基于SOINN的欠采样方法在网络入侵检测中的应用
来源:优秀文章 发布时间:2022-11-18 点击:
吴署光,王宏艳,王 宇,温晓敏,3,李海滨,4,周尚辉,5
(1.航天工程大学 航天信息学院,北京 101400;
2.中国人民解放军32039部队,北京 102300;
3.中国人民解放军93719部队,内蒙古 呼和浩特 010000;
4.中国人民解放军66242部队,内蒙古 锡林郭勒 011216;
5.中国人民解放军95806部队,北京 100076)
网络入侵检测系统(Network Intrusion Detection System,NIDS)通过检测通信中产生的数据包加以分析来发现未经授权的恶意操作。神经网络、SVM、决策树等机器学习算法已经非常广泛地应用在入侵检测系统中,并且取得了比较好的检测效果。但由于在网络系统中采集到的原始网络流量通常表现为正常流量远大于异常流量,存在严重的类别不平衡问题,部分机器学习算法进行分类时,在少数样本上的效果比较差,由此可见,有效解决数据不平衡问题对于提高分类器性能非常重要。
解决数据不平衡问题主要方法有欠采样、过采样和混合采样。其中,欠采样的目的是减少多数类样本中的一些数据,随机子集选取(Random Subset Selection,RSS)是最为简单的一种方法,即随机从训练集中选取数据,这种方法的不足之处是可能丢失对分类器贡献较大的多数类样本,不能提升模型的整体性能。基于Kmeans的欠采样方法采用滑动窗口机制,将窗口内的数据进行聚类,把每个窗口得到的聚类中心作为欠采样后的数据。文献[6]采用K-means算法得到多数类样本的簇中心点,然后按顺序选取与簇中心点距离最近的样本。文献[7]提出一种多元敏感性欠采样(Diversified Sensitivity Undersampling,DSUS)算法,该算法在聚类的基础上,按照敏感度大小来选择样本。这类欠采样方法没有根据簇内样本的总体信息进行筛选,对于构建分类器而言有些聚类中心的价值很低。过采样的目的是增加少数类样本的数量,SMOTE(Synthetic Minority Oversampling Technique)是目前应用最为广泛的方法之一,它的原理是计算近邻少数类样本之间的线性插值,从而形成新的样本。混合采样的方法则是将两种方法相结合,对于少数样本采取过采样方式增强样本数量,对于多数样本采取欠采样方式筛选有代表的样本,使数据平衡。文献[10]采用高斯混合模型进行聚类,从每一个簇中提取若干样本,减少多数类样本,采用SMOTE进行过采样。
上述两类欠采样方法会造成多数类样本信息丢失,最后选取的样本不能很好地代表原始数据的特性,影响最终的分类器性能。基于以上问题,本文将自组织增量学习神经网络(Self-organizing Incremental Neural Network,SOINN)算法应用于欠采样。由于SOINN在增量学习过程中会自动保存已学知识,学习完成后形成的少量样本保留了原始样本的特性。因此,本文利用SOINN对多数类样本进行数据精简,得到平衡后的数据样本,然后将数据输入有监督分类器中加以训练来实现入侵检测功能。
SOINN是一种基于竞争学习的神经网络,该算法是在生长型神经气(Growing Neural Gas Network,GNG)的基础上进一步改进,使得拓扑学习能力得到了增强,特征向量的数目进一步减少。算法输出为分布在特征空间的神经元和神经元之间的连接关系,神经元分布大致反映了原始数据的分布特性,连接关系构成了数据的拓扑结构。算法以在线的方式动态地更新网络,且不影响之前的学习效果,降低了学习过程中的存储开销。
实验证明,单层SOINN网络与双层SOINN网络具有同样的学习效果,且训练参数进一步简化。本文采用了单层SOINN网络算法,主要有以下几个步骤:
1)设定初始神经元数量和连接关系集合,假设={,},其中,的权重为,∈R,,为样本集R中的2个随机样本,初始化连接关系集合⊆×为空集。
2)接收样本∈R,通过计算欧氏距离,查找中与最近的2个神经元和,即:

式 中:W 表 示 神 经 元的 权 重;
和命 名 为 获 胜 神经元。
3)计算和的相似度阈值,对于任意神经元,设其邻居神经元的集合为N,则的相似度阈值T的计算公式为:
如果N≠∅

否则

若‖-W ‖>T或‖-W ‖>T成立,则进行类间插入,为生成一个新的节点,=⋃{},W =,返回步骤2)继续接收样本,否则执行步骤4)。
4)若和没有连接关系,则建立2个神经元的连接,即=⋃{(,)},将这条边的年龄设为0,即age=0。
5)更新年龄参数,即age=age+1,∈N,N为的邻居神经元;
将超龄的边删除,即若age>age,={(,)},其中age为预先定义的参数。
6)更新获胜神经元及其邻居节点的权重:

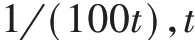
7)学习完个样本后,意味着一个学习周期结束,此时要删除密度比较低的神经元。若没有学完个样本,则返回步骤2)继续接收新的样本。
神经元集合以及连接关系集合为算法的输出。
SOINN采用了竞争学习的方式,自适应地调整相似度阈值,以此来识别新的输入模式。网络动态生成新的神经元,可以自动保存已经学习到的知识,算法输出的少量样本可以表示样本数据的分布特性。两种神经元插入方式和噪声删除机制使得输出数据数量远远小于原始的数据。基于此,本文提出一种基于SOINN的欠采样方法,并将其应用于入侵检测以检验应用效果。
2.1 基于SOINN的欠采样方法的实现流程
未经欠采样的入侵检测模型存在严重的数据不平衡问题,影响有监督分类器检测效果。本文提出的基于SOINN的数据欠采样方法可解决数据不平衡问题,实现流程如图1所示。
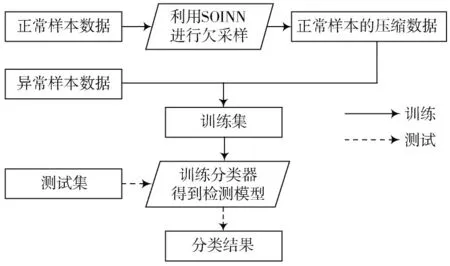
图1 基于SOINN的欠采样方法在入侵检测中的应用流程
算法步骤为:
Step1:对数据集进行数值化和降维,根据标签类型划分样本空间;
Step2:根据正负样本数量比例来确定正常样本的切割数量,分块输入SOINN进行欠采样,得到采样后的正常样本;
Step3:将采样后的正常样本和剩余比例的异常样本进行拼接,组成训练集;
Step4:将训练集输入分类器,训练后得到检测模型;
Step5:将测试集输入已经训练好的检测模型,计算相关评价指标。
2.2 分块采样方法
实验表明,直接将SOINN进行数据压缩,形成的神经元数量与输入数据规模不成正比关系,而是随着输入数据量增大,采样率逐渐减小。图2表示输入数据规模与采样率的关系,实验参数取=300,age=50。若直接将数据量大的样本进行SOINN数据压缩,将造成压缩后的数据量少于预期的数据量,无法达到预定的数据压缩效果。
为此,本文提出一种分块采样的思想,首先计算采样率,然后根据采样率确定分块规模并进行数据压缩,最后将压缩后的数据块进行合并。采用分块采样的方式可使数据达到大致平衡。具体过程为:
Step1:确定参数,为采样率,"为采样后的数据集,为原始数据集,为数据块个数,为每个数据块的大小。
Step2:计算采样率= ||" ||,||和||"分别代表采样前和采样后的数据规模,通过输入数据规模与采样率的关系图(见图2),确定对应的数据规模。

图2 数据规模与采样率的关系图
Step3:计算数据块个数=||,对每个数据块进行数据压缩,构成每一块数据的压缩数据",=0,1,2,…,。

实验主要验证经SOINN欠采样后构成的训练集对模型检测效果的影响。
3.1 实验环境与数据集
在WIN10操作系统平台上利用Python 3.7.0开展实验,编程工具是PyCharm,处理器为IntelCorei5-10210U,内存16 GB。实验数据为10% KDD Cup 99,尽管该数据集有一些不足,但它仍然是应用于入侵检测系统的性能测试的经典数据集,表1为该数据集的分布情况。
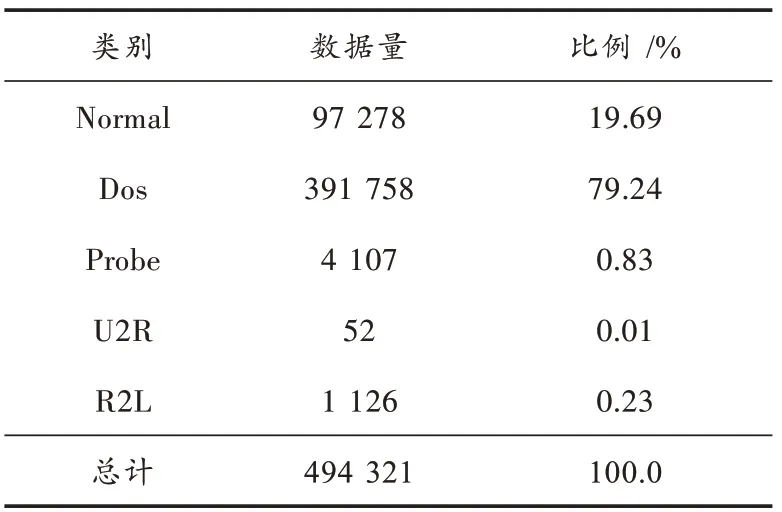
表1 10% KDD Cup 99训练数据样本分布情况
为满足本实验二分类任务需求,实验数据集取Probe、U2R、R2L和0.88%的Dos组成数据规模为8 752的异常训练集,使得正常样本数量远大于异常样本数量,这样的数据集划分更加符合真实的网络环境。
3.2 通过降维加速网络数据训练
实践表明,未经降维的数量集直接输入神经网络,训练时间很长,系统计算资源被严重占用,因此在进行数据预处理的时候,要进行降维。非负矩阵分解(Nonnegative Matrix Factorization,NMF)采用矩阵分解的方式进行降维,而且降维后的低维矩阵为非负矩阵,该方法能够很好地保持原矩阵的物理含义,实现起来比较简单而且便于理解。实验中将分解后的矩阵维度参数设置为15。
3.3 分块采样
实验选取的正常样本数量为97 278,为确保数据平衡,期望压缩后的数据量为8 752,采样率约为9.0%。由图2所知,9.0%的采样率对应的数据规模约为5 100,可将正常样本划分为19个规模为5 119的数据块,然后分别压缩后再进行拼接,形成欠采样后的正常样本。
3.4 评价指标
本实验采用5折交叉验证,将平均准确率(Accuracy)、平均召回率(Recall)和假阳性率(FPR)作为评价指标。
在一次数据检测中,会产生4类检测结果,分别为:TP(True Positive)、FP(False Positive)、TN(True Negative)和FN(False Negative)。
Accuracy:准确率是指正确分类的样本数占样本总数的比例,准确率越高分类器性能越好。

Recall:召回率是指预测正确的正例数量占全部正例样本数量的比例,召回率越高分类器性能越好。

FPR(False Positive Rate):假阳性率是指预测错误的正例数占全部正例数的比例,可以代表算法的误检率,假阳性率越低,分类器的性能越好。

3.5 实验结果对比
将基于SOINN的欠采样方法与不进行欠采样、RSS和K-means进行对比,采用的有监督分类器分别为决策树、KNN和SVM,实验采取5折交叉验证的方式。其中基于滑动窗口K-means聚类的欠采样方法,设置窗口大小为20 000,每次滑动长度为2 000,聚类中心数量为200,将每一次形成的聚类中心组合形成正常样本数据集。tree的 最 大 深 度max_depth=None,KNN的 近 邻 数n_neighbors=5,SVM的核函数为径向基内核。表2为实验结果的对比情况。
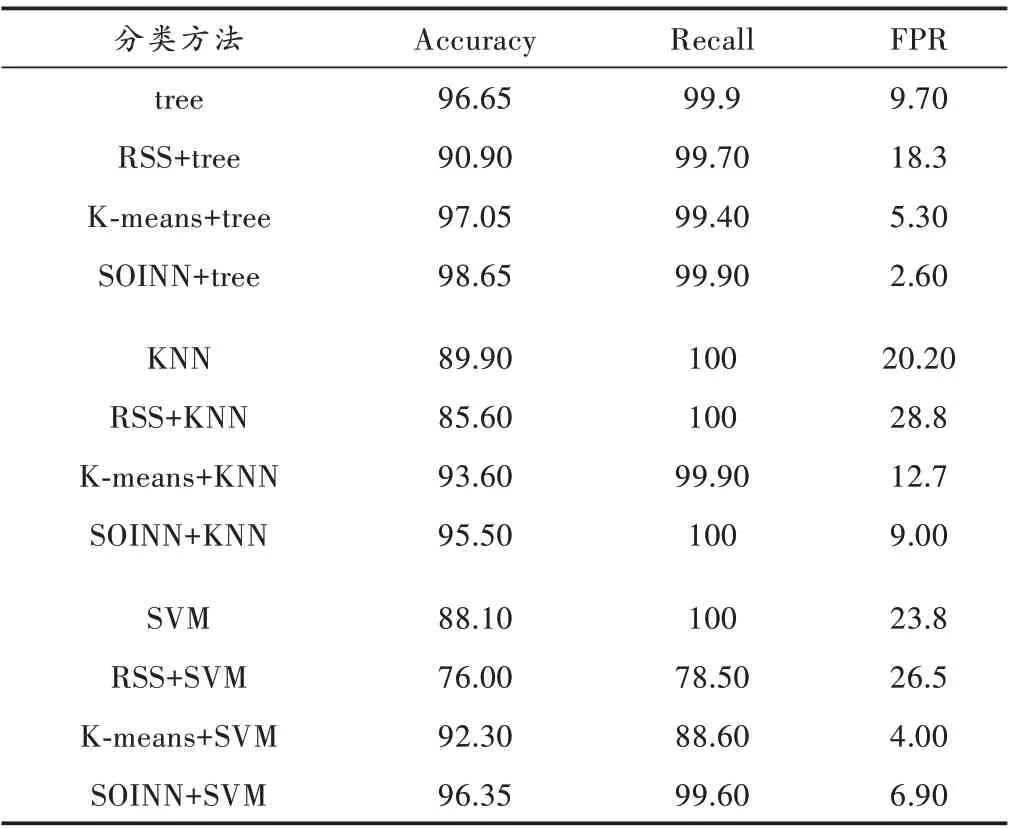
表2 5折交叉验证的不同算法分类准确率和召回率结果%
分析表2的实验结果,可以得出以下结论:
1)在样本数据不平衡的情况下,分类器对少量样本的刻画能力不足,使得最终学习的分类边界更倾向于多数类,相比于采用K-means和SOINN的欠采样方法,三个评价指标都比较差,分类器的性能普遍不佳。
2)采用随机采样的方法(RSS)会造成样本特征的大量丢失,所选择的少量样本不具有代表性,在此基础上训练的分类器模型准确率和召回率比不进行欠采样时还要低,而假阳性率比不进行欠采样时要高,分类器的总体性能最差。
3)基于SOINN和基于滑动窗口K-means的欠采样方法,相比于不进行欠采样,准确率和召回率都得到了提升,假阳性率都比较低,两种欠采样方式都比较有效。
4)SOINN在学习时可以保留原始样本的特征,在此基础上训练出的模型,准确率和召回率均高于基于Kmeans的方法,除SVM外,模型的假阳性率低于基于Kmeans的方法。
实验证明了基于SOINN的欠采样方法相比于其他方法的综合性能优势。
本文将SOINN用于网络入侵检测数据欠采样,将平衡后的数据应用于分类器训练,解决了现实网络环境中正常流量与异常流量严重不平衡的问题。实验中,将准确率、召回率和假阳性率作为评价标准,选择决策树、支持向量机和K近邻作为分类器,证明了所提方法的有效性。后续将继续研究基于SOINN的欠采样方法与过采样方法相结合后的混合采样方法的应用效果,进一步提升分类器性能。
猜你喜欢 分类器聚类神经元 分类器集成综述计算机时代(2022年9期)2022-11-03少样本条件下基于K-最近邻及多分类器协同的样本扩增分类现代电子技术(2022年15期)2022-07-28学贯中西(6):阐述ML分类器的工作流程电子产品世界(2022年4期)2022-04-21基于数据降维与聚类的车联网数据分析应用汽车实用技术(2022年4期)2022-03-07AI讲座:神经网络的空间对应电子产品世界(2021年8期)2021-01-16基于模糊聚类和支持向量回归的成绩预测华东师范大学学报(自然科学版)(2019年5期)2019-11-11仿生芯片可再现生物神经元行为中国计算机报(2019年49期)2019-02-07这个神经元负责改变我们的习惯中国新闻周刊(2017年36期)2017-10-21基于AdaBoost算法的在线连续极限学习机集成算法软件导刊(2017年4期)2017-06-20基于密度的自适应搜索增量聚类法电子技术与软件工程(2016年23期)2017-03-06推荐访问:采样 入侵 检测