改进YOLOv5s的无人机目标检测算法
来源:优秀文章 发布时间:2023-02-16 点击:
宋谱怡,陈 红,苟浩波
1.西安工业大学 电子信息工程学院,西安 710021
2.陕西凌云电器集团有限公司 卫星导航研究所,陕西 宝鸡 721006
交通问题一直是困扰世界各国的一大难题,交通拥挤不仅会造成一定的社会问题还会进一步加重环境问题,造成严重的经济损失。为了缓解经济高速发展给交通运输业带来的压力,近几年世界各国都进一步加强了对智能交通的研究和管理[1]。目标检测作为其关键且最基础的一环显得尤为重要,将采用灵活度较高,成本较低的无人机来实现路面交通信息采集,作为交通路况处理的一个重要依据。在一定水平上减少了公路交通管理方式的弊端,扩大了道路交通监控器的监控时间和范围,进一步加强智能交通系统的建设促进我国交通业的发展[1-2]。
传统的目标检测算法检测流程过于繁杂,严重影响目标检测的效率,已逐渐推出主流舞台。基于深度学习的目标检测算法逐渐显示出其优势,YOLO(you only look once)作为one-stage detection的开山之作在2015年首次被提出[3-4]。最新推出的YOLOv5s算法在模型参数量和浮点运算量方面表现更加突出[5-9]。
近几年,对于YOLOv5s的改进主要是在输入端、特征提取网络以及Head输出层。由于在无人机视角下检测目标呈较小形态且目标背景较为复杂,针对这一情况文献[10]提出了一种自适应特征增强的目标检测网络(YOLO-AFENet)来提高算法对小目标的检测率。在YOLOv5s原算法的基础上融合特征融合因子,设计了改进的自适应双向特征融合模块(M-BiFPN),提高网络的特征表达能力。但是其模型的损失函数设计未考虑到数据集长尾分布的特点、对于大目标的检测性能提升不够明显。为了提升检测器识别效果,文献[11]提出将注意力模块CBAM与YOLOv5s网络的Neck部分融合,从而提高网络的特征提取能力,但其算法计算量过大对于边缘设备十分不友好,因此还存在一定的改进空间。文献[12-13]提出的基于连续两帧间差分法的动态检测等方法使得无人机可以在复杂背景下快速准确地检测目标,但该方法对识别精度的提升不够明显。文献[14]提出一种超轻量型的目标检测网络,并提出在其颈部网络上进行改进,对检测头部锚框进行重新设计,缩小对检测锚框的设定,使其更适应对于小目标的检测。文献[15]针对目标检测中的漏检、误检等问题提出在特征提取网络中添加注意力机制,并且构建了一种可以和卷积神经网络进行端到端训练的注意力模块尽可能减少训练过程中中的损耗,最后在区域建议网络中用Soft-NMS替换传统非极大值抑制算法,从而降低算法漏检提高定位精度。从YOLO算法的发展可以看出,利用算法进行检测时,不断完善网络特征融合结构,以及利用多尺度特征图作预测对算法性能的改进都有一定帮助。基于算法革新发展以及现应用需求本文提出一种基于YOLOv5s的改进目标检测算法,通过添加压缩-激励模块以及对其颈部输出通道改进,并对损失函数进行替换,从而有效提高了算法性能。
YOLOv5s属于单阶段目标检测算法,其在YOLOv4的基础上添加了一些新的改进方法,对算法的性能提升提供了很大的帮助。其主要包含四部分:输入端、基准网络、Neck网络、Head输出层。
(1)输入端:检测图片输入。通常输入图像大小为640×640,该阶段首先对图像进行预处理,即将输入图片缩放到网络的输入大小,进行灰度处理等操作。在网络训练时,算法使用Mosaic数据增强方法进一步提高模型的训练速率和检测精度,并新增自适应锚框计算与自适应图片缩放方法。
(2)基准网络:通常是一些优质的分类器网络,该模块用来提取一些常用的特征表现。YOLOv5s中主干网络采用CSPDarknet53结构,使用Focus结构作为其基准网络。
(3)Neck结构:位于基准网络和主干网络之间,利用它可以进一步提升特征的提取能力。虽然YOLOv5s同样用到了SPP模块、FPN+PAN模块,但是实现的方法不同。YOLOv4的Neck结构中采用的普通卷积操作,YOLOv5s中采用CSP2结构在某种程度上增强其网络特征融合能力。
(4)Head输出端:目标检测结果的输出通道。不同的检测算法,输出端的通道数也不同,通常包括一个分类分支和一个回归分支。YOLOv5s采用的GIoU Loss损失函数,使得算法精确度得到进一步改善。YOLOv5s基本网络结构如图1所示。

图1 YOLOv5s网络结构图Fig.1 Network structure diagram of YOLOv5s
2.1 融入通道注意力机制
注意力机制(attention mechanism)首次被提出来自于人类视觉的研究,在人们的精神认知中,会主动去关注一部分信息,同时也会忽略其他可视的信息[16]。深度学习中的注意力机制与人类视觉的注意力机制相似,即从众多信息中把注意力集中在重要的点上,挑出重要信息,忽略其他不重要的信息[17]。因此通过融入通道注意力机制,可以更好地解决环境带来的干扰从而提高检测精确度。
虽然目前很多研究提出将通道注意力和空间注意力两者结合起来使用效果更好,但是这样会增加额外的运算量,影响其检测速率。另外,神经网络的感受范围是通过卷积操作来提高的,很大一部分融入的是空间注意力机制,基于以上两点考虑,本文提出融合通道注意力的YOLOv5s检测网络。
通道注意力经典的代表就是SENet(squeeze and excitation network),因此本文引入其中的压缩-激励模块,其目的在于通过建立特征通道之间相互依赖的关系,增强有用信息的特征,在处理阶段提高这些特征的利用率并抑制无用的信息特征。
如图2所示,压缩操作采用了全局平均池化来压缩输入通道的特征层,对特征图u压缩空间维度后的结果如公式(1)所示:

图2 压缩激励模块结构图Fig.2 Structure diagram of compression excitation module

其中,zc表示第c个特征的一维向量值;
h和w分别表示特征图的两个维度。激励操作会学习通道间的非线性相互作用,首先通过全连接层将特征维度降低到输入的1/16,然后通过ReLU激活函数增加非线性,再通过一个全连接层恢复到原来的特征层,瓶颈结构由两个全连接层共同组成,用来预测通道间的相关性,最后通过Sigmoid函数获得归一化权重。激励操作的表达式如(2)所示。

其中,σ指Sigmoid函数,δ为ReLU函数,g(z,w)表示两个全连接层构成的瓶颈结构,w1的维度为×c,w2的维度为c,r是一个缩放参数。
在压缩和激励操作完成后,通过公式(3)所示将乘法逐通道加权到原来的特征上。

这样就将通道注意力模块添加到了目标检测网络中,对于提高无人机的检测精度在一定程度上会有所帮助。
2.2 引入双锥台特征网络结构
为了使提高算法对复杂背景下小目标的检测能力,本文引入LIU等人提出的改进FPN的输出通道数值,使其经过FPN的特征融合之后,输出通道为[138,225,138]。但由于无人机拍摄图像的角度、高度、抖动等问题,导致目标呈现尺寸较小以及拍摄背景杂乱,通道的特征图组包含所提取的目标信息有限,从而使训练后所得到的模型检测效果较差[18]。为了提高检测网络对于小目标的检测精确度,本文引入双锥台特征融合(bifrustum feature fusion,BFF)结构,传统金字塔特征融合结构和本文的双锥台特征融合结构的对比图,如图3所示。

图3 双锥台特征融合结构Fig.3 Characteristic fusion structure of double-cone platform
为了检测图像中不同尺度的目标,本文选择5、6、7层的特征层,将三层不同大小的特征图组传输到颈部进行网络特征融合。
浅层特征图包含的细节信息较多,但是由于被检测的车辆目标较小,即使使用225通道的特征进行融合,其包含的可用目标信息仍然不足以检测出足够有用信息,为了既减少模型计算量,又不降低检测精度,本文选择使用138通道的C5特征图;
C7特征层包含较多的特征信息,经过特征融合包含的可用信息较多,为了更好提取目标特征信息,故选择138通道输入下一层;
而C6层特征图,不但包括细节信息,还包括图像的语义信息,相比C5和C7层可获得的特征信息更全面,因此225通道的特征信息传至检测头部网络。
在原有特征网络的基础上,双锥台特征融合结构更巧妙地利用了各特征提取层之间相互联系,提取出包含语义信息较多的特征层进行通道扩展处理,方便网络提取到识别任务中需要的有效信息,尽可能减小干扰信息对目标识别精确度的影响。且选择性地进行通道扩展,对于模型参数大小来说影响甚微,从而避免算法训练过程中不必要的运算,在保证算法检测精确度的同时尽量提高其检测速度。
实验结果验证,经此改进所得到的特征融合方式,无人机对复杂背景下的小目标检测精度得到进一步的提升。
2.3 损失函数改进
YOLOv5s采用GIoU Loss做bounding box的损失函数,使用二进制交叉熵(BCE)和Logits损失函数计算类概率和目标得分的损失[19]。
GIoU Loss在原函数的基础上引进预测框和真实框的最小外接矩形。
GIoU公式:
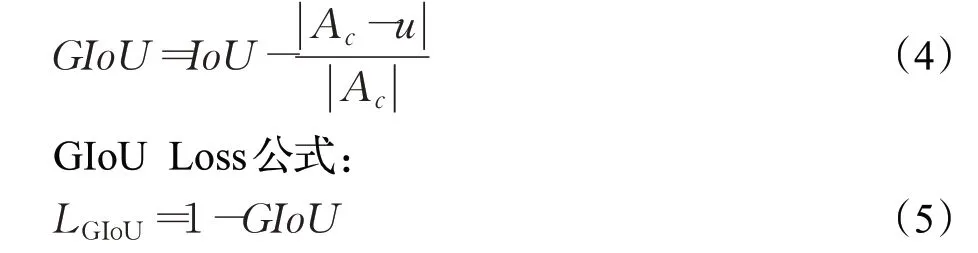
式中,IoU表示边界框(predicted box,PB)和真实边界框(ground truth,GT)的交并比,Ac表示将PB和GT同时包含的最小的矩形框的面积,u表示PB和GT的并集,LGIoU为GIoU损失。当两框完全重合时取最小值0,当两框的边外切时,损失函数值为1;当两框分离且距离很远时,损失函数值为2。使用外接矩形的方法不仅可以反映重叠区域的面积,还可以计算非重叠区域的比例,因此GIoU损失函数能更好地反映真实框和预测框的重合程度和远近距离。
但是GIoU Loss包含时计算得到的IoU、GIoU数值相等,损失函数值与IoU Loss一样,无法很好地衡量其相对的位置关系。同时在计算过程中出现上述情况,预测框在水平或垂直方向优化困难,导致收敛速度慢。而CIoU Loss在针对上述问题考虑了以下三点分别是覆盖面积、中心点距离和长宽比,如下公式:

式中b和bgt表示PB和GT的中心点,ρ2(·)表示求欧式距离,c表示PB和GT的最小包围框的最短对角线长度,α表示一个正平衡参数,ν表示PB和GT的长宽比的一致性。α和ν的定义如公式(8)、(9):

其中wgt、hgt和w、h分别表示GT和PB的宽度和高度。
相比YOLOv5s中使用的GIoU Loss,CIoU Loss在损失项中加入了PB、GT中心距离和长宽比例的惩罚项,使网络在训练时可以保证预测框更快地收敛,并且得到更高的回归定位精度,本文将CIoU Loss作为车辆检测网络的损失函数。
3.1 数据集处理
(1)数据集筛选
本课题主要针对智能交通系统中的车辆进行视频采集,由于自采数据受限,因此本课题采用目前公开的数据集。根据本课题需求对目前公开的无人机拍摄视频图像进行筛选重建。选取的无人机拍摄数据集有VIVID数据集、VisDrone-2019数据集、VOC2007数据集以及自己采集图像,共计11 260张,所有数据都采用PASCALVOC格式进行标注,其中80%用于训练,20%用于测试。数据集中包含各种交通场景,包括高速公路、十字路口、丁字路口,不同的环境背景,包括白天、夜晚、雾霾天、雨天。该类数据集满足实验训练的需求,更好地实现无人机对地面小目标的检测。数据集示例如图4所示。

图4 数据集示例Fig.4 Dataset example
(2)数据集标注
将采集的无人机拍摄图像按照算法模型的需求,使用Labeling软件对图片进行标注,均标注保存为PASCAL VOC格式。将图中出现的小轿车均标注为car标签;将图中出现的出租车标注为taxi标签;
将卡车均标注为truck标签;
将公交车标注为bus标签。具体标注如图5所示。

图5 数据集标注图Fig.5 Dataset annotation plot
3.2 实验环境与评估指标
(1)实验环境
本文实验平台操作系统为Ubuntu 18.04,CPU为Intel Xeon E5-2620 v4,GPU为Nvidia GeForce GTX 3080Ti,实验仿真使用Windows10系统下PyTorch深度学习框架,开发环境为Python 3.9,PyTorch 1.6.0,
CUDA 11.1。
(2)参数设置
本文为保证训练结果的准确性,参与对比的算法均在相同训练参数下,对算法进行训练测试,模型参数值设置如表1所示。

表1 参数设置表Table 1 Parameters setting table
(3)评估指标
为了更准确地分析检测性能,本文采用每秒处理的图像帧数(frame per second,FPS)、平均精度均值(mean average precision,mAP),作为本实验算法模型的评价指标,每种指标都会在一定程度上反映检测算法在不同方面的性能。首先应计算其查准率(precision)和查全率(recall)。查准率是模型预测的所有目标中,预测正确的比例,突出结果的相关性;
查全率又称召回率,所有的真实(正)目标中,预测正确的目标比例。公式如下所示:

其中,TP表示实际为正例且被分类器划分为正例的样本数量;
FP表示实际为负例但被分类器划分为正例的样本数量;
FN表示实际为正例但被分类器划分为负例的样本数量。
平均精度(average precision,AP)就是对数据集中的一个类别的精度进行平均,如公式(12)所示,p和r分别表示查准率和查全率,AP为曲线包含的面积。平均精度均值(mAP)是指所有类AP的平均值,其计算公式如式(12)、(13)所示:

3.3 模型训练
实验在自建数据集上进行,首先针对YOLOv5s训练要求更改配置文件,设置实验参数值包括衰减系数、epoch值、学习率、批量、动量等。在实验训练过程中通过查看训练日志可以发现,在训练达到300次左右时,损失函数基本不再下降逐渐趋于平稳,因此在训练达到300次时终止训练。将训练日志中数据进行统计,具体结果如图6、7所示。

图6 改进算法mAP变化曲线Fig.6 Change curve of improved algorithm mAP

图7改进算法损失变化曲线Fig.7 Loss change curve of improved algorithm
图6 、7分别为改进算法模型训练过程中mAP和损失函数变化曲线图,由图中可以看出改进后算法模型检测精度可达到86.3%,损失函数变化曲线随着训练次数的增加在250~300次时逐渐趋于平稳。
3.4 实验结果
(1)压缩激励模块对比实验
为了验证压缩-激励模块对算法改进的有效性,本节采用对照实验的原理,分析改进模块对算法性能提升的有效性。分别对比了YOLOv5m、YOLOv5s以及其分别引入压缩激励模块后在同一数据集上的实验结果,结果如表2所示。

表2 压缩-激励模块对算法性能影响对比Table 2 Influence comparison of compression-excitation module on algorithm performance
表2第一行是YOLOv5m原算法在数据集上的实验结果,平均检测精度为73.6%,检测帧率为89.3 frame/s,加入压缩-激励模块后平均检测精度提升5.5个百分点,检测帧率降低3.8 frame/s;
YOLOv5s在数据集上的平均精度和检测帧率分别为69.5%、126.6 frame/s,加入压缩-激励模块后平均检测精度提升了7.8个百分点,但是其检测帧率降低了2.9 frame/s。为了进一步验证实验的有效性,横向对比在YOLOv5s基础上引入SAGN(空间注意力模块),可以看出其对原算法的精度有一定的提升,但是相比本文引入模块实验效果较差,并且其对算法速度的影响较大。在原算法基础上引入CBAM(卷积注意力模块),通过实验结果可看出其虽然对精度提升幅度较大,但是由于其同时关注空间和通道信息,因此其检测速度不尽如人意,几乎只有原算法速度的一半。由此可以看出引入压缩-激励模块对算法精度有一定改进,但其同时也会增加一定计算量,从而对检测速度有一定影响。
(2)颈部不同输出通道对比实验
为了验证颈部不同输出通道对算法实验结果的影响,对三层输出通道进行重组,进行训练得到不同的检测结果,具体结果如表3所示。

表3 不同输出通道对算法效果影响对比Table 3 Influence comparison of tdifferent output channels on algorithm effect
由表3可以看出当增加模型输出通道数时,模型参数也随之增加,其检测性能也有一定提升。但同时也出现了模型数量增加但其检测精度下降的情况,比如通道数由[128,225,138]增加到[225,225,138],模型参数由3.81 MB增加到4.41 MB,但是其检测精度却由74.4%降为73.2%。由于无人机视角下检测目标过小并且易受周围复杂背景影响,其负样本的增加数量大于正样本数从而导致检测精度下降。综合评估下当通道数为[138,225,138]时检测精度最高为76.8%,模型数为3.97 MB,相对原算法检测精度提高了7.3个百分点。由此可见,引入双锥台特征融合结构对于提升算法性能有一定作用。
(3)损失函数对比实验
为证实本文提出改进损失函数的有效性,进行损失函数对比实验,实验参数中设置的epoch值为300,在实验训练过程发现训练达到300次左右时,损失函数基本趋于平稳,因此终止训练。具体训练结果如图8所示。

图8 损失变化曲线对比图Fig.8 Comparison diagram of loss change curves
由图8训练后的损失函数对比图可以清楚看出,改进后YOLOv5s的损失函数下降趋势更明显,表明了改进后算法的有效性。
为了进一步验证改进损失函数的有效性,将改进损失函数与原算法损失函数以及MAE(绝对误差损失)对算法性能影响的结果进行对比,结果如表4所示。

表4 损失函数实验结果对比Table 4 Experimental results comparison of loss functions
由表4,为了验证改进损失函数对算法性能的影响,在实验中将算法中损失函数进行单独替换,分别替换为MAE、CIOU Loss与原算法中GIOU Loss进行横向对比实验。从结果可以明显看出,将损失函数替换为MAE后检测平均精度提高了0.6个百分点,检测帧率提高了2.7 frame/s;
替换为CIOU Loss后,由于CIoU Loss在损失项中加入了PB、GT中心距离和长宽比例的惩罚项,使网络在训练时可以保证预测框更快地收敛,并且得到更高的回归定位精度,可以看出检测精度提高了3.3个百分点,检测帧率提升较多,增加了11.6 frame/s,因此可以得出本文提出的CIoU Loss对算法速度提升效果较优。
(4)消融对比实验
为了更好地验证本实验三种改进策略的有效性,在自建数据集上展开消融实验,对改进算法的有效性进行分析。依次在YOLOv5s的基础上加入压缩-激励模块、BFF模块以及改进损失函数。为保证实验的准确性,训练过程中均采用相同参数配置,衰减系数为0.000 5,学习率为0.01,批量设置为16,动量设置为0.937。实验结果如表5所示。

表5 消融实验结果对比Table 5 Comparison of ablation experiment results
表5第一行表示改进前YOLOv5s在自建数据集上的训练结果,平均检测精度是69.5%。在分别引入SENet和BFF模块之后可以明显看,lSENet对检测精确度的影响较大,但是BFF对检测速度的提升较为明显。通过对这两个模块的功能分析得出,压缩-激励模块主要是增加计算量从而提升模型算法的特征提取能力,因此对检测精度影响较大,计算量增加也对检测速度有一定影响。而BFF通过增加模型通道在提升检测精度的同时也对检测速度有一定改进。在同时引进两个模块之后,检测模型得到最优结果,检测精度和帧率分别提高了16.8个百分点和6.6 frame/s。
(5)模型检测结果
为了更好地展示改进后算法的检测效果,分别选取道路情况复杂的十字路口、夜晚交叉路口以及住宅区旁边的道路三种不同场景下拍摄图像,对原算法YOLOv5s和改进后的算法进行测试,实验结果对比如表6所示。

表6 实验结果对比Table 6 Comparison of experimental results
如图9中第一排为原YOLOv5s算法实验结果图,第二排为PP-YOLO算法在数据集上的训练结果,第三排为YOLO v4的训练效果图,第四排为改进后YOLOv5s算法的实验结果图。由图9(a)可以看到,改进前的YOLOv5s算法并没有检测出远处的小目标车辆并且检测精度较低,而改进后的算法不仅检测出远处较小目标还进一步提升了算法精度。图9(b)中远处斑马线旁的出租车原算法实验中并没有检测出,而改进后算法不仅准确检测出并且对其进行正确的分类。图9(c)中可清楚看出,改进后算法对于道路车辆的精准分类以及检测精度有明显提升,进一步说明算法改进的有效性。

图9 检测结果对比图Fig.9 Comparison diagram of test results
本文基于YOLOv5s提出一种改进YOLOv5s算法,主要针对无人机拍摄图像中检测目标较小、背景复杂及特征提取受限,导致无人机检测速度和精度无法同时提升的问题。该算法在YOLOv5s的基础上引入压缩-激励模块,用于提高网络的特征提取能力;
其次引入双锥台特征融合结构从而提升算法对小目标的检测精度;
最后替换CIoU Loss为算法模型的损失函数,在提高边界框回归速度的同时提高定位精度。本文实验以VIVID、VisDrone-2019数据集为基础,筛选建立新数据集进行实验。实验结果表明,在复杂环境下改进后的算法适应力更强,准确率在原算法的基础上提高了16.8个百分点,检测帧率提高了6.6 frame/s。尽管模型权重相对来说已经很小,但是对于边缘设备而言仍然负载过大,因此模型的轻量化是其未来发展的一个重要方向。