面向高渗透率新能源电网的短期负荷预测算法设计
来源:优秀文章 发布时间:2023-04-27 点击:
王 运,孙小湘,祁 鑫,张天睿,陈 婧
(1.宁夏电力调度控制中心,宁夏银川 750001;
2.北京清能互联科技有限公司,北京 100084)
化石能源的过度消耗所带来的能源枯竭、环境污染问题,催生出了新能源技术。其技术种类多样、发展迅速,并具有较高的渗透率,这对电网的短期负荷预测提出了较大挑战。
目前,常用的负荷预测技术包括时间序列预测、神经网络和卡尔曼滤波估计器,具体实现方法包括基于长短期记忆(LSTM)的电器行为学习、人工神经网络、基于遗传的多层感知以及模糊专家系统等。
该文使用聚类技术,基于卡尔曼滤波技术与小波神经网络设计了短期电网负荷预测算法。
电网短期负荷的消耗特征定义方式种类繁多,因此该文使用聚类技术[1]在数据分析软件R-studio和Matlab的辅助下,采用统计分析方法定义短期消耗的特征[2],建立具有共同特征的数据共同区域[3]。创建聚类区域后,将数据提供给后续估计算法进行预测,进而减少预测数据的误差[4]。降低误差的关键因素为数据群的大小及数量。故尝试使用不同的集群数量与大小组合,并验证预测数据及实际数据的误差[5],经统计分析后得出结论。电网负荷数据聚类的最佳选择,是将其聚类到6 个不同的簇数[6]。通过多次实验可知,若簇数大于8 或小于2,则后续识别算法无法正常工作,因此数据分类簇数的最佳选择为6。
基于朴素的K-means 技术对负载段进行聚类时,定义Z为具有t个实例的数据,可将Z分类为K个不相交的聚类S1,S2…,SK[7]。则误差E可由下式定义:
其中,μ(Si)是簇Si的质心。D(y,μ(Si))是数据点y与μ(Si)之间的距离,即任何数据点的欧几里德距离。而对于数据yi=(yi1,yi2,…,yin)与yj=(yj1,yj2,…,yjn)的欧式距离可通过下式定义:
该文使用多种预测模型,将聚类数据聚合到预测混合模型中,如图1 所示。
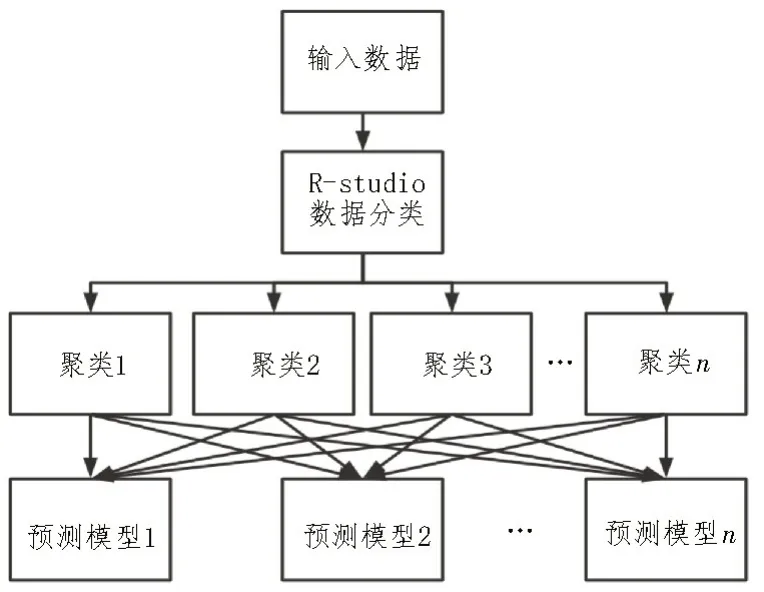
图1 输入输出聚类预测聚合模型
如图1 所示,将数据首先送入聚类算法,再把聚类后的数据送入不同的预测模型以选择最佳预测模型组合,然后将数据聚合为一个模型。
2.1 卡尔曼滤波预测算法
卡尔曼滤波预测器是使用线性动力系统进行状态估计的最常用方法之一,该模型定义如下:
2.2 小波神经网络预测算法
小波神经网络(WNN)具有与人工神经网络(ANN)相同的能力,其在隐藏层中具有不同的激活函数[8]。由于激活函数为局部小波函数,WNN 具有更紧凑的技术与学习速度,输出类似于ANN 方式的加权小波总和[9]。定义wjk为隐藏单元j和输入单元k之间的权重[10],则加权输入总和定义为fj(n):
式中,xk(n)为第k个输入。每个隐藏神经元的输出定义为:
其中,ψ为小波函数,aj(n)定义为尺度,bj(n)为隐藏神经元中小波函数的平移系数。输出神经元的输入f(n)与输出y(n),wij是输出i与隐藏单元j之间的权重,由以下等式定义[11]:
式中,σ表示输出与输入间的映射关系。
2.3 特征构建工程
由于特征构建和选择在基于神经网络的预测模型中起着重要作用,因此该文深入分析了基于神经网络中的权重选择特征及其重要性[12]。表1 显示了数据集的R2 得分,其用于表征数据拟合的优度,是预测任务的重要特征。

表1 数据集的单输出模型结果
为了解决特征重要性的表征问题,将不同输入特征的神经网络权重归一化后进行评估。这提供了特征重要性的定性描述,但没有准确的结果分析[13]。MT1-OP20 实验中存在代表电力生产周期时间滞后特征的权重较高(R2 得分为0.6 以上),而MT1-OP10基线数据和MT2-OP10 测试集数据中存在的其他时间滞后和移动平均特征的归一化权重均低于0.151。由此表明,电力生产与非电力生产时间之间的区别较为重要。因此,预测模型中需要引入电力生产计划这一重要特征[14]。
2.4 超参数选择
图2 展示了独立的超参数值对预测性能的影响。文中涉及的超参数包括特征个数、不同算子以及隐藏单元数量[15]。

图2 各类因素对预测性能的影响
图2(a)表明,特征个数为200 时,训练集误差显著变大,因此较大的特征集有明显的缺点。因此需要针对每个新数据集调整超参数,从而在给定搜索空间内找到最佳组合[16]。
经过实验可以发现,训练过少会导致训练集和测试集欠拟合。而训练过多则会导致模型过拟合,从而使得测试集性能不佳。因此,该文使用以下策略防止过拟合的发生:一旦验证数据集的性能开始下降,则停止模型训练;
图2 的三个超参数对系统影响表明,无法确定具有一般意义的超参数设置规则,这说明需要针对每个新数据集进行超参数调整。
为了评估此次的混合模型,采用真实数据集进行训练。数据运行环境采用了运行在Intel i3-2370MCPU 和2 GB RAM 上的Matlab 计算软件,并使用2020 年1-12 月的电力负载值来训练WNN。同时,采用了2021 年1-12 月的数据来测试WNN。每小时的预测结果如图3 所示,Y表示模型输出的百分比误差。基于双层预测模型的百分比误差分别为3.8%和3.81%,ANN 预测模型的百分比误差分别为2.2%和2.23%,基于混合预测模型的误差百分比均为1.24%。

图3 每小时预测误差实验
每日的预测结果如表2 所示。从表中能够清楚地看到,基于ANN 的预测模型预测未来负荷时偏差最大。与其他两个现有模型相比,所提出的混合预测模型预测未来负荷时偏差最小。基于混合预测模型的短期负载预测算法相比其他两种模型更为准确。

表2 每日预测误差实验
预测策略的准确性与其收敛速度之间存在取舍,双层预测模型提高了预测模型的准确性,但导致收敛速度相对较慢。混合预测模型由于采用并行的结构,在提高预测精度的同时,在执行时间方面并未付出较多的成本。图4 为训练数据样本的数量对预测模型误差性能与执行时间的影响。

图4 训练数据样本数量对模型性能的影响实验
通过图4(a)可知,当输入样本的数量从30 增加到120 时,能够改善所有模型的误差性能。当训练样本数量从60 增加到120 时,对于预测模型的改进效果并不显著。图4(b)显示了样本数量对于执行时间的影响,由于训练样本的数量增加,人工神经网络的训练也需要更多时间。从图4 中可以看出,与其他两个模型相比,所提出的混合预测模型更具可扩展性,即拥有相对更高的稳定性。
表3 显示了在两组数据集上的平均绝对百分比误差(MAPE)与3 个预测模型的迭代次数之间的关系。收敛特性(即迭代次数)表明,基于混合模型和双层模型在几乎相同的迭代次数中收敛至最优值。而基于ANN 的预测模型只需20-23 次迭代即可收敛至最佳目标值,但这种最小的计算负担是通过付出高昂的预测准确性成本来实现的。因此,基于混合模型的预测算法实现了比ANN 模型和双层预测模型略高的运算性能。

表3 MAPE与模型迭代次数关系统计
可再生能源供需侧均存在波动性和不确定性,因此负荷预测是智能电网的关键一环。该文针对基于聚类技术的短期负荷预测提出了混合模型,为了提高短期预测的效果,使用基于卡尔曼滤波与小波神经网络的混合模型对电网负荷进行了短期预测。
智能电网区别于传统的电网技术,具有较高的动态性,这为管理带来了挑战。此时,智能电网的信息传输更加高效,能为管控提供更多的参考信息。而如何在时变系统下研究电网负荷的短期预测问题,将是该研究下一步的重点。
猜你喜欢聚类神经网络电网穿越电网数学大王·趣味逻辑(2021年11期)2021-12-03神经网络抑制无线通信干扰探究电子制作(2019年19期)2019-11-23基于DBSACN聚类算法的XML文档聚类电子测试(2017年15期)2017-12-18基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26基于神经网络的拉矫机控制模型建立重型机械(2016年1期)2016-03-01电网也有春天河南电力(2016年5期)2016-02-06复数神经网络在基于WiFi的室内LBS应用大连工业大学学报(2015年4期)2015-12-11一个电网人的环保路河南电力(2015年5期)2015-06-08电网环保知多少河南电力(2015年5期)2015-06-08基于支持向量机回归和RBF神经网络的PID整定海军航空大学学报(2015年4期)2015-02-27推荐访问:新能源 电网 算法