基于TD3-PER的混合动力履带车辆能量管理*
来源:优秀文章 发布时间:2022-11-11 点击:
张 彬,邹 渊,张旭东,杜国栋,孙文景,孙 巍
(北京理工大学机械与车辆学院,北京100081)
混合动力电动履带车辆(HETV)具有结构简单、可靠性高、布置灵活等优点。混合动力方案兼具了燃油车和纯电动车的优点,通过合适的能量管理策略(EMS)能使发动机工作在较经济的状态,提高车辆的燃油经济性和续航里程。对于油电混合系统,EMS根据不同部件的状态反馈,实现不同动力源的功率分配,达到提高燃油经济性、减少排放等目的。由于各动力源的特性差异,各动力源之间的功率分配也不同。因此,EMS是最大化混合动力系统燃油经济性、充分发挥混合动力系统的综合性能的关键技术之一。
EMS的主要目的是合理地分配发动机和动力电池的输出功率,提高车辆的燃油经济性和续航里程。近年来出现的EMS主要分为基于规则的策略和基于优化的策略两大类。基于规则的策略具有良好的实时性和可靠性,在工程实践中得到广泛的应用,但其对不同工况和车型的可移植性较差,且很难取得最优的控制效果。目前大部分EMS的研究集中在基于优化的策略。基于优化的策略旨在建立系统目标函数和约束条件后,通过优化使目标成本最小化。但基于优化的策略计算量大,须提前知道整个工况,对不同车型、不同运行工况的移植性差。但它可得到理论最优或近似最优解,常被作为参考基准用于评估或改进其他能量管理策略,如动态规划(DP)算法等。
混合动力系统是典型的非线性多场耦合的复杂系统,需要更加精细和智能的算法来构建EMS。强化学习(RL)算法在处理非线性、强耦合、高复杂度问题时更有优势,最近多用于解决能量管理问题。Liu等在混合动力履带车辆上采用基于Q-learning和Dyna的能量管理策略,此策略对发动机燃油经济性有一定的提高。但RL算法存在由离散化引起的“维数灾害”,会导致训练时间的大幅增加且难以收敛。为解决此问题,Zhao等采用基于深度强化学习(DRL)的能量管理策略,并将基于DRL算法的策略应用到混合动力公交车上,燃油经济性相对于Q学习算法提高了10%,训练时间也大幅缩短。虽然基于DRL的策略在状态空间是连续的,但其控制量仍需降维和离散处理,导致了控制精度的降低。同时由于最大化值函数逼近,DRL算法存在动作值过优估计的问题,这可能会导致不稳定或效果不佳的现象。为解决过优估计问题,Han等应用基于双深度强化学习(DDQL)的EMS到混合动力履带车上,与DQL算法相比燃油经济性提高了7.1%。为解决控制量离散问题,Zhang等提出基于深度确定性策略梯度(DDPG)的EMS,仿真结果表明该策略能实现更细化的油门开度控制,进一步提高燃油经济性。但同DQL一样,DDPG也存在动作值过优估计的问题,可能导致训练不稳定。
为解决上述算法存在的问题,进一步提高车辆的燃油经济性、获得更好的电池SOC保持效果,提出基于优先经验采样的双延迟深度确定性策略梯度(TD3-PER)的能量管理策略,将其应用于串联式混合动力履带车辆。基于双延迟深度确定性策略梯度(TD3)的策略能实现状态空间和动作空间的连续控制,同时解决了动作值过优估计的问题。为加快策略的收敛速度和达到更高的燃油经济性,采用优先经验采样算法(PER)来加速网络训练。
1.1 车辆配置参数
图1为课题组自研的串联式混合动力电动履带车辆(SHETV)。该车辆采用模块化和动力履带设计,将组件全布置于两边的履带舱内,为中间平台省出更多的承载空间。图2为动力系统拓扑图,主要包括发动机-发电机组、电池、功率分配单元、驱动电机总成和整车控制单元(VCU)。驱动电机的额定功率是25 kW,转速范围为2 000~2 500 r/min。发电机组通过AC/DC整流单元向直流母线提供电能,而电池组直接向母线提供电能。母线电压为两个驱动电机提供电能,用于驱动主动轮旋转。VCU负责整车的控制策略、能量管理策略和功率匹配,是提高燃油经济性的核心。表1为整车及其主要部件的参数。

表1 串联式混合动力履带车辆主要参数

图1 串联式混合动力电动履带车辆
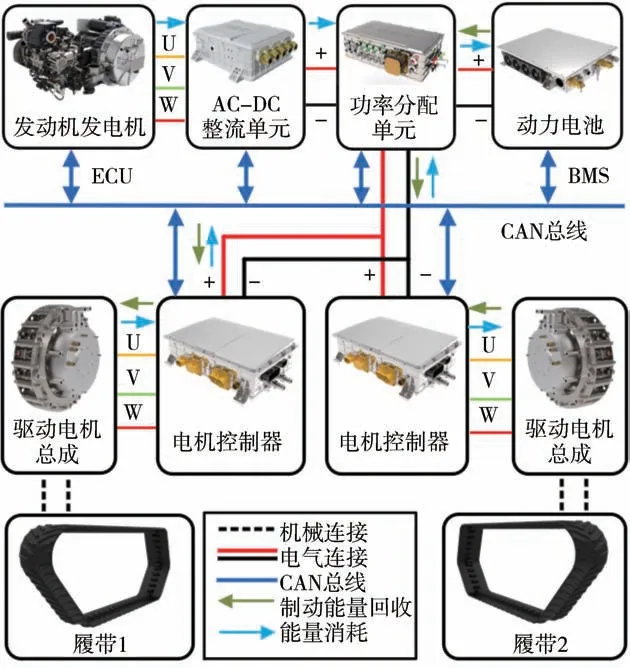
图2 串联式混合动力系统拓扑图
1.2 车辆动力学模型和传动系统模型
履带车辆的动力学模型如图3所示,图中为横摆角速度,为履带车辆轨距。

图3 履带车辆动力学模型
车辆的受力主要包括滚动阻力与、驱动力与、加速阻力、空气阻力、坡度阻力和转向阻力矩。和分别为左、右侧履带的速度。履带车辆的动力学方程为

式中:为履带车辆的需求功率;
为纵向驱动力;
为车辆的平均速度,=(+)/2。
、、、和的计算公式为
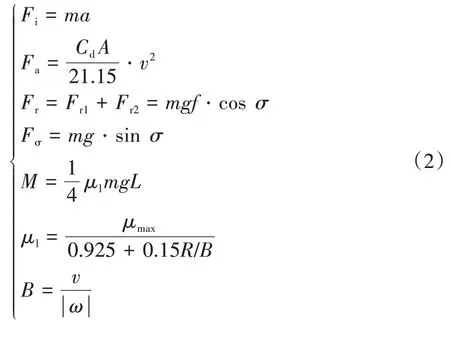
式中:为车辆加速度;
为转向半径;
为车辆受到的总滚动阻力;
σ为道路坡度角;
为车辆做半径≥/2转向时的转向阻力系数;
为车辆做半径为/2转向时的转向阻力系数;
车辆做半径为0-/2转向时转向阻力系数。
根据功率平衡关系,直流母线需求功率和动力源输出功率满足:

式中:和分别为发电机功率和电池组功率;
为直流母线电压;
为发电机电流;
为电池电流;
和分别为电池的开路电压和内阻;
和分别为发电机等效电动势系数和等效阻抗系数;
为发电机转速。
关于履带车辆传动系统中的发动机-发电机组模型、动力电池模型和驱动电机模型在以往的成果中已有详细的介绍,请详见文献[17],在此不再赘述。
在Simulink中搭建车辆动力学仿真模型和传动系统模型,如图4所示。将实车采集的数据作为SHETV前向模型的目标工况进行仿真,仿真数据和实车数据的对比结果如图5所示。从图5(a)可知,车辆的仿真模型可很好地跟随实测速度。由于实测环境存在噪声等诸多影响,发动机转速、电池SOC、母线电压仿真数据与实测数据有一点偏差,但总体变化趋势很好地吻合。说明所建立的模型能反映实车的基本物理特性。此外,EMS的开发主要关注需求功率的分配,允许模型有一定的偏差,因此建立的仿真模型可作为后续策略开发的验证模型。

图4 车辆Simulink模型

图5 仿真数据与实车数据的对比曲线
1.3 能量管理问题
对所研究的SHETV,EMS的首要目标是找到最优策略*在满足系统性能要求和保持电池波动不大的情况下最小化燃油消耗。因此成本函数定义为燃油消耗和电池变化的组合:


系统约束条件为

式中:和分别为发动机最低和最高转速;
为发动机最大转矩;
为发电机最大放电电流;
和分别为电池最小功率和最大功率;
和分别为电池最大充电和放电电流;
为电子油门开度系数。
图6为基于深度强化学习(DRL)的EMS理论框架。TD3算法是基于Actor-Critic框架的DRL算法,图7为基于TD3-PER的EMS具体框架。选取车速、发电机转速、电池荷电状态和车辆当前时刻的需求功率作为状态矢量,即s=[,,,]。为提高算法训练时的收敛速度,对、和进行归一化处理。履带车辆为EMS中的环境,智能体根据车辆的状态s和智能体中的策略在每步选择一个动作a作用于车辆,车辆反馈即时奖励r和下一刻状态s。经验池(replay buffer)存储当前的状态、动作、即时奖励、下一刻状态矢量(s,a,r,s),形成历史经验数据;
通过优先经验采样方式从经验池中抽取历史数据送入智能体中的网络进行训练。智能体通过与环境的不断交互来调整网络权重得到最优策略,即燃油消耗最低且具有保持能力。经验池的使用有效消除了相邻状态间的相关性,同时优先经验采样(PER)算法的引入加速了网络的收敛并提高了训练的效果。
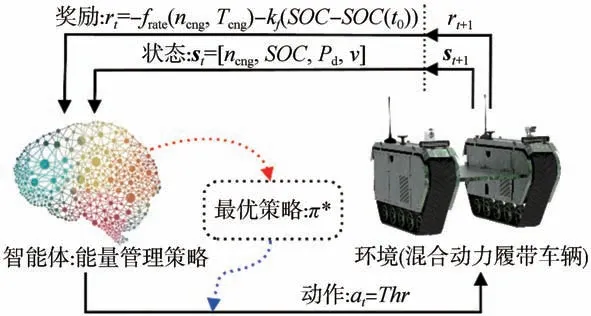
图6 基于深度强化学习算法理论框架

图7 基于TD3-PER的能量管理策略框架
TD3算法包含策略网络Actor和评判网络Critic。其中Actor网络以车辆的状态作为输入并根据网络参数输出控制动作,Critic网络用于评判Actor网络执行动作的优劣。TD3算法能同时处理连续动作空间和策略值函数过优估计的问题。EMS的控制变量为发动机电子油门开度,因此TD3算法的控制动作为[0,1]的连续值。具体来说,TD3算法是在DDPG的基础上,同时对Actor网络和Critic网络进行优化,主要包括:(1)Critic网络包含Critic1和Critic2两个独立网络,通过选取两个网络中最小的值作为目标值,解决了DDPG中对值持续过优估计的问题,如式(6)所示;
(2)算法采用两个随机噪声,其中在线策略网络的随机噪声用来保证动作的探索能力,而目标策略网络中加入随机噪声,则用来增加算法的稳定性;
(3)降低了在线策略网络的更新频率,使得actor的训练更加稳定。
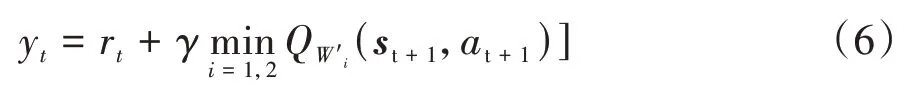
式中:r为时刻的即时奖励;
为折扣因子;
Q(s,a)为根据+1时刻的状态值s、动作值a和网络参数"得到的目标网络的值。
目标函数为

在线网络参数的更新方式为梯度下降法。Critic网络采用时序差分误差(TD-error)的均方差来评价近似的准确性。Critic网络的权重参数、通过梯度下降法最小化损失函数()来更新,如式(8)和式(9)所示。在线Actor网络参数的更新通过梯度上升法使值关于迭代增加:


目标网络的权重参数更新采用滑动平均的软更新方式,如式(11)所示,将在线网络中的参数以一定的权重更新到目标网络中:

式中:为软更新参数;
为在线策略网络参数;
"为目标策略网络参数;
和分别为在线网络1和在线网络2的网络参数;
"和"分别为目标网络1和目标网络2的网络参数。
在传统的DRL算法中,从经验池中抽取片段时是以等概率随机抽取。事实上经验池中片段的难易程度和从中学习到的知识都不同。为加速网络训练且得到更好的训练效果,本文中采用了优先经验采样(PER)算法,并结合不同的经验给予一定的权重,例如在交互过程中表现越差的片段给予更高的权重,则这些片段有更高的概率被网络重新学习,这样模型的学习效率就会大大提高。相反,在交互过程中表现较好的片段给予较低的采样权重。
TD-error的值越大,片段越有价值。因此,用TD-error的绝对值来表征片段的重要性。TD-error的值σ为

式中为折扣因子。
经验片段的优先级有两种形式:(1)直接用TDerror的绝对值|σ|来表征,如式(13)所示,为较小的正常数,用于保证在边缘概率为0的片段也有一定的概率被采样;
(2)根据|σ|的大小对经验样本进行排序,然后得到样本的序列(),如式(14)所示的优先级指标D。第2种形式具有更好的鲁棒性,本文中采用第2种形式。


直接采用式(14)的采样方式为贪婪抽样,会导致初始TD-error较小时长时间不被抽样和TD-error较大时被高频重复抽样,从而导致缺乏样本多样性。为解决此问题,采用均匀采样和贪婪抽样结合的方式,经验池中每个样本的采样概率()为
式中:D为第个样本的优先级指标;
为超参数。当为0时为均匀抽样;
当为1时为贪婪抽样;
当0<<1时为两种采样的结合。
PER的另一问题是对模型的更新会引入偏差。为使模型更新无偏,引入更新权重:

式中:为经验池大小;
为介于0至1之间的调节因子,较小时样本利用率高,较大时更新偏向于无偏。
基于TD3-PER的能量管理策略的流程和有关的伪代码如表2所示。

表2 TD3-PER算法计算流程
3.1 TD3-PER算法模型训练
采用SHETV实车采集的信息作为训练用的循环工况,其速度变化曲线和对应的需求功率如图8所示,工况的总时间为1 000 s,训练时采样频率为10 Hz。最大车速为39.5 km/h,车辆的需求功率范围为-1.06~15.49 kW。需求功率的负值为混合动力驱动系统的制动能量再生能源。

图8 TD3-PER算法训练工况
状态矢量的初始向量为=[2000,0.75,0,0],将其作为TD3-PER算法的初始向量输入网络中进行训练。TD3-PER算法网络的超参数如表3所示。图9为在训练过程中的回报函数曲线、损失函数曲线和每一回合的油耗值曲线。从图中可以看出,随着训练进程的进行,回报函数不断增大且油耗值不断减小,在训练的第23个回合左右,算法的回报函数曲线和损失函数曲线都趋近于0,这表明算法的训练已经收敛,相应的控制策略即将达到最优值附近。

表3 TD3-PER算法网络超参数定义

图9 训练过程的总回报、损失函数和燃油消耗量
3.2 控制性能对比验证
为验证TD3-PER算法的性能,将相同的行驶工况分别作为DP、DDPG、TD3、TD3-PER 4种算法的训练工况,通过神经网络训练后对比其性能,其中基于全局优化算法DP的EMS作为其他3种算法的对比基准。图10为3种算法的动力电池变化曲线。从图中可以看出,3种算法的变化趋势具有相似性且变化都不大,这是由于TD3算法为DDPG算法的改进算法,都能实现油门开度的连续控制。但是基于TD3-PER算法的波动更小,在初始值0.75附近波动。这是由于TD3算法作为DDPG的改进算法,能实现值更稳定的迭代,因此能使在初始值附近更小的波动。同时PER算法的加入使TD3算法的训练过程更快,控制效果更好。

图10 3种算法的SOC曲线对比
图11为基于3种算法的EMS的发动机工作点分布图。3种算法的发动机工作点具有一定的相似性,这是由于基于3种算法的EMS在状态空间都是连续的且都能实现油门开度的连续控制。但TD3算法的发动机工作点相对于DDPG更多地位于燃油消耗较低的高效区,同时PER算法的加入使得TD3算法的燃油经济性进一步提升。

图11 发动机工作点分布对比
由于发动机工作点分布和的终端值不同,4种算法的仿真油耗也存在差异。为消除算法在终端状态下的差异,采用修正方法对燃油消耗进行补偿。表4是经修正后的燃油消耗量对比。在所给定的真实循环工况下,DP、DDPG、TD3和TD3-PER算法分别消耗燃油499.02、546.24、532.21和525.01 g,TD3-PER算法的燃油消耗比DDPG降低了3.89%,燃油经济性达到DP基准的95.05%。同时,相对于离散算法DP,连续型算法的训练时间也大大缩短。以上仿真结果表明TD3-PER算法具有更好的优化控制效果,验证了基于TD3-PER算法的能量管理策略的最优性和有效性。

表4 3种算法SOC修正后的燃油消耗量
3.3 基于TD3-PER算法的EMS的适应性验证
为验证所提出的能量管理策略的适应性和优化性能,在训练好的TD3-PER网络参数中采用实车采集的新工况进行仿真对比。新工况信息如图12所示,工况的最高车速为26 km/h,最大需求功率为14.56 kW,最小功率为-4.21 kW。

图12 算法适应性和最优性验证工况
将新的工况输入到DDPG、TD3、TD3-NAF算法中进行仿真验证,结果如图13和图14所示。从图13可见,3种算法都能实现较好的保持能力,但TD3-PER算法的波动性更小。从图14可见,3种对比算法的发动机工作点分布类似,但相对于DDPG算法,TD3算法和TD3-PER算法使更多的发动机工作点分布在经济区。

图13 3种算法的SOC曲线

图14 发动机工作点分布
采用与3.2节中同样的方法修正油耗来消除终端值不同带来的影响,结果如表5所示。由表可见,TD3-PER修正后的油耗为417.53 g,与TD3算法相比下降了15.7 g,与DDPG算法相比下降了34.11 g。仿真结果表明了TD3-PER算法具有更好的节油效果,同时也验证了基于TD3-PER算法对工况的适应能力。

表5 3种算法对于新工况的燃油消耗量
为优化混合动力电动履带车辆的燃油经济性和动力电池性能,提出了一种基于优先经验采样的双延迟深度确定性策略梯度(TD3-PER)能量管理策略。TD3算法采用双Critic网络解决了DDPG算法过优估计问题,PER算法提高了算法的收敛速度和训练效果。因此,TD3-PER算法解决了能量管理策略无法处理连续控制和过优估计的问题,同时加速了神经网络的训练。具体结论如下:
(1)将提出的基于TD3-PER的能量管理策略应用于串联式混合动力履带车辆中,通过实车采集的工况仿真对比了TD3-PER、TD3和DDPG算法的燃油经济性和电池的波动。基于TD3-PER算法的EMS的燃油经济性比TD3提高了1.29%、比DDPG提高了3.87%,若以DP算法为基准,可达到95.05%。
(2)通过实车采集的新工况验证了训练好的网络数据的燃油经济性,TD3-PER算法修正后的油耗比TD3下降了15.7 g,比DDPG下降了34.11 g,同时验证了算法对于工况的适应性。
为了使TD3-PER算法能更好地适应复杂越野工况,下一步工作将开展在线更新网络参数的研究,进一步提高算法对于工况的适应性和燃油经济性。
猜你喜欢 履带经济性工况 基于MCTS-HM的重型汽车多参数运行工况高效构建方法汽车工程学报(2022年5期)2022-10-12燃气机热泵与电驱动热泵技术经济性实测对比煤气与热力(2022年4期)2022-05-23热网异常工况的辨识煤气与热力(2022年4期)2022-05-23居住建筑中装配式钢结构的应用经济性分析锦绣·上旬刊(2022年2期)2022-05-16移动排涝抢险用水陆两栖履带车设计专用汽车(2022年2期)2022-04-05论工况环境温度对风压传感器精度的影响科学与财富(2021年33期)2021-05-10西安市公交线路模态行驶工况构建汽车实用技术(2020年10期)2020-06-11含风电的电力系统调度的经济性分析智富时代(2018年5期)2018-07-18含风电的电力系统调度的经济性分析智富时代(2018年5期)2018-07-18工程车创新作文(1-2年级)(2017年11期)2018-04-17推荐访问:履带 混合动力 能量