基于HRNet,的轻量化人体姿态估计网络
来源:优秀文章 发布时间:2023-04-27 点击:
梁桥康 ,吴樾
(1.湖南大学 电气与信息工程学院,湖南 长沙 410082;
2.航天江南集团有限公司,贵州 贵阳 550009)
人体姿态估计是计算机视觉中最基本和最具有挑战性的任务之一,旨在从图像或者视频序列中检测并识别人体关键点的位置和类型.其在行为识别[1]、自动驾驶和行人检测[2]等后续任务中具有广泛的应用.
近年来,随着深度神经网络(Deep Neural Net⁃works,DNN)的不断发展,DNN 在计算机视觉领域得到了广泛的应用并取得了巨大的成功,人体姿态估计取得了显著的进展.
早期的基于卷积神经网络的(Convolutional Neu⁃ral Networks,CNN)方法直接从图像中预测关节点的位置,DeepPose[3]利用深度神经网络直接从图像中回归关键点坐标,这种方法很难获得精确的坐标,而且网络的收敛速度非常缓慢.Tompson 等人[4]使用马尔可夫随机场为每个关节点创建一个与其他关节点相关的图模型(Graphical Model)结构,并利用热力图表示关节点信息,热力图数值的大小表示该位置是关节点的概率大小,热力图中最大值的坐标即为关节点的坐标.由于热力图可以通过卷积操作直接得到,因此,使用热力图表示关节点位置这一方法很大程度上促进了基于CNN 的人体姿态估计方法的发展.现有的大多数人体姿态估计方法都是基于热力图预测.Huang 等人[5]提出了一种由无偏坐标系统变换和无偏关键点格式变换组成的无偏数据处理(Unbi⁃ased Data Processing,UDP)系统,该系统可以很容易地与任何人体姿态估计网络相结合,进一步提高预测精度.DARK(Distribution-Aware Coordinate Repre⁃sentation of Keypoints)[6]提出了一种基于泰勒展开的坐标解码和无偏亚像素中心坐标编码方法.
目前,多人姿态估计主要有两种主流策略,即自上而下和自下而上两种方法.自上而下的方法需要先检测出人体边界框,然后对识别到的人体进行单人姿态估计.自下而上的方法不进行人体框的检测,而是直接检测出所有的关键点,然后将它们进行分组.自上而下的方法精度更高但是会牺牲速度,而且受人体框检测精度的影响.自下而上方法速度更快但是精度相对不高,现有的自下而上方法主要集中在如何将检测到的属于同一个人的关节点关联在一起.
OpenPose[7]提出部分亲和力场(Part Affinity Fields,PAFs)的概念,PAFs 存储了肢体的位置和方向信息,结合预测的热力图快速地将各关节点分组到每个人.Kreiss 等人[8]提出用部分强度场(Part In⁃tensity Field,PIF)来表示关节点的位置和用部分关联场(Part Association Field,PAF)来表示关节点之间的关联,利用部分关联场特征将属于同一个人体的关节点关联起来.DEKR(Disentangled Keypoint Re⁃gression)[9]提出了一种多分支结构的解耦关键点回归方法,每个分支分别对特定关键点进行独立的特征提取和回归,实现了关键点之间的解耦,解耦后的特征能够独立地表示特定关键点区域.Pishchulin 等人[10]提出把所有的关节点作为节点形成一个图结构,然后利用预测的人体框信息,将属于同一个人的关节点归入同一个类别.AE(Associative Embedding)[11]提出了一个端到端的单阶段网络,同时为每个关节点生成热力图和分类标签,标签值接近的关节点属于同一个人.
CPM(Convolutional Pose Machines)[12]通过序列化的多阶段网络逐步细化关键点预测,利用中间监督信息可以有效地解决梯度消失的问题.Chen 等人[13]提出了一个两阶段的级联金字塔网络,前一阶段用于预测一个粗略的姿态,后一阶段在前一阶段的基础上改进预测结果.模拟人类认知的过程,即先注意能够直接看到的关节点,然后利用已知的关节点信息推测出看不见的部分,RSN(Residual Steps Network)[14]提出了姿态调整机,能够进一步细化初始姿态,提高姿态估计的精度.HRNet(High Resolu⁃tion Net)[15]以一个高分辨率的子网络作为第一阶段,之后的每个阶段比前一阶段多一个并行的低分辨率子网络,在同一阶段内,不同分辨率子网络的信息被反复融合,这种保持高分辨率特征的策略能够显著提高人体姿态估计的精度.
由于算力和内存限制,移动设备和嵌入式平台不适合部署大型网络[16],因此,目前的人体姿态估计网络难以得到广泛应用.Osokin 等人[17]利用减少细化阶段层数减少网络参数量和使用空洞卷积提升感受野的大小等方法提出了一个轻量化的Openpose网络,在CPU 上实现了实时的人体姿态估计.Lite-HRNet[18]提出条件通道加权,从所有通道中学习权重,实现跨通道和分辨率交换信息,与其他轻量化网络相比,取得了更好的精度.Zhang 等人[19]构建了一个轻量化的沙漏网络,利用快速姿态蒸馏模型学习策略,能够更有效地训练轻量化人体姿态估计网络.
与以往的轻量化人体姿态估计方法不同,本文提出了一种兼顾精度和轻量化人体姿态估计网络,在保持精度的前提下有效地减少了网络的计算量和参数量,为移动设备、嵌入式平台等运算能力、内存大小有限的设备提出了一种有效的轻量化人体姿态估计网络.
增加网络的容量(更深或更宽)能够促使网络提取到更加复杂、高级的特征信息,可以相对容易地提高网络的精度.然而,网络的性能并不会随着网络深度或宽度的递增线性地增长,可能会出现性能饱和甚至下降,网络的参数量和内存消耗量也会越来越高,其对硬件计算能力和内存的要求也增大.动态卷积[20]根据注意力程度动态地聚合多个卷积核,能够在不增加网络深度和宽度的条件下增加模型的复杂度.Inception[21]提出的在同一模块中使用不同尺寸的卷积核,使得网络能够自主地提取不同尺寸目标的特征.Szegedy 等人[22]提出使用两个一维卷积核替代一个二维卷积核,以此来减小网络的参数量.ResNet(Residual Net)[23]提出残差学习来解决网络退化的问题,其提出了两种不同的残差块,Basic 块和Bottle⁃neck块,如图1所示.

图1 残差块Fig.1 ResNet blocks
ResNet模块可表示为:
式中,x为输入特征,y是输出特征,F(⋅)是ResNet 学习到的映射变换,残差连接的主要优点是特性再利用,可以减少特性冗余.
当输入特征大小为Hin×Win×Din,输出特征大小为Hout×Wout×Dout,卷积核大小为S×S时,标准卷积可学习的参数量为:
Basic 块由两个3 × 3 卷积组成,当保持特征输入输出通道数D不变时,其可学习的参数量为:
Bottleneck 块由两个1 × 1 卷积和一个3 × 3 卷积组成,其可学习的参数量为:
由计算可知Bottleneck 模块的参数量下降为Ba⁃sic模块的.
分组卷积(Grouped Convolution,GC)是指在通道方向上对输入特征进行分组,每组特征被相应分组的卷积核单独卷积,之后通过拼接组合产生输出特征.分组卷积最早由AlexNet[24]提出,由于当时硬件的运算能力和内存资源有限,在网络训练时,一个GPU 无法处理所有的卷积操作,所以作者将模型部署在两个GPU 上,最后将两个GPU 的结果融合在一起.
在分组卷积中,输入特征和卷积核都会被分成g组,每组特征的大小为,每组卷积核的数量为,每个卷积核大小为,每组卷积核只对相应分组的特征进行卷积操作,则分组卷积可学习的参数量为:
深度可分离卷积(Depthwise Separable Convolu⁃tion,DSC)[26-27]是将标准卷积分解成两部分,即深度卷积和1 × 1 卷积,每个深度卷积核只对输入特征的一个通道进行卷积操作,卷积核的数量与特征的通道数相同,因此,深度卷积不改变特征的通道数量.1×1 卷积用于实现特征的升维或降维.与常规的卷积操作相比,深度可分离卷积的参数量和运算成本相对更低.
如图2 所示,ResNeXt[28]提出了深度和宽度之外的下一个维度,即基数(Cardinality),增加基数可以在保持模型复杂度的情况下提高模型的性能.ResNeXt 在图像分类方面的巨大成功促使我们将其引入人体姿态估计领域,并用其改进当前的人体姿态估计方法.

图2 两种ResNeXt模块Fig.2 ResNeXt blocks
ResNeXt模块可表示为:
式中,x为输入特征,y是输出特征,Ti是ResNeXt 第i个分支学习到的映射变换,g是基数,即分组数.
ResNeXt 模块由两个1×1 卷积和一个3×3 分组卷积组成,其可学习的参数量为:
由式(3)、式(7)可得:
在神经网络中,不同像素大小的特征分别蕴含着不同层次的信息.
检测任务的目标是准确地检测目标在图像中的空间位置.一般来说,高像素特征蕴含丰富的空间位置信息,其位置敏感性更强,有利于检测任务.
分类任务的目标是对图片中的目标进行分类.实验表明,随着卷积神经网络层数的不断增加,输出特征具有的语义信息逐渐增强,其位置不变性更强,有助于分类任务[29].人体姿态估计既包含定位关节点位置的检测任务,又包含分类不同关节点的分类任务,因此,人体姿态估计任务的性质决定了网络既要具有分类任务的位置不变性,又要具有检测任务的位置敏感性.
HRNet 采用多分支结构,在网络中高像素特征分支与低像素特征分支并行排列,不同分辨率特征的相互融合提高了神经网络的位置敏感性和位置不变性.一方面这使得其在目标检测、语义分割和人体姿态估计等方面展示出了卓越的能力.另一方面也产生了参数量巨大、难以训练和内存消耗大等问题.
本文聚焦于在HRNet的基础上设计一个轻量化的人体姿态估计网络.首先利用Bottleneck 模块替换掉HRNet 中大量使用的Basic 模块,然后利用ResNeXt 替换Bottleneck 模块进一步减少网络的参数.为了向HRNet 和ResNeXt 致敬,将本章提出的方法命名为X-HRNet.
X-HRNet 网络结构如图3 所示,X-HRNet 与HRNet 具有相同的网络构架,总共有四个阶段,每个阶段分别有1、2、3、4 个不同分辨率的分支.预处理阶段使用两个步长为2 的3×3 卷积将输入图片的分辨率降低为1/4,通道数由3增加为64.第一阶段利用4 个Bottleneck 模块进行特征提取.从第二阶段开始使用ResNeXt 模块替换原始HRNet 网络中大量使用的Basic 模块进行特征提取,各分支的分辨率分别为1/4、1/8、1/16、1/32,通道数分别为48、96、192、384.为了避免分辨率下降造成特征图信息丢失,每个新增的低分辨率分支通道数增加一倍.第四阶段的末尾,将四个分支的特征上采样到相同的分辨率,然后使用元素加得到最终的输出,最终的输出为17 个关节点的热力图.网络的具体结构如表1 所示.其中,(3 ×3,s=2) × 2 表示两个步长为2 的3 × 3 卷积,(3 ×3,GC)表示3×3分组卷积.

表1 X-HRNet的结构Tab.1 Architecture of X-HRNet

图3 X-HRNet模型的结构Fig.3 The structure of X-HRNet
3.1 实验方法
网络的训练使用了NVIDIA RTX 2080Ti GPU,操作系统为Ubuntu 18.04 LTS,使用的深度学习框架为Pytorch,代码框架基于MMpose[30].训练过程中使用了随机缩放、水平翻转、随机剪裁等常用数据增强方法.使用DARK[6]作为坐标编解码方法.输入图片固定为384 × 288,使用Adam 作为网络优化器,总训练轮数为210轮,初始学习率为5e-4,在第170轮时,学习率下降为5e-5,在第200 轮时,学习率下降为1e-5.最小批次大小为14.数据集为COCO[31],COCO数据集是目前最主流的二维人体姿态估计数据集之一,它包含20万张以上的图像和25万个带有关键点注释的人体实例.
3.2 损失函数
高斯热力图已被广泛应用于关键点坐标的编码和解码.关节点P={p1,p2,...,pk:pi=(ai,bi)},其高斯热力图可表示为:
式中,Gi为第i个关节点的热力图,ai、bi分别是关节点pi的横坐标和纵坐标,λ是控制高斯热力图大小的常数.
在网络训练期间使用的损失函数为:
在网络预测过程中,利用公式(11)将高斯热力图解码为关节点的坐标.
3.3 评价指标
1)基于对象关节点相似度(Object Keypoint Similarity,OKS)的平均精度(Average Precision,AP)
本文使用COCO 数据集人体姿态估计任务标准的评价指标,即基于OKS 的AP,评估了不同阈值和不同对象大小下的平均精度:AP、AP50、AP75、APM、APL和平均召回率AR.
式中,di是预测关键点位置与真实值之间的欧式距离,s是目标尺度因子,ki是与关节点相关的衰减常数,vi是关键点是否可见的标识符,当关节点标注时,δ=1,当关节点未标注时,δ=0.
2)浮点运算次数(Floating-point of Operations,FLOPs)
浮点运算次数主要用来衡量算法复杂度.卷积操作的计算量为:
式中,Din是输入特征的通道数,S为卷积核的大小,Hout、Wout、Dout分别为输出特征的高、宽和通道数.
3.4 结果分析
表2 展示了本文所提出的方法与其他方法在COCO 验证集上的表现.结果显示,X-HRNet-W48-G12(表示ResNeXt 模块的基数为12)达到了77.8%的精度,显著优于其他轻量化网络.与FastNet-W48相比,获得了3.3%的精度增长,参数量下降了4.4M,计算量减少了7.4GFLOPs(Giga Floating-point of Op⁃erations).与Lite-HRNet-30 和Lite-HRNet-18 相比,精度分别增长了7.4%和10.2%.相比MobileNet V2和ShufflfleNet V2,精度分别增加了10.5%和14.2%.
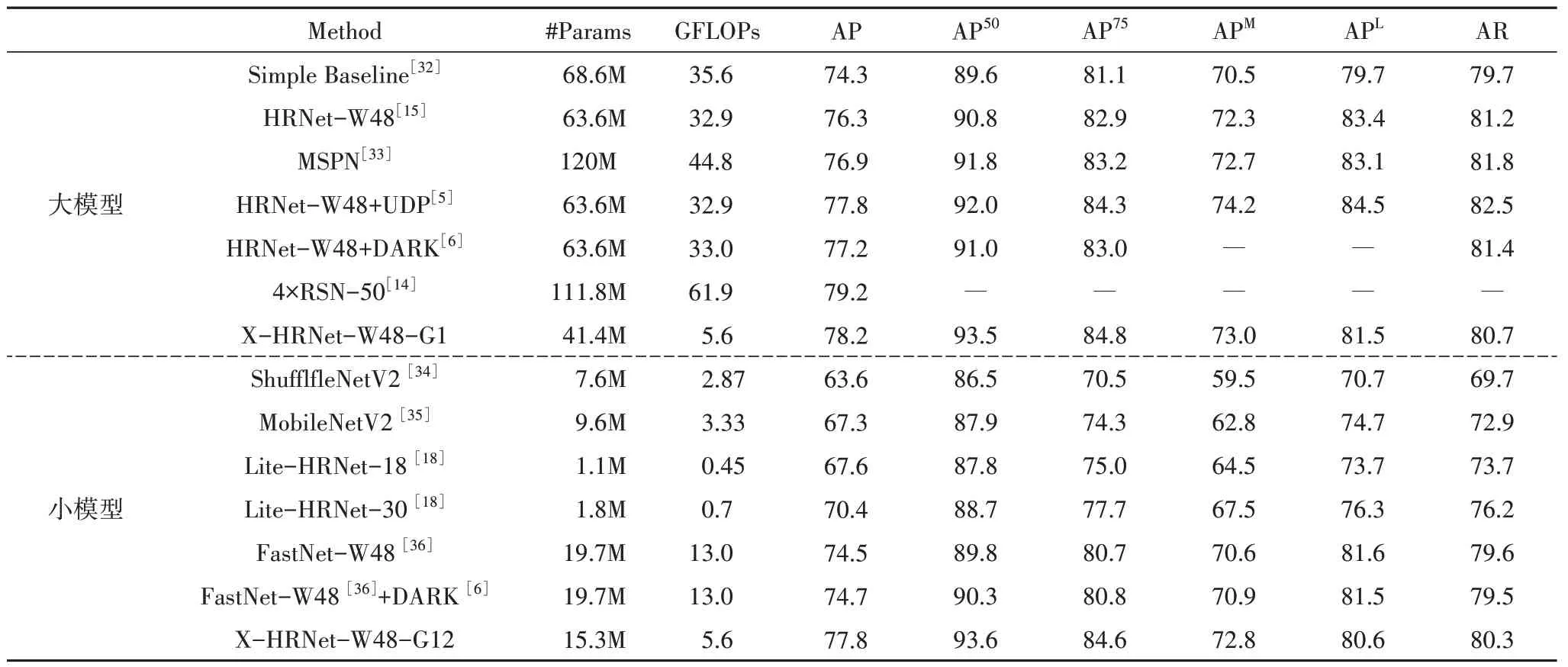
表2 与现有算法在COCO验证集上的性能比较Tab.2 Performance comparison with the existing algorithms on the COCO validation set
X-HRNet-W48-G1 的精度为78.2%,参数量为41.4M,计算量为5.6GFLOPs.相比HRNet,精度上升了1.9%,参数量下降了22.2M,计算量下降了27.3GFLOPs.相比HRNet-W48+DARK,精度上升了1.0%,参数量下降了22.2M,计算量下降了27.4GFLOPs.与MSPN 相比,X-HRNet-W48-G1 的精度取得了1.3%增长,参数量下降了78.6M,计算量下降39.23GFLOPs.与4×RSN-50 相比,虽然精度由79.2%下降到了78.2%,但是参数量下降了70.4M,计算量下降了27.43GFLOPs.
与大模型相比,X-HRNet 以更低的参数量和计算量取得了可以媲美的精度.
表3 展示了X-HRNet 和其他方法在COCO testdev 测试集上的表现.X-HRNet-W48-G12 取得了74.7%的精度,相比FastNet-W48 精度增加了0.9%.相比Lite-HRNet-30 精度值提高了5.0%.与Mo⁃bileNet V2 相比,精度值增加了7.9%,和ShuffleNet-V2 相比,精度值提高了11.8%.X-HRNet 在COCO test-dev 测试集上取得了比其他轻量化网络更高的精度值.

表3 与现有算法在COCO test-dev上的性能比较Tab.3 Performance comparison with the existing algorithms on the COCO test-dev set
X-HRNet-W48-G1 取得了75.0%的精度,相比Simple Baseline、CPN 和CFN,精度值分别提高了1.3%、2.9%、2.4%.虽然X-HRNet 在精度上与其他大模型相比存在差距,但是X-HRNet 的优点是参数量和计算量很低.
由实验结果可知,X-HRNet在保持精度的同时,有效地降低了网络的参数量和计算量,更好地实现了精度和网络计算量之间的平衡.
3.5 消融实验
3.5.1 基数的消融实验
为了研究不同基数对人体姿态估计精度的影响,本节在COCO 数据集上进行消融实验.所有网络都从随机初始化状态开始训练,输入图片固定为384 × 288.
消融实验的结果如表4 和图4 所示,X-HRNet-W48-G12与X-HRNet-W48-G1相比,精度只下降了0.4%,参数量下降了26.1 M.当基数继续增加到24和48 时,关节点定位精度分别比X-HRNet-W48-G1 下降了0.9% 和2.0%,参数量分别下降了27.3M 和27.9M.

图4 消融实验结果Fig.4 Results of ablation experiments
值得注意的是,精度最低的网络X-HRNet-W48-G48 取得了76.2%的精度,仅比HRNet-W48 低0.1%,参数量减少了50.1 M.
消融实验1 的结果表明,增加基数可以有效地降低网络的参数量,但是精度也会降低.对于基数的选择,需要结合实际情况合理平衡精度和参数量的关系.
3.5.2 解耦关节点特征表示
基于热力图的姿态估计方法通常会为每个关节点预测一个热力图,热力图上最大值处即为对应关节点的坐标.理想情况下,不同的热力图只会关注于特定的区域.在自下而上的方法中,为了让每个通道更加专注于一个关节点而不受其他关节点的干扰,Geng 等人[9]提出解耦各关节点之间的特征表示,利用多分支结构回归关节点坐标.该方法可以表示为:
式中,是第i个关节点的预测热力图.Bi为分支i的输入特征,Ui(⋅)为第i个分支学习到的映射.
在COCO 数据中,共标注了17个关节点,由于通道数必须能整除基数,为了保持相近的参数量,本节的消融实验将最高分辨率分支的通道数设为51,基数设为17,得到X-HRNet-W51-G17.
由表4 和图4 可知,与X-HRNet-W48-G12 相比,X-HRNet-W51-G17 的精度下降了0.5%,参数量上升了1.2M.与X-HRNet-W48-G24 相比,精度下降了0.1%,参数量增加了1.4M.

表4 消融实验结果Tab.4 Results of ablation experiments
消融实验2 的结果表明,虽然多分支结构可以使每个分支专注于一个关节点,但是,人体姿态是一个整体的结构,不同关节点之间存在着相互依赖的关系,为了能够利用不同关节点之间相互依赖的信息,保持多个分支之间的信息融合更加有利于提高自上而下人体姿态估计方法的精度.X-HRNet 在COCO 验证集上取得了较好的效果,部分结果如图5所示.

图5 在COCO验证集上的部分结果Fig.5 Some results on the COCO validation set
由于嵌入式平台计算能力和内存限制,常用的基于神经网络的人体姿态估计算法难以部署在嵌入式平台上.为了满足实际应用中对神经网络轻量化的要求,本文在HRNet 的基础上,利用ResNeXt 替换原模型中的Basic 模块,利用深度可分离卷积对网络进行改进,在保证精度的前提下,达到减少网络的参数量和计算量的目的,提出了一种改进的轻量化人体姿态估计算法.实验表明,相比其他轻量化人体姿态估计网络,本文提出的方法在COCO 数据集上取得了更高的精度,是一种有效平衡了精度和网络复杂度的方法.
猜你喜欢关节点力图轻量化汽车轻量化集成制造专题主编精密成形工程(2022年2期)2022-02-22乔·拜登力图在外交政策讲话中向世界表明美国回来了英语文摘(2021年4期)2021-07-22基于深度学习和视觉检测的地铁违规行为预警系统研究与应用科学技术创新(2021年19期)2021-07-16关节点连接历史图与卷积神经网络结合的双人交互动作识别沈阳航空航天大学学报(2020年6期)2021-01-27血栓弹力图在恶性肿瘤相关静脉血栓栓塞症中的应用进展现代临床医学(2019年4期)2019-09-10一种轻量化自卸半挂车结构设计智富时代(2019年2期)2019-04-18一种轻量化自卸半挂车结构设计智富时代(2019年2期)2019-04-18时空观指导下的模块整合教学——以《20世纪四五十年代力图称霸的美国》为例中学历史教学(2017年12期)2018-01-19搞好新形势下军营美术活动需把握的关节点军营文化天地(2017年6期)2017-06-28RGBD人体行为识别中的自适应特征选择方法智能系统学报(2017年1期)2017-06-01推荐访问:姿态 估计 人体