超体素约简和谱聚类结合的机载LiDAR点云单木分割
来源:优秀文章 发布时间:2022-12-09 点击:
王伟伟,庞勇,杜黎明,张钟军,梁晓军
1.中国林业科学研究院 资源信息研究所,北京 100091;2.国家林业和草原局 林业遥感与信息技术重点实验室,北京 100091;3.北京师范大学 人工智能学院,北京 100875
激光雷达LiDAR(Light Detection And Ranging)可以获得高精度的森林空间结构信息,在森林资源调查监测中的应用日益广泛(Hyyppä 等,2008)。机载激光雷达ALS(Airborne Laser Scanning)可以精确刻画冠层垂直结构,提取林分和单木尺度的森林参数(Sačkov 等,2017;
李增元 等,2016)。ALS点云数据的单木分割对林业科学研究和生产实践具有重要意义,基于准确的分割结果,可以从中获取描述单木空间结构特征和生物化学组分属性的单木因子,为评价森林生长和生态功能、评估森林破坏程度和监测森林再生情况提供数据支持(Chen等,2007)。
对ALS 点云数据的单木分割算法可以大致分为二维方法和三维方法(Lindberg 和Holmgren,2017)。二维方法通过表示冠层上部轮廓的CHM(Canopy Height Model) 或DSM (Digital Surface Model)栅格数据,将其中的局部最大值识别为树顶来分割单木。搜索局部最大值时,可以选择固定或可变的窗口尺寸(Popescu 等,2002;
Zimble等,2003)。基于冠层上表面的局部最大值,常用的单木分割方法包括分水岭方法(Chen 等,2006;
Zhao 等,2014;
李旺等,2015),区域增长法(Solberg等,2006;
Pang等,2008;
Zhen等,2015),以及其他基于二维图像分割的算法(Brandtberg,2007;
李平昊等,2018)。尽管这些方法对于树顶明确且树冠轮廓清晰的高层单木具有很好的分割效果,但使用的二维栅格数据损失了几乎全部的林下信息,对于许多低矮单木缺乏识别能力。
与二维方法相比,更好地利用完整LiDAR 点云数据的三维分割方法在单木分割问题中受到越来越普遍的关注。聚类方法是一种常用的三维方法,其主要包括K-means 聚类、层次聚类和局部最大值聚类等(Morsdorf 等,2004;
Lee 等,2010;
Li 等,2012)。Gupta 等(2010)比较了几种改进的K-means聚类和层次聚类方法,发现在K-means算法中使用局部最大值作为初始种子点并缩小点云高度取得了更好的结果,同时层次聚类方法没有得到令人满意的结果。Ayrey 等(2017)提出了一种对点云数据分层使用K-means 的层叠方法,对树冠覆盖实现了较高的估计精度。这类算法对于大树和单一简单林分可以产生合理的分割效果,但是算法对于多层复杂林分的应用存在局限性(Williams等,2020)。
基于谱图理论的谱聚类方法在分割问题中表现优异,其对数据分布没有限制,且无需假定初始种子点。谱聚类方法通过构造数据点间的相似度矩阵并进行特征分解,在特征空间中实现数据的聚类分割,然后将结果映射回原始的数据空间。谱聚类方法在LiDAR 点云数据处理中的挑战在于高计算复杂度,尤其是相似度矩阵的特征分解步骤。Nyström 近似是对谱聚类方法的一种有效简化(Fowlkes 等,2004),其使用采样技术和数值逼近理论,通过插值权重将采样点的特征向量扩展到非采样点,从而快速地得到原始相似度矩阵的近似特征值和特征向量,减少算法的计算复杂度。由于不同的采样结果会对原始相似度矩阵产生不同的近似,因此采样方法对Nyström 方法的精确性至关重要。已有很多研究提出了不同的采样方法(Zhang 和You,2011;
Zeng 等,2014;
Cohen 等,2015)。Bouneffouf 和Birol(2015)指出,可以通过最小化新的和已有的采样点之间相似度的平方和来最大化采样点间相似度矩阵行列式,从而最小化近似误差。基于这一概念,Bouneffouf 和Birol(2015)提出了考虑采样点方差和相似度的逐步迭代MSSS(Minimum Sum of Squared Similarities)方法,该方法与其他采样方法在不同数据集的对比实验中展示出很好的精度结果和优异的采样性能,同时,理论分析中也进一步证实了该采样方法的优越性(Bouneffouf和Birol,2016)。
此外,考虑到三维点云数据量产生的算法效率限制和存储空间困境,体素化方法成为许多三维方法对原始点云数据处理的有效方式。体素化方法将原始点云投影到体素空间中,进而在体素空间中进行单木分割。Wang 等(2016)根据点密度使用给定分辨率的立方体来构建体素点云,然后根据体素的空间邻域关系从冠层中检测树顶。Reitberger 等(2009)对体素化点云使用归一化切割NCut(Normalized Cut)方法(Shi和Malik,2000;
王濮等,2019)进行迭代二分实现了对单木的三维分割,但是其高的计算复杂度限制了对大规模数据的普及和推广。
与传统规则立方体的体素化方法相比,超体素方法(李平昊等,2018)提供了一种更为灵活有效的思路来构建更为紧致的体素空间。可以选择合适的分割方法对原始点云进行过分割,将获取的过分割结果视为体素点,从而构造整个体素空间。本文算法参考超体素的思路,使用均值漂移(mean shift)算法实现对LiDAR 点云的体素化,有效地减小后续计算过程中的数据量。作为一种快速有效的聚类算法,mean shift 算法不需要对数据分布或聚类数目进行假设,通过迭代地将每个搜索点移向偏移均值点处来对点进行分组。在此过程中,搜索点总是沿着局部密度递增的方向移动到密度极大值点处,最终构造出合理紧致的体素空间。对构造的体素空间,本文算法使用Nyström 方法实现谱聚类算法中特征分解步骤的快速近似,得到最终的单木分割结果。其中,关键的采样过程通过MSSS 方法完成,以快速获取最佳采样结果。本文算法旨在通过一系列优化手段提升谱聚类算法的计算效率,使其优越的分割性能在机载LiDAR 点云数据的单木分割问题中得以发挥,为大规模数据应用提供可能。
2.1 实验区基本情况
研究区位于中国黑龙江省佳木斯市的孟家岗林场(46°20′N—46°30′N,130°32′E—130°52′E),其地理位置如图1所示。孟家岗林场中的人工林面积达1.5 万ha,占总林地面积的76.7%。人工林的90%由落叶松(Larix olgensisHenry),红松(Pinus koraiensisSieb.et Zucc.),樟子松(Pinus sylvestrisL.var.mongolica Litv.)和云杉(Picea asperataMast.)组成。
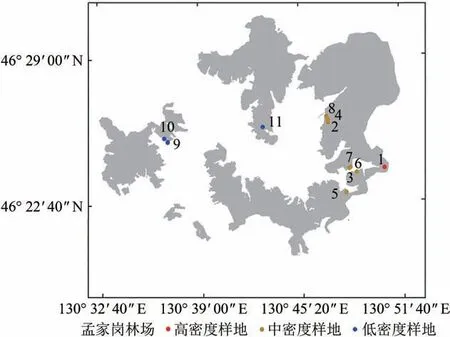
图1 孟家岗林场位置及不同株数密度的样地分布Fig.1 Study area and the distribution of field plots with different stem densities
2.2 LiDAR和地面实测数据
本研究采用中国林业科学研究院机载遥感系统CAF-LiCHy 于2017年5月31日—6月15日 采 集的LiDAR 数据。其中LiDAR 传感器为Riegl 的LMS-Q680i(Pang 等,2016),航摄平台为运-5 多用途飞机,平均绝对飞行高度为1000 m,相对飞行高度约650 m。ALS 点云采集于LiCHy 系统,点云数据密度约为20 pts/m2。对ALS点云的处理包括基于体素的孤立点去除、基于不规则加密三角网TIN (Triangulated Irregular Network)的地面点分类、高度归一化处理和地面点去除,此点云数据作为原始点云数据。
本研究选择了11 个落叶松样地数据进行单木分割实验以评估算法性能,其位置分布如图1 所示。地面调查数据于2017年6月—7月获得,表1对样地的关键参数进行了总结。胸径DBH(Diameter at Breast Height)使用围尺测量得到,且只记录DBH≥5 cm 的单木参数。树高使用超声波树木测高仪测得,11 个样地的平均树高从13—25 m不等,且同一个样地内树高差异较小。冠幅使用钢卷尺测量东西及南北两个方向,并计算其平均值作为平均冠幅。样地中心地理位置由全球卫星导航系统GNSS(Global Navigation Satellite System)手持接收机测量获取,同时该接收机使用参考接收机获取的实时差分信号进行校正,单木位置通过GNSS 手持接收机、全站仪、地基激光雷达和皮尺等测量数据的空间校正得到,定位精度在1 m 之内(梁晓军 等,2020)。此外,落叶松人工林样地单木总体分布相对密集,但样地之间存在一定株数密度差异,据此将11 个样地按照株数密度分为高(H)、中(M)和低(L)等3 类,用以进一步检验算法对不同株数密度样地的分割性能。最终,去除样地内的枯死木记录,得到的单木株数为991株。

表1 样地数据参数Table 1 Characteristics of field plots
本文基于谱聚类方法的思路框架,并通过引入基于均值漂移(mean shift)的体素化和Nyström方法解决其计算效率低的问题,图2显示了本文算法的一般工作流程。传统谱聚类算法直接对原始数据构造相似图,对相似度矩阵进行特征分解,在特征空间使用K-means 方法进行聚类,最终将结果映射回原始数据空间得到分割结果。与之相比,本文算法有以下两个关键的改进之处:

图2 基于Nyström-谱聚类算法的单木分割流程Fig.2 Flowchart of individual tree segmentation using Nyström-based spectral clustering algorithm
(1)使用mean shift 方法将原始的LiDAR 点云数据转换到体素空间以合理压缩数据量;
(2)使用Nyström 方法快速计算相似度矩阵的近似特征向量和特征值。其中的关键采样步骤由考虑采样点方差和相似度的逐步迭代MSSS 采样方法实现。
3.1 基于mean shift的体素化
Mean shift 是一种快速有效的聚类算法,本文使用mean shift 方法来完成体素化过程,并将mean shift的带宽参数设置得较小,以实现过分割来达到体素化目的(带宽参数的详细设置见3.5 节中关于参数配置部分)。与使用给定分辨率的立方体来构建规则体素点云的方法不同,在使用mean shift 方法构造的体素空间中,每个体素点由mean shift 的聚类结果表示,体素位置由类内中心点坐标确定,体素权重等于类内的点数。后续的分割过程将基于体素空间完成,可以通过mean shift 聚类结果的类别标签将原始点云中的每个点对应到体素点云中,从而将体素空间中得到的分类结果映射回原始点云,最终得到单木的分割结果。同时,可以通过体素权重将原始点云的空间分布信息表征在体素空间中,即,体素权重越大表明该局部区域的原始点密度越高。在实验过程中,使用mean shift聚类算法得到的体素点云数据量较原始点云约减少了10 倍,大大减轻了算法在后续过程中的计算负担。
3.2 相似度函数与相似图
参考Von Luxburg(2007)的工作,本文使用常用的高斯相似度函数构造k-近邻图,其很容易构造稀疏邻接矩阵,且不易受到不良参数选择的影响。考虑单木的形态和体素的属性,本文采用的高斯相似度函数构造如下:
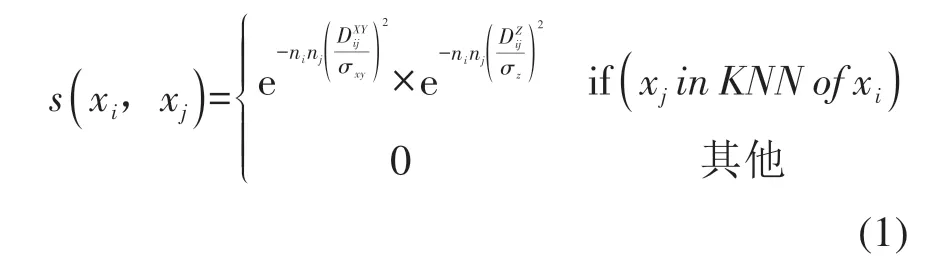
式中,s(xi,xj)表示两个体素xi和xj之间的相似度;
KNN 表示k-近邻;
和别是两个体素xi和xj之间的水平和垂直欧氏距离,其被分配不同的比例因子σxy和σz以适用于单木的椭球形状;
两个加权因子ni和nj是体素xi和xj的权重,以维持体素空间与原始点云的一致性。此外,考虑到基于mean shift的体素化产生的体素点没有规则的空间位置索引,故无法像传统立方体体素化方法那样快速访问k-近邻,本文采用KD-Tree数据结构来弥补这一不足。
3.3 Nyström方法
在体素空间中构建完成k-近邻图即可得到体素点间的相似度矩阵,本文使用Nyström 方法快速计算相似度矩阵的近似特征向量和特征值。
3.3.1 Nyström理论
对一有N个体素点的数据集,构造其k-近邻图得到相似度矩阵W∈RN×N,Nyström 方法将所有的点分为n个采样点和m个剩余点(m=N-n),进而将相似度矩阵W分块为

式中,A∈Rn×n表示采样点间的相似度矩阵,且有对角化形式A=UΛUT;
B∈Rn×m表示采样点和剩余点之间的相似度矩阵;
C∈Rm×m表示剩余点间的相似度矩阵。
Fowlkes 等(2004)给出了W的近似正交特征向量的构造方法。若矩阵A正定,定义S=A+A-12BBTA-12,且其对角化为S=USΛS,其中,US∈Rn×n且列元素为为S的特征向量,ΛS是对角元素为S对应特征值的对角矩阵。那么=VΛSVT即为W的近似特征分解,且有

通过这种方式,特征分解的计算复杂度由对W的O(N3)减小为对S的O(n3)。此外,对于归一化谱聚类算法,还需要实现相似度矩阵的归一化,即其中,为相似度矩阵的度矩阵,是对角元素的对角矩阵。由于有

式中,1表示单位列向量,ar,br∈Rn分别表示矩阵A和B的行和向量,bc∈Rm是矩阵B的列和向量。那么就可以将矩阵A和B归一化为
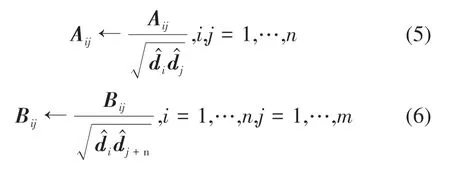
3.3.2 MSSS采样
Nyström 方法的关键在于采样方法,本文使用考虑采样点方差和相似度的逐步迭代MSSS 采样方法(Bouneffouf 和Birol,2015)得到最佳采样点。MSSS方法综合了增量采样IS(Incremental Sampling)和最小相似度采样MSS(Minimum Similarity Sampling)。如图3所示,该方法首先从完整数据集中随机选择两个点到采样点集中;
然后从剩余点集中随机取出一定比例的点,计算这些点与采样点集中采样点之间的相似度平方和,并将最小值点作为新的采样点放入采样点集中;
重复该过程直到采样点集的大小满足要求。
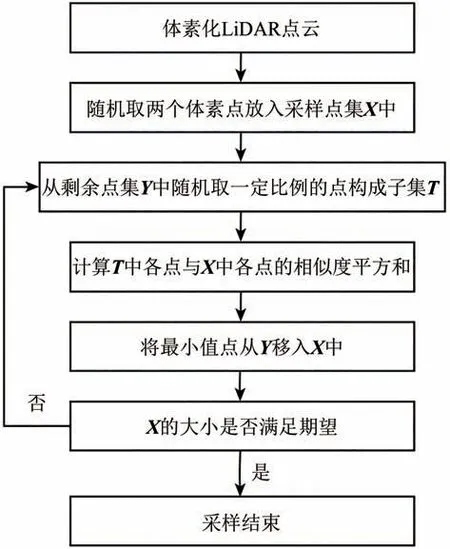
图3 MSSS采样方法过程Fig.3 Flowchart of MSSS sampling method
根据Bouneffouf 和Birol(2015)的评估建议和模拟实验,将每次从剩余点集中随机取出的子集T占剩余点集Y的比例设置为10%,期望的采样点集合X的大小也确定为原始体素点集合的10%。
3.4 单木分割及参数提取
在计算相似度矩阵的特征值和特征向量之后,最终的聚类数目k可以通过特征值间隔启发式(eigengap heuristic)来进行选择(Von Luxburg,2007)。令λ1,…,λn表示的特征值,即式(5)中ΛS的对角元素,目标是选择k值使得特征值λ1,…,λk的值都非常小,而λk+1值相对较大,即在第k个和第k+1 个特征值之间存在间隔,|λk+1-λk|比较大,该间隔表明数据集包含k个类。
接着,在特征空间中使用K-means 方法得到分割为k类的聚类结果。在特征空间中,K-means算法的直接分割对象是前k个特征向量构成的矩阵的归一化行元素,其得到的labels 值索引与体素点一一对应,通过labels 值的索引就可以将结果映射回体素空间。同时,体素点与原始点云通过mean shift的聚类标签一一对应,可以通过标签索引将分割结果从体素空间映射回原始点云空间,最终得到单木的聚类点云。
对于得到的单木点云聚类,单木参数直接从三维点云信息中获取。在本研究中,单木位置和树高由最高点的空间坐标来确定,即(xtree,ytree,htree)=(xHighest,yHighest,zHighest)。
3.5 参数配置
在基于Nyström 的谱聚类算法中,有3 个参数对算法的单木分割效果有关键影响,即mean shift体素化方法中的核函数带宽、高斯相似度函数的宽度参数σxy和σz。
对于mean shift 体素化中的关键参数核函数带宽,由于体素化处理是要创建局部小单元(即体素),因此带宽不宜过大,以生成大量细碎的聚类结果构成体素空间。在本文算法中,核函数带宽值由Python sklearn.cluster 模块中的estimate_bandwidth 函数计算得到。其中的关键参数quantile的取值表示进行近邻搜索时的近邻占样本的比例,本文将点云密度视为平均水平下的局部近邻值的近似表示,以根据点云数据特点控制体素化尺度,在保持体素空间合理性的同时压缩后续计算数据量。由此,使用点云密度和点云数据点数的比值作为quantile 的参数值,将计算得到的带宽值带入sklearn.cluster 模块中的MeanShift 函数以实现体素化过程。这里,除带宽参数外,MeanShift 中的其他参数均采用默认值。
对于式(1)中高斯相似度函数的宽度参数σxy和σz,即水平和垂直欧氏距离的比例因子,考虑到单木的形状近似椭球,高度约为冠幅直径的6倍左右,将σz设为σxy的6 倍,以使水平和垂直距离达到同一个尺度。根据实验经验,取σxy= 3.16 m,由此得到σz取值为18.96 m。
3.6 精度评价
单木分割结果的准确性从检测率和单木参数精度两个方面进行评估。
在算法的单木检测率方面,参考Eysn等(2015)和Wang 等(2016)的思路,对每株外业实测参考单木在一定空间范围内寻找与之匹配的分割单木。整个匹配搜索过程按照实测参考单木树高递减顺序进行,对每株实测参考单木,搜索其冠幅范围内满足表2 中树高差的分割单木作为最佳匹配的候选,这里的树高差准则是参考Eysn 等(2015)的设计。
当多株分割单木满足要求成为候选时,匹配过程从近到远进行。如果更远的候选表现出更小的树高差,且其距当前实测参考的距离比较近候选的距离增量在2.5 m 之内,那么更远的候选成为更佳匹配。重复此过程,直到检查完所有实测参考单木。
图4以一对匹配单木为例,展示了上述匹配方法的过程,其中的数值表示树高。根据实测参考单木树高为20 m 及表2 的准则可得,树高差准则为ΔH<4 m。最终,高21 m的分割单木成为高20 m的实测参考单木的最佳匹配,二者树高差ΔH=1 m,距离为2.2 m。

表2 匹配方法的树高准则Table 2 Height criterion for individual tree matching
根据上述匹配方法,分割结果可被分为TP(True Positive)、FN(False Negative)和FP(False Positive)3 种,分别代表匹配、漏检和过检,且满足TP + FN = Nreference和TP + FP = Ndetection,这里,Nreference和Ndetection分别表示实测参考单木和算法分割单木的株数。提取率(Rextr)、匹配率(Rmatch)、漏检率(ROm)和过检率(RCom)可以通过式(7)—(10)计算得出。

式中,Rextr为分割株数与实测株数的比值,故其取值可能大于100%,即为存在相对较多的过检。此外,用RMSextr,RMSmatch,RMSOm和RMSCom分别表示多个样地的提取率、匹配率、漏检率和过检率的均方根,以查看算法的整体效果。对于单木参数,计算所有匹配结果的树高R2和RMSE 值,以评估参数的准确性。
4.1 基于Nyström谱聚类算法的单木分割结果
图5 展示了本文提出的基于Nyström 的谱聚类算法的分割结果示例,分别从顶视图、斜视图、侧视图展示了分割后的单木三维点云,相邻单木的点云用不同颜色渲染显示。可以看出,算法将ALS点云分割为合理的符合单木形态的结果。

图5 基于Nyström谱聚类算法的分割示例Fig.5 Examples of segmentation results using Nyström-based spectral clustering algorithm form
4.2 分割精度评价
图6 中展示了本文提出的基于Nyström 的谱聚类算法对研究区11 个样地的分割结果的提取率和匹配率,并将匹配率按不同株数密度分不同灰度显示。可以看出,本文算法对所有样地的匹配率大致随株数密度的减小而提高。从整体水平看(表3),算法提取了104%的参考单木,其中65%是正确匹配,这对于漏检和过检是一个较好的平衡。对于单木参数的提取精度,匹配结果被验证为具有较高的树高精度,R2值和RMSE 值分别为0.88和1.57 m(图7)。

图6 基于Nyström-谱聚类算法的样地单木检测率Fig.6 Detection rates for individual tree segmentation using Nyström-based spectral clustering algorithm in field plots
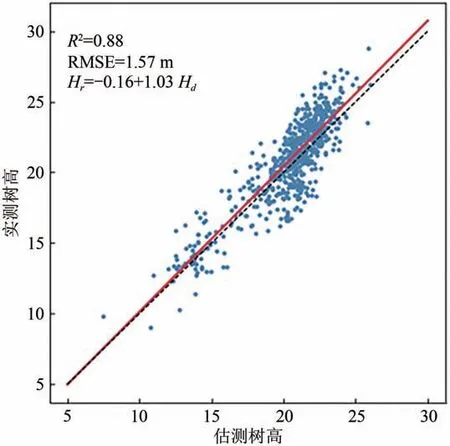
图7 匹配结果的树高精度Fig.7 Height accuracy of the matched trees
为进一步检验算法的分割性能,分别考虑对不同株数密度和树高层单木的识别情况。如表3所示,在株数密度方面,随着株数密度的增加,RMSmatch从72%降低至61%。但是,在高株数密度样地中发现了最佳提取率(RMSextr.=90%),比整体提取率低13%。低株数密度样地的过检率和漏检率都是最少的,RMSCom和RMSOm分别为30%和28%。对于中等株数密度样地而言,匹配率处于居中的水平,但是提取率和过检率均较高,RMSextr.和RMSCom分别为106%和40%。在对不同树高层的分割结果中(表5),本文的算法对20—25 m 和大于25 m 树高层的单木匹配率分别为77%和78%,对于15—20 m 和小于15 m 单木的匹配率分别为45%和51%,该结果在表5 的对比中属于较优表现。

表3 基于Nyström-谱聚类算法的分割精度Table 3 Segmentation accuracy of Nyström-based spectral clustering algorithm
4.3 不同分割算法的对比
4.3.1 分割精度对比
为进一步验证本文算法的单木分割性能,将本文提出的基于Nyström的谱聚类算法NSC(Nyströmbased Spectral Clustering)与其他算法进行对比,分别考虑K-means 算法和谱聚类算法SC(Spectral clustering)。K-means 算法作为目前ALS 点云数据单木分割问题中常用的聚类方法,与其进行对比可以验证本文算法在基于聚类方法的单木分割算法中的表现;
谱聚类算法作为本文算法的理论基础,与其进行对比可以查看本文算法对谱聚类进行一系列改进的有效性。对于算法参数设置,参考Gupta 等(2010)的工作,在K-means 算法中缩小点云高度以取得更好的结果,并通过多次实验选取最佳分割结果;
对于SC 算法,由于其与本文算法的理论相似,故参考NSC 的最优参数选择方法对其进行参数设置。
图8 展示了不同算法在研究区的11 个样地中的单木分割精度。这里,为进行比较,对K-means算法和谱聚类算法均使用本文算法选择的分割单木株数,故在同一样地内3 种算法的RMSextr.值一致。可以看出,谱聚类算法在所有样地中均取得了最高的匹配率,本文算法的表现紧随其后。同时,3 种算法对于9 号、10 号和11 号3 个低株数密度样地的单木分割结果的匹配率较为接近,但K-means算法对中高株数密度样地的单木识别精度较低。

图8 不同分割算法的单木检测率Fig.8 Detection rates for different segmentation algorithms
表4中对不同分割算法在不同株数密度样地中的分割结果进行了定量对比,其中,RMSmatch表示整体匹配率,而RMSmatch_H、RMSmatch_M、RMSmatch_L分别表示对高、中、低株数密度样地匹配率的均方根结果。谱聚类算法在所有匹配结果中均取得了最优的精度,整体匹配率为70%,且对不同株数密度的分割精度差距较小,对高、中、低株数密度样地的匹配率分别达到68%、69%和75%,表明其相对稳定的出色性能。K-means算法在整体匹配率上比谱聚类算法低7%,且分割精度随株数密度的增加与谱聚类算法的差距逐渐增大,对低、中、高株数密度样地的匹配率分别较谱聚类算法下降了5%、8%和14%。本文的算法基于谱聚类理论,通过体素化过程和Nyström 方法优化计算性能(关于计算性能的讨论可见4.3.2节),对谱聚类算法的分割精度产生了少许的损失,整体匹配率为65%,较谱聚类算法下降了5%,对高、中、低株数密度样地的匹配率分别为61%、63%和72%,较谱聚类算法分别下降了7%、6%和3%,但仍优于K-means 算法。对于单木参数,3 种方法得到的匹配树高精度大致相同,R2值均在0.88 左右,RMSE值均为1.56 m左右。

表4 不同分割算法对不同株密度样地的分割结果对比Table 4 Comparison of segmentation results by stem densities for different segmentation algorithms
表5比较了不同算法对不同树高层的单木分割结果。同样地,谱聚类算法在所有树高层中均取得了最高的匹配率,对最高两层大于25 m 和20—25 m 的匹配率分别达到83%和81%,对15—20 m和小于15 m 树高层的匹配率分别为58%和51%。K-means算法对不同树高层的匹配率均低于谱聚类算法,在最高两层的匹配率均下降5%,而最低两层则下降了10%左右。本文算法较谱聚类算法的匹配精度有少许下降,对最高两层的匹配率下降4%—5%,最低两层下降6%—7%,但仍优于K-means算法。

表5 不同分割算法对不同树高层的分割结果对比Table 5 Comparison of segmentation results by height layers for different segmentation algorithms
4.3.2 计算效率对比
除了分割精度对比,计算效率是算法性能的另一个重要衡量。图9 比较了3 种算法在研究区的11 个样地中的计算时间,算法均使用Python 3.6 编程实现,于64 位8 核3.6 GHz 主 频的Windows 操作系统下运行。为查看计算时间随点云点数增加的变化趋势,对样地按照点数由小到大排序,样地号及点数如x轴所示。
谱聚类算法虽然在分割精度上取得了最佳的结果(4.4.1 节),但是计算效率十分低下,由图9可见,当点数在30000 左右时,计算时间约为2000 s。本文的算法对11 个样地的平均计算时间为17 s,是3 种算法中计算效率最高的,其计算效率最快约提高到谱聚类算法的96 倍(11 号样地)和K-means算法的3倍(2号样地)。其中,本文算法在5 号样地的计算时间略高于K-means 算法,但整体水平仍优于K-means 算法(平均计算时间30 s)。同时,由图9 可以看出,随着点数的增加,谱聚类算法和K-means 算法的计算时间都呈较为明显的上升趋势,而本文算法的计算时间对点数增加的反应则较为平缓。可见,本文算法在计算效率上比传统谱聚类和K-means算法具有优势。

图9 不同单木分割算法的计算时间Fig.9 Computing time for different segmentation algorithms
针对现有机载LiDAR 点云单木分割方法的不足,本文提出了基于Nyström 的谱聚类算法完成单木分割,并从获取的单木聚类点云中提取关键单木因子。该算法基于谱聚类方法,同时引入了mean shift体素化和Nyström 方法,在保持谱聚类算法优越表现的同时,减小了谱聚类算法的空间和时间复杂度。对落叶松人工林数据单木分割的整体匹配率为65%,对低、中、高株数密度样地的匹配率分别达到72%、63%、61%,对20—25 m和大于25 m 树高层的单木匹配率为77%和78%。与现有方法相比,本文的算法在分割实验中整体表现良好,单木识别率与谱聚类算法差别较小,且优于K-means 算法。在算法效率方面,本文的算法对11 个样地的平均计算效率最高,最快约提高到谱聚类算法的96 倍和K-means 算法的3 倍。提取的单木树高具有较高的精度,为机载LiDAR 点云数据的单木分割提供了一个可行的方案。
本文算法的改进大大提高了谱聚类方法的计算效率,改进后的算法更适合于大规模机载LiDAR 点云数据的单木分割实验。由于谱聚类算法本身对数据分布的适应性很强,本文方法是对谱聚类算法的近似优化,理论上可适用于多种林分情况(单一或混合树种、不同株密度水平等)。考虑到本文所选研究数据为落叶松人工林数据,算法对其他林分情景的适用性还有待进一步探索。
志 谢感谢中国林业科学研究院林业研究所、东北林业大学林学院、黑龙江省孟家岗林场在外业调查方面提供的帮助。
猜你喜欢 样地株数聚类 桉树培育间伐技术与间伐效果分析世界热带农业信息(2022年8期)2022-07-19基于数据降维与聚类的车联网数据分析应用汽车实用技术(2022年4期)2022-03-07小陇山林区麻沿林场森林抚育成效监测调查种子科技(2021年8期)2021-07-11生态疏伐采伐强度控制要素探析现代农业科技(2020年11期)2020-06-21基于模糊聚类和支持向量回归的成绩预测华东师范大学学报(自然科学版)(2019年5期)2019-11-11龙粳31良种良法配套栽培技术研究农民致富之友(2017年17期)2017-09-21不同草种交播对春季冷暖季型草坪草消长的影响江苏农业科学(2017年6期)2017-05-11基于密度的自适应搜索增量聚类法电子技术与软件工程(2016年23期)2017-03-06巧解“植树问题”学苑创造·B版(2015年12期)2016-06-23样地蓄积计算误差比较分析安徽农学通报(2014年16期)2014-09-18推荐访问:分割 谱聚类 超体素约简