系统,利用多个函数及其相应功能,包括表对象、数组公式等,还有各种函数的调用嵌套配合。可以这样理解,Excel 提供了各种数据处理工具,这些工具有些存在于界面菜单中,有些存在于函数中,用户可根据具体情况和具体问题对其进行灵活组合,针对性地解决如数据计算、排序、查询、筛选、分类、汇总、统计,甚至数据转图表等数据处理问题。
本文详细介绍了模糊筛选系统的设计思想及用Excel方法实现该设计的过程。该系统可分为前台与后台:前台根据部门及姓名可方便、快捷地从一万多名员工中选出某位员工;
后台可对基础数据进行日常维护,以适应基础数据的变更与增删。系统不仅提高了信息输入效率,而且减少了信息输入工作量、降低了出错率,还能很好地适应基础数据的变化需要。如果用户需要用其它数据进行模糊筛选,只需替换一下基础数据即可,而不需要重新设计,因此具有较好的可维护性和复用性。