基于FPGA的改进的排序QR分解实现
来源:优秀文章 发布时间:2023-01-21 点击:
陈健,庄耀宇,杨丹,张俊杰
[1.上海大学通信与信息工程学院,上海 200444;
2.特种光纤与光接入网重点实验室(上海大学),上海200444]
随着人们对移动通信需求的急剧增加,复杂的数据通信和处理将成为移动通信中一个重要挑战[1-4].多输入多输出(Multiple-Input Multiple-Output,MIMO)技术的高带宽、低延迟、强鲁棒性的特性使其成为下一代移动通信的关键技术[5].
虽然MIMO 技术在不增加额外频谱和功率消耗的情况下能显著提高通信系统的容量和质量,但是与传统的单输入单输出(Single-Input Single-Output,SISO)通信系统相比,MIMO检测需要包含空间维度在内的多维度信号处理,复杂度更高.与此同时,MIMO系统发射天线所引起的同信道干扰为信号的检测增加了难度[6].因此,近些年来,人们针对不同的MIMO传输方案提出了不同的检测算法.
MIMO 检测算法主要分为线性检测算法和非线性检测算法两大类.虽然线性检测算法复杂度较低,但检测性能不如非线性检测算法.迫零(Zero-Force,ZF)检测算法和最小均方误差(Minimum Mean Square Error,MMSE)检测算法[7]是两种典型的线性检测算法.它们利用信道矩阵得到加权矩阵,对接收信号进行判决.为了提高线性检测的精度,排序的连续干扰消除(Ordered Successive Interference Cancellation,OSIC)方法[8]采用一组线性接收机,每个接收机检测数据流中的一个符号,其次,在每个阶段都能够成功地从接收信号中删除已检测出的信号成分,从而减少对后续待检测信号的干扰.
非线性检测算法中,最大似然(Maximum Likelihood,ML)检测是一种最优的检测算法[9-10].传统的ML 检测通过计算接收信号向量和所有可能的后处理向量之间的欧氏距离,找到一个最小距离来进行判决.由于ML 要遍历搜索所有可能的发送信号,其复杂度随信号调制阶数和发射天线数呈指数上升.文献[1]提出了一种基于Cholesky分解和k-best检测相结合的检测方案.其中k-best[11]是一种次优检测算法,对矩阵进行Cholesky[12]分解是为k-best检测做预处理.通过选择合适的k值使得检测性能逐渐逼近ML.然而对矩阵进行Cholesky 分解,该方法要求该矩阵正定对称,适用范围受限.QR 分解(QR Decomposition,QRD)算法[13-14]不但可以为诸如k-best 检测算法做预处理,其本身也可作为一种非线性检测手段进行信号检测.QR 分解通过对接收到的信号进行分层检测从而消除符号间的干扰.同时QR分解避免了复杂的矩阵求逆运算且适用性最广.但是在分层检测的过程中,容易出现误差累积效应.因此,基于排序的QR分解算法被提出[15-16].
研究者们针对QR 分解的实现提出了不同方案.矩阵进行QR 分解主要包括格拉姆-施密特(Gram-Schmidt,GS)正交化[17],豪斯霍尔德(Householder)变换[18]和吉文斯(Givens)变换[19]三种方式.由于Givens变换只包含酉矩阵的乘法且运算逻辑简单,更适合硬件实现.文献[14]和文献[20]提出了一种基于Givens 变换的QR 分解的FPGA 实现方案,但是都没有引入排序过程.本文主要工作如下:
1)通过对各类QR 分解实现方案的对比,选用Givens 变换作为QR 分解的实现方案并基于脉动阵列设计相应的电路结构.
2)由于L2 范数的计算复杂度较高,本文改进了排序QR 分解中的基于L2 范数的排序方案,采用L1范数进行排序.Matlab 性能仿真显示,改进后的方案对系统性能的影响几乎不变.同时L1 范数在单个列范数计算中组合逻辑资源比L2 范数至少节省29.2%,触发器资源至少节省32.4%.
3)针对排序QR分解的实现特点,本文设计了基于串行迭代的排序单元.利用该排序单元对N个数据进行排序,只需要N个比较器,且迭代延迟为N+1个时钟周期.排序的QR分解中只需要进行最小值交换,因此最终只会产生1个时钟的排序延迟.
1.1 系统模型
图1给出了MIMO系统中一个典型的信号传输模型.发射天线数为NT,接收天线数为NR.发射信号矢量,接收信号矢量
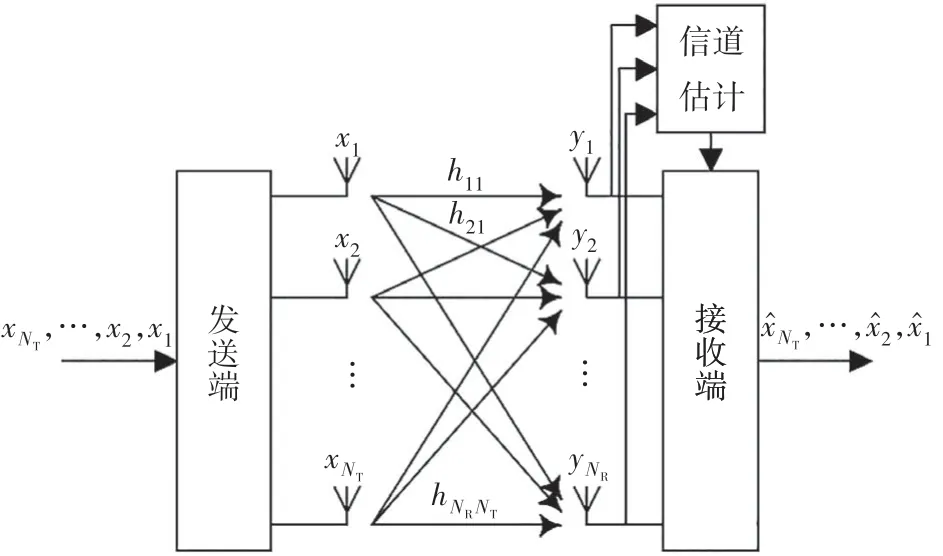
图1 MIMO系统模型Fig.1 The model of MIMO system
信道传输矩阵H表示为:

式中:hji表示第i根发射天线和第j根接收天线之间的信道增益,它们统计独立且服从高斯随机分布[7,21].在本文中,我们将一直假定信道信息已知.则该NR×NTMIMO系统可以表示为:

式中:z=是均值为0,方差为的加性高斯白噪声.
1.2 QR分解检测
相较于ZF 检测和MMSE 检测,QR 分解检测避免了复杂的求解伪逆矩阵的过程,受到了人们的广泛关注.NR×NT(NR≥NT)的MIMO 信道传输矩阵H,进行QR分解后可以得到:

式中:Q是NR×NR的酉矩阵且满足QHQ=I;
R是NT×NT的上三角矩阵.接收信号y左乘QH得到:
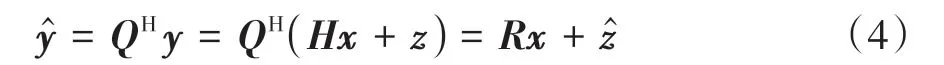
式中:=QHz.为方便阐述,我们假设NR=NT=N,并将式(4)改写为:

由于Q是酉矩阵,因此QHz不会放大噪声.考虑到第N层信号的检测不受其他层的干扰,先从第N层开始检测,得到第N层信号的估计值:

式中:Q[·]表示按照信号调制方式作判决.利用第N层得到的估计值消除对第N-1 层的干扰,从而得到第N-1 层的估计值依此类推,那么第k层的估计值可以表示为:
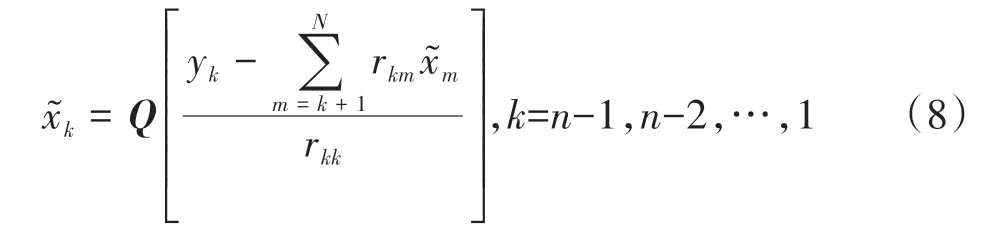
显然,这种方式容易存在持续的误差累积.为了降低误差传播,理想的检测是使每一层的SNR 尽可能大,第k层的信噪比可以表示为:
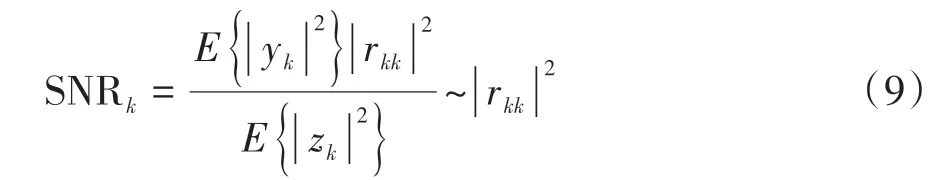
从式(9)可以看出,每层的SNR 正比于R矩阵的主对角线元素,因此应使QR 分解后得到的R矩阵的主对角线元素尽可能从左往右单调不减,即rNN≥rN-1N-1≥… ≥r22≥r11.这便引出了基于排序的QR分解.
1.3 基于Givens变换的排序的QR分解
图2 以4 × 4 复矩阵的分解为例,展示了不同分解方法的计算复杂度[22].整体来看,Householder 变换复杂度最高,GS 变换复杂度较低.由于Givens 旋转只包含酉矩阵的乘法,被认定为是一个数值稳定的算法,且可以通过旋转的方式来代替除法和开方运算.因此,在本文中,我们采用Givens 旋转的方式来实现QR分解.

图2 分解方法的复杂度Fig.2 The complexity of decomposition methods
以2 × 2 复矩阵为例,阐述Givens 旋转过程.给定复矩阵H:

为了使左下角的元素H10变为0,复数Givens 旋转运算如下:

式中:θ0==-∠H00;
θ2=-∠H10;
R10=0.排序的QR 分解检测是在分解的过程中引入排序,使得R矩阵的主对角线元素尽可能按照升序排列.对矩阵进行排序的QR 分解时,首先通过对比原始矩阵列向量范数的大小,对矩阵的列向量进行交换.利用交换后的矩阵进行Givens 旋转.在每轮旋转完成后,需要再次排序并进行列向量交换.一个N列的矩阵H一共需要N-1 次迭代排序.在本文中,我们以列向量的L1 范数的大小作为参考进行排序.Givens 旋转排序的QR 分解的伪代码逻辑如表1 所示.此外,当矩阵H列欠秩时,对矩阵H进行QR 分解后,会导致分解得到的R矩阵主对角线上的元素有0的情况.结合QR 分解的检测流程,当其中某一层主对角线为0 时,会产生严重的误判.因此,QR 分解不太适用于欠秩的MIMO信道.

表1 Givens旋转的排序QR分解Tab.1 Sorted QR decomposition based on Givens rotation
2.1 整体结构设计
为了硬件实现排序的QR 分解,我们提出的整体结构如图3 所示.该结构主要由三个部分组成:信道矩阵的存储RAM、范数排序单元以及Givens 迫零旋转单元.为了方便范数计算以及Givens旋转,信道矩阵以列向量的形式存储到RAM 中.范数排序单元对RAM 地址中的列向量重新进行映射.映射的结果同样按列向量的形式保存到由RAM 构成的Buffer 中.Givens 迫零旋转单元一次只对一列进行迫零.对于NR×NT的信道矩阵H,则需要NT次迭代且在每一次迭代之前重新对列向量排序.

图3 排序QR分解结构Fig.3 The architecture of sorted QR decomposition
2.2 排序方案设计
相较于传统的QR 分解算法,排序的QR 分解在实现过程中不可避免地会引入排序延迟.目前研究者们基于FPGA 的并行排序已经设计出了不同的方案[23-26].考虑在QR 分解的实现方案中,以矩阵列向量串行输入,通过构建脉动阵列的方式,达到节省资源的目的.因此,本文构建了基于迭代的串行排序单元.图4 展示了该单元的硬件结构.它由2 个数据寄存器、2个多路选择器和1个比较器组成.
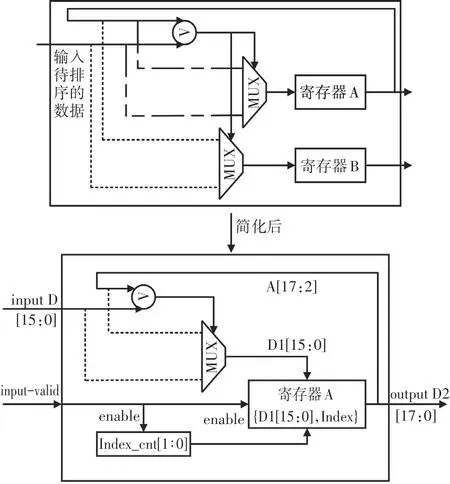
图4 串行迭代排序单元Fig.4 Sorting unit based on serial iteration
我们假设当前按照升序排序.寄存器A 在初始化时,存储当前位宽下所能表示的最大无符号数.当待排序的数据被送入该排序单元,立刻与寄存器A中的数据进行比较.较小的数据被写入寄存器A,较大的数据被写入寄存器B 用于后续的迭代比较.在排序的QR 分解中,我们需要找到L1 范数最小的列向量.因此我们做了进一步的简化.简化后的排序单元只需要1个寄存器、1个比较器和1个多路选择器.但多了一个索引计数器.索引计数器的计数值范围为0~3,初始化为0.待排序的数据以每个时钟1 个数据的方式串行送入该排序单元.信号input_valid 高电平表明当前输入数据有效.同时索引计数器和寄存器A 利用该信号完成数据的更新.当数据D 被送入该单元后,立刻与寄存器A 中的数进行比较.如果D 小于A,则将数据D 连同当前的索引计数值一同写入寄存器A,否则寄存器A中的数保持不变.检测input_valid 的下降沿作为排序结束标志,寄存器A 和索引计数器同时重新初始化.
2.3 列向量映射交换设计
如2.1 小节所述,整体结构中的范数排序单元,除了完成对信道矩阵H列L1 范数的排序,还需要依据排序的结果对矩阵列向量进行重新映射.这里以4 × 4 的H矩阵第一轮迭代为例说明映射的过程.为了方便描述,我们定义矩阵的列向量从左至右依次为第一列、第二列,并以此类推.排序QR分解的目的在于使得分解后的R矩阵的主对角线元素从左至右尽可能按照升序排序.因此我们选择L1 范数最小的列与第一列进行交换.在计算L1 范数时,我们从左至右依次读取每一列数据,然后按照读顺序,通过修改RAM 写地址的方式,完成矩阵的列交换.图5 给出了对应的读写流程.如果排序得到的最小范数由第一列产生,那么列向量的写地址依次为{0,1,2,3};
如果由第二列产生,列向量的写地址依次为{1,0,2,3};
如果由第三列产生,写地址依次为{2,1,0,3};
如果由第四列产生,写地址依次为{3,1,2,0}.

图5 排序映射逻辑Fig.5 Sorting and mapping logic
2.4 Givens迫零旋转设计
任何n阶复非奇异矩阵H=(hj,i)可通过左乘有限个复初等旋转矩阵转化为上三角矩阵,且对角线元素除最后一个外都是正数[27].参考式(11),在对第i列第j行元素hj,i迫零时,利用hj,i和hj-1,i得到旋转角度,且迫零运算过程中,矩阵的乘法只对第j行元素和第j-1 行元素产生影响.图6 为4 × 4 矩阵的Givens 旋转运算的过程,首先利用X31和X41对X41进行迫零,然后利用第一次迫零的结果R31和X21对R31进行迫零,最后利用第二次迫零的结果R21和X11对R21进行迫零.至此第一列属于下三角的元素全部变为0.同样的流程,第二列需要2 次迫零运算,第三列需要1次迫零运算.

图6 4 × 4矩阵Givens旋转过程Fig.6 The process of Givens rotation on 4 × 4 matrix
为了得到旋转所需要的角度以及完成相应的矩阵乘法运算,设计了图7 所示的硬件单元,包括边界单元和迫零运算单元.在边界单元中,通过调用Xilinx Cordic IP 核得到旋转矩阵所需要的角度,迫零运算单元主要利用边界单元得到的角度,完成复数乘法运算.

图7 QR分解硬件组成单元Fig.7 The hardware units of QR decomposition
结合式(11),图8 展示了边界单元具体的角度运算流程.由于θ0的计算需要先得到H00和H10的模,然后再求解反三角得到角度,最后才能得到正弦和余弦的值.相较于θ1和θ2的计算,多出了求解反三角的延迟.我们对(11)进行改写,得到:

图8 旋转角度计算流程Fig.8 The calculation process of rotation angle

我们通过在迫零计算单元中先计算(cosθ1+jsinθ1)H00和(cosθ2+jsinθ2)H10,从而可以将求解反三角函数的延迟隐藏在迫零运算中,达到减少等待延迟的目的.图9 展示了基于边界单元和迫零计算单元的脉动阵列结构.该阵列结构对矩阵第一列除主对角线元素进行迫零运算.通过逐列读取RAM 的方式,完成一轮迫零迭代.

图9 Givens旋转脉动阵列Fig.9 The systolic array of Givens rotation
3.1 Matlab仿真分析
本文利用Matlab 对不同算法的性能进行对比分析.实验仿真环境选择数据帧长度为10 000,调制方式采用16-QAM(Quadrature Amplitude Modulation,QAM)调制,信道为平坦瑞利衰落信道,噪声为均值为0 的加性高斯白噪声.图10 和图11 以4 × 4 MIMO模型给出了检测算法在不同的SNR 下的误符号率.从图10 中可以看出,系统误符号率从低到高依次为:ML,Givens 旋转的排序QR 分解(Givens SQR),QR分解,MMSE,ZF.
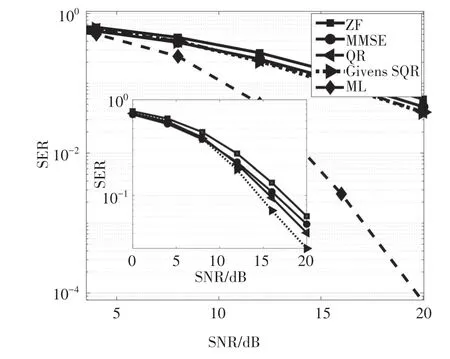
图10 各类算法性能仿真Fig.10 The performance simulation of different algorithms

图11 L1范数和L2范数性能对比Fig.11 The performance comparison between L1-norm and L2-norm
图11 给出了分别利用L1 范数和L2 范数进行排序对系统性能的影响,其中Givens SQR1 表示基于L1 范数排序,Givens SQR2 表示基于L2 范数排序.虽然在Givens 旋转时引入了排序,但是并不能使得分解后的R矩阵的主对角线元素从左至右严格按照递增的要求排序.从图11 的仿真结果来看,两种排序的方案所起到的效果几乎相同.
表2 给 出 了 在4 × 4、32 × 32、64 × 64 三 种MIMO 模型下的不同SNR 的误符号率.从仿真结果来看,所提出的算法在多种场景下,其算法性能具有一致性.当收发天线规模扩大后,算法的检测性能也进一步提高.

表2 算法性能对比Tab.2 The comparison of algorithm performance
由于浮点数运算会占用较多的硬件资源,因此在本文中采用定点数的方式实现整个逻辑的设计.图12 以相同的仿真环境展示了不同精度的数据表示对系统性能的影响.8 位定点小数性能较差.10 位定点小数性能略低于浮点表示,但基本满足检测需要.为了保证运算的精度以及防止数据溢出,我们采用16 bit量化的方式.其中1 bit符号位,5 bit整数位,10 bit小数位.数值的表示范围为-32≤n≤31.999 023 4,精度为1/210.
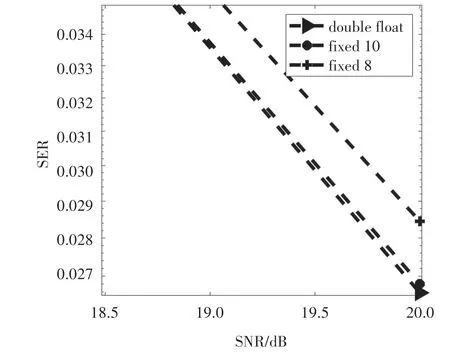
图12 数据精度对比Fig.12 The comparison on different precisions
3.2 硬件逻辑仿真
为了验证本文所提结构的正确性.利用Mentor Graphics 的Modelsim 仿真平台搭建仿真环境并与Maltab 的结果进行对比.在Matlab 端产生了4 × 4 的平坦瑞利衰落信道并按照3.1小节所述进行量化,量化后的结果作为激励导入到所提设计中.
图13 展示了对读取的矩阵列向量求解L1 范数并以其为参考进行排序以完成矩阵列向量交换的过程.Norm_1_result_valid 表明当前求解的范数有效,Norm_1_result_temp 表示某一列向量的L1 范数值.按照RAM 读取顺序,分别为第一列、第二列、第三列和第四列.Recent_min_norm 表明了当前排序中最小的列向量范数,其中低2 bit 为该范数所对应的列向量标号.Norm_sorting_finish 标志着列向量排序结束.Ram_data_o 表示按照读顺序需要重新写入RAM 的数据.Ram_data_addr 为当前Ram_data_o 所要写入的RAM 地址.由于当前迫零迭代下,第一列的范数最小,因此按照2.3 节的地址映射逻辑,写地址依次为0,1,2,3.参考Matlab,L1 范数的求解和排序交换映射逻辑正确.

图13 排序并交换列向量Fig.13 Sorting and exchanging matrix columns
图14 展示了QR 分解的Modelsim 仿真和Matlab仿真的对比结果.此时Matlab 仿真得到的R矩阵主对角线元素恰好是单调不减的.在Modelsim 仿真图中,Rotate_wr_ram_valid_temp 表明当前写RAM 数据和地址有效.Rotate_wr_ram_addr_temp 表示当前时钟周期下写数据所对应的写地址.Rotate_wr_ram_dout_temp 表示分解完成后矩阵列向量中的4 个元素.RAM地址0对应矩阵的第一列,地址1对应矩阵的第二列,地址2对应第三列,地址3对应第四列.仿真误差范围控制在10-3内.基本满足作为原理模型的需要.

图14 QR分解的结果Fig.14 The results of QR decomposition
3.3 FPGA布局实现
本文主要是利用矩阵L1 范数来替换L2 范数.对于4 × 4 复矩阵,每列中包含4 个复数.L1 范数可以直接利用Xilinx Cordic IP 核进行求解.L2 范数在忽略开方的情况下,可以利用复数乘法器乘共轭复数或者在模值的基础上做平方运算获得.本文基于Xilinx FPGA VC709 开发套件,以默认综合选项对相关资源进行了评估.表3给出了Cordic 核进行8 次旋转迭代,复数乘法器以及无符号数乘法器所需要的硬件资源,其中数据位宽都是16 bit.FF 表示触发器资源,LUT表示查找表资源.因此,对于一个4 × 4 矩阵求某一列向量L1 范数时,需要2 424 个LUT,2 504个FF.而求L2 范数时,至少需要3 428 个LUT,3 708个FF.表4 中给出了整体资源使用情况及电路性能.为了便于流水线实现,我们对每一级运算结果都做了缓存,因此占用了较多的存储资源.

表3 计算单元资源利用情况Tab.3 The resource utilization of computing units

表4 整体资源消耗情况Tab.4 The resource utilization of the entire design
图15 展示了基于VC709 FPGA 设计的QR 分解硬件电路板级测试结果.利用Matlab 将经过量化后的两个4 × 4 复矩阵导出成Coefficient 文件,作为板级测试的初始化文件,并保存在只读存储器ROM中.当FPGA 上电后,QR 分解处理单元循环地从ROM 中读取数据进行运算.通过调用Xilinx 提供的集成逻辑分析仪IP 核对运算结果实时抓取.OUT_VALID 高电平表明当前时刻运算结果有效.Aij_I 表示矩阵第i行第j列元素的实部,Aij_Q 表示矩阵第i行第j列元素的虚部.图中以矩阵第四列的结果进行了展示.板级测试结果与仿真预期结果一致,结果正确.

图15 FPGA板级测试结果Fig.15 The test results on FPGA
本文基于矩阵列向量的L1 范数设计了排序的QR 分解硬件电路结构.利用L1 范数进行排序,单列计算中LUT 资源至少节省29.2%,FF 资源至少节省32.4%.通过Matlab 仿真,所提出的优化算法在大规模MIMO 场景下仍有适用空间.针对范数排序问题,我们设计了基于串行迭代排序单元,只需要利用一个比较器便可完成一次迭代中的排序需要.在每次Givens 旋转角度计算中,我们依靠6 个Cordic 核完成相应的运算.并基于脉动阵列构建了矩阵乘法运算单元.对4 × 4 复矩阵进行分解时,本文所提出的结构主频性能得到明显改善并通过仿真以及板级测试分析,电路功能正确.
猜你喜欢 范数排序信道 基于同伦l0范数最小化重建的三维动态磁共振成像波谱学杂志(2022年1期)2022-03-15信号/数据处理数字信道接收机中同时双信道选择与处理方法火控雷达技术(2021年2期)2021-07-21作者简介名家名作(2021年4期)2021-05-12恐怖排序科普童话·学霸日记(2020年1期)2020-05-08节日排序小天使·一年级语数英综合(2019年2期)2019-01-10一种高效多级信道化数字接收机的设计与实现雷达与对抗(2018年3期)2018-10-12一种无人机数据链信道选择和功率控制方法北京航空航天大学学报(2017年3期)2017-11-23基于加权核范数与范数的鲁棒主成分分析中国校外教育(下旬)(2017年8期)2017-10-30基于非凸[lp]范数和G?范数的图像去模糊模型现代电子技术(2016年5期)2016-05-14基于导频的OFDM信道估计技术北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27推荐访问:分解 排序 改进