基于EEMD-Kmeans-ALO-LSTM的短期光伏功率预测
来源:优秀文章 发布时间:2023-04-10 点击:
朱 坤,付 青
(中山大学物理学院,广东广州 510275)
光伏发电作为新能源的代表之一,在中国获得了巨大的发展,越来越多的光伏电站接入到电网[1]。但是光伏功率与气象因素高度相关,具有波动性、随机性、不稳定的特征,因此给电网的稳定运行和调度带来了新的挑战。针对此问题,国内外学者通过研究光伏功率短期和超短期预测问题,提前做好电网规划,提高电网运行的稳定性。
预测模型方面,部分研究主要使用浅层神经网络构建模型,进行光伏功率预测时会因为模型欠拟合而导致预测精度不足[2-5]。相较于浅层神经网络在解决复杂问题时的劣势,深度学习有着更好的学习能力和泛化能力[6],因此成为近两年光伏功率预测领域的新星。文献[7-9]采用深度学习完成光伏功率预测任务,但是由于原始序列的波动性,使得模型精度仍有不足。在数据预处理方面,文献[10]使用经验模态分解(empirical mode decomposition,EMD)对光伏功率序列进行分解,降低波动性后,分别使用LSTM 预测各分量再合并为最终结果,但未考虑EMD 分解可能存在模态混叠的问题进而影响预测精度。文献[11]引入变分模态分解(variational mode decomposition,VMD)对光伏功率序列分解后使用LSTM 模型进行预测,但LSTM 的网络层数以及网络神经元个数依据主观经验进行调节无法确保模型精度[12]。另外在预测模型所需信息方面,以上研究均依赖气象信息,针对单变量光伏功率预测的研究较少。
为了解决上述模型存在的问题,考虑到EEMD 和LSTM的优势[13],提高模型的适用范围,本文将EEMD 和LSTM 结合并且引入Kmeans 算法对EEMD 分解后的光伏序列分量进行合并重构,提出EEMD-Kmeans 数据处理方法。Kmeans 聚类算法从空间上(欧氏距离)计算分量之间的相似度,相似的分量合并会降低分解后序列的数量和复杂度,从而降低模型运算时间,同时提高预测精度。然后采取ALO 算法替代传统人工调参,对LSTM 的参数进行优化,使预测网络达到最佳状态。通过实验证明本文提出的EEMD-Kmeans-ALO-LSTM 单变量组合预测模型相较于其他模型(LSTM、BPNN、EEMD-LSTM等)具有更好的预测精度,并验证了EEMD-Kmeans 数据处理方法能够在一定程度上提高数据质量进而提高预测精度。
光伏功率数据本身具有较强的日周期性,但是由于受到天气的影响大,具有较强的波动性、随机性和不稳定性。为了减少随机波动对光伏功率预测精度的影响,本文首先采取EEMD 算法对光伏功率数据进行分解,得到不同时间尺度的数据分量,并采取Kmeans 聚类的方式将分量进行聚类合并,降低数据复杂度,提高模型训练速度和预测精度。
1.1 集成经验模态分解
EMD 是一种适用于非线性、非平稳序列的信号分解方法,理论上可用于任何非平稳的信号,可以将信号分解为不同时间尺度的本征模函数(intrinsic mode function,IMF)和残余项(res),相比传统分解方法,具有直接、直观、后验、自适应的特点。EMD 的分解结果形式如式(1)所示。

式中:ci(t)为IMF 分量;
res为残余项;
p(t)为光伏功率原始序列。
实际应用中,由于光伏功率波动性大,存在噪声干扰,因此在EMD 分解过程中可能出现模态混叠现象,不能获得理想的光伏功率子序列,使预测的可靠性和适用性下降。而EEMD 在分解过程中添加了高斯白噪声,解决了模态混叠问题,实现了信号在适当时间尺度的自动分布,也保证了分解方法依然具备先验性。EEMD 的计算步骤如下:(1)在光伏功率信号中加入高斯白噪声;
(2)对上一步的光伏功率序列进行EMD 分解,分解得到n只IMF 分量ci(t)和残余项res;
(3)迭代进行前两步,重复次数N,每次加入不同幅值大小白噪声,对每次分解的IMF分量求和,并且以平均值作为最终的IMF分量。
1.2 K 均值聚类算法
Kmeans 思想简单,对于确定的样本集合,算法将样本集合分为K个簇,让簇中的样本点尽可能接近,同时保证簇间距离尽可能大[14]。
设聚类的簇为Ci,ui为簇Ci的均值向量,即:

则最小化平方误差E为:
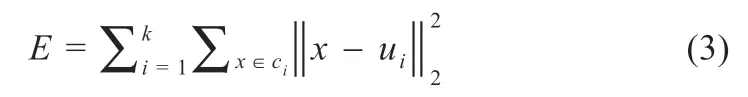
本文中,输入样本集为分解后的12 个IMF 和残余项(res),设定K为聚类簇数,经过多次实验,K值为8 时预测效果最好。Kmeans 的计算流程如下:
(1)从13 个样本序列中随机选择8 个样本作为初始质心向量:{u1,u2,...u8}。
(2)分别计算每个点到8 个聚类中心的欧氏距离,进而将该点分到与聚类中心最近的簇。
(3)重新计算每个簇的均值,重复前两步,直到均值不再变化,输出聚类结果C={C1,C2,...C8}。
Kmeans 算法将形态相似的分量进行聚类,随后将分类一致的分量进行相加合并,增强合并后分量的整体趋势,减少了噪声对整体趋势的影响,降低序列的复杂度,进而提高预测精度,同时因为合并导致分量数量减少,能够提高模型的训练和预测速度。
2.1 蚁狮优化算法
ALO 算法是Seyedali Mirjalili 在2015 年提出的模仿自然界中蚁狮狩猎过程的启发式算法[15]。该算法模拟了猎物(蚂蚁)的随机游走,蚁狮设置陷阱、捕食猎物以及重建陷阱等主要步骤。首先,猎物的随机游走会使其陷入蚁狮设置的陷阱,该过程中猎物游走的超球面会不断缩小,加快算法收敛。然后,蚁狮捕食猎物,将位置更新至猎物位置,重建陷阱,获取更好的狩猎机会,寻求更优解,因此算法具有优秀的全局搜索能力。同时,结合精英蚁狮和轮盘赌策略使得ALO 算法具有更好的寻优能力。ALO 算法具有使用简单、寻优精度高的优点,在文中用于优化LSTM 的超参数。
2.2 LSTM 神经网络
LSTM 神经网络模型是一种改进的循环神经网络(RNN),通过记忆细胞保存前一时刻的历史信息,并且通过遗忘门有选择地记忆或者忘记历史信息,解决了RNN 存在的梯度爆炸和梯度消失的缺点,因此适用于长时间序列预测问题。LSTM 模型的计算节点有输入门、输出门、遗忘门和记忆细胞Cell。其中输入、输出、遗忘门是控制信息的关键,遗忘门是对需要记忆信息的筛选,Cell 则用来更新当前时刻状态。输入门的xt经过激活函数sigmoid 和tanh 后控制记忆单元中的保存向量,其中xt为光伏功率输入向量。记忆单元遗忘部分由xt和上一时刻中间输出ht-1决定。中间输出ht由更新后的St和ot决定。计算方法如下:

式中:ft,it,gt,ot,St,ht分别为遗忘门、输入门、输入节点、输出节点、输出门、状态单元状态值;
Wfx,Wfx,Wfh,Wix,Wih,Wgx,Wgh,Wox,Woh,bf,bi,bg,bo分别为对应门与输入和中间输出的权重矩阵(W)及对应门的偏置矩阵(b),最终输出层的预测值yt=σ(Wyht+by)。
2.3 ALO-LSTM 预测模型
由于LSTM 没有数学理论用以确定其最优参数,而ALO算法具有优秀的全局寻优能力,因此本文采用ALO 算法优化LSTM,确定其最佳网络结构,提高LSTM 的预测性能。其具体步骤如下:
(1)输入光伏功率数据,并且将其划分为测试集和训练集。
(2)分别初始化ALO 和LSTM 网络参数,随机生成LSTM网络。
(3)通过LSTM 的损失函数计算ALO 的适应度。
(4)根据蚁狮的位置求得需要优化的LSTM 参数最优解。
(5)将上一步得到的最优解代入LSTM 网络进行预测,并输出预测结果。
为了对具有非线性和强波动性的光伏功率序列进行精准预测,本文结合EEMD 与LSTM,使用Kmeans 算法对EEMD 分解后的序列进行聚类重构,提出EEMD-Kmeans 数据处理方法,同时引入ALO 算法优化LSTM 的网络参数,设计了基于EEMD-Kmeans-ALO-LSTM 的组合预测模型。其具体步骤如下:
(1)原始光伏序列处理:利用EEMD 方法对光伏历史数据进行分解,得到一组IMF 和残余项res。
(2)对步骤(1)中的IMF 分量和残余分量使用Kmeans 聚类成8 类,即重构为8 个子序列。
(3)数据归一化:将步骤2 中重构后的子序列分别归一化处理。
(4)将步骤(3)得到的子序列分别使用训练后的ALOLSTM 进行预测。
所有子序列预测完毕后,将数据反归一化后叠加,最终得到预测结果。
本文将从单一预测模型、优化预测模型(群智能算法优化LSTM 模型)、组合预测模型(结合分解聚类)三阶段分别验证本文所提EEMD-Kmeans-ALO-LSTM 模型中组成成分,LSTM、ALO群智能算法、EEMD-Kmeans数据处理方法的优越性。
4.1 数据来源与预处理及评价指标
本文数据集源于DC 国能日新第二届光伏功率预测赛公开 数据集,采 用2017 年4 月1 日~2017 年8 月30 日 上午8 点到下午6 点之间的数据,采样周期为15 min,数据总量为6 040组数据,其中4 832 组观测值用于训练,占比80%,1 028 条数据用于测试,占比20%。本文数据在整理后统一经过数据清洗,标准化处理,后者利于统一量纲,并提升预测模型的收敛速度和防止预测模型梯度爆炸。
为了严谨地评估模型的预测精度,本文共使用三项指标作为依据,包括:平均绝对误差(mean absolute error,MAE)、均方根误差(root mean-square error,RMSE)、平均绝对百分误差(mean absolute percentage error,MAPE)。
4.2 分解及聚类重构结果
本文使用EEMD 分解算法对光伏功率数据进行分解,将原始序列分解12 个IMF 与一个剩余项,由于迭代次数N取值为100 的整数倍时效果较好[16],因此分解过程中N=200。其结果如图1 所示,其中IMF1、IMF2、IMF3 的波动频率较高但幅值较低,大部分数值集中在0~1 之间,表征了光伏功率的高频分量,res是剩余项,表征原数据的非线性低频趋势。由图1 中可知,经EEMD 分解得到的每个分量能够描述不同时间尺度的波动特征,各分量波动频率均衡,不存在明显的时间尺度差异,克服了EMD 的模态混叠现象,与原序列相比,除IMF1~IMF3 以外的子序列均更加稳定,波动频率更低,有利于后续的预测。之后使用Kmeans 算法对其进行类别划分,分 为8 类,即:[IMF1],[IMF2,IMF7,IMF9],[res],[IMF11,IMF12],[IMF6,IMF10],[IMF4],[IMF3,IMF5],[IMF8]。同时,重构后分量数量由13 减少为8,提高了模型训练及预测速度。为了证明分解和聚类对于预测精度具有一定的增益作用,本文的实证将讨论模型LSTM、EEMD-LSTM、EEMDKmeans-LSTM 预测的效果。

图1 EEMD 的分解结果
4.3 单一模型实证分析
在本文中,单一模型LSTM、支持向量回归(support vector regression,SVR)、BP神经网络(back propagation neural network,BPNN)和极限学习机(extreme learning machine,ELM)均用来拟合原始光伏功率序列,其拟合结果精度如表1所示,ELM 的整体精度低于其他单一模型,SVR 的MAE 指标在当前数据下具有较好的表现,其值为0.731 4,但是其他指标均未达到最优效果。LSTM 的预测结果与其他模型相比具有较小的误差,其MAPE 为39.366 2%,RMSE 为1.094 8,均达到最优。同时,预测结果如图2 所示(截取部分样本点图便于观察),黑色为真实数据,紫色为LSTM 预测结果,可以看出,原始数据的波动性较大,在变化较集中且复杂的部分难以预测,但紫色曲线整体拟合较好。通过以上分析可得出,在对原始序列进行拟合时,LSTM 具有最优的结果,因此后续工作以LSTM 为基础预测模型。
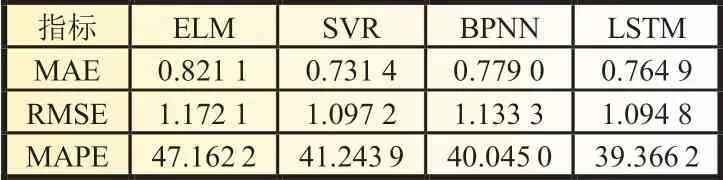
表1 单一模型预测精度

图2 单一模型预测结果
4.4 优化LSTM 模型实证分析
验证了单一模型中LSTM 针对本问题具有最佳预测性能以后,本文对优化LSTM模型进行验证,该过程主要分为粒子群优化算法(particle swarm optimization,PSO)、遗传算法(genetic algorithm,GA)、ALO 三种优化算法对LSTM 参数进行一定修正,预测结果详情见表2和图3。图3 中ALO-LSTM 预测值(紫色)与实际值(黑色)拟合相对较好。相比较LSTM,PSO-LSTM的三项指标MAE、RMSE 和MAPE 提升度分别为3.486 6%、0.417 0%和8.358 7%,GA-LSTM 的三项指标提升度分别为3.529 9%、0.968 2%和5.437 9%,其MAE 和MAPE 指标均不如ALO-LSTM。而ALO-LSTM 与LSTM 相比,其MAE、RMSE和MAPE的提升度分别为5.237 8%、0.557 2%和10.774 6%。从结果可知,优化LSTM 模型在一定程度上优于单一模型,且ALO算法针对本问题对LSTM 的优化效果最佳。

表2 优化LSTM 模型预测精度
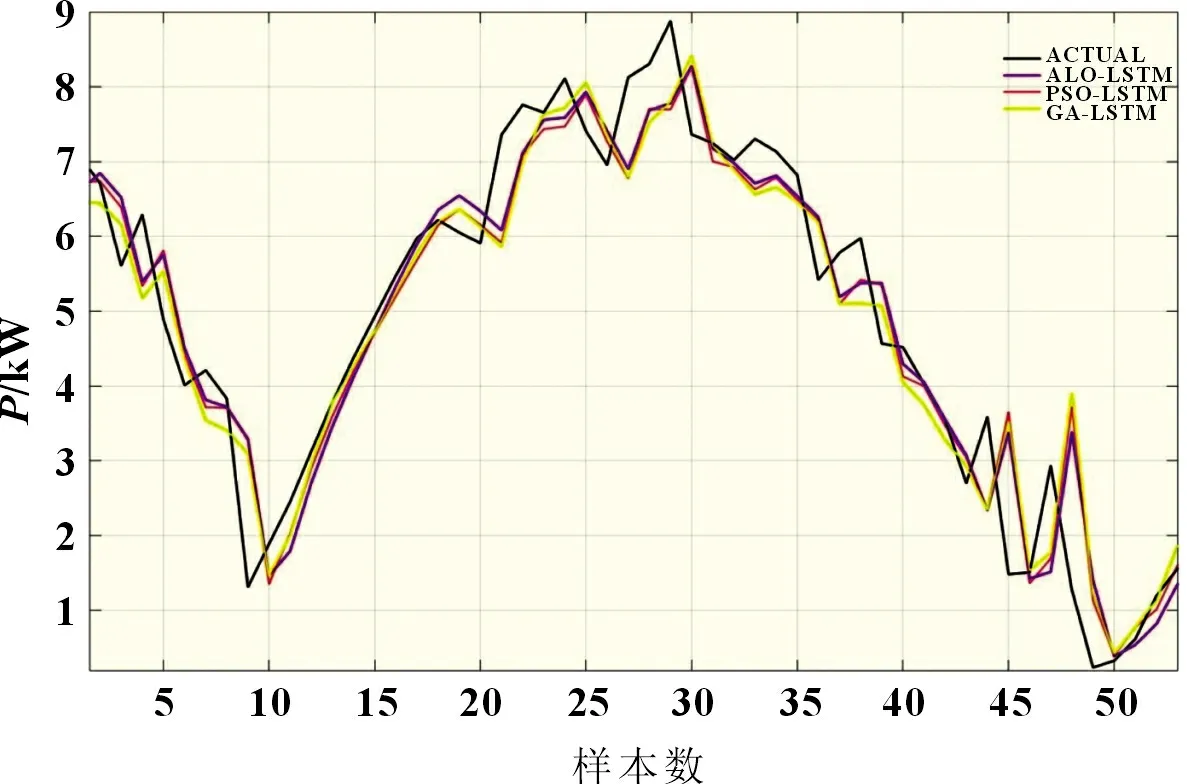
图3 优化LSTM 模型预测结果对比
4.5 组合模型实证分析
通过实验得到预测指标结果如表3 所示,相比于LSTM和优化LSTM 模型,组合模型的精度明显更高,其中EEMDLSTM 相对于ALO-LSTM 模型的三项指标MAE、RMSE 和MAPE 提升度分别为59.690 9%、57.297 6%和63.930 7%。因此,分解对于预测精度的提升效果更为明显。本文通过计算序列纯度,将聚类数目设置为8(此时聚类后子序列纯度最高、预测精度最高),即原本的13 支分量聚类至8 只,此过程所构造模型为EEMD-Kmeans-LSTM(H1)。如表3 所示,H1 相对于EEMD-LSTM 模型,其三项指标MAE、RMSE 和MAPE 提升度分别为5.941 38%、2.322 27% 和15.684 5%;
相对于LSTM,其MAE、RMSE 和MAPE 的提升度分别为64.075 8%、58.526 7%和72.864 7%。

表3 组合模型预测精度
经过上述实证分析可知,LSTM 在单一模型中预测精度最高,ALO 对于LSTM 具有更好的优化效果,EEMD-Kmeans数据处理方法相对于EEMD 能进一步提高模型运算速度和精度。因此将三者进一步组合,提出EEMD-Kmeans-ALOLSTM(H2)组合预测模型,其指标和预测结果如表3 和图4 所示(由于模型预测结果比较接近,因此采用误差对比图)。由图4 可以看出,黄色曲线(EEMD-LSTM)离X轴最远(样本数1 000 到1 200 之间尤为明显),而红色曲线(H1)在误差较小的部分拟合不如紫色曲线(H2),且大误差值较多,而紫色曲线(H2)整体更加接近X轴。并且从表3 可以得出,相对于H1 模型,H2 的三项指标MAE、RMSE 和MAPE 的提升度分别为9.345 2%、9.310 2% 和15.152 8%。因此可以证明EEMDKmeans 数据处理方法和ALO-LSTM 模型的组合是有效的,本文提出的EEMD-Kmeans-ALO-LSTM 模型在当前数据集上具有最高的预测精度。
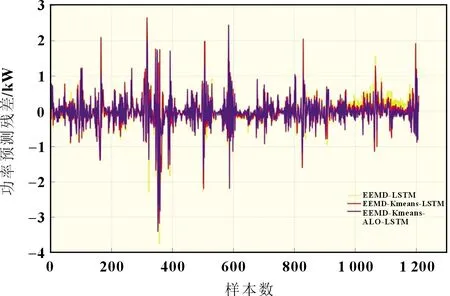
图4 组合模型预测残差对比
本文针对光伏功率预测精度低的问题,提出了一种基于EEMD-Kmeans-ALO-LSTM(H2)的单变量短期光伏功率预测模型,并采用DC 国能日新光伏功率预测竞赛公开数据集进行实验。实验结果表明,相对于EEMD-LSTM,H1 和H2 模型的主要误差指标MAPE 分别降低了15.7%和28.5%,证明了本文所提模型的有效性。通过实验探究得出以下结论:
(1) 群智能算法能够实现对LSTM 网络参数的优化从而达到更好的预测效果,而ALO 算法相对于PSO 算法、GA 算法,具有更好的优化效果。
(2) 本文提出的EEMD-Kmeans 数据处理方法相对于EEMD 方法,能进一步提升数据质量并且降低分量数量,从而提高预测精度和预测速度。
(3)本文探究了单一模型和优化模型,结合探究结果提出了H2 单变量组合预测模型,该模型具有较高的预测精度。
本文所提模型仅仅依赖光伏功率历史数据,未对环境因素对光伏功率预测的影响做太多探究,因此后续研究中应考虑结合环境因素对该模型进行探究。
猜你喜欢分量聚类精度热连轧机组粗轧机精度控制一重技术(2021年5期)2022-01-18超高精度计时器——原子钟中学生数理化·八年级物理人教版(2019年9期)2019-11-25一斤生漆的“分量”——“漆农”刘照元的平常生活当代陕西(2019年19期)2019-11-23一物千斤智族GQ(2019年9期)2019-10-28基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08分析误差提精度中学生数理化·八年级物理人教版(2019年12期)2019-05-21论《哈姆雷特》中良心的分量英美文学研究论丛(2018年1期)2018-08-16基于DSPIC33F微处理器的采集精度的提高电子制作(2018年11期)2018-08-04基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04推荐访问:功率 光伏 预测