融合注意力机制和多尺度特征的图像语义分割
来源:优秀文章 发布时间:2023-04-09 点击:
姚庆安, 张 鑫, 刘力鸣, 冯云丛, 金镇君
(长春工业大学 计算机科学与工程学院, 长春 130012)
图像语义分割的目标是将场景图像分割为若干有意义的图像区域, 并对不同图像区域分配指定标签. 因此, 如何提高语义分割精度是图像语义分割的关键. 全卷积神经网络(fully convolutional networks for semantic segmentation, FCN)[1]由于其强大的特征学习及表达能力目前已成为图像语义分割问题的首选方法. 图像语义分割方法大部分基于FCN, 其中很多网络结构都有效提升了语义分割的性能, 但图像语义分割的发展仍存在如下问题:
1) 网络不断加深, 连续下采样导致像素值大幅度丢失, 严重削减了上下文语义信息, 并在上采样过程中难以恢复;
2) 图像多目标分割任务中感受野不同以及高、 低阶网络间的信息差异性, 导致图像有效信息严重丢失.
针对上述问题, 本文提出一种融合注意力机制和多尺度特征的图像语义分割方法, 以ResNet-101[2]为主干网络, 采用编码器-解码器结构提高精度. 该模型主要包括3个模块:
改进的带孔空间金字塔池化模块(reshape atrous spatial pyramid pooling, RASPP), 采用更密集的空洞率融合多尺度特征, 提取图像语境信息;
注意力细化模块(attention refinement model, ARM), 监督特征信息的学习, 增加上下文语义的关联性;
基于注意力的特征融合模块(attention-based feature fusion model, A-FFM), 采用通道监督有针对性地指导高、 低阶有用信息的融合, 提升网络泛化能力. 本文采用改进的带孔空间金字塔池化模块, 可捕获多尺度特征的语义信息, 提升多尺度目标下有意义特征信息的分割精度;
通过引入注意力机制模块, 用注意力细化融合模块, 监督上下文信息引导语义特征的学习, 并设计基于注意力的融合模块, 通过对重要通道的监督学习引导高、 低阶特征融合, 提高了模型的泛化能力;
实验过程中使用1×1卷积减少了参数计算量, 并在数据集Cityscapes上取得了72.62%的实验结果, 证实了模型的鲁棒性.
1.1 编码器-解码器结构
全卷积网络FCN[1]推动了语义分割研究的发展. 编码器-解码器结构也被整合完善用于计算机视觉领域, 如Ronneberger等[3]提出了U-Net, 通过跳跃连接将编码器-解码器中的特征图进行拼接, 有效融合了对应层级间的特征信息;
Badrinarayanan等[4]提出了SegNet, 在编码阶段保留最大池化值和最大索引, 在解码阶段利用最大索引位置信息上采样得到稠密特征图. 目前, 编码器-解码器作为一种通用的框架模型已广泛应用于各领域. 本文采用编码器-解码器结构实现网络设计.
1.2 注意力机制
受人类注意力机制的启发, 希望网络能自动学习到图片中需要关注的目标信息, 抑制其他无用信息. Hu等[5]提出了SENet, 采用通道注意力对各通道进行学习, 并将所学结果用于指导特征图, 进行调整;
Woo等[6]提出了CBAM, 通过构建空间、 通道两个注意力子模块, 综合信息获得更全面可靠的的注意力信息. 目前, 自然语言处理领域中的Transformer[7-9]在计算机视觉领域也得到广泛关注. 注意力机制在图像语义分割中应用广泛, 本文采用注意力机制模块监督上下文语义信息, 引导特征学习.
1.3 多尺度融合
特征融合可补充像素值的缺失, 常被用于图像语义分割中. Zhao等[10]提出了PSPNet, 通过级联不同步长的全局池化操作(即金字塔池化模块)融合多尺度特征, 实现了高质量的像素级场景解析;
Chen等[11-14]提出了通过DeepLab系列优化带孔金字塔池化(atrous spatial pyramid pooling, ASPP)模块用于融合尺度目标的处理, 有效改善了多尺度分割目标的任务;
Lin等[15]提出了表示图像特征的金字塔网络, 以融合上下文语义信息, 组合成新的特征, 解决了目标物体性能不佳的问题. 为提高多尺度物体分割的性能, 本文通过改进RASPP融合多尺度信息提取语义信息, 并设计A-FMM模块监督高、 低阶特征融合, 以提高模型的泛化能力.
2.1 网络体系结构
本文提出的模型旨在解决图像语义分割中多尺度类别下目标分割率低、 图像上下文特征信息关联性差的问题. 网络的整体结构如图1所示. 网络的主体为编码器-解码器结构, 以ResNet-101拓扑结构为基准. 编码阶段下采样到原图的1/16, 先将下采样结果输入到RASPP模块, 提高多尺度目标类别信息的利用率, 然后通过1×1卷积优化特征图信息. 解码阶段包含两部分:
1) 用ARM模块捕获解码器浅层网络的上下文信息;
2) 先将编码结果特征图上采样到同层特征图的大小, 再将同层特征图通过A-FFM进行特征融合, 削减高、 低阶特征语义间直接跨层融合导致信息丢失的问题. 最后输出得到分割结果图.
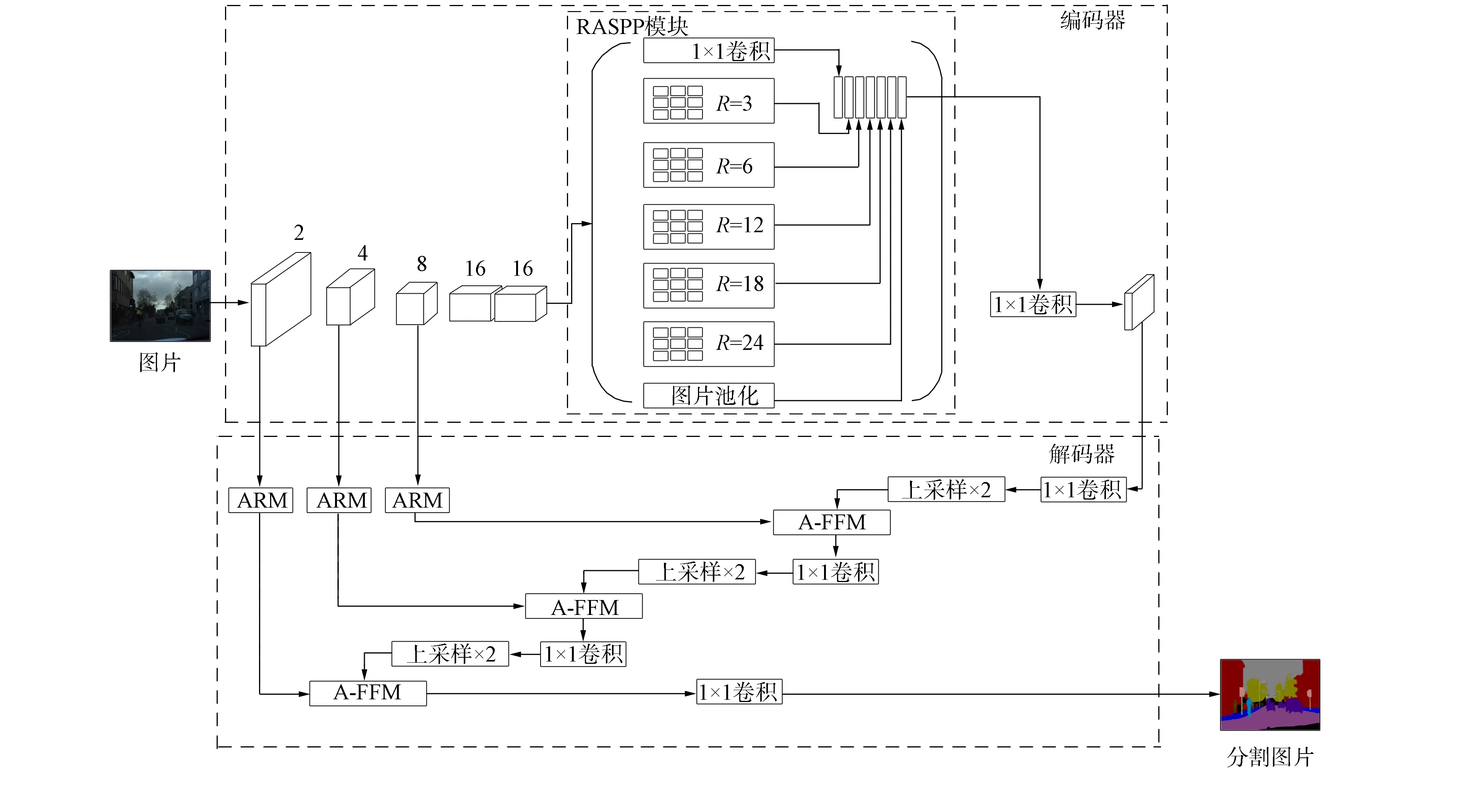
图1 网络整体架构
2.2 RASPP
RASPP模块在保留全局平均池化和1×1卷积不变的情况下, 可降低维度、 减少参数量, 并采用稠密空洞率实现多目标分割, 如图1中RASPP模块所示. 将RASPP模块的输入用


(1)
其中: 空洞卷积在不增加参数量的情况下增大了感受野, 在保证图像分辨率的同时可有效捕获更大范围的类别信息[16];
采用更稠密的空洞率可捕获更多多尺度目标物体的细节信息.
2.3 注意力模块
由于网络深度不同, 其特征图各通道承载的特征信息也不相同, 将网络深、 浅层特征图直接求和或拼接会导致大量特征信息的丢失, 影响分割精度.因为前者包含大量的抽象语义信息, 后者更多的是位置细节信息.因此, 本文提出添加ARM模块和A-FFM模块, 分别如图2和图3所示. 前者用于细化特征图的上下文关联信息, 后者根据各通道承载信息对预测目标贡献的大小, 有针对性的强化重要特征并进行突出学习, 以进一步提高模型的学习、 泛化能力.

图2 注意力细化模块

图3 注意力机制下的特征融合
ARM模块用公式可表示为

(2)
设编码器中浅层位置信息为Xi∈c×h×w(c表示通道数,h和w分别表示特征映射的高度和宽度), 将其输入到ARM模块中,Xi依次经过全局池化、 1×1卷积、 批标准化和Sigmoid激活函数, 得到输出结果再将与输入特征Xi相乘, 输出结果

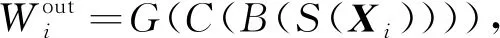
(3)
其中G表示全局池化,C表示1×1卷积,B表示批标准化(batch normal),S表示Sigmoid激活函数.
A-FFM模块用公式可表示为

(4)

(5)

(6)
其中R表示Relu激活函数.
3.1 实验设计
3.1.1 数据集
数据集Cityscapes[17]提供了50个不同城市街景记录的立体视频序列, 包含20 000张弱注释图片和5 000张高质量的弱注释图片. 图片像素为1 024×2 048, 涵盖各时间及天气变化情形下的街景, 共19个语义类别用于训练和评估.
数据集CamVid[18]由车载摄像头拍摄得到的5个视频序列组成, 提供了不同时段701张分辨率为960×720的图片和32个类别的像素级标签, 包括汽车、 行人、 道路等. 数据集中道路、 天空、 建筑物等尺度大, 汽车、 自行车、 行人等尺度小, 待分割物体丰富.
3.1.2 评价指标
采用平均交并比(mean pixel accuracy, MIoU)[19]作为语义分割质量的评价标准. MIoU是分割结果真值的交集与其并集的比值, 按类计算后取平均值, 用公式可表示为

(7)
其中pii表示正确分类的像素个数,pij表示本应属于第i类却被分为第j类的像素个数,n为类别数.
3.1.3 实验参数设置
实验基于Pytorch网络框架使用Python3.7编写实现. 计算机系统为CentOs7.9, 图形处理器为NVIDIA TITAN XP(4块), 加速库为Cuda10.2. 在数据集Cityscapes和CamVid上对模型进行微调, 以加快模型收敛速度, 同时采用随机梯度下降法对模型进行训练, 设基础学习率为1×10-4, 动量为0.9, 将输入图片进行裁剪.
3.2 实验结果与性能分析
3.2.1 模型性能对比
为衡量模型的有效性, 本文在Cityscapes验证集上进行实验, 并与DeepLab v3+,SegNet,FCN-8s模型进行对比. 实验结果列于表1. 由表1可见, 本文模型比其他模型的结果更优, 在相同主干网络下, 比DeepLab v3+的预测结果高1.14%, 比FCN-8s的预测结果高7.42%.

表1 在Cityscapes验证集上不同模型的性能实验结果
为更直观展示本文模型的优越性, 将DeepLab v3+和本文模型进行可视化展示, 结果如图4所示. 由图4中第一、 第二列的图片可见: DeepLab v3+模型处理近处目标分割边界粗糙, 对远处目标细节丢失严重, 而本文模型很好地弥补了上述不足, 准确地捕获了细节信息, 解决了分割模糊和漏分割问题;
对比图4中第三列可见, 本文模型能正确分割远处建筑物的细节信息;
对比图4中第四列可见, 本文模型成功避免了误分割和模糊分割的问题. 实验结果表明, 本文模型能更好地保留图像细节信息, 使预测结果更准确和全面. 用本文模型对测试集的分割结果进行可视化展示如图5所示.

图4 Cityscapes验证集上图片分割示例

图5 Cityscapes测试集上图片分割示例
3.2.2 消融实验
RASPP是在ASPP基础上使空洞率稠密化, 本文采用控制变量法进行实验, 实验结果列于表2, 测试集Cityscapes上ASPP模块性能对比如图6所示. 由表2可见, 通过将DeepLab v3+原有空洞率(1,6,12,18)稠密化为(1,3,6,9,12,24), 本文提出密集型感受野相对于DeepLab v3+原有的感受野提高了0.59%. 由图6可见, RASPP在兼顾多类别信息的同时有效捕获了多尺度细节信息, 也为后续高、 低阶特征图的融合提供了较高分辨率的语义特征图.

表2 ASPP模块改进前后性能对比
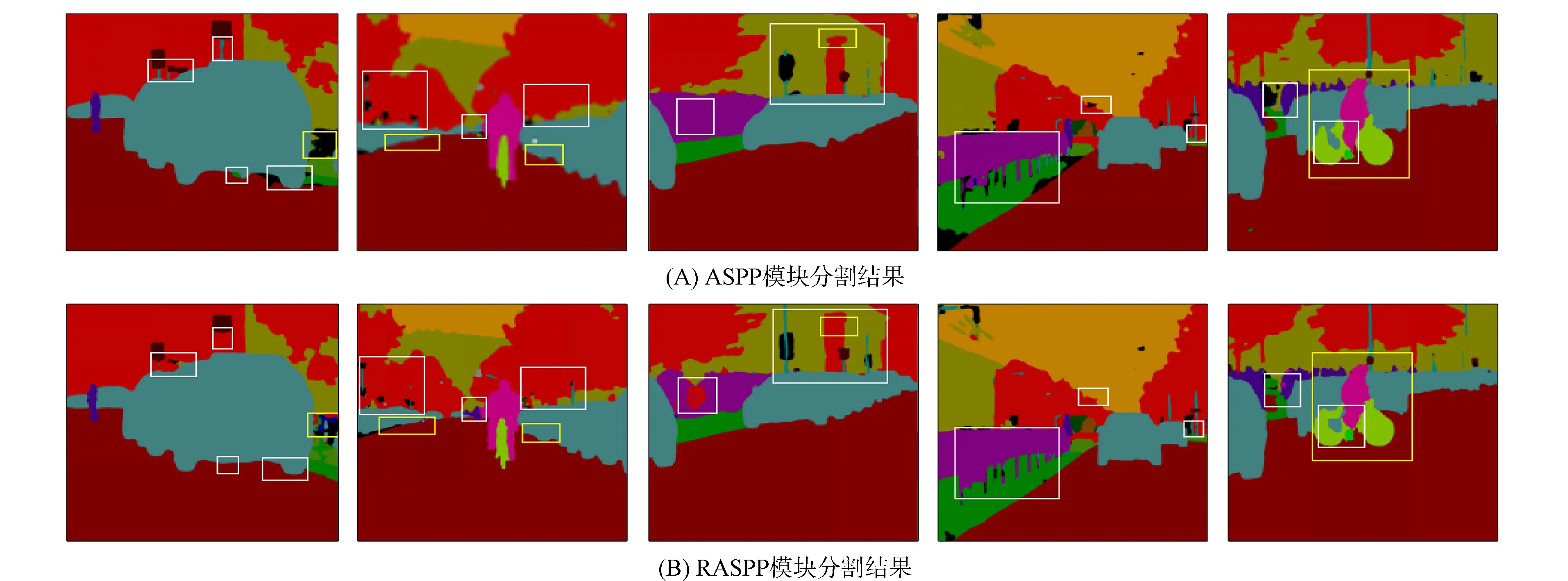
图6 Cityscapes测试集上ASPP模块性能对比
为验证本文提出的RASPP,ARM和A-FFM的有效性, 使用数据集Cityscapes进行逐层消融实验, 对比指标为MIoU, 消融实验结果列于表3, 消融过程中各模块可视化结果如图7所示.

表3 在数据集Cityscapes上不同改进方案的性能分析

图7 Cityscapes测试集上消融实验结果
由表3可见, RASPP模块将网络的MIoU从63.49%提升到69.25%, 有效提高了多目标物体的分割精度, 而注意力机制模块ARM和A-FFM的引入, 对不同层信息充分保留的同时极大削减了各特征层之间的语义差异, 最后达到MIoU为72.62%的结果输出, 体现了本文算法的优越性.
3.2.3 泛化实验
为进一步检验本文模型的泛化能力, 将RASPP,ARM和A-FFM模块分别添加到FCN和DeepLab v3+等模型中, 在数据集Cityscapes上可达到MIoU为65.71%和72.62%的精确度, 验证了本文模型有一定的可适性.
下面在小数据集CamVid上进行实验, 同样采用MIoU作为评价指标, 实验结果列于表4. 由表4可见, 本文模型相比DeepLab v3+其MIoU提高0.57%, 相对于SegNet提高9.28%, 证实了本文模型具有泛化能力.

表4 在数据集CamVid上不同模型的性能对比
综上所述, 针对图像语义分割中空间信息易丢失、 多尺度类别下目标分割率较低的问题, 本文提出了一种融合注意力机制和多尺度特征的图像语义分割方法. 通过改进ASPP模块, 提供了更丰富的尺度多样性, 从而提高了类别信息利用率;
使用ARM模块监督上下文语义信息的提取, 细化了信息边界;
A-FFM模块通过降低高、 低阶特征图之间的融合差异, 有针对性地减少特征丢失以增强模型的泛化能力, 并在不同数据集上对本文模型结构的鲁棒性进行了验证.