结合知识图谱的变分自编码器零样本图像识别
来源:优秀文章 发布时间:2023-02-16 点击:
张海涛,苏 琳
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105
随着近年来深度学习在人工智能领域的广泛应用,图像分类准确度达到了新的高度。但由于传统分类任务的每一个类别均要收集大量的训练数据,同时还要逐一地进行人工标注,费时费力且成本昂贵,对于某些稀有对象获取数据还较为困难,因此零样本图像识别成为近年来机器视觉领域的研究热点之一。零样本学习(zero-shot learning,ZSL)的主要思想在于模仿人类对接触新事物学习以及逻辑推理的过程。例如,人类在未见过某种动物的情况下,通过一些语义描述就可以推测识别出该类动物,这样的一个“触类旁通”学习过程可以总结为利用常识或先验性知识的语义描述来对已知类和未知类之间建立联系。
大部分ZSL是基于嵌入模型的学习[1-7],即学习一个兼容性的跨模态映射函数,将两个模态下的特征嵌入到一个空间后,进行最近邻搜索来预测未知类别标签。由于不同模态之间的特征有很大的语义间隔,同时已知类和未知类是完全不同的类别,仅从已知类学习的嵌入模型在用于未知类预测时会因为缺少未知类样本而产生偏差。
近来,基于生成对抗网络(generative adversarial network,GAN)[8]或变分自编码器(variational autoencoder,VAE)[9]生成模型的零样本学习[10-14]逐渐发展起来,即对未知类生成样本(特征),以控制已知类和未知类之间的比率。这种方法不仅避免了空间映射,缩小了语义间隔,还将ZSL转换成传统的分类任务,减轻了可见类和不可见类之间的数据不平衡,在准确率上有一定的提高。但由于GAN在训练过程中的不稳定性,VAE成为更好的选择,如Schonfeld等[12]提出的交叉对齐变分自编码器模型(cross and distribution aligned VAE,CADA-VAE),将生成的低维视觉特征和语义特征映射到潜在空间,根据潜在特征进行分类。然而,这些生成方法大多建立在属性注释、词向量文本描述这些语义辅助信息上。当辅助信息差异很小的情况下,生成的特征会有一些歧义,例如:使用属性“stripe”为斑马生成样本时,另一个同样标注了“stripe”的老虎也可能获得与斑马相似的合成样本(即域偏移问题[15]),而这一问题在很大程度上会影响分类结果。
基于此,为了更好地提高辅助语义信息的有效性,缓解域偏移问题,提升分类准确率,本文提出了结合知识图谱和变分自编码器零样本识别模型(variational auto-encoder combined with knowledge graph zero-shot learning,KG-VAE)。该模型以类别间的相关性做边,以类别标签的单词嵌入为类别节点,构建知识图谱(knowledge graph,KG)作为语义辅助信息库,联合类别分级信息,类别文本描述和词向量,涵盖丰富且有层次的辅助信息,同时将KG嵌入到生成模型VAE中,以减小生成特征的歧义性,使其更好地保留不同模态下的判定信息,促进知识迁徙。模型在CUB、SUN、AWA1、AWA2四个数据集上进行实验,结果证明KG-VAE达到了较好的分类准确率。
1.1 零样本学习研究近况
早期零样本方法基于属性的预测,由Lampert等[16]提出的基于语义属性的零样本学习的直接属性预测模型(direct attribute prediction,DAP)和间接属性预测模型(indirect attribute prediction,IAP)模型,两个模型奠定了零样本图像分类模型的基础框架。
后续发展的零样本分类大多是基于映射空间的:(1)将视觉特征嵌入到语义空间,Frome等[1]以及Akata等[2-3]提出的均是学习从视觉空间到语义空间的映射函数以及其他相似性度量来比较嵌入的视觉和语义特征从而进行分类;
(2)将语义特征嵌入到视觉空间,Kodirov等[7]使用语义自编码器进行零样本分类识别,从语义空间到视觉空间的映射可以缓解枢纽点问题(hubness problem)[17];
(3)将视觉特征和语义特征共同嵌入到一个潜在空间,Romera-Paredes等[4]将两个模态特征映射到一个空间,在嵌入空间中进行最近邻搜索以预测类别标签。Changpinyo等[6]通过对齐类嵌入空间和加权二分图的合成分类器进行分类。
而近年来,基于GAN和VAE的生成模型零样本学习得到了广泛的研究,Xian等[10]提出F-CLSWGAN基于WGAN[18]增加了分类正则化,以此生成更具有判别性的视觉特征来确保分类准确率;
Zhu等[14]提出的ABPZSL通过优化生成器和反向传播函数改进GAN,提高分类准确率;
但由于GAN在训练过程中的不稳定性,VAE成为更好的选择,Mishra等[11]提出的CVAE模型通过VAE学习生成潜在特征,进而进行零样本分类;
Schonfeld等[12]提出的交叉对齐变分自编码器模型(CADA-VAE),将生成的低维视觉特征和语义特征映射到潜在空间,根据潜在特征进行分类。
1.2 知识图谱
图(graph)是由节点(vertex)和边(edge)构成的,符号表示为G=(V,E)。知识图谱(KG)[19]本质上是语义网络的知识库,可以将其解释为多关系图,它包含多种类型的节点和边,节点表示语义符号,边表示语义之间的关系。
近来,研究者们开始将知识图谱与零样本识别相结合,Wang等[19]和Kampffmeyer等[20]使用GCN聚集知识图谱中的语义信息生成语义向量后与相应视觉特征向量进行比对计算,得出相似性分数;
Liu等[21]则是在GCN的基础上引入“属性传播机制”,通过最近邻将分类器将图像映射到与图像嵌入的属性向量最接近的类中;
以上三种方法均是通过GCN学习知识图谱中的语义信息,比对两个模态特征训练分类器。然而不同模态的特征具有较大的语义间隔,会对分类结果产生影响。本文将知识图谱结合到生成模型中,对不同模态特征通过生成低维向量后进行交叉对齐,缩小了语义鸿沟,促进了知识迁移。
1.3 图卷积神经网络
图卷积神经网络(graph convolutional network,GCN)[22]的引入最初是为了解决半监督的目标分类问题。GCN通过一系列卷积操作在图结构的节点之间传播信息,并获取图数据的相关性,对此模型通过:

在图G=(V,E)上进行类似卷积一样的局部聚合,输入为:
(1)特征矩阵X∈Rn×d(n为节点数,d为节点的特征维数),其中{xi∈X}ni=1,xi为每个节点的特征向量,B为偏差项。
在GCN的每一层,卷积运算通过聚集图中定义的相邻节点来计算每个节点的向量表示,并将其更新到下一层。将卷积运算依次叠加,在最后一层输出该节点的潜在嵌入。对于第i个类别节点,其第k层矢量表示为:

其中,Ni为第i个类别节点的邻居节点,Wk和Bk分别为卷积层中的权重矩阵和偏差项。
1.4 变分自编码器
变分自编码器(VAE)[9]是基于变分贝叶斯(variational Bayes,VB)推断的生成式网络结构[9]。变分自编码器包含编码器和解码器两个过程,两者的输出都是受参数约束变量的概率密度分布。假设原始数据集为X,生成数据样本集合为X^,产生的中间变量为Z。其中X是一个高维的随机向量,Z是一个相对低维的随机向量,该模型可以分成如下过程:
(1)推断网络即编码器根据输入变量建立潜在变量后验分布qφ(z|x)的过程。该过程会产生两个向量:均值μ和标准差σ。
(2)生成网络即解码器将从qφ(z|x)中采样得到的数据建立输出变量条件分布pθ(x|z)的过程,该过程把标准差向量中采样加到均值向量上,然后输入到生成网络中。
其中,φ指推断网络的所有参数,θ指生成网络的所有参数,通过KL散度(Kullback-Leibler)[23]来衡量两个分布之间的相似度,并通过优化约束参数φ和θ使KL散度最小化。即:

2.1 问题定义
零样本学习的形式化数学定义为:给定符号X表示图像的特征空间,X={Xtr,Xte},其中,Xtr为已知类图像,Xte为未知类图像;
符号Y表示类别标签,Y={Ytr,Yte},其中,Ytr表示已知类类别标签,Yte表示未知类类别标签,Ytr和Yte之间互斥,即,Ytr⋂Yte=∅;
符号Tr表示由N个已知类图像特征及其标签组成的训练数据集,Tr={Xtr,Ytr},符号Te表示由M个在训练数据集中未曾出现且不带标签的图像组成的测试数据集,Te={Xte,Yte}。零样本学习的任务是利用Tr训练分类器来实现对Te的精准分类,先使用Xtr和Ytr对模型进行训练,再通过已知类和未知类之间知识迁移,实现对未知类的预测,即:f:(Xte,(Xtr,Ytr))→Yte。
由于ZSL的测试阶段设置较为理想,不能真实反映现实世界中物体识别的情景,由此提出了广义零样本学习(generalized zero-shot learning,GZSL)[24],它与传统的零样本识别的区别在于不再将测试数据强制认定为仅来自未知类别,而是对测试数据的来源做更松弛化的假设,即测试数据可以来自于所有类别中的任意对象类。
2.2 KG-VAE模型
本文提出了一种结合知识图谱和变分自编码器零样本识别模型KG-VAE,该模型融合了嵌入模型和生成模型,包括训练模型阶段和分类识别阶段。训练模型阶段分为三个部分:(1)对视觉特征学习网络的训练。训练图像Ii输入CNN卷积神经网络,将提取到的图像特征Xi通过VAE编码成低维特征向量Zi,投入潜在特征空间。(2)对语义特征学习网络的训练。将类别语义向量(如词嵌入向量)送入基于知识图谱的深度神经网络模块,通过图变分自编码器对图中的节点进行聚合更新后编码生成新的低维语义向量Zj,投入潜在特征空间。(3)对每个模态特定解码器的训练。将生成的潜在向量Zi和Zj,在类别相同的条件下,分别用另一模态的解码器进行解码,重构原始数据,即,每个模态的解码器由提取到的其他模态潜在特征向量进行训练。在此基础上,训练一个softmax分类器。分类识别阶段则是利用学习好的网络融合未知类视觉和语义知识推断出样本的类别。模型结构图如图1所示。
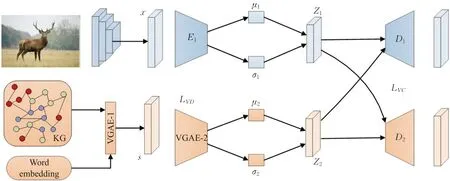
图1 KG-VAE模型结构Fig.1 KG-VAE model architecture
2.2.1 基于变分自编码器(VAE)的生成模型
模型的目标是在一个公共空间中学习两种模态特征,为了减少有效的判定信息丢失,模型通过变分自编码器对视觉特征进行编码,生成低维特征向量投入公共潜在空间。
变分自编码器包括编码器和解码器两部分,如图1所示,编码器E对图像特征Xi进行编码生成潜在向量Zi,后经由解码器D重构输出,因此基于变分自编码器的生成模型的损失函数为:
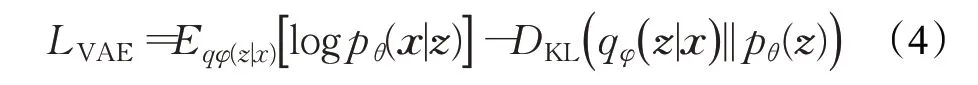
其中第一项为重构误差,用于测量网络重构数据的程度,以防重构数据过度偏离原始数据,第二项为推理模型的误差,pθ(z)服从多元高斯分布。
2.2.2 知识图谱嵌入
模型的语义特征由知识图谱(KG)提供。KG选择WordNet作为构建基础,以类别标签的单词嵌入为节点,节点包括训练数据中的已知类别以及测试数据的未知类别,每个节点都代表一种语义类别,即V={V1,V2,…,Vn};
若节点在WordNet中相关联,则连接对应的相关联节点,以类别间相关性为基础构建边,即以“父-子类”对类别间的层次关系进行建模,E={E1,E2,…,En},而类别之间的相关性由n×n维邻接矩阵A表示。
在KG嵌入过程中,如图1所示,模型通过图变分自编码器(variational graph auto-encoder,VGAE)[25]学习函数对KG中每一个节点进行聚合更新得到语义向量编码,生成一组聚集相关节点信息的低维语义向量S={S1,S2,…,Sn}作为类别语义嵌入。VGAE经过第一层图卷积网络生成低维特征矩阵:

编码器(推理模型)由图卷积网络GCN组成,它以邻接矩阵A和特征矩阵X作为输入,输出嵌入空间的变量Z。后通过第二层图卷积网络生成节点均值μ和节点方差log σ2:
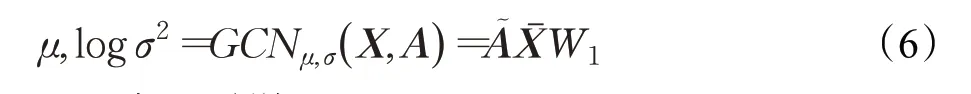
然后从分布中采样Z。
解码器(生成模型)由嵌入变量Z之间的内积定义,解码器的输出是一个重构的邻接矩阵A~:

图变分自编码器的损失函数:
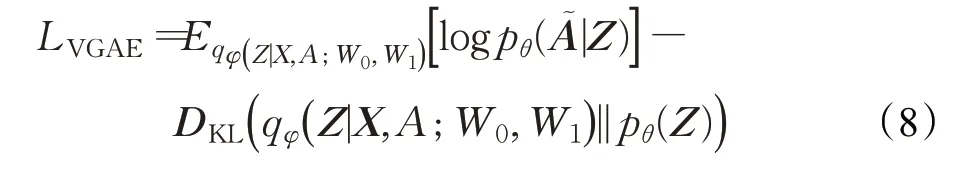
其中W0、W1为待学习的图卷积神经网络的权重参数,第一项为向量分布,第二项为正态分布的KL散度,故图变分自编码器的损失函数可以简化为与变分自编码器的损失函数结构一致:
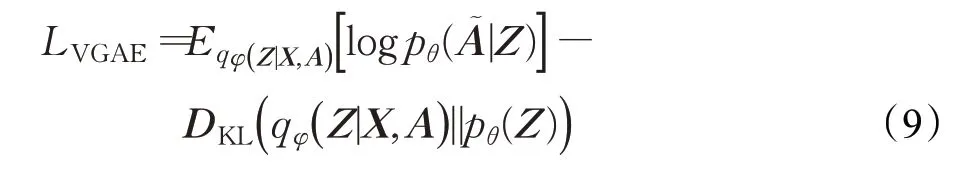
2.2.3 交叉对齐约束
KG-VAE模型利用两组变分自编码器VAE和VGAE分别学习两种模态(视觉特征和语义特征)的向量表示,为了提高模型的鲁棒性,引入变分对齐损失LVD和变分交叉损失LVC对模型进行约束。
变分对齐损失LVD:在两个模态的分布之间,通过最小化编码过程中产生的均值向量和标准差向量之间的距离,来缓解不同模态下特征之间的语义间隔以及维度差带来的判定性信息丢失问题,距离采用WGAN[18]中提出的2-Wasserstein距离,公式如下:
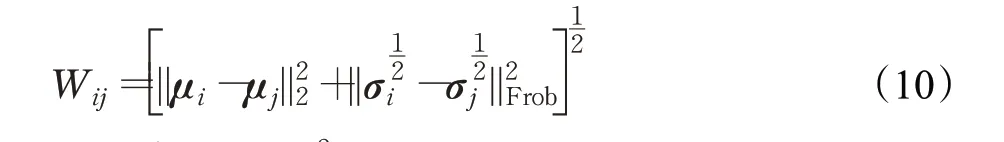
其中,{μi}2i=1和{σj}2j=1分别为编码过程中产生的均值向量和标准差向量。
则变分对齐损失LVD为:
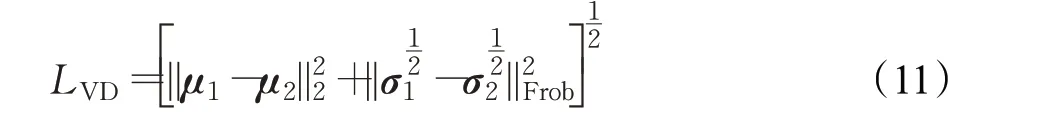
变分交叉损失LVC:为了减少生成重构过程中特征信息损耗缓解信息域偏移问题,增强编码器对不同模态特征融合的能力,通过解码另一模态同类别的潜在特征来重建原始数据,即:每个解码器都是在另一模态获得的潜在特征向量上训练的。
则变分交叉损失LVC为:
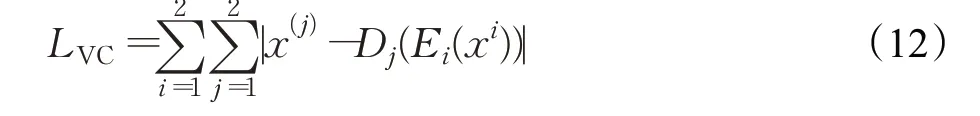
式中,Ei(i=1,2)为第i个模态的编码器,Dj(j=1,2)为第j个模态的解码器,i≠j,X(i)和X(j)分别表示同一类别标签下的视觉特征和语义特征。
LVC的展开式为:

其中,x、s为视觉和语义两个模态的原始特征;
x′(zi)i=1,2、s′(zi)i=1,2视觉和语义两个模态重构特征。
2.2.4 损失函数
综上所述,本文提出的KG-VAE模型利用两组变分自编码器VAE和VGAE学习视觉特征和语义特征的向量表示,同时引入变分对齐损失LVD和变分交叉损失LVC对模型进行约束。因此KG-VAE的目标函数包括两组变分自编码器的损失以及变分对齐损失和变分交叉损失,总损失函数L可表示为:
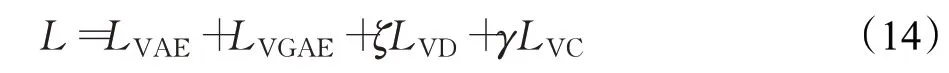
其中,ζ和γ是变分对齐损失和变分交叉损失的权重值,具体设置详见3.4节。设置所有重构误差均使用L1距离表示。通过最小化公式(14)来训练得到本文所提模型。
3.1 实验数据集
本文使用零样本图像识别广泛使用的四个数据集CUB、SUN、AWA1、AWA2来对模型方法进行评估。如表1所示,CUB和SUN是细粒度数据集,CUB有200种鸟类的图片,共11 788张图像,可见类别为150类,不可见类别为50类;
SUN有717场景类,共14 340张图片,可见类别为645类,不可见类别为72类;
AWA1和AWA2是粗粒度数据集,有50个动物类别,分别有30 475和37 322张图像,可见类别均为40类,不可见类别为10类。所有图片经由ResNet-101卷积神经网络最终池化层,得到的特征维数为2 048维。

表1 实验数据集详细信息Table 1 Details of experimental datasets
3.2 实验细节
模型使用预先训练的ResNet-101卷积神经网络来提取VAE编码的图像特征,经由卷积网络的最终池化层,得到的特征维数为2 048维。对于语义特征,使用在Wilkipedia训练的GloVe文本模型作为知识图谱中的特征表示,同时利用这些表示在WordNet中的上下位关系图构建知识图谱,通过图卷积层生成和ResNet-101输出特征同为2 048维的语义特征向量。VAE和VGAE的编码器和解码器之间均带有一个隐藏层的多层感知器。模型使用Adam[26]优化器通过随机梯度下降对模型进行100次迭代训练,批大小为50,每批训练都包含来自不同类别的图像特征和语义特征,但每个匹配的特征对必须来自同一类别。模型训练完成后,通过训练好的深度嵌入网络和编码器将已知类和未知类的图像特征和类嵌入特征投射到潜在空间,潜在特征的大小设为64维,然后利用潜在特征对softmax线性分类器进行训练和测试。
3.3 评价标准
为了减轻每个类别的测试数据不平衡所导致的偏差,模型将文献[27]以算法在训练数据集和测试数据集上得到的类平均准确度为基础的调和平均准确度(harmonic mean accuracy)作为零样本分类性能评价指标,其中类平均准确度为:

其中Dy是y类数据标签对的数据集,y^是对图像X的预测。
文献[27]提出的调和平均准确度(harmonic mean accuracy)计算公式为:

其中ACCs和ACCu分别表示在训练数据集和测试数据集上得到的类平均准确度。
3.4 权重值选择以及对实验结果的影响
经过多次实验证明,对于目标函数(14)L=LVAE+LVGAE+ζLVD+γLVC中的权重参数ζ和γ是经由大量实验的最优输出而设定。ζ和γ初始值设为0,其中ζ从第6次开始到第22次为止,每次迭代以0.54的倍速增加,γ从第21次开始到第75次结束,每次迭代以0.044的倍速增加。本文在数据集CUB和AWA1上采用控制变量法验证两个权重参数对实验的影响,实验结果如图2、3所示。对于参数ζ,当ζ∈(7,8)时,分类准确率趋于稳定,ζ=8.1时达到峰值。当γ=2.376时,分类准确率达到峰值。若ζ和γ继续增加,分类准确率会有所下降。与此同时,对比图2、3的峰值分类准确率,可以得出γ对实验结果的作用力高于ζ,这说明在交叉重构视觉和语义模态的潜在特征时,变分交差损失有效地约束了不同模态间的有效特征保留,缩小了对类别图像特征的分布的偏向,减小了跨模态间的语义鸿沟,有效地缓解了域偏移。

图2 权重参数ζ对分类结果影响Fig.2 Effect of weight parameter ζ on classification results
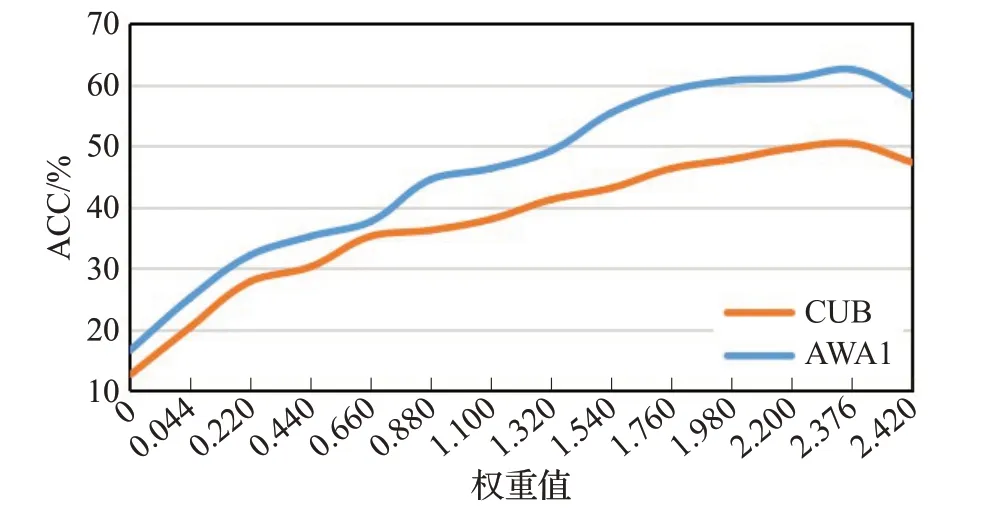
图3 权重参数γ对分类结果影响Fig.3 Effect of weight parameter γ on classification results
3.5 零样本图像识别
在零样本图像识别实验中,以复现的CADA-VAE[12]模型结果作为基准(baseline),为了更好地与基准模型做对比,本文沿用了CADA-VAE模型的参数。同时基准模型与本实验都是使用相同划分的基准数据集,故其余的对比实验结果均直接引用CADA-VAE论文中的分类准确率。
实验结果如表2所示。表中,黑体为每列最优值,“—”代表原文没有对该数据集做实验。

表2 不同模型零样本分类调和平均准确率Table 2 ZSL harmonic mean accuracy of different models单位:%
从表2可以得出,对比嵌入模型DEVISE[1]、ALE[2]、SYNC[6]、SAE[7]、KG-VAE在所有数据集上明显优于这些方法;
而对于生成视觉特征的CVAE[11]和F-CLSWGAN[10]模型,KG-VAE在数据集CUB和SUN上有一定幅度的提高;
CUB和SUN属于细粒度数据集,其中类别接近,特征差异小,对模型要求更高,而KG-VAE通过知识图谱将类别信息层次结构化后,有效地缩小了生成的辅助语义向量的误差,促进了已知类和未知类之间的知识转移,提高了分类准确率;
此外,对比基准模型(CADAVAE),KG-VAE在CUB、SUN、AWA1、AWA2四个数据集上分别提高了0.5、0.7、0.8、0.6个百分点。实验证明了知识图谱的引入有效地保留了语义类别的核心特征,更精准地对齐了同一类别不同模态之间的特征信息,缓解了域漂移问题,提高了模型的泛化能力。
3.6 广义零样本图像识别
为了进一步证明模型的有效性,以复现的CADAVAE[12]模型结果作为基准(baseline)进行广义零样本实验,分别与12种主流的方法进行对比实验,包括经典的ZSL方 法DEVISE[1]、ALE[2]、SJE[3]、EZSL[4]、LATEM[5]、SYNC[6]、SAE[7],视 觉 特 征 生 成 模 型F-CLSWGAN[10]、CVAE[11]、SE[13]和ABPZSL[14]。本实验沿用了基准模型的参数设置,实验结果如表3所示。
表3中,黑体为每列最优值,“—”代表原文没有对该数据集做实验,S为可见类别的分类准确率,U为不可见类别的分类准确率,H为两者的调和平均准确率。同时基准模型与本实验都是使用相同划分的基准数据集,故其余的对比实验结果均直接引用CADA-VAE论文中的分类准确率。
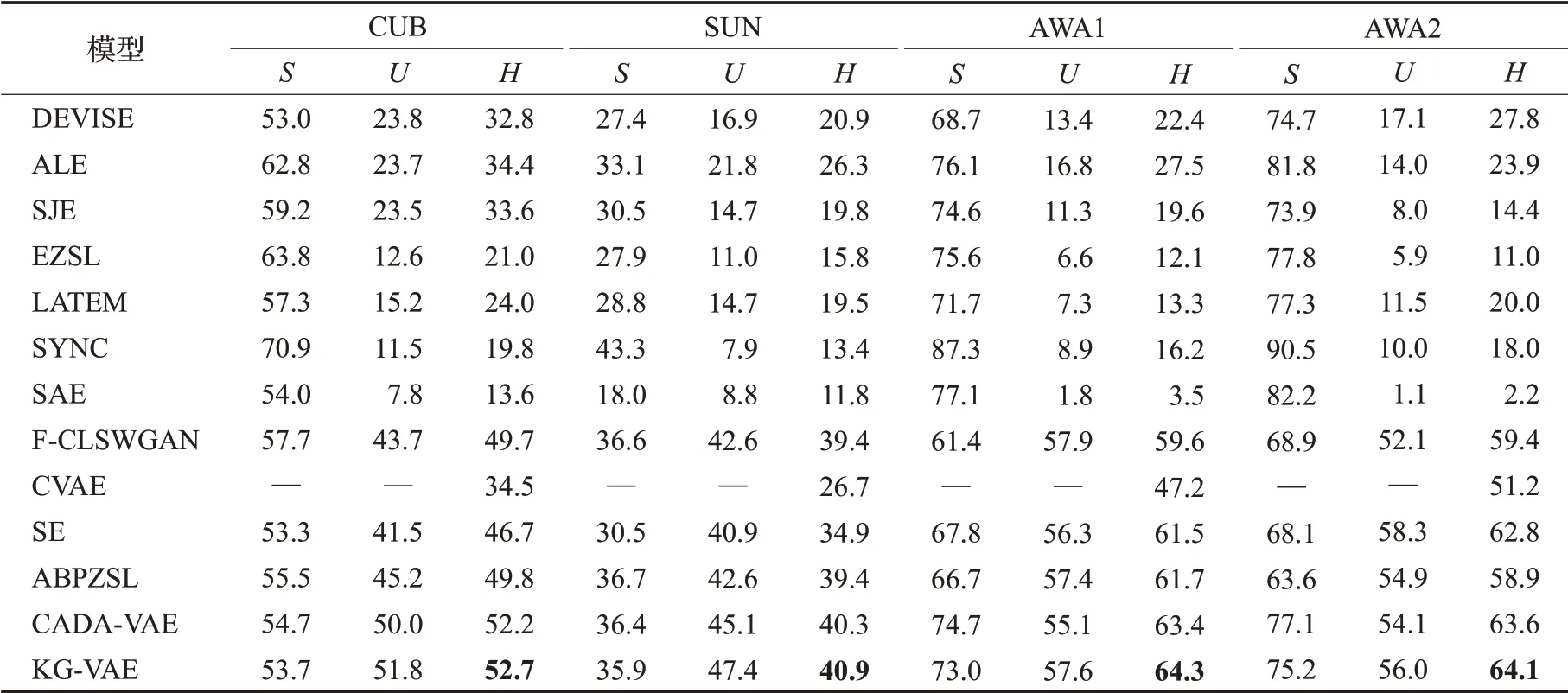
表3 不同模型广义零样本分类调和平均准确率Table 3 GZSL harmonic mean accuracy of different models 单位:%
对于经典的ZSL方法,DEVISE[1]、ALE[2]、SJE[3]、EZSL[4]、LATEM[5]使用线性相容函数或其他相似性度量来比较嵌入的视觉和语义特征从而进行分类;
SYNC[6]通过对齐类嵌入空间和加权二分图的合成分类器进行分类,SAE[7]使用语义自编码器进行零样本分类识别。对于F-CLSWGAN[10]、CVAE[11]、SE[13]、ABPZSL[14]模型学习生成人工视觉数据,从而将零样本学习问题转化为增加样本数据任务的生成模型。与这些方法相比,KG-VAE的分类准确度有着不同幅度的提高。此外,与基准方法CADA-VAE相比,KG-VAE在CUB、SUN、AWA1、AWA2四个数据集分别提高了0.5、0.6、0.7、0.5个百分点;
实验证明,本文模型具有良好的分类准确率,在保持两个模态潜在核心特征和判定信息有效的同时,知识图谱的引进有着积极的作用,丰富层次结构化语义信息比单一的属性辅助信息有着更好的扩展性,更为有效。KG-VAE模型在广义零样本图像识别方面有着一定的提高。
3.7 消融实验
为了进一步验证知识图谱对分类准确率的影响,本文同基准方法(CADA-VAE)[12]一样,在广义零样本图像识别下的CUB数据集上,通过设置不同损失函数以及相应的变量,对相应的模型进行消融实验。
公式(14)L=LVAE+LVGAE+ζLVD+γLVC为模型的损失函数;
当LVD=0,LVC=0时,此时的损失函数记为L1;
当LVC=0时,此时的损失函数记为L2;
当LVD=0时,此时的损失函数记为L3。
在消融实验中,在各个模型上比较不同辅助信息——属性向量嵌入(Att)和知识图谱(KG)嵌入的分类准确率。实验结果如图4所示。

图4 消融实验结果Fig.4 Results of ablation experiments
从实验结果中可以发现,知识图谱的引入对所有模型起着正向的作用,对比属性向量嵌入,知识图谱嵌入在有着不同幅度的提高,在对应的子模型上均提高了约0.5%,证明了以类的层次关系作为辅助语义,更好地巩固了类名词向量和视觉特征的映射关系,比只以属性向量嵌入作为类语义信息具有更好的性能,对提高分类准确率有着积极的意义。由此可以得出结论,将包含各种类边信息的知识图谱结合到生成的零样本识别模型时,分类准确率会随着类语义信息的丰富而有所提高,证明了论文算法的有效性。
为了更好地缓解ZSL中的域漂移问题和语义间隔问题,本文提出了一种结合知识图谱的变分自编码器零样本识别算法(KG-VAE)。通过将层次结构化的知识图谱嵌入到生成模型中,对齐公共嵌入空间中不同模态下的变分自动编码器生成的潜在特征来学习跨模态映射关系,在此基础上训练分类器。从实验结果来看,KG的引入对分类准确率起着积极的作用,尤其是对细粒度数据集,有效地缓解了域漂移和不同模态特征间的语义间隔;
实验证明,KG中丰富的语义信息对类别的表征能力更强,对已知类和未知类知识迁移的效果更好。但模型中的知识图谱还具有一定的局限性,可以融合更多的表征信息如属性关系、类别关系权重等等,是未来研究的方向。