面向入侵检测的Taylor神经网络构建与分析
来源:优秀文章 发布时间:2023-04-25 点击:
王振东,张林,杨书新,王俊岭,李大海
江西理工大学 信息工程学院,江西 赣州341000
互联网和计算机系统已经成为现代社会生活中的重要组成部分,随之带来的安全问题[1]成为影响社会稳定的关键因素。入侵检测技术作为一种能够检测和抵御恶意软件侵害的新型安全机制,逐渐发展成为保护网络安全的关键技术。
国内外相关研究者对入侵检测技术进行了深入研究,主流方法包括基于机器学习、数据挖掘和深度学习[2-4]等多种入侵检测算法。文献[5]提出一种加权朴素贝叶斯入侵检测模型,结合粗糙集理论和改进粒子群算法来提升检测能力,但机器学习算法模型训练时间过长,计算成本偏高。文献[6]采用了基于支持向量机的数据挖掘方法,使用粗糙集理论进行特征选择,减少了手动分析任务的需要,但数据挖掘算法对大数据中的噪声较为敏感,易出现过拟合现象。文献[7]提出了一种结合信息增益和主成分分析的混合降维技术,并基于支持向量机、实例的学习算法和多层感知机的集成分类器来构建无监督学习的入侵检测模型,但无监督学习方法对于噪声和异常值敏感。文献[8]使用强化学习方法将入侵检测问题转换为预测马尔可夫奖励过程的价值函数,使用线性基函数的时间差异算法来进行值预测,但是强化学习技术难以检测较新和较复杂的分布式攻击行为,导致模型检测性能不佳。文献[9]提出了一种基于四角星的可视化特征生成方法,用于评估五分类问题中样本之间的距离,但入侵检测可视化系统通常是在有限的区域内进行图像展示,其扩展性差。而神经网络通过模拟生物大脑的思维方式处理信息,具有自组织、自学习和自适应的特点,可以在保证性能的同时,控制算法中的参数量,降低计算成本[10]。
目前,研究者使用神经网络如BP(back propagation)[11]、循环神经网络(recurrent neural network,RNN)[12]、卷积神经网络(convolutional neural networks,CNN)[13]、深度置信网络(deep belief networks,DBN)[14]等设计了一系列入侵检测算法。BP 神经网络具有强大的自学习能力、泛化能力和非线性映射能力,文献[11]将BP 神经网络应用于入侵检测,得到了较高的检测率和较低的误报率,但BP 算法权值阈值初始化随机性较大,易陷入局部极值,导致训练时间过长。RNN 神经网络能够挖掘出数据中的时序信息和语义信息,被广泛用于序列相关的入侵检测。文献[12]结合RNN 和区域自适应合成过采样算法来提升低频攻击的检测率,得到了较优结果,但大多数攻击数据不存在明显的序列相关性,难以适用于入侵检测系统。CNN 是一个典型的基于最小化预处理数据要求而产生的区分性深度结构,通常处理高度非线性抽象分类问题,文献[13]将其与权值下降相结合应用于入侵检测,保留数据间长期依赖关系,丢弃重复特征,有效避免了过拟合现象,然而CNN 计算过程复杂,导致运算时间及成本偏高;
DBN 神经网络可以有效解决高维数据的检测问题。文献[14]提出一种改进遗传算法与DBN 的入侵检测技术,通过遗传算法自适应地生成最优隐藏层数和神经元数,以适应不同攻击类型,然而攻击数据通常是一维,将其用于入侵检测存在明显缺陷,并且DBN 的学习过程较慢,参数的选择不当会导致结果陷入局部最优。
鉴于神经网络具有较优自学习和自适应能力,本文提出一种基于Taylor 神经网络的入侵检测算法。Taylor 公式在逼近多项式函数值等方面具有显著优势,本文将网络入侵数据样本的特征值视为Taylor 公式的输入,利用Taylor 公式挖掘出特征值间所隐藏的函数映射关系。为了使Taylor 公式能够有效运行,本文利用神经网络逼近Taylor 公式的各个展开项系数,有效提高神经网络的入侵检测性能。同时,为了有效选择Taylor 公式的展开项数目,设计了基于高斯过程的人工蜂群算法。实验结果表明,基于一元Taylor神经网络的入侵检测算法(Simple_TNN)与基于多元Taylor 神经网络的入侵检测算法(Multi_TNN)均具有较优性能。
传统神经网络通过为不同特征数据分配不同权值,达到区分样本的目的,而忽略了样本特征数据与最终标签的函数映射关系。为提升神经网络算法对数据的区分和鉴别能力,在神经网络运行过程中引入函数映射关系。具体操作如下:利用Taylor 公式作为映射关系的载体,使用神经网络逼近Taylor 公式的展开项系数,从而挖掘出样本特征数据与样本标签间的函数关系。
Taylor 公式分为带佩亚诺型余项的泰勒公式以及带拉格朗日余项的泰勒公式。前者对函数f(x)的展开要求较低,只需在点x0处n阶可导即可,而不需要连续可导,更无须在x0的邻域内存在n+1 阶可导,因此本文采用带佩亚诺型余项泰勒公式。其构建的一元及多元Taylor 神经网络(Taylor neural network,TNN)结构如图1、图2 所示。

图1 一元Taylor神经网络的基本结构Fig.1 Basic structure of univariate Taylor neural network

图2 多元Taylor神经网络基本结构Fig.2 Basic structure of multivariate Taylor neural network
其中,x为一条样本的特征数据;
N是Taylor 函数的展开项数目;
fN+1(x)是对输入数据x作变换,以适应一元Taylor公式的输入;
微分分量D为Taylor 公式展开项的系数;
R为麦克劳林分量;
F(x)为一元Taylor展开式。微分分量D和麦克劳林分量R通过神经网络(全连接神经网络,其结构见实验部分)优化所得。
同样,x为输入的特征数据,fi(x)是对输入数据x作变换,使输入的特征数据能够更方便完成多元Taylor 展开式的运算,详见式(9);
微分分量D为Taylor 公式展开项的系数;
R为麦克劳林分量;
式(8)中的F(x1,x2,…,xn) 为多元函数在xk处的泰勒展开式;
F(x)为Taylor展开式的矩阵形式。其中D、H(xk)与R都由神经网络(全连接神经网络,其结构见实验部分)优化得到,基于工程简单且易于实现,取xk为一条零向量,得到式(10)。
入侵检测数据特征间函数映射关系不明显,因此引入TNN 挖掘出其中隐藏的特征映射关系。TNN以一条数据样本的某个特征值作为Taylor 公式的展开点,但一条网络入侵数据样本中可能存在多个特征值。为适应网络入侵数据样本,本文设计了Taylor神经网络层(Taylor neural layer),使其能够对一条数据中的各个特征值同时处理。在TNL 中,将网络入侵数据的各个特征值作为各Taylor 公式的展开点,并利用神经网络逼近微分分量和麦克劳林分量,从而计算各Taylor 公式的函数值,此时函数值是考虑了样本特征值函数关系后的更深层次的样本特征。最后,将函数值输入到深度神经网络(deep neural network,DNN,其结构见实验部分)中实现分类,Taylor 神经网络模型结构如图3 所示。

图3 Taylor神经网络模型Fig.3 Taylor neural network model
为了获取微分矩阵D和麦克劳林矩阵R,本文利用两个DNN对f(0)、f′(0)、f″(0)…f(n)(0)和R0,R1,…,Rn进行逼近,上述两个DNN 的输入均为网络入侵检测数据样本x。最终获得D与R的矩阵形式,详见式(12)和式(13),其中n为数据的维数,N为Taylor公式展开的项数,为f(x)在第N次求导后x=0时的函数值。
为满足Taylor 神经元的输入条件,将入侵检测数据样本x做如下变换得到X(n×N)。
将变换后的X与矩阵D的转置进行点乘:
以上为一元Taylor 神经网络层运算过程,输出数据是n×1 维数据。多元Taylor 神经网络层与一元Taylor 神经网络层相同,使用神经网络计算出D、H(xk)和麦克劳林分量R,再代入输入数据X即可。
再考虑Taylor 网络层至第一层DNN 中信息的运算:
其中,Y是Taylor 网络层的输出;
X1为第一层DNN的输出;
W1为第一层DNN 的权重;
B1为第一层DNN 的偏置;
σ1为第一层DNN 的激活函数。
DNN 中运算过程为:
式中,Xl-1为第l-1 层DNN 的输出,同时也是第l层DNN 的输入;
Xl为第l层DNN 的输出;
Wl为第l层DNN 的权重;
Bl为第l层DNN 的偏置;
σl为第l层DNN 的激活函数。
通过上述分析可知,在DNN 前加一个Taylor 网络层可以有效挖掘入侵数据特征值中所隐藏的函数关系,利用这种关系能够有效地提升算法的检测精度。然而,Taylor 展开式持续展开至N项并不现实,不仅会占据大量内存空间且得不到较好结果。因此,本文提出一种基于高斯过程的人工蜂群算法,对展开项数N进行优化。
人工蜂群算法(artificial bee colony,ABC)[15]由Karaboga 于2005 年提出,该算法用蜜源所在位置表示问题的解,用蜜源产出的花粉数量表示解的适应度值。根据分工的不同,算法将蜜蜂划分为引领蜂、跟随蜂以及侦察蜂三种。其中,引领蜂发现食物源并以一定的概率将其分享给跟随蜂;
跟随蜂根据引领蜂分享的概率选择蜜源;
侦察蜂在蜂巢附近寻找新的蜜源。算法迭代运行,对蜂群和蜜源位置初始化后,对三种蜂的位置迭代更新以寻找问题的最优解。人工蜂群算法鲁棒性强,通用性好,但是局部开采能力较差,易陷入“早熟”,因此本文设计了基于高斯过程的人工蜂群算法对Taylor 公式的展开项数进行优化。
3.1 高斯过程
高斯过程(Gaussian processes,GP)[16]是一种常见的非参数模型,其本质是通过一个映射将自变量从低维空间映射到高维空间(类似于支持向量机中的核函数将低维线性不可分映射为高维线性可分)。高斯过程是多元高斯概率分布的一种泛化形式,通过先验知识确定参数的后验分布,从而确定一组任意且有限的输入数据和目标输出之间的函数关系。如同高斯分布一样,可以用均值和方差来刻画,如下:
其中,m(x)为均值函数,通常取m(x)=E[f(x)];
k(x,x′)为核函数,通常取k(x,x′)=E[(f(x)-m(x))(f(x′)-m(x′))]。为方便计算,取m(x)=0,0 均值高斯过程直接由其核函数决定。
给定输入数据X=x1,x2,…,xn。目标输出通常包含高斯噪声,且与真实值之间相差ξ,即:
其中,K为协方差矩阵。此时,n个训练样本的目标输出Y和测试数据的预测值f*构成了联合高斯先验分布:
其中,K*=[k(x*,x1)k(x*,x2)…]k(x*,xn),K**=k(x*,x*),x*为预测输入。取f*的边缘分布,并根据联合高斯分布的边缘分布性质可得到如下预测分布:
其中,f*若为标量,那么
f*若为向量,那么
3.2 基于高斯过程的人工蜂群算法
由于人工蜂群普遍存在收敛速度慢,局部开采能力差,易陷入“早熟”等缺点,引入高斯过程对其进行优化,过程如下:
初始化蜜源阶段:
其中,i=1,2,…,m,m为蜜源个数;
j=1,2,…,n,n为问题的维数;
η是一个介于(0,1)之间的随机数;
uj和lj分别是xij的最大和最小边界值。
引领蜂位置更新阶段:
其中,j是介于[1,m]之间的随机整数,i,k∈{1,2,…,m},且k≠i;
xkj为随机选取的蜜源;
将ςij改为服从高斯分布的随机数,相对于均匀分布的随机数,可以提供相对集中的搜索区域,从而加快收敛速度,扩大搜索范围,增加种群多样性。
跟随蜂阶段:
其中,pm为跟随蜂通过轮盘赌机制选择某个蜜源而更新位置的概率,如果该值大于随机产生的一个数,那么跟随蜂就依附到此蜜源。
侦察蜂阶段:当引领蜂和跟随蜂搜索完整个空间时,一个蜜源的适应度函数值在给定的有限次数内没有提高,则将该蜜源丢弃,该蜜源相对应的引领蜂从而变成侦察蜂,并使用公式搜索新的可能解。
适应度函数:将神经网络的损失值作为算法的优化目标。
3.3 基于高斯过程的人工蜂群算法步骤
基于高斯过程的人工蜂群算法(artificial bee colony algorithm based on Gaussian process,GABC)步骤如下:
步骤1初始化种群数、最大迭代次数以及搜索空间,并利用式(27)更新种群位置。
步骤2利用式(33)计算并评估每个初始解的适应度函数值,根据适应度函数值确定极值以及最好最差的位置。
步骤3利用式(33)进行贪婪选择,如果vi的适应度优于xi,则用vi代替xi,将vi作为当前最好的解,否则保留xi不变。
步骤4设置循环条件开始循环。
步骤5利用高斯过程更新引领蜂位置,详见式(28)~(31)。
步骤6利用式(32)更新跟随蜂位置。
步骤7若一个食物源经过数次迭代后仍未被更新,那么就将其放弃,则此引领蜂转成一个侦察蜂,由式(27)产生一个新的食物源。
步骤8记录目前为止的最优解。
步骤9判断是否满足循环终止条件,若满足,循环结束,输出最优解,否则返回步骤4 继续搜索。
众所周知,泰勒公式逼近某一函数数据的精度,很大程度上取决于泰勒公式展开项的多少。一般而言,展开项越多,泰勒公式逼近函数数据的精度越高。但实际上,利用数据集中的样本训练神经网络去拟合泰勒公式中展开项的系数,数据集中总会存在一些噪声信息。此时,如果盲目地增加泰勒公式展开项的数目,追求泰勒公式逼近数据的精度,极有可能造成过拟合现象;
而泰勒公式展开项数目不足也将导致欠拟合现象。手动合理地选择泰勒公式展开项的数目需要大量的经验支撑,为了避免手动选择展开项数的局限性,有效提高入侵检测模型的性能,采用人工蜂群算法对泰勒公式展开项数目进行寻优,但传统人工蜂群算法存在的局部开采能力较差,易陷入“早熟”等问题,因此引入基于高斯过程的人工蜂群算法,有效避免了传统人工蜂群中存在的问题,其模型描述如下:
使用基于高斯过程的人工蜂群算法优化TNN 的基本思路是,首先求出适应度函数最好的一组蜂群位置,迭代结束后,将该位置作为TNN 的最优展开项数建立入侵检测模型,模型训练过程及结构如图4所示。

图4 基于GABC 的TNN 入侵检测算法框架Fig.4 TNN intrusion detection algorithm framework based on GABC
步骤1初始化人工蜂群算法的种群数目、蜜源位置、最大迭代次数和搜索空间。
步骤2对原始数据x进行预处理:
(1)将数据集中的离散特征转换为数值型特征;
(2)将数值型特征进行归一化处理,使其都是分布在[0,1]之间的实数。
步骤3将归一化后的数据特征进行变换,使其满足Taylor神经网络层的输入条件。
步骤4将变换后的数据划分为训练集x_train、测试集x_test。
步骤5将训练数据x_train 输入至TNN 中,并对其进行训练。
步骤6计算并返回训练数据的损失值,并将其作为GABC 的优化目标,更新相关参数。
步骤7反复执行步骤5 至步骤6,直至触发GABC 的迭代终止条件,获得TNN 的最优展开项数。
步骤8传递参数至TNN 并对其进行训练,训练完成后在测试集上进行测试。
为验证Simple_TNN 和Multi_TNN 入侵检测算法的性能,采用NSL-KDD[17]和UNSW-NB15[18]数据集对其进行验证,其中NSL-KDD 包含41 个特征属性和1 个类别标签,如表1 所示。较NSL-KDD 而言,UNSW-NB15 数据分布更平衡,不包含冗余数据;
NSL-KDD 将攻击类型分为Dos、Probe、R2L、U2R 共4大类攻击。UNSW-NB15包含49 个特征属性,更能真实地反映现代网络数据;
UNSW-NB15 将攻击分为Fuzzers、Analysis、Backdoors、DoS、Exploits、Generic、Reconnaissance、Shellcode、Worms 共9 大类攻击。本文所使用的数据分布如表1 所示。

表1 数据分布Table 1 Data distribution
5.1 性能指标
两种数据集无论是正常行为和攻击行为之间,或是各类攻击行为之间都存在数据不平衡等问题,因此除准确率外,还需要引入精确率、召回率和F1 值对算法进行评价,参数定义如表2 所示。

表2 参数定义Table 2 Parameter definition
准确率(Accuracy),预测对的样本数占样本总数的比例,其数学表达式如下:
精确率(Precision),预测为正的样本中有多少是真正的正样本,其数学表达式如下:
召回率(Recall),样本中的正例有多少被预测正确,其数学表达式如下:
F1-score 是基于召回率和精确率计算的,其数学表达式如下:
5.2 与经典机器学习算法的比较
本文所使用的Taylor 神经网络模型结构如表3所示。其中DNN1 用来优化麦克劳林分量R,DNN2用来优化微分分量D,DNN3 用来对TNL 的输出进行更深层次的分析处理并完成分类,参数设置如表3所示。

表3 Taylor神经网络模型结构Table 3 Taylor neural network model structure
5.2.1 二分类实验结果
二分类实验结果如表4 所示,将其与经典的机器学习算法和神经网络进行对比。显然,在几种算法中,不论是NSL-KDD 数据集还是UNSW-NB15 数据集,所提出的Simple_TNN 和Multi_TNN 效果总是最优的,分别是97.6%、99.6%和96.8%、97.3%。在NSLKDD 数据集上,SVM 的Accuracy 为53.4%,Recall和F1-score 仅仅只有0.1%,说明SVM 在此数据集上完全失效;
相较于机器学习算法,神经网络算法在此数据集上表现更好,CNN的Precision甚至达到了98.8%,仅仅与Simple_TNN 差了0.1 个百分点;
而Simple_TNN 的Recall却比CNN低了4.3个百分点,说明Simple_TNN 在分类正样本时的性能较CNN 差,总是将一部分正样本错误地预测为负样本;
Multi_TNN的四种性能指标分别达到了99.6%、99.7%、99.4%和99.5%,是几种算法中性能最佳的。在UNSW-NB15数据集上,CART 的Precision 最差,仅仅只有70.4%,但Recall 却是最高,达到了99.8%,说明CART 在分类正样本时,性能较优;
相较于神经网络算法,机器学习算法反而在此数据集上表现更好,KNN 是几种经典算法中性能最优的,但是较Simple_TNN 和Multi_TNN 的Precision 而言,还是低了3.2 个百分点和2.0个百分点;
再观察Simple_TNN 和Multi_TNN 可看出,虽然Multi_TNN 的Accuracy 比Simple_TNN 高了0.5 个百分点,但是Precision 却低了1.2 个百分点,说明Multi_TNN 将部分负样本预测为了正样本,这样会给网络安全带来更大的威胁。ROC 曲线图反映真正率和假正率之间的关系,曲线将整个区域划分成两部分,曲线下部分的面积被称为AUC,用来表示预测准确性。从图5 可以看出,在各算法中,无论是正常数据还是攻击数据,所提Simple_TNN 和Multi_TNN 算法的AUC 均较优,充分说明引入Taylor 的必要性。

图5 二分类ROC 曲线Fig.5 Two-classification ROC curve

表4 二分类实验结果Table 4 Two-classification experiment results
5.2.2 多分类实验结果
多分类实验结果如表5 所示,将其与经典的机器学习算法和神经网络进行对比,可看出不论是NSLKDD 数据集还是UNSW-NB15 数据集,Multi_TNN性能总是最佳的。在NSL-KDD 数据集上,与机器学习算法相比,神经网络算法较优;
SVM 如二分类一样,效果极差,Accuracy 只有53.5%,Precision 也只有37.6%,相当于把大部分正样本预测为负样本,大部分负样本预测为正样本;
其他几种经典算法几乎都达到了80%以上,性能较优;
然而Simple_TNN 算法性能下降,Accuracy 低于CNN 算法3.9 个百分点,说明Simple Taylor 在处理NSL-KDD 数据时,不如CNN效果好;
但是Multi_TNN 却比CNN 的Precision 高2.7个百分点,说明Multi Taylor 在该数据集上更具有优势。在UMSW-NB15 数据集上,较机器学习而言,神经网络算法的多分类性能明显下降;
SVM 在几种算法中位居首位,Accuracy 达到了80.5%,仅仅比最好的Multi_TNN 差了3.8 个百分点;
SVM 与其他几种机器学习算法的Precision 相差不大,但是Recall 却高约5 个百分点,说明SVM 在预测正样本时比其他几种经典算法更具有优势;
CNN 却是性能最差的,Precision 只有53%,相当于接近一半的负样本预测为正样本,这将给网络安全带来更严重的危害;
其他几种经典算法几乎都达到了70%以上,相对较优,但与Multi_TNN 还是差了10 个百分点左右。微平均ROC和宏平均ROC 曲线图直观地反映算法在大量数据和少量数据中的检测性能,如图6 所示,不论是NSLKDD 数据集,还是UNSW-NB15 数据集,也无论是大量数据还是少量数据,所提出的Simple_TNN 和Multi_TNN 的AUC 总是最优的。

表5 多分类实验结果Table 5 Multi-classification experiment results

图6 多分类微平均和宏平均ROC 曲线Fig.6 Multi-class micro-average and macro-average ROC curves
5.3 时间性能分析
由上节分析可知,Simple_TNN 与Multi_TNN 算法均具有良好的检测性能。为检验其运行速度,继续在UNSW-NB15 数据集上与各入侵检测算法进行对比,结果如表6 所示。可以看出,在相同迭代次数下(50 次),无论二分类还是多分类,Simple_TNN 与Multi_TNN 所用时间均非最少,主要是因为模型使用了3 个DNN(如表3 所示)输出所需的Taylor 系数。而本文采用了3 个DNN 串行的方式并使用梯度下降法分别训练DNN,导致Simple_TNN、Multi_TNN 消耗时间较长。对比算法中,决策树算法用时最短,是因为决策树算法通过计算信息熵来衡量各次划分样本的信息增益,再利用信息增益的最大化实现对决策树的训练,参数相对于其他算法较少,且信息熵、信息增益的计算量也较低,但决策树算法准确率却较低。RNN 响应时间虽较短,但准确率相比Simple_TNN、Multi_TNN 差距较大,是因为RNN 易出现梯度消失等问题。CNN 的时间性能与Multi_TNN 相差不大,但准确率远低于Multi_TNN。事实上,Simple_TNN 与Multi_TNN 作为一种新型神经网络架构,其结构还存在较大的优化空间。后续考虑设计Simple_TNN 与Multi_TNN 中DNN 的并行训练方法,并开发轻量级的Simple_TNN 与Multi_TNN 以进一步降低运行速度。
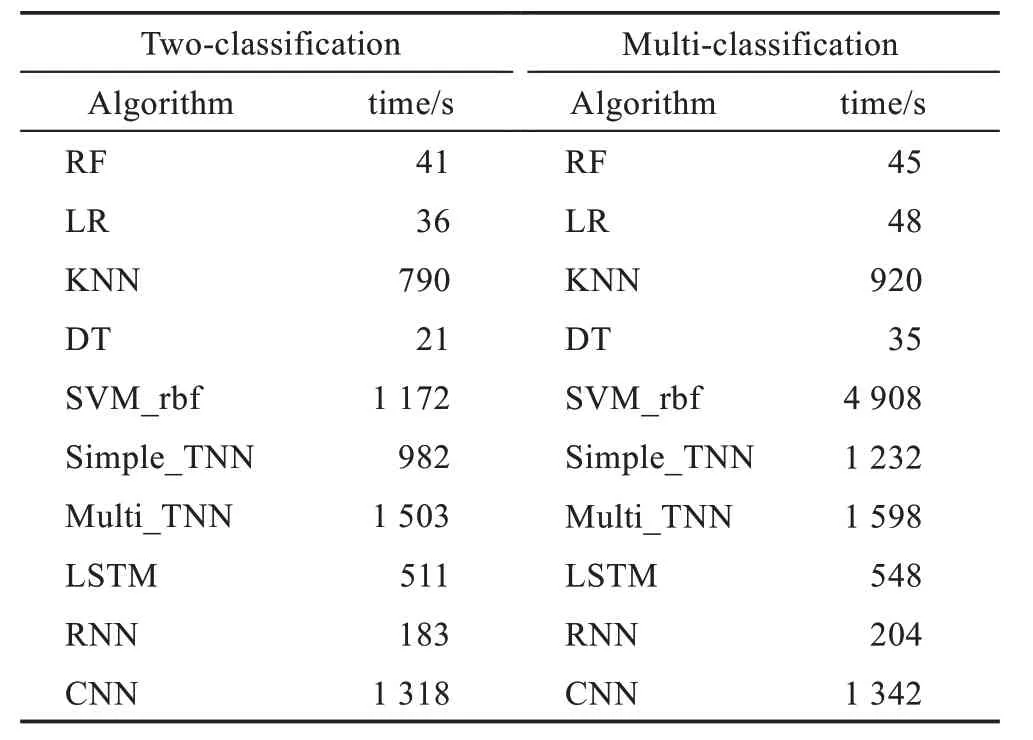
表6 时间性能Table 6 Time performance
5.4 与现阶段最新入侵检测算法的比较
Simple_TNN 和Multi_TNN 与现阶段最新的入侵检测算法进行实验对比,如图7 所示(由于每篇论文给出的性能指标都不相同,只对Accuracy 进行比较)。文献[19-22]对数据特征进行选择后再分类;
文献[23-24]基于规则检测;
文献[25-28]为多步骤分类;
文献[29-30]对现有入侵算法进行了改进;
文献[31-33]对神经网络结构优化后再分类。上述所得到实验结果较优,但并没有一种算法是针对攻击数据而专门提出的入侵检测算法。因此,本文提出基于Taylor 公式的神经网络,较其他算法而言性能总为最优,充分说明了Simple_TNN 和Multi_TNN 入侵检测算法的有效性。

图7 算法比较Fig.7 Comparison of algorithms
本文提出了一种基于Taylor 神经网络的入侵检测算法。利用Taylor 神经网络结构挖掘网络入侵检测数据特征背后所隐藏的函数映射关系,并利用这种映射关系对网络入侵行为进行有效的检测。为了将Taylor 神经网络应用到入侵检测领域,设计了Taylor 神经网络层(TNL),并针对Taylor 公式展开项难以通过经验确定的难题,设计了一种基于高斯过程优化的人工蜂群算法(GABC)。使用GABC 有效选择TNL 中Taylor 公式的展开项数目。实验结果表明,Taylor 神经网络模型在入侵检测领域具有良好的性能,后期将对Taylor 神经网络模型进行更深入的研究,实现其对于恶意代码、病毒等相关安全威胁的高效检测。
猜你喜欢高斯蜂群公式组合数与组合数公式新高考·高二数学(2022年3期)2022-04-29排列数与排列数公式新高考·高二数学(2022年3期)2022-04-29等差数列前2n-1及2n项和公式与应用中学生数理化(高中版.高二数学)(2020年11期)2020-12-14“蜂群”席卷天下小哥白尼(军事科学)(2020年4期)2020-07-25数学王子高斯小天使·二年级语数英综合(2019年4期)2019-10-06天才数学家——高斯小学生学习指导(低年级)(2019年6期)2019-07-22例说:二倍角公式的巧用中学生数理化·高一版(2018年6期)2018-07-09改进gbest引导的人工蜂群算法现代计算机(2016年17期)2016-02-28有限域上高斯正规基的一个注记四川师范大学学报(自然科学版)(2015年2期)2015-02-28蜂群夏季高产管理湖南农业(2015年5期)2015-02-26推荐访问:神经网络 入侵 构建推荐文章
- 初中英语教师的述职报告范文【三篇】|初中英语教师个人人述职报告范文
- 2018年国产电影 2018年西藏注册测绘师考试报名入口【7月13日开通】
- 2018年安徽亳州经济开发区选拔教师公告【292人】_2018亳州经济开发区教师招聘
- 简短狼性团队口号 电商团队狼性口号:企业和市场同步,管理与世界接轨。
- 【2018年云南高考艺术、体育类一本批次征集志愿计划】2018云南体育类招生表
- 【战友聚会活动主持词结束语】战友聚会主持词结束语
- 2018辽宁丹东振兴区教育系统公开招聘合同制教师公告【40人】_
- [2018年重庆高考招生录取二次志愿征集公告七]2018高考招生征集志愿
- 2018年驱动型作文范例 [2018财务应聘简历范例]
- 关于学习的名言警句:不知则问,不能则学:励志的名言警句