基于CNN的国产商用分组密码算法识别研究
来源:优秀文章 发布时间:2022-12-04 点击:
刘节威,王 钢,颜培志,方一格,荆 浩
(1.内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010051;
2.内蒙古工业大学 信息化建设与管理中心,内蒙古 呼和浩特 010051;
3.内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010051)
在商用密码应用安全性评估工作中,要求对采用商用密码技术、产品和服务集成建设的网络和信息系统密码应用的合规性与正确性进行评估[1]。分析与识别安全系统所采用的密码算法,对于评估信息系统安全性、密码使用合规性与正确性、中间人攻击等方面有着重要的现实意义。同时,密码算法识别是开展密码分析的前提条件,也是密码分析的一个重要组成部分。无论是对信息系统或网络设备中商用密码算法的应用合规性进行评估还是开展密码分析工作,对密文进行密码算法识别都是至关重要的前提。目前对密码算法的识别方向主要有两个:(1)逆向分析技术[2-4];
(b)唯密文特征识别技术。在密评工作中,由于密码算法应用合规性检测多采用逆向分析技术,存在耗时和安全性等问题,利用唯密文特征识别密码算法可以缓解上述问题的存在。同时,唯密文方法是目前主流的研究方向,也是本文所采用的方法。
由于密码轮函数、密钥长度和加密结构等加密条件的不同,明文经过不同密码算法加密而来的密文在空间分布上也会存在差异,且加密后的密文数据也并未达到真正的随机性,彼此之间尚存微小差异。因此可通过提取密文数据隐藏的特征关系作为密码算法识别的依据。虽然利用统计学的方法对古典密码算法进行识别取得了不错的成绩,但对现代密码算法识别工作却收效甚微[5]。随着机器学习在其他领域的成熟应用发展,其逐渐被研究者引入密码算法识别任务中。利用机器学习算法对唯密文开展密码算法识别可以将其视为模式识别问题,通过某种方式对密文提取特征,并对提取到的密文特征进行选择和机器学习模型训练,最终识别出其所属的密码算法。当前常见的密文特征提取方式有:(1)NIST随机性测试返回p_value特征值[6-7];
(2)特定字符、字节或比特的熵;
(3)特定字符、字节或比特的概率;
(4)将密文看成可变长的文档向量[8];
(5)以上几种特征提取方式组合[9-10]。本文采用NIST随机性测试方法提取密文特征,通过分析特征分布情况选择合适的随机性测试方法。
如今,将机器学习方式运用到密码算法识别领域的研究日渐增多。2010年,Kuncheva等人[11]对DES、IDEA、RC2、AES共4种分组密码算法进行识别,研究了8种机器学习模型在密码算法识别中的效果。2011年,Manjula等人[12]基于决策树算法,对11种加密算法进行识别,识别的密码体制包括分组密码、公钥密码、序列密码与古典密码。2012年,Chou等人[13]设计了基于支持向量机的识别模型,对ECB模式与CBC模式下的AES、DES、RC4三种分组密码算法生成的密文进行加密算法识别。2015年,吴杨等人[6]基于NIST的随机性测试方法,选取三种测试方法设计密文特征,对AES、DES、3DES、Camellia、SM4五种分组密码算法使用K-mean聚类算法进行两两聚类。2018年,黄良韬等人[9]综合已有的密码算法识别研究成果,给出了密码算法识别系统的一个形式化定义,然后对古典密码、流密码、分组密码、公钥密码四种体制,通过簇分和单分两个阶段划分识别阶段,然后基于随机森林算法进行分层识别。同年,赵志诚等人[14]结合随机性测试方法、比特熵和不定长文本向量等方法,设计密文特征,将Grain-128密码算法分别与11种其他对称密码算法进行了两两区分。2019年,赵志诚等人[7]基于NIST随机性测试标准重新设计密文特征提取方法,基于随机森林算法完成对AES、DES、3DES、IDEA、Blowfish和Camellia六种分组密码算法的两两区分实验。2021年,纪文桃等人[15]针对分组密码算法进行识别,利用三种随机测试方法对密文提取特征,训练C4.5决策树分类模型将商密SM4算法与国际主要标准分组密码算法进行两两识别。同年,曹莉茹[16]使用随机性测试方法选择密文特征,使用深度学习方法对密码算法体制进行识别,分别将BP神经网络、卷积神经网络和循环神经网络算法应用于密码算法识别任务中,确定了合适的网络参数,构建相应的密码算法识别分类器,对8种密码算法进行识别。
分组密码算法是现代密码学中的一个重要研究分支,其诞生和发展有着广泛的实用背景和重要的理论价值,同样在众多网络设备和信息系统中广泛应用,针对国产商用分组密码算法SM4开展识别研究,对密评工作也具有促进作用。目前,在密码算法识别领域很少有研究者主要针对国产商用密码进行识别研究,且研究选择识别的加密算法没有考虑密钥长度等影响识别效果的变量信息。同时,深度学习技术因其拥有处理和分析大量复杂数据的能力,在图像、自然语言处理和加密流量识别等众多领域取得显著成果,其研究对人工智能技术的发展意义重大。基于此,本文提出了一种基于自动编码器(Autoencoder,AE)和卷积神经网络(Convolutional Neural Networks,CNN)结合的分组密码算法识别方案,利用NIST随机性方法提取密文潜在的整体和局部特征,研究识别的密码算法是在尽量控制密钥长度一致的基础上选择,对商密SM4算法与AES、Camellia、DES、IDEA分组密码算法进行两两区分识别。
密码算法识别首先要提取密文特征,然后通过各类密文特征之间的差异进行分类。据此,本文首先使用NIST随机性测试方法对密文数据提取特征,然后对特征进行数据预处理生成规则的灰度图,以便后续卷积神经网络完成分类识别任务。在特征提取阶段,选择组内频率测试、最长1游程测试和二元矩阵秩测试等9种方法体现密文数据整体特征,选择非重叠模板匹配方法体现密文数据局部特征。由于局部特征维度与整体特征维度不匹配,使用自动编码器对局部特征降维,然后对整体特征和降维后的局部特征融合处理生成对应的灰度特征图,之后将它们输入到卷积神经网络模型进行训练。该方法的结构如图1所示。

图1 基于自动编码器和卷积神经网络的密码算法识别模型
2.1 特征提取
由于NIST随机性测试众多方法对序列的整体或局部随机性均有针对性的测试,针对这一特性,本文将整体和局部特征融合共同作为密文特征来突出各种加密算法密文之间的差异性。同样,选择合适的随机性测试方法反映密文整体特征也是至关重要的。通过对各类加密算法的密文文件进行特征分布统计分析,选择了9种随机性测试方法反映密文整体特征,分别是频率测试(Frequency test)、组内频率测试(Frequency test within a block)、游程测试(Runs test)、最长1游程测试(Longest run of ones test)、二元矩阵秩测试(Binary matrix rank test)、离散傅里叶变换测试(Discrete Fourier transform test)、序列测试(Serial test)、近似熵测试(Approximate entropy test)、累加和测试(Cumulative sums test)。而反映密文局部特征的方法选择的则是非重叠模块匹配测试(Non overlapping template matching test)。
在待提取特征的密文文件统一大小的基础上,将密文文件分割为数份固定大小的二进制密文块,分别基于上述10种随机性测试方法提取密文特征。密码算法集合为M={m1,m2,m3,…,mk},其中k代表密码算法的数量。每种密码算法mi分别加密明文文件F得到密文文件C,每个密文文件Ci分割为一定数量等长的密文块Cij。每个密文块Cij基于反映密文文件整体特征的9种随机性方法提取特征,可得特征向量Afeaij={Afeaij_1,Afeaij_2,…,Afeaij_d};
基于反映密文局部特征的非重叠模块匹配测试方法提取特征,可得特征向量Bfeaij={Bfeaij_1,Bfeaij_2,…,Bfeaij_q}。在对特征向量Afeaij和Bfeaij融合之前,首先需要对Bfeaij进行数据降维处理。
2.2 自动编码器数据降维
自动编码器[17]是一种无监督机器学习算法,其基本思想是直接使用一层或者多层的神经网络对输入数据进行关系映射,得到输出向量作为从输入数据中提取的特征。自动编码器广泛用于数据降维[18]和特征学习[19],与主成分分析(PCA)算法相比,自动编码器具有更好的灵活性和处理非线性特征的能力。图2所示为三层自动编码器模型,从图中可以看出自动编码器分为三部分:输入层、隐藏层和输出层。其中输入层向隐藏层的低维映射被称为编码器,得到输入数据的高效表征;
从隐藏层到输出层的高维映射被称为解码器,对输入数据进行重构。一般情况下隐藏层的维度比输入层的维度要小,由于隐藏层抽取了输入层的有效信息,因此自动编码器可用于数据降维[20]。由于2.1节中特征向量Bfeaij维度过高且Afeaij维度过低,如果未经过任何降维处理直接融合特征向量,就会造成两个特征向量维度不匹配的问题。在分类模型训练过程中,高维度特征向量会压制低维度向量,导致训练效果不理想。

图2 三层自动编码器模型
为了将密文整体和局部特征更高效地融合,使用自动编码器对特征向量Bfeaij降维。以处理16 KB密文块为例,自动编码器模型包括1个输入层、4个线性隐藏层+激活层、1个输出层,如图3所示。
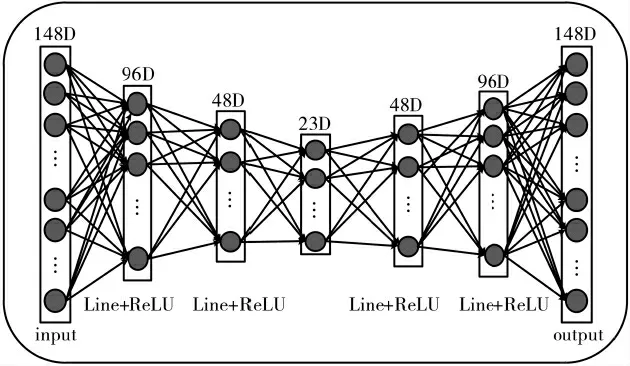
图3 自动编码器模型
2.3 卷积神经网络模型
卷积神经网络[21]由于善于提取数据局部特征和下采样特性,相比其他机器学习模型更适合处理特征维度较高和具有空间特征的数据,如图像、文本和本文中使用的密文数据空间特征。不同结构的加密算法生成的密文文件在空间分布上存在信息差异性,这种空间信息差异性很难用传统机器学习算法分析,故本文使用卷积神经网络对密码算法展开识别研究。卷积神经网络识别模型如图4所示,以16 KB密文块为例,包括一个输入层、三个卷积+最大池化连接层、两个全连接层以及一个输出层,其中输入层为预处理过之后的灰度特征图。

图4 卷积神经网络识别模型
基于卷积神经网络模型的识别方案,具体流程如下:
(1)训练阶段
①随机抽取密码算法已知的一组密文文件C1,C2,…,Cs,其中s为文件个数;
②对每个密文文件Ci按固定大小分割为二进制密文块Ci1,Ci2,…,Cit,其中t为密文块个数;
③对密文块Cij数据内容进行特征提取,得到两组特征向量Afeaij和Bfeaij,对Bfeaij特征降维,然后融合特征向量Afeaij和Bfeaij得到feaij={feaij-1,feaij-2,…,feaij-d},其中d为特征维数,其维数由具体选择的采集方式确定;
④每个密文文件组成一个大小为t×d的特征矩阵,转换为灰度特征图;
⑤s个密文文件则构成s个灰度特征图且特征标签已知为Lab={lab1,lab2,…,labs},每个密文文件构成二元组(feai,labi);
⑥将带标签的数据(feai,labi)提交到神经网络分类算法,进行分类模型的训练。
(2)测试阶段
①从网络设备或信息系统中获取密文文件。对一个待识别的密文文件C按固定大小分割为二进制密文块,对每个密文块进行特征提取和特征降维,拼接每个密文块的特征向量feai,得到一个二维矩阵并转换为灰度特征图。
②将灰度特征图输入到在训练阶段训练好的分类器模型中,模型给出密码算法识别结果,即密码算法标签lab。
本文实验使用OpenSSL和GmSSL密码库工具中实现的SM4、AES、Camellia、DES和IDEA密码算法加密明文文件,使用NIST随机性测试工具包提取密文特征,以PyTorch深度学习框架和PyCharm软件为模型训练环境,实验测试环境如表1所示。
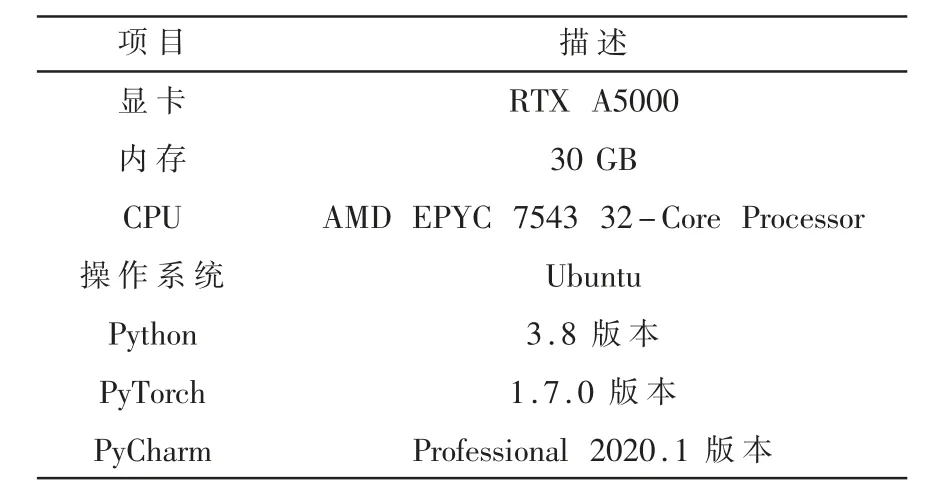
表1 实验测试环境
明文数据来源于网上爬取的图片,将所有图片拼接成大小为1 024 MB的明文文件,再将其平均分割为2 000份小文件,每份大小均为512 KB。设置对应的固定密钥和分组密码ECB工作模式,每份小文件经过不同密码算法加密后获得对应的密文文件共计10 000份。对实验数据灰度特征图进行随机抽样训练,随机抽样70%作为训练集,其余30%作为测试集,以10折重复随机抽样数据集的平均准确率作为识别效果的度量值。后续模型训练阶段和测试阶段都是在此基础上完成。有关各类密码算法的设置情况和实现方式如表2所示。

表2 5种加密算法的具体参数列表
10种随机性测试方法的参数设置对返回值p_value的大小和数量均有影响。表3为实验所用随机性测试方法的参数设置情况[22],未说明实验取参均使用NIST随机性测试包默认设置。

表3 10种随机性测试参数范围列表
为了验证密文块大小对实验效果是否有影响,本文采用两种密文分块方案,分别将密文文件划分为32块和128块,则密文文件大小为16 KB和4 KB。对每种分块方案的密文块分别记为和,密文文件提取特征生成32×32维和128×128维的特征灰度图。图5和图6所示分别为基于某种加密算法的和密文块方案的特征灰度图。

图5 C3ij2密文块方案特征灰度图

图6 C1ij28密文块方案特征灰度图
完成以上工作,将得到的特征灰度图输入到卷积神经网络模型中训练分类。首先将商密SM4算法 与AES、Camellia、DES、IDEA算 法 之 间 两 两 区 分识别,其准确率都在80%以上,如表4所示。
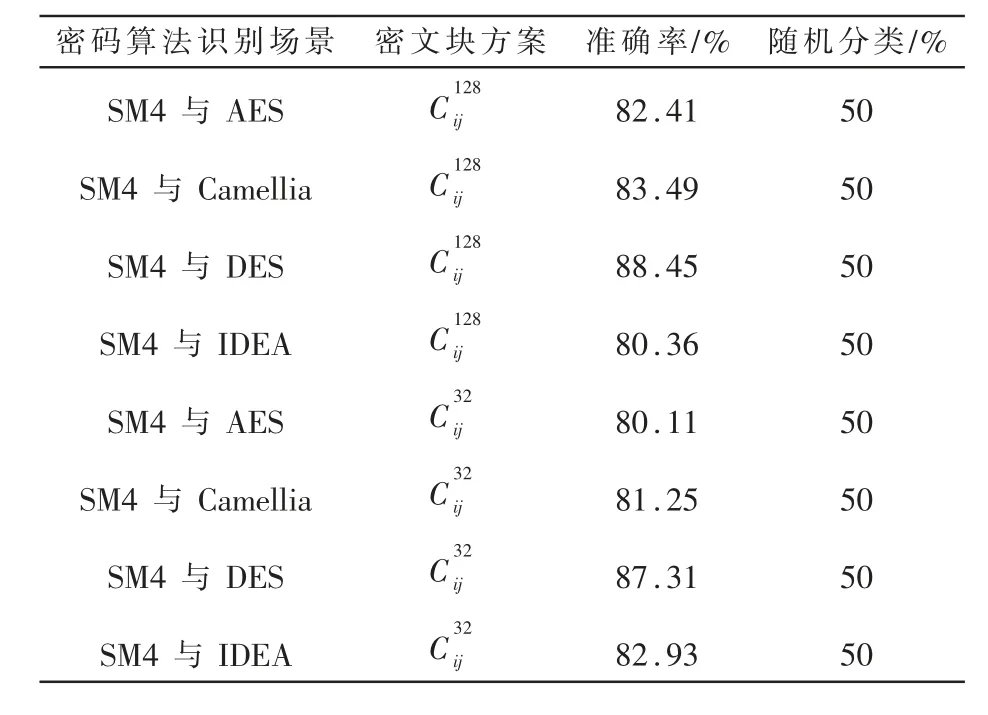
表4 SM4与4种分组密码算法识别准确率

表5 DES与4种分组密码算法识别准确率
DES算法与其他算法识别准确率均在85%以上,具有较高的识别准确率,这说明密钥长度不同确实会影响密码算法之间识别的效果。研究识别的密码算法在密钥长度一致的基础上,与其他相关文献相比,本文提出的基于自动编码器和卷积神经网络的密码算法识别方案取得了不错的准确率和稳定性,对比结果如表6所示。

表6 分组密码算法识别方案对比
本文利用NIST随机性方法对密文文件提取整体和局部特征,使用自动编码器对数据降维,提出一种基于自动编码器和卷积神经网络模型的分组密码算法识别方案。所选密码算法在控制密钥长度这一变量的基础上开展研究,实验结果表明,密钥长度不同的两种分组密码算法,识别准确率相对较高,说明算法密钥长度不同对识别结果的准确率确实有影响。同时,SM4与其他算法两两识别的准确率可达80%之上,DES与其他算法两两识别的准确率可达85%之上。本文主要针对分组密码ECB工作模式进行识别研究,在后续的工作中,将尝试对CBC、CFB等复杂工作模式开展研究,对多种不同密钥长度的密码算法进行识别,优化密文特征选择和特征处理过程。同时,对国产商用序列密码体制和公钥密码体制识别展开研究。
猜你喜欢 密文随机性编码器 基于ResNet18特征编码器的水稻病虫害图像描述生成农业工程学报(2022年12期)2022-09-09一种新的密文策略的属性基加密方案研究无线互联科技(2019年13期)2019-10-17密码分类和攻击类型计算机与网络(2019年13期)2019-09-10一种抗攻击的网络加密算法研究现代电子技术(2018年20期)2018-10-24认真打造小学数学的优美课堂魅力中国(2017年6期)2017-05-13基于TMS320F28335的绝对式光电编码器驱动设计科技与创新(2017年5期)2017-03-28浅析电网规划中的模糊可靠性评估方法中国科技纵横(2016年20期)2016-12-28条件型非对称跨加密系统的代理重加密方案计算机应用(2016年9期)2016-11-01对“德育内容”渗透“随机性”的思考体育教学(2014年9期)2015-01-30具备DV解码功能的DVD编码器——数字视频刻录应用的理想选择电子设计应用(2004年6期)2004-07-27推荐访问:分组 算法 识别