一种改进的BMUF训练框架及联邦学习,系统实现
来源:优秀文章 发布时间:2023-04-10 点击:
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
赵鑫博1,2,代闯闯1,2,陆忠华1*
近年来,目标检测、图像分类、语义分割、自然语言处理等人工智能技术蓬勃发展,不仅在学术理论上取得优异成果,还在各个领域中得到应用并发挥出巨大优势。然而,深度学习模型能否得到充分训练并且获得良好性能,与用于模型训练的数据规模有着直接关系[1-2]。
在大数据时代,数据已经成为重要的基础资源。然而,数据在推动人工智能等技术发展的同时,也带来许多社会问题,例如个人隐私数据泄漏等。因此,社会和政府对数据权益保护愈发重视,国内外针对数据保护的立法也逐步完善。在隐私保护日益严峻的环境下,医疗、金融等对隐私保护要求严苛的行业很难做到通过共享数据完成模型的训练,这也就造成一个个“数据孤岛”的出现。谷歌在2016年提出联邦学习概念[3],为解决“数据孤岛”与“数据隐私”等问题提供可行方案,即训练数据分散在各个设备上,通过聚合各方训练后所上传的更新信息来完成全局模型的学习。
传统的联邦学习架构常常采用中心化参数服务器完成聚合任务,虽然简单有效,但因将更新信息集中于一台服务器上,带来了额外的隐私风险和成本。区块链作为一种去中心化分布式账本,在与联邦学习结合方面具有天然优势,已有很多工作利用区块链替代参数服务器作为联邦学习系统的通信架构。例如,Ramanan等[4]提出联邦学习系统(BAFFLE),使用智能合约更新参数与聚合模型,并将全局模型存储在区块链上。Kim等[5]提出了基于区块链的联邦学习架构(BlockFL),使用区块链代替参数服务器,模型更新使用联邦平均算法[6],并加入验证机制与相应的奖励机制。Li等[7]提出了基于区块链的联邦学习框架(BFLC),定义了模型的存储模式、训练过程与委员会共识机制,并对BFLC的可扩展性、有效性与安全性进行了分析。在系统的训练过程中,大部分都选择使用FedSgd算法或FedAvg算法[6],其中FedAvg算法因在本地进行多次迭代更新,可以节省较多通信成本。
在联邦学习系统中,需要关注恶意参与方的推理与攻击行为,恶意参与方会针对梯度、参数等信息进行反向推理与攻击。针对这种行为,隐私保护手段在联邦学习系统中得到广泛应用,其中常见的有同态加密与差分隐私。同态加密技术因其加密函数的同态特性,在联邦系统中常被用于模型聚合前的数据或参数加密。Awan等[8]在系统中使用同态加密和代理重新加密技术,即针对任务与代理产生两种密钥对传输参数进行保护。Lugan等[9]在所提出联邦学习系统TCLearn的C模式中,使用同态加密来确保模型的可跟踪性和保密性。Zhu等[10]为了保证局部梯度隐私,在他们的联邦学习系统Deep-Chain中引入了同态加密与秘密共享机制。在差分隐私技术方面,Chen等[11]在提出的LearningChain中,对本地训练后的梯度加入差分隐私噪声来提供隐私保护。Lu等[12]使用差分隐私扰动本地数据来维护数据隐私。Liu等[13]通过本地化差分隐私技术来防止成员推理攻击。相较于同态加密,差分隐私通过将随机噪声添加到数据或模型参数中来保证隐私,并不会带来额外的计算成本。
同样值得关注的还有联邦学习系统中可能存在的拜占庭攻击问题,即恶意参与方并不向聚合者发送通过本地训练所得到的真实信息,而是企图通过发送拜占庭梯度来影响全局模型的性能。现有的拜占庭攻击容忍算法Draco[14]、Bulyan[15]、Multi-Krum[16]等有着较高的计算复杂度。Chen等[11]在系统LearningChain中,使用l-nearest算法来抵御拜占庭攻击,即将前一轮梯度和作为良性梯度,计算本轮梯度与良性梯度间的余弦距离并选取前l个相近梯度进行聚合。Muñoz-González等[17]提出一种基于良性梯度去除恶意梯度的方法,即将本轮梯度的加权平均值作为良性梯度,计算其与每个梯度之间的余弦相似度,并将范围外的梯度视为恶意梯度。
针对上述几个关键点,提出了一个基于改进BMUF框架的区块链联邦学习系统。本文贡献可以概括为:
(1)改进BMUF框架并应用,使系统在不同的数据分布场景下聚合效果较使用FedAvg算法更好;
(2)在客户端本地训练中使用Opacus[18]加入差分隐私机制保护本地隐私;
(3)提出一种基于全局更新梯度的拜占庭检测鲁棒聚合算法,使聚合者可以检测出系统中存在的拜占庭客户端并完成鲁棒聚合;
(4)使用MNIST[27]数据集进行实验,对所述系统与算法的有效性进行验证。
1.1 区块链
区块链概念最早由“中本聪”在比特币[19]论文中所提出,2016年中国工信部发布的《中国区块链技术和应用发展白皮书》中对其进行定义:狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算 范式[20]。
如图1所示,区块一般由区块头与区块体两部分构成,其中区块头中记录了当前区块的头信息,包括前一个区块的哈希值、本区块的哈希值、时间戳等等;
区块体中存储区块的详细数据信息,可以是交易信息或其他信息。

图1 区块链数据结构Fig.1 Blockchain data structure
区块链的很多特性与联邦学习结合有着天然优势。例如,借助区块链中的共识机制,如PoW、PoS、DPoS与PBFT等,实现对联邦系统中各参与方的奖励与激励机制;
利用区块链的可追溯性防御联邦学习系统中的潜在攻击,并给予相应惩罚;
利用区块链的不可篡改性,将联邦学习各参与方的相关信息存储于区块链中,防止恶意参与方对其进行篡改。
1.2 联邦学习
联邦学习可以使各参与方在训练数据不离开本地的前提下,通过交换模型相关信息来协同完成全局模型的训练,在交互过程中可以使用隐私技术保护参与方隐私。联邦学习架构如图2所示,训练过程可描述如下:
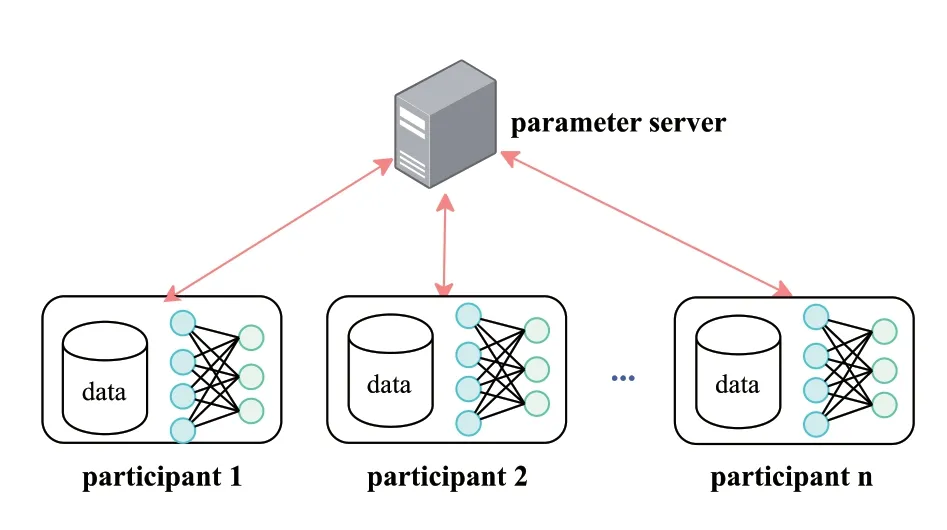
图2 联邦学习架构Fig.2 Federated learning architecture
(1)参与方在本地完成模型训练,并将加密或扰动后的梯度、参数传给参数服务器;
(2)服务器收到足够的更新信息后执行安全聚合,并将聚合结果传输回参与方;
(3)参与方使用服务器传输回的聚合结果更新自身模型。
重复执行上述三个步骤,直到全局模型的损失函数收敛或达到全局最大通信轮次即可完成联邦学习的训练。
1.3 BMUF框架
BMUF框架,又称逐区块更新滤波技术,是一种深度学习模型的并行训练算法,由陈凯[21-22]提出用于改善模型平均(Model Average)算法可扩展性差的特点,MA算法将所有从机训练后得到模型的算数平均值作为本轮训练的全局模型。不同于MA算法,BMUF将全局模型更新过程视作block级的随机优化过程,改善了算法的收敛速度与可扩展性[21],BMUF框架流程概括如下:
启动从机i训练,等待从机训练完成;
聚合所有从机优化得到的模型:

计算全局更新梯度:

更新全局模型:

使用CBM方式 :

使用NBM方式 :
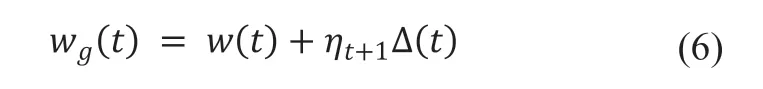
1.4 差分隐私
差分隐私由Dwork在2006年提出,其目的在于提供一种方法,当用户对数据库进行查询操作时,通过向查询结果中添加随机噪声,使恶意用户难以通过观察结果推断出原始信息[23]。目前差分隐私常用的扰动机制包括拉普拉斯机制[24]、指数机制[25]与高斯机制[26]等,差分隐私定义如下:

2.1 BMUF框架的改进
本文对联邦学习环境下BMUF框架的改进主要体现在以下两个方面:
(1)增量块的定义
原文中[20]作者对增量块的定义面向分布式深度学习中的数据并行场景,每次主机迭代时N台从机处理的Split构成一个block。设整个训练数据集为D,并将其分割为M个block,作者将这种分割方式称为“N * M”,如图3所示。

图3 数据分割方式Fig.3 Data segmentation method
本文对增量块定义面向联邦学习场景,设有N台客户端参与联邦学习训练,每次系统迭代时,将参与本轮训练客户端所处理本地数据集的总和视为一个block。
(2)聚合者针对更新信息的聚合方式
原文中[21], 在每次迭代结束后,主机获取从机的模型参数,并使用模型平均算法与BMUF算法对其进行聚合,聚合过程如1.3中所述,现针对框架中改进部分作出说明:

本文面向联邦学习场景,对更新信息的聚合方式定义如下:
客户端每次训练结束后,向聚合者传递更新梯度,聚合者使用基于数据量加权的方式进行聚合,即:

2.2 系统架构
本文提出一个基于改进BMUF框架的区块链联邦学习系统,系统训练过程如图4所示,并可将其总结为算法1。目的在于解决当下“数据孤岛”与“数据隐私”等难题,使各参与方在去中心架构下针对不同数据分布场景,保护自身数据隐私,抵御恶意客户端的拜占庭攻击,继而完成全局模型的高效训练。系统执行流程可分为两个步骤:

图4 系统训练过程Fig.4 System training process
(1)初始化过程
初始化过程包括网络初始化与模型参数初始化两部分。所有参与方共同构建一个去中心化的点对点网络,并为接下来的训练过程初始化模型参数。
(2)训练过程
训练过程包括共识过程、客户端本地训练与聚合者模型聚合三部分。首先,通过共识过程在参与方之间选举出本轮聚合者;
之后,客户端开始本地训练过程,过程中可以使用差分隐私机制保护本地隐私,并在完成训练后将更新信息传递给聚合者;
聚合者收集到足够多的更新信息后,开始模型聚合过程,聚合完毕后将数据封装入区块,并添加到区块链上;
最后通过共识过程对本轮贡献者进行奖励。
2.3 初始化过程
2.3.1 网络初始化
网络初始化步骤将在系统各参与方之间构建一个点对点(Peer-to-Peer)系统,用于后续训练过程中各参与方之间的信息交流。在初始化过程开始时,每位参与方都向系统中其他参与方宣布自身的存在,最终完成对等网络的初始化。
2.3.2 模型参数初始化
在训练过程开始前,通过模型参数初始化步骤,系统中所有参与方就初始模型参数达成共识。我们假设模型的初始权重与偏置项参数使用随机数算法生成,并由可信的权威机构发布在创世纪块中。
2.4 训练过程
2.4.1 共识过程在系统中,区块链被所有参与方所持有,但在训练过程结束后,应只有一个参与方有权创建新的区块并将其添加到区块链上。在训练过程的初始阶段,系统通过共识过程选举产生一个聚合者来完成聚合任务并将新创建的区块添加到区块链上。我们使用类似PoS共识中的权益概念来衡量参与方对全局模型的贡献并完成共识选举,设在第t轮通信中,k号参与方的权益量为,则每个参与方被选举为聚合者的概率为:

对于客户端的权益增量,则取决于本轮其对全局模型的贡献大小。系统在训练结束后,将对做出有益于系统行为的客户端进行奖励,包括上传正确更新信息与完成模型聚合任务,并对上传拜占庭更新信息的客户端进行惩罚。

Algorithm 1 Summary of training process Notations: block momentum ; block learning rate ; the number of local epochs E ; the local learning rate ; the local batch size B; the clients indexed by k; index set of the clients participating in this round of computation Z; identification sign of the byzantine clients acc; the total amount of data n and the amount of data supplied by the client k ;while each round t =1,2... < Max communication rounds do Run consensus protocol to elect the aggregator ; Client:(1) Retrieve global model as from the block ;(2) The client calculates its local gradient : if not disable differential privacy then use Opacus to train model ; end if for each local epoch i =12...E do for b∈B do ; end for end for

Algorithm 1 Summary of training process ;(3) Send the update information to the aggregator;Aggregator :(1) Wait for enough“update information”to aggregate the global model ;(2) Use Algorithm 2 to remove byzantine clients and compute G(t) ;(3) Set acc to false for byzantine clients ;(4) Retrieve global model from the block ;(5) The aggregator updates the global model : Use Nesterov block momentum scheme :(6) Create block and append it to the chain , the data contained in block : Datat = { , , {Infok t , k∈Z }};Reward aggregator and clients whose acc sign is true ;end while
2.4.2 客户端本地训练
在客户端本地训练步骤中,客户端使用本地数据集计算局部梯度,向聚合者共享本地更新信息,过程中可以通过差分隐私机制保护自身隐私,具体流程描述如下:
(1)各客户端从区块链的最后一个区块中获取全局模型参数作为本地模型参数更新本地模型;
(2)各客户端根据预先设定好的超参数,如学习率(learning rate)、批大小(batch size)、本地迭代次数(epochs)等,使用本地数据集对模型进行训练,可以在本地进行多次迭代以减少通信成本;
(3)本地迭代结束后,客户端对更新信息进行打包并将其发送至本轮聚合者处,更新信息中包含了客户端索引(k)、本地更新梯度、参与本地训练数据量、拜占庭检测标志位(acc)、全局通信轮次(t),设在第t轮通信中,k号客户端的更新信息为,则有:

关于本地隐私保护,系统中的差分隐私机制通过将Opacus[18]的PrivacyEngine接口链接至PyTorch优化器实现,可以在处理模型梯度的同时追踪隐私预算。
2.4.3 聚合者模型聚合
在训练过程的初始阶段,系统通过共识过程在各参与方之间选举产生聚合者,聚合者不进行本地训练,而是阻塞并收集各客户端的更新信息。待收集足够更新信息后,聚合者执行算法2进行拜占庭检测与鲁棒聚合,之后使用BMUF算法生成全局模型,最后将相关信息封装入新的区块并添加到区块链上,具体流程如下:
(1)等待各客户端完成本地训练,收集足够数量的更新信息;
(2)执行算法2进行拜占庭检测与鲁棒聚合,对算法2分步骤描述如下:
a.初始化相关参数,将收集到的更新信息视作集合P(良性客户端集合),并初始化空集B(拜占庭客户端集合)与非空集R(临时客户端集合),根据预先设置的阈值(拜占庭检测阈值)、(拜占庭检测阈值增量)与(梯度裁剪阈值)执行算法;

c.当集合R不为空集时,继续执行步骤c与步骤d。将集合R置为空集并分别计算集合P中相似度的平均值、中位数 与标准差。设参与训练的客户端数量为,其中拜占庭客户端数量为,算法要求来保证算法的可行性与稳健性,易证在时,拜占庭客户端数量恒小于参与训练客户端数量的一半,即,所以中位数m所代表的相似度来自于良性客户端;
e.重复执行步骤c与步骤d直到集合R为空集,即可完成拜占庭客户端检测,接下来执行步骤f进行鲁棒聚合;
f.对集合P中所有更新梯度逐维度排序,并将每个维度中最大的个值与最小的个值在原梯度中置0,最后对集合P中的更新梯度进行加权求合。因某些情况下,恶意梯度可以接近良性梯度来干扰模型收敛[15],步骤f使聚合结果更加鲁棒。

Algorithm 2 Byzantine detection and robust aggregation Notations: byzantine clients’set B ; good clients’set P ; temporary clients’set R ; gradients trim threshold β ; byzantine detection threshold ξ ; byzantine detection threshold incrementΔξ>0;1: Retrieve global model update Δ(t- 1) from the block Blockt-1;2: Compute the similarity Sk between Gk t andΔ(t- 1) ;3: while len(R)≠0 do 4: R=φ ;5: Compute mean (μ) of Sk for clients in P;6: Compute median (m) of Sk for clients in P;7: Compute standard deviation (σ) of Sk for clients in P ;8: if μ

Algorithm 2 Byzantine detection and robust aggregation 17: for k in P do 18: if Sk> m+ξσ then 19: if len(P)>2β+1 then 20: R.append(k), P.remove(k) ;21: end if 22: end if 23: end for 24: end if 25: ξ=ξ+Δξ , B.append(R) ;26: end while 27: For dimention d , sort the dth dimension values of all gradients in P, and set the largest and smallest β values to 0 in original gradient ;28: ;29: return B,P,G(t) ;
(3)将集合B中客户端的拜占庭检测标志位acc置为False,判定其更新信息为恶意信息;
(6)创建区块,并将区块添加到区块链上,包含在区块中的信息有全局模型参数、全局更新梯度与各客户端上传的更新信息,设在第t轮通信中向聚合者传递更新信息的客户端索引集合为Z,包含在区块中的信息为 ,则有:

3.1 改进BMUF框架实验
3.1.1 实验数据集与实验环境
实验采用MNIST[27]数据集,该数据集包含60,000个训练样本和10,000个测试样本,实例为0至9之间某一手写数字的灰度图像,大小为28 × 28像素。
实验环境如下:操作系统为Ubuntu 18.04.5,CPU为Intel(R) Core(TM) i9-10940X,GPU为GeForce RTX 2080 Ti,内存64G,CUDA 11.1,Python 3.7.5,Pytorch 1.8.1。
3.1.2实验方案
本实验仅测试改进BMUF框架聚合效果,模拟真实联邦学习场景,将数据集中的训练样本切分为100个索引集从而模 拟100个客户端参与全局模型构建。每轮随机选取10个索引集,分别基于前一轮全局模型进行训练并对训练产生的局部更新信息进行收集,之后使用改进BMUF框架或FedAvg算法完成全局模型聚合,如此迭代直至达到最大通信轮次。现将数据集中的训练样本针对Unbalanced与Non-IID两种数据分布场景作如下切分:
(1)Unbalanced(数据量分布不均):将数据集中的训练样本打乱,生成总和为60,000的100个随机数,按照生成随机数序列将训练样本分配至100个客户端处,每个客户端所持有数据量如图5所示。

图5 Unbalanced场景数据分布Fig.5 Data distribution in unbalanced scenario
(2)Non-IID(数据非独立同分布):根据样本标签(0-9)对训练样本进行排序,将排序后样本划分为200份并平均分配至100个客户端处,每个客户端分得2份,可能为一个数字的600个样本或两个数字各300个样本。
本节实验采用卷积神经网络,模型结构如表1所示,使用Relu激活函数,本地模型训练使用SGD算法,学习率设置为0.1,冲量设置为0.5。两种数据分布场景中均将块冲量设置为0.9,块学习率设置为1。

表1 CNN模型总结Table 1 Summary of the CNN model
3.1.3 实验结果
图6展示了在本地训练中分别取不同迭代次数和批大小时全局模型的准确率情况。从实验结果可以看出,Unbalanced场景下,模型准确率在前 20 次通信中快速提高,并在第 50次通信前后基本收敛。Non-IID场景下,模型准确率受非独立同分布影响而出现波动,但整体呈上升趋势并最终收敛。

图6 全局模型准确率曲线Fig.6 Accuracy curve of the global model
在对比实验中,设置本地迭代次数为1,批大小为50,图7展示了联邦学习在分别采用改进BMUF与FedAvg时全局模型的准确率情况。从实验结果可以看出,Unbalanced场景下,改进BMUF较FedAvg准确率提升更加迅速,并可在更少的通信轮次内使模型达到收敛状态。Non-IID场景下,改进BMUF较FedAvg准确率波动小且提升更快,在第100次通信前后基本收敛,FedAvg则需要更多通信轮次来达到收敛状态。

图7 改进BMUF与FedAvg准确率对比Fig.7 Accuracy comparison of improved BMUF and FedAvg
3.2 联邦学习系统实验
3.2.1 实验数据集与实验环境
实验采用MNIST[27]手写数字数据集,简介见3.1.1。实验环境如下:操作系统为Ubuntu 18.04.5,CPU为Intel(R) Xeon(R) E5-2640,GPU为12张Tesla K80,内存251G,CUDA 10.2,Python 3.7.10,Golang 1.16.4,Pytorch 1.10.0。
3.2.2 实验方案
本实验对文中所述联邦学习系统与算法的有效性进行验证,包括:(1)不同参与方规模下全局模型的准确率情况;
(2)差分隐私机制对全局模型准确率的影响;
(3)拜占庭检测与鲁棒聚合算法的防御效果。实验在伪分布式环境下进行,我们在本地部署联邦学习系统并使用不同端口模拟各参与方进行全局模型构建。
数据分配方面,针对实验(1)与(2),将数据集中的训练样本打乱后平均分给每个参与方,参与方之间数据无交集。针对实验(3),在所述分配方式基础上,令拜占庭客户端持有单一数字且标签错误的数据集。在模型与超参数方面,实验采用多层感知机模型,模型分为三层,神经元个数分别为784、32和10,使用Relu激活函数,本地模型训练使用SGD算法,学习率设置为0.0005,冲量设置为0.5。针对参与训练客户端的数量N,启发式的将块冲量设置为,块学习率设置为1。在实验(1)与(2)中,将阈值 设置为2.0,设置为0.5,设置为0。在实验(3)中,将阈值设置为1.5,设置为0.3,设置为恶意参与方的数量。
3.2.3 实验结果
图8展示了系统在参与方数目分别为10、15与20时全局模型的准确率情况,从实验结果可以看出,三种情况下全局模型均在第150次通信前后达到收敛状态,参与方规模与本地所持数据量对前期准确率的提升有一定影响,但对收敛后的准确率影响不大。
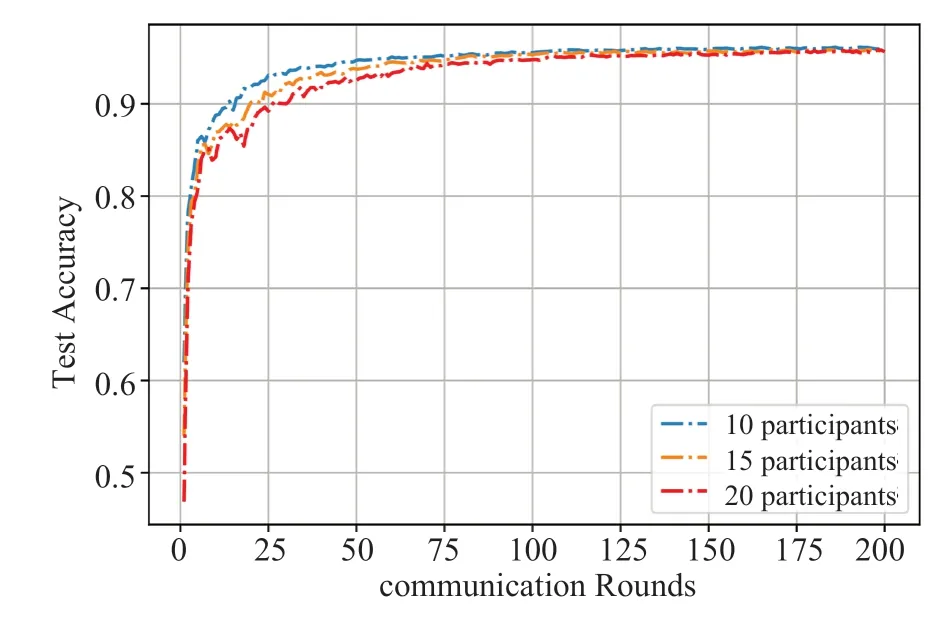
图8 不同参与方规模下全局模型的准确率Fig.8 The accuracy of the global model under different participant scales
表2展示了系统采用不同隐私预算对全局模型准确率的影响,从实验结果可以看出,采用较小的隐私预算可以更好保护本地隐私,但会牺牲一定的模型准确率。在实际应用中,应结合隐私保护要求对隐私预算进行设置,使隐私保护与模型效用达到平衡。

表2 差分隐私机制对全局模型准确率的影响Table 2 The impacts of differential privacy mechanism on the accuracy of the global model
图9展示了拜占庭检测与鲁棒聚合算法的防御效果。实验共设置20个参与方且存在不同数目的恶意参与方。从实验结果可以看出,当系统中存在10%与20%的恶意参与方时,全局模型准确率与无恶意参与方时相差无几,算法可以有效剔除客户端并进行鲁棒聚合。当存在30%恶意参与方时,算法依然可以保证全局模型以较高准确率达到收敛状态。

图9 拜占庭检测与鲁棒聚合算法效果Fig.9 The effect of byzantine detection and robust aggregation algorithm
本文对BMUF训练框架做联邦学习环境下的适应性改进,基于BMUF训练框架中的全局更新梯度提出了一种拜占庭检测鲁棒聚合算法,并实现了一个基于区块链的隐私保护联邦学习系统,可以通过差分隐私机制有效保护客户端隐私、抵御拜占庭攻击并完成模型的高效训练。最后,通过多组实验对文中所述算法与系统的有效性进行了验证。未来还可以在原型系统中引入模型压缩等技术以支持更大规模的深度学习模型,进一步优化存储与通信开销,探索改进BMUF框架在联邦学习环境下的超参数设置规律等。联邦学习是“数据孤岛”、“数据隐私”等问题的有效解决方案,研究探索联邦学习技术对各行各业具有重要意义。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢拜占庭参与方联邦基于秘密分享的高效隐私保护四方机器学习方案计算机研究与发展(2022年10期)2022-10-14一“炮”而红 音联邦SVSound 2000 Pro品鉴会完满举行家庭影院技术(2020年10期)2020-12-14拜占庭帝国的绘画艺术及其多样性特征初探内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03303A深圳市音联邦电气有限公司家庭影院技术(2019年7期)2019-08-27浅谈初中历史教学中的逻辑补充——从拜占庭帝国灭亡原因谈起中学历史教学(2018年1期)2018-04-04《西方史学通史》第三卷“拜占庭史学”部分纠缪古代文明(2016年1期)2016-10-21绿色农房建设伙伴关系模式初探中国房地产·学术版(2016年7期)2016-10-21涉及多参与方的系统及方法权利要求的撰写专利代理(2016年1期)2016-05-17基于IPD模式的项目参与方利益分配研究项目管理技术(2016年10期)2016-05-17拜占庭之光凤凰生活(2016年2期)2016-02-01推荐访问:联邦 框架 系统实现