基于多粒度与自修复融合的人脸表情识别
来源:优秀文章 发布时间:2023-04-15 点击:
王俊峰,木特力甫·马木提,阿力木江·艾沙,3,努尔毕亚·亚地卡尔,3,库尔班·吾布力,3+
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;
2.新疆大学 图书馆,新疆 乌鲁木齐 830046;
3.新疆大学 新疆多语种信息技术重点实验室,新疆 乌鲁木齐 830046)
随着硬件计算能力的迅速提升和优秀深度学习模型的加持,卷积神经网络在目标分类任务上取得了很多非常好的成果,在人脸表情识别中应用深度学习方法也已成为研究者的主要选择。然而关于表情局部特征和粒度的关系、哪种粒度最具有区别性以及如何在多粒度之间融合表情特征信息研究者投入较少的精力,此外自然场景下人脸表情数据集一般存在错误样本标签、不确定性和背景复杂等问题。为了降低这些因素的影响,本文基于深度卷积神经网络提出多粒度与自修复融合的人脸表情识别模型,模型首先采用拼图生成器生成不同粒度的表情图像,其次利用渐进式的训练过程在不同训练阶段学习不同粒度图像之间互补的特征信息,并通过自修复方法避免网络模型过度拟合错误样本图像,有效缓解这些消极因素的影响。
关于人脸表情识别的研究可以追溯到上世纪七十年代,相关研究从最初使用少量小型的表情数据集和一些传统图像特征提取算法转变为当前使用海量大型的表情数据集和机器学习、深度学习方法,大型数据集和优秀的深度学习算法极大地推动了人脸表情识别的发展。
Ding等[1]提出一种双局部二值模式(double local binary pattern,DLBP)来检测视频中的峰值表情帧,并基于LBP和Taylor展开的Taylor特征模式(TFP),从Taylor特征图中提取有效的人脸特征,方法优于单独使用LBP的效果,且具有实时的特点。侯小红等[2]提出结合Harris-SIFT特征点检测和LBP纹理特征的表情识别方法,采用Harris过滤SIFT提取特征点来获取更加有效的人脸表情特征。Rahul等[3]提出一种结合Gabor特征和改进的隐马尔可夫模型(hidden markov model,HMM)表情识别方法,该方法首先使用Gabor方法提取面部表情丰富区域的表情特征,如:鼻子、嘴巴、眉毛和眼睛等,其次采用主成分分析法(principal component analysis,PCA)进行降维,最后使用两层的HMM进行测试,该方法具有效率高和鲁棒性强的优势。Zhao等[4]提出一种基于三维卷积神经网络(3D convolutional neural network,3DCNN)的模型,利用3DCNN提取图像序列中静态和动态特征,并且从光流序列中提取动态特征,使用不同图像对的构造方法,获取面部肌肉运动密集光流:普通光流和累积光流,使用累积光流能够获取更多的面部运动信息。
随着GPU硬件计算能力的快速提升与深度学习方法的出现,优秀的深度学习模型近年来在国内外受到众多研究者的青睐,研究者在人脸表情识别方向引入新的深度学习模型,推动人脸表情识别取得长足进步。与传统人脸表情识别方法相比,深度学习方法在大批量数据处理方面和优秀的拟合能力上有着无可比拟的优势,然而深度学习也存在一些不足之处,如:训练和调参过程繁琐、模型过拟合等问题。
利用注意力机制有效提取表情关键区域特征也是表情识别的一个重要研究方向。Xie等[5]提出具有显著表情区域注意力的深度多路径卷积神经网络(DAM-CNN)模型,模型利用基于注意力的显著表情区域描述符(SERD)自适应地估计不同图像区域对于人脸表情识别任务的重要性,并使用多路径抑制网络(MPVS-Net)区分与表情无关的信息。基于卷积神经网络的HoloNet模型[6]通过使用CReLU代替ReLU,减少了冗余信息并增强低卷积层中的非饱和性和非线性,将残差结构和CReLU激活函数结合构造中间层,增加网络深度获得更高的准确率和效率。Kurup等[7]提出一种缩减特征的半监督情感识别算法和新的特征选择方法,首先提取面部图像特征,并将特征进行缩减,然后将具有可用标记和未标记数据的半监督训练应用于深度信念网络(deep belief network,DBN),最后在选择特征时去除不提供信息的特征。Zhang等[8]提出了基于生成对抗网络(generative adversarial network,GAN)的端到端表情识别模型,能够扩充人脸表情数据集样本数,模型验证GAN方法在生成人脸表情上具有良好的性能,对扩大数据集规模有积极作用。
目前应用深度学习的人脸表情识别方法性能表现十分突出,但是很多方法存在着一些局限性,而且一些表情数据集存在错误标注、复杂背景和模糊等问题,致使准确率难以满足现实需求。为了进一步提升人脸表情识别的效果,本文基于深度卷积神经网络提出多粒度与自修复融合的人脸表情识别方法。具体来说,首先使用拼图生成器生成不同粒度的图像,利用渐进式的训练过程学习不同粒度图像之间相互补充的表情特征信息,利用自修复方法避免网络过度拟合错误样本图像,对错误样本进行严格的重新标注。实验结果表明方法具有有效性,在AffectNet数据集和RAF-DB数据集上进行验证,取得了竞争性的识别结果。
2.1 多粒度图像生成
研究者发现拼图游戏可以应用于表征学习的自我监督任务中,根据这一想法,使用拼图生成方法生成不同粒度的合成图像,将拼图图像输入到网络模型不同的训练阶段,迫使模型学习到多粒度级别的表情图像特征信息。具体而言,首先将要训练的大小为3×W×H表情图像平均划分为N×N个图像块,划分好的图像块大小为3×(W/N)×(H/N), 将划分的图像块随机打乱顺序,然后再重新组合成为3×W×H原始大小图像,以N值为8,4,2,1大小粒度拼图生成图像为例,使用拼图生成方法生成的多粒度图像如图1所示。

图1 多粒度图像生成
2.2 渐进式训练
使用拼图生成图像训练模型,目的是为了学习不同粒度图像的互补特征[9]。在训练时,采用渐进式训练策略进行训练。具体来说,首先训练网络低层,然后依次添加网络层进行训练。由于网络低层的感受野和表征能力是有限的,通过渐进式训练使模型在网络低层从局部区域学习到区别性的表情特征信息。与训练整个网络相比,这种训练策略在网络浅层提取特征图后,逐步输入网络深层,可以从局部细节信息学习到全局的区别特征信息。
在每个训练阶段完成后计算交叉熵损失(cross entropy loss),对每个阶段的交叉熵损失求和作为总的损失值。因此在每个训练阶段对所有参数进行了优化,有助于模型中的每个训练阶段起到协同的作用
(1)

由于获得的多粒度信息可能会倾向于相似区域,直接使用渐进式训练不利于表情特征的提取,因此通过引入拼图生成方法在每个训练阶段提取不同粒度级别的图像特征信息来缓解这个问题。
2.3 自修复方法
模型在最后训练阶段使用自修复方法来抑制表情数据的不确定性,避免模型过度拟合不确定的表情图像[10]。具体而言,将不同粒度图片逐渐训练提取特征信息后,使用原图训练时批次输入的表情图像经过主干网络提取得到[B,3072]特征向量,其中B为批处理样本数BatchSize,使用注意力机制得到图像注意力得分,对注意力得分依次从高到低排序、高低分组和正则化加权,使高重要性组的平均分值高于低重要性组平均分值,同时将主干网络提取的特征经Softmax预测,在低重要性组样本中当预测最大概率Pmax的样本标签不是给定标签时,将最大预测概率Pmax和给定标签概率Plabel进行比较,二者差别超过阈值δ2时则认为给定标签错误,然后对标签进行修改,自修复模块如图2所示。

图2 自修复模块
具体而言,首先将主干网络输出的[B,3072]特征向量依次输入到全连接层和Sigmoid激活函数,得到批次图像中每个图像的分值αi。考虑到将分值权重直接与损失相乘会导致有些图像的损失为零,因此采用加权交叉熵损失LWCE,如式(2)所示
(2)

LRR定义为排序正则化损失,其中δ1是LRR损失函数的参数,M和N为高重要性组和低重要性组样本数,αi为样本得分,αH,αL为两组得分的平均值,如式(3)所示,LRR损失高重要性组和低重要性组样本区分度更加明显。模型的总损失为Lall,其中γ为LWCE和LRR二者的比例系数,具体如式(4)所示
(3)
Lall=γLWCE+(1-γ)LRR
(4)
2.4 多粒度与自修复融合模型
为了有效提取表情特征信息以及消除表情图像不确定因素的影响,本文提出多粒度与自修复融合的人脸表情识别方法。在训练模型前,首先对人脸表情数据集进行简单的离线预处理操作,包括尺度与灰度归一化等,采用主流的深度学习残差网络ResNet作为主干网络,通过多次实验测试后使用层数为50层的ResNet50模型作为本文模型的主干网络[11]。
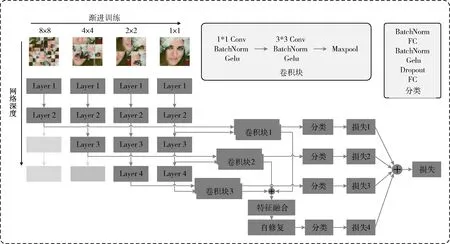
图3 多粒度与自修复融合模型
实验环境:CPU为Intel(R) Core(TM) i9-7980XE CPU,显卡为NVIDIA GeForce RTX 2080 Ti 22G,硬盘为256G SSD的主机。实验使用Windows10电脑操作系统,使用Pytorch深度学习框架搭建网络模型,其中Pytorch的版本为1.5.1,使用的CUDA版本为10.1版本,使用Python3.7编程语言。
数据预处理:使用两个自然场景下的人脸表情数据集:AffectNet数据集和RAF-DB数据集,数据集部分样本如图4和图5所示。RAF-DB表情数据集包括7类表情,共计15 339个表情样本,其中12 271个用于训练,3068个用于测试。AffectNet数据集[12]是从网络搜集的样本广泛的大批量表情数据集,实验使用一些研究者对AffectNet数据集进行筛选整理更为均匀的7类表情数据集,共计24 530个样本,其中训练集22 077个样本,测试集2453个样本。在训练前对数据进行离线预处理操作,将输入图像设置为224×224大小像素的图像,使用Normalize进行批归一化,为避免网络出现过度拟合的问题,对数据进行了数据增广处理,并对多种数据增广方法的效果进行验证。

图4 AffectNet数据集

图5 RAF-DB数据集
参数设置:在设定参数上本文通过对每个参数进行实验选去最佳值,排序正则化损失参数δ1设置为0.15,修改标签概率阈值δ2设置为0.2。此外每个批次样本数量BatchSize设置为64,在预训练模型网络时学习率Learning-Rate设置为0.0002,其它卷积模块和全连接层初始学习率LearningRate设置为0.002,采用余弦退火算法来更新学习率,从而加快网络的收敛速度。
3.1 多粒度的影响
实验采用VGG13、VGG16、VGG19、ResNet18、ResNet34和ResNet50基本深度学习网络模型在两个数据集上验证多粒度在网络模型中的有效性,实验采用1×1(原图)、2×2、4×4、8×8这4种粒度图像分4个阶段进行验证,表1和表2分别为多粒度模块在RAF-DB数据集和AffectNet数据集上的实验效果。表1和表2实验结果表明使用不同深度的深度学习模型,随着网络深度的不断增加网络的识别效果也越来越好,在网络模型中加入多粒度模型识别效果比单独使用原始网络的整体性能表现更好,在每个网络模型上准确率都有一定的提升。在RAF-DB数据集上ResNet18模型提升最高,可以达到3.61%,其它模型最少也可以提升0.2%。在AffectNet数据集上由于其数据噪声较大的原因,实验结果提升不是很明显,但是准确率最高仍然可以提升1.22%。因此,实验结果表明在不同的深度学习网络模型中添加多粒度模块可以有效提升人脸表情识别的准确率。

表1 在RAF-DB数据集上多粒度的影响/%

表2 在AffectNet数据集上多粒度的影响/%
3.2 渐进训练的影响
对于多粒度方法的验证,采用按4个训练阶段逐步输入多粒度图像验证其效果,由于网络输入图片的大小为3×224×224,根据不同大小的图像划分大小合适的粒度,划分太小可能会造成准确率的下降。因此模型选择经过拼图生成器按照1×1(原图)、2×2、4×4和8×8分块打乱顺序重新排列生成的图像,通过实验验证不同粒度逐步输入模型按阶段训练是否对识别结果有积极作用。
在RAF-DB数据集和AffectNet数据集验证不同粒度逐步输入模型渐进训练对网络模型的提升作用。表3实验结果表明分阶段渐进训练的影响在两个数据集上准确率的变化趋势是一致的,随着多粒度图像训练阶段的增加,在两个数据集上模型的准确率均是逐步提升的,分别可以提升3.05%和4.69%,然而当增加到一定程度后模型的准确率反而呈下降趋势。

表3 渐进训练的影响/%
经分析,由于输入图片的大小为224×224,图像被划分过小的粒度时,图像的特征被过分打散,不利于特征的提取。因此不同的粒度逐步输入对识别结果有促进作用,但是不是随着层次一直有效的。实验结果表明分3个阶段多种粒度训练时效果最好,其输入分别为1×1、2×2和4×4的粒度图像。
3.3 数据增广方法的影响
为了学习到图像更深层次的特征,模型采用了深层次的经典深度学习基本网络。相比于数据集的数据量,模型容易出现过拟合现象,因此使用Pytorch深度学习框架下数据增广方法对表情数据进行扩充,数据增广的方法种类很多,实验采用翻转、随机遮挡、旋转和颜色变换4种数据增广方法,并且依次添加组合验证数据增广方法对识别结果的影响。表4实验结果表明在多粒度模块下逐渐添加选择的4种不同数据增广方法在表情识别结果上效果显著,提升幅度较大,最高可以提升3.03%,说明使用数据增广方法降低了模型过拟合问题,而且在模型中使用数据增广方法扩充了数据规模,增加了模型的泛化作用。

表4 数据增广方法的影响/%
3.4 多粒度与自修复融合模型实验
由于自然场景下低质的人脸图像、模糊的表情以及标签标记的主观因素等不确定性是表情数据集好坏的重要指标,对实验结果造成很大的干扰。为了解决这一问题,采用自修复模块来抑制表情数据的不确定性,避免过度拟合不确定的人脸图像,同时添加多粒度模块更有效的提取表情不同区域的细节信息。在添加使用数据增广方法和多粒度模块的条件下通过实验对自修复模块效果进行了验证,表5实验结果表明融合模型在RAF-DB数据集和AffectNet数据集上最高准确率分别达到87.10%和63.94%,与不使用自修复模块相比分别提升2.78%和0.51%。此外,融合模型的运行耗时略有增加,但准确率提升明显,结果表明模型在RAF-DB数据集和AffectNet数据集上均达到很好的识别效果。

表5 自修复模块的影响/%
3.5 与其它方法的比较
表6和表7是本方法分别在RAF-DB数据集和AffectNet数据集上与近年国内外其它方法的对比结果。实验结果表明本方法在RAF-DB数据集上和AffectNet数据集的准确率均达到很高的准确率,超过多数现有方法,验证了本文模型在人脸表情识别方向上的有效性。因此针对自然场景下的人脸表情识别,本文模型在每个组成部分都有效的情况下,具有较高的准确率和良好的鲁棒性。

表6 在RAF-DB数据集上与其它方法的对比/%
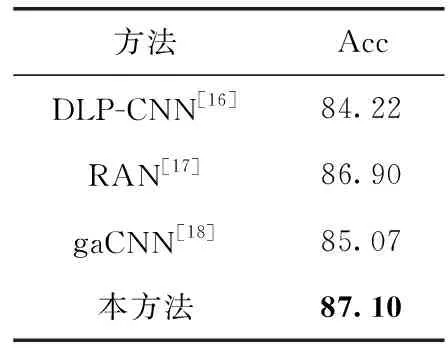
表7 在AffectNet数据集上与其它方法的对比/%
本文针对表情图像哪种粒度最具有区别性以及如何在多粒度之间融合信息,以及在自然场景下所建立的数据集通常存在错误数据、不确定样本的问题,提出基于多粒度与自修复融合的人脸表情识别模型。本研究发现在人脸表情识别任务上多粒度可以有效提取表情特征信息,在渐进训练过程中逐步添加不同粒度图像并不是一直有效,将多粒度与自修复融合后能够降低表情数据集的不确定因素,同时也有效提取了表情图像的特征信息,进一步完善了人脸表情识别方法,提升了人脸表情识别的准确率。由于本文主要研究如何利用深度学习构建自然场景下的表情识别,在远距离、侧脸和低质量、低像素等复杂表情图像方面没有太多涉及,存在一些不足和改进之处,有待进一步深入研究。
猜你喜欢人脸粒度特征根据方程特征选解法中学生数理化·中考版(2022年9期)2022-10-25有特点的人脸少儿美术·书法版(2021年9期)2021-10-20一起学画人脸小学生必读(低年级版)(2021年5期)2021-08-14粉末粒度对纯Re坯显微组织与力学性能的影响粉末冶金技术(2021年3期)2021-07-28如何表达“特征”疯狂英语·新策略(2019年10期)2019-12-13不忠诚的四个特征当代陕西(2019年10期)2019-06-03三国漫——人脸解锁动漫星空(2018年9期)2018-10-26抓住特征巧观察数学小灵通·3-4年级(2017年9期)2017-10-13基于粒度矩阵的程度多粒度粗糙集粒度约简系统工程与电子技术(2016年12期)2016-12-24双粒度混合烧结矿颗粒填充床压降实验浙江大学学报(工学版)(2016年11期)2016-06-05推荐访问:的人 粒度 修复