Multi-AUV,Inspection,for,Process,Monitoring,of,Underwater,Oil,Transportation
来源:优秀文章 发布时间:2023-04-28 点击:
Jingyi He, Jiabao Wen, Shuai Xiao, and Jiachen Yang,
Dear Editor,
This letter presents an inspection method for process monitoring of underwater oil transportation via multiple autonomous underwater vehicles (AUV).To improve the adaptability of our method in practice, we introduce the dynamic complex ocean current data to the previously mentioned case by using regional ocean modeling system(ROMS) for the first time, and elaborately design AUV’s local information, as well as the deep reinforcement learning (DRL) tuple (St,At,Rt,St+1).Specifically, according to the local information of each AUV, including captured pipeline image, ocean current velocity,position coordinates and pose angles, an agent can be well trained to control the AUV for underwater oil pipeline tracking through visionhydrology-motion-based soft actor critic (VHM-SAC) mechanism.Experimental results show that the proposed method can provide stable oil pipeline tracking performance in dynamic complex underwater environment.
Underwater oil transportation is an important part of offshore oilfield systems, which can continuously transport large amounts of oil in a fast, efficient and economical way [1].However, the lifespan of oil pipelines is limited.With the increase of service time, the aging and corrosion of the pipelines occur from time to time.The resulting oil leakage will not only bring serious economic losses, but also cause long-term pollution to the environment.In this case, it is of great significance to be able to give an alarm in a timely manner through process monitoring [2] and take remedial measures when the pipeline leaks.
The main purpose of underwater oil pipeline inspection is to find out whether there is a leakage point on the pipeline, which can usually be divided into internal inspection methods and external inspection methods.The former mainly uses ultrasonic, magnetic flux, eddy current and other technical means to complete, the results are accurate but only suitable for large-diameter pipes.The latter mainly focuses on parameters such as flow difference, pressure difference,negative pressure wave, etc., the cost is lower than the internal inspection methods and there is no possibility of pipeline blockage due to detection equipment [3]−[5].Thus, the external inspection methods are more common in the field of underwater oil pipeline inspection.
AUV is a typical representative of underwater unmanned system.With its small, flexible and low-energy-consumption features, it can play an important role in the external inspection of underwater oil pipelines [6] and [7].However, the underwater environment is dynamic and complex, a single AUV may not be able to meet the needs of refined tasks.Faced with this situation, AUV cluster can realize multi-directional inspection of underwater oil pipelines through mutual cooperation [8]−[10].
With the outstanding performance of AlphaGo and other highly intelligent products, DRL method has led the development of various decision-making methods, such as traffic control, man-machine game, video coding, search referral, text processing etc.It can extract the important features form various observation states through deep neural networks, and hereafter realize the trial-and-error learning for agent through the reward-driven interaction between environment and agent.The combination of the features-extracting ability and the decision-making ability [11], making DRL method as if it is tailored for AUV underwater pipeline inspection.
Related work: With the development of underwater equipment technology, many researchers have carried out studies on underwater pipeline inspection and tracking by using underwater robots.Most of those studies are based on remotely operated vehicle (ROV).Matsumotoet al.[12] used Deep Ocean Phantom S2 ROV to design a Hough transform-based submarine cable detection system, which realized the tracking of 25 mm cables.Oceaneering company designed Magna ROV that can use electromagnetic ultrasonic technology to detect pipelines exposed on the seabed in the depth of 3 000 meters [13].However, due to the influence of the umbilical cable, ROV must be supported by the mother ship and cannot carry out large-scale and long-distance missions.What is worse, ROV requires operators to keep their eyes on the screen for remote control.Then, researchers begin to turn their attention to applying AUV.Huanget al.[14] proposed an AUV-based underwater pipeline detection method by fusing multi-source information collected by AUV.Liet al.[15] proposed an adaptive control law for AUV pipeline tracking, which includes the estimation of uncertain parameters related to the hydrodynamic damping coefficients.
Like the methods mentioned above, most of the existing methods need to establish an accurate kinematic model for AUV, which is usually difficult when not having enough prior information.DRL method can provide control strategy without knowing the kinematic model, by interacting between agent and environment.Yuet al.[16]proposed an underwater motion control system based on DRL method to solve the problem of underwater robot trajectory tracking,getting more accurate results than traditional proportion-integrationdifferentiation (PID) control systems when the trajectory is a complex curve.Wuet al.[17] proposed a discrete-time model-free reinforcement learning framework to solve three depth control problems for AUV, namely constant depth control, curved depth tracking, and seafloor tracking.Unfortunately, there is few works to consider the impact of the real underwater environment when training the agent.


Fig.1.The dynamic process of DRL-based AUV underwater oil pipeline inspection.
Combining the advantages of policy-based DRL algorithm and value-based DRL algorithm, actor critic (AC) algorithm becomes popular in recent years.Based on the environmental information, the actor network is used to estimate the action through the policy gradient which can be expressed as

whereθis actor network’s parameter,Qπ(s,a)is the expected longterm discounted cumulative rewards for an agent applying the actionaat the states.The critic network is used to estimate the value on the basic of the policy by temporal difference (TD) error which can be expressed as
In order to improves the randomness of action selection, entropy regularization is introduced into soft actor critic (SAC) algorithm.The greater the entropy, the higher the randomness of action selection.Then, the goal of the algorithm should be
whereH(n(·|st)) is the policy entropy representing the entropy of the output action under the policyn(at|st), andαis the temperature parameter.
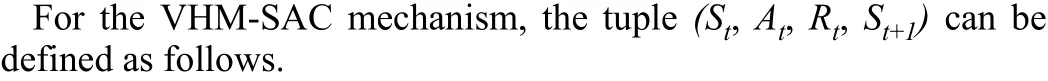
1) State spaceS: The goal of the agent is to control AUV cluster to move from starting point to end point along the underwater oil pipeline without collision in dynamic complex underwater environment.Therefore, the state space mainly includes captured pipeline image, ocean current velocity, position coordinates and pose angles,where the raw captured pipeline image is two dimensional and the rest raw data is one dimensional.As shown in Fig.2, all state data is flattened and then concatenated to form a one-dimensional vector through deep neural networks, where (x,y,z) denotes the position coordinates in the earth frame, (φ,θ,ψ) denotes the pose angles in the body frame, (u,v,w) denotes the ocean current velocities in the directions of the three coordinate axes.The captured image is decomposed into three matrices according to the red-green-blue (RGB)components.
2) Action spaceA: The discrete action space is composed of the movements in six directions: up, down, left, right, front and back.Each movement represents a fixed timestep in the corresponding direction, and only one action will be chosen at a certain time.
3) Reward functionR: The design of the reward function is of great significance to the convergence of the DRL method [19].Since both the state space and the action space are large and complex, traditional sparse reward function cannot be expected to work.Therefore,a composite reward function is designed
i) The vertical distance between the AUV and the oil pipeline,rd=−0.1|d1−dTH|, whered1is the vertical distance between the AUV and the oil pipeline,dTH(set to 2 m) is the threshold of the vertical distance between the AUV and the oil pipeline.
ii) The distance to the target,rt= −0.01d2, whered2is the distance to the target.
iii) The collision,rc= 0 (if no collision) or −1 (if collision).
Thus, the total reward for each step isr=rd+rt+rc, which is clipped in [0,1].
The pseudo code of the SAC algorithm used is as follows:

Algorithm 1 VHM-SAC Input: The captured image of the oil pipeline Iop, The position coordinates of the AUV PA, The pose angles of the AUV AA, The velocity of the ocean current Vcπ∗Output: Optimal action decision policy Initialize parameters: Target point Pt, Number of steps N, Number of episodes M, Batch size K, Temperature parameter α, Learning rate λ, Policy parameters θp, Q-function parameters θ1, θ2, target parameters θ1’← θ1, θ2’←θ2, Replay memory D, Vertical distance threshold dTH, Discounting factor γrepeat if it is the beginning of the episode then Initialize the position of the AUV PAend if Observe the state sand select an action a~ πθp(a|s)Execute the action a, get the reward r, the next state s’, and the done signal dto indicate whether s’is the terminal Store the transition (s, a, r, s’) in DSample random minibatch Kof transitions (s, a, r, s’) from DCompute targets for the Q functions Update Q-functions by one step of gradient descent Update policy by one step of gradient ascent Update the temperature parameter Update target networks until convergence
Experiments: Our simulation and the experiments are carried out on Ubuntu 20.04 system, using an Intel Core i7-12700K CPU @ 3.60 GHz, two NVIDIA GeForce RTX 3080 GPU.The necessary software includes Gazebo 11.4, ROS Noetic Ninjemys, Python 3.8,Pytorch 1.10, NetCDF 4.1, Hdf5 1.8, MATLAB 2016b and other commonly used dependencies for data processing [20].
To evaluate the performance of the proposed method, we laid the pipeline model inocean_wave.worldof Gazebo simulation software,and imported a dynamic complex ocean environment generated by ROMS to simulate the actual underwater oil pipeline inspection.The reason for using ROMS generated data is that the generated data can be more uniform and spatiotemporally denser through data processing when compared with the measured data, providing more reliable data support.The environment is a subarea of the South China Sea,covering the spatial extent of 20.75°N−22.25°N, 118.5°E−120.0°E.The average water depth is 2495.88 meters and the maximum water depth is 3650.54 meters.Linear interpolation was adopted to fill the data into continuous.
Three homogeneous AUVs with same attributes were used to form a cluster for multi-angle coordinated inspections of underwater oil pipelines.Each AUV has its corresponding agent to control itself.In our training progress, learning rate is 0.0005, batch size is 256, target entropy is −6, and temperature parameter is 1.Fig.3 shows the result of an oil pipeline inspection via multi-AUV.It can be seen that all three AUVs can keep a certain distance and move along the oil pipeline stably.Table 1 shows the success rate of the AUV cluster to complete underwater oil pipeline inspection under the influence of different ocean current intensity.Even in the case of ocean current velocity of 1 m/s, our method can still maintain good control effect with an average success rate 86.67%.

Fig.2.The illustration of VHM-SAC mechanism.

Fig.3.The result of an oil pipeline inspection via multi-AUV.

Table 1.Comparison of Different Ocean Current Intensity
Conclusions: This letter presents a VHM-SAC mechanism for process monitoring of underwater oil transportation by multi-AUV in dynamic complex underwater environment.Three agents are trained to control their corresponding AUV based on the local information,and perform well even with severe ocean current, providing some meaningful references for the application of AUV clusters and deep reinforcement learning in the field of process monitoring.
Acknowledgments:This work was supported by the National Natural Science Foundation of China (61871283).
推荐访问:Inspection process Multi