基于Stacking集成模型的台区线损率预测方法研究
来源:优秀文章 发布时间:2023-03-01 点击:
李晋源,保富,胡凯,张丽娟
(1.云南电网有限责任公司信息中心,昆明 650217;
2. 云南电网有限责任公司,昆明 650200)
在电力系统中,线损管理是电网运维和供电企业电能营销服务系统的重要基础业务[1]。在我国,台区线损约占整个电网线损的20%,严重的电力损耗不仅损害了电网公司的利益,也与我国双碳这一目标的实现背道而驰,对台区线损进行管理迫在眉睫[2]。而线损率的准确预测有助于提高线损管理水平,因此,对线损率预测方法进行研究具有重要的实际意义。
目前,国内外有许多研究人员对线损率计算方法进行了深度研究,主要集中在深度学习、集成学习等智能算法上。文献[3]中,提出了一种将级联BP神经网络和小生境遗传算法相结合的台区线损率预测模型。结果表明,该预测方法的训练效率和泛化能力均优于传统预测方法。文献[4]中,提出了一种改进的自编码器方法来预测台区的线损率。结果表明,该预测方法的相对误差和计算效率均优于传统的预测方法。文献[5]中,提出了一种将变分模态分解和改进最小二乘支持向量机相结合来预测台区线损率。结果表明,该预测方法的精度和效率均优于传统预测方法。文献[6]中,提出了一种降噪自编码器和长短期记忆网络相结合的线损率预测方法。结果表明,该模型预测线损率精度高,运行速度适中,具有一定的应用价值。虽然上述预测方法在一定程度上比传统方法更准确、更高效,但在线损率预测精度方面并不理想,需要进一步提高。
在此基础上,提出了一种结合Stacking集成学习模型和改进的k-均值聚类方法来预测台区的线损率。通过聚类方法进行数据聚类,在通过Stacking集成学习模型对台区线损率进行预测。通过试验进行了对比分析。
原始输入数据为某省电力公司台区数据,采样为1天/次,将连续30天的数据作为输入,对第31日的线损率进行预测。由于采集设备故障和人为操作等因素的干扰,存在缺失和异常等情况,在预测低压台区线损率之前,应对这些线损数据进行处理[7]。
(1)缺失值处理技术。
部分线损率数据为零或为空,影响线损率预测效果。文中用拉格朗日插值法对这些数据进行了补充。
提取缺失点前后的五个数据,并用式(1)和式(2)进行补充[8]。
(1)

(2)
式中r为缺数据对应的下标序号;
ri为非缺失数据yi的下标序号;
Ln(r)为补充数据;
li(r)为拉格朗日多项式。
(2)异常值处理。
对数据进一步分析,找出异常值进行剔除。线损率:剔除线损率≤0%或>40%的异常高损耗台区。功率因数:剔除功率因数<0.6的台区[9]。
(3)数据归一化。
为了更全面地预测线损率,需要对数据进行归一化处理,数据归一化过程如式(3)所示[10]:
(3)
式中x和x′分别为原始数据的实际值和归一化数据;
xmax和xmin分别为原始数据的最大值和最小值。
2.1 改进的K-means 聚类方法
麦奎因提出了k-均值聚类算法,不再考虑相似性问题,而是考虑距离问题[11]。作为一种优化,它是通过找到目标函数的极值来调整的。步骤如下:
步骤1:将类别数k定义为初始化过程中初始集群中心的数量。
步骤2:根据式(4)计算样品与每个中心点之间的距离。样本和最近的中心点被分组为一类,形成k个簇[12]。
(4)
式中Iij为样本点i到j的距离;
m为样本点坐标的维数;
Zik和Zjk分别第k个簇中样本点i和j的坐标。
步骤3:将坐标平均值作为新聚类中心。
步骤4:通过式(5)判断是否收敛[13]。

(5)
式中Zq为Ci类中的样本q的坐标;
mi为Ci类的聚类中心坐标;
E为平方误差。
k-均值聚类方法需要在聚类之前确定聚类的数目[14]。其次,聚类中心的确定原则不明确,如果初始值选择不正确,后续工作就无法得到理想的聚类拟合结果[15]。
为了优化k-means聚类方法,使用聚类结果的总轮廓系数St(值越高,效果越好)来选择最优k值。对于任何采样点i,轮廓系数S(i)的计算如式(6)所示[16]:
(6)
式中q(i)为点i与聚类中其他点的距离值;
p(i)为点i与聚类中其他点的最小平均距离。
聚类结果总轮廓系数计算如式(7)所示[17]:

(7)
采用评价指标PE评估聚类的质量,聚类如式(8)所示[18]:
(8)
式中ωj为第j个特征参数的权重;
Zij为第j个簇中样本点i的坐标;
Zjmin为距离最近的第j个聚类中心坐标。根据PE值的升序原则,将样本平均划分为k个类别,并将每个类别的中心样本设置为该类别的聚类中心。使用上述公式通过迭代计算确定理想分类。
2.2 Stacking集成学习模型
Stacking集成学习模型融合了多个预测模型,将原始数据划分多个子集,输入第1层的各基学习器,输出结果作为第2层的元学习器的输入[19]。学习方法如图1所示。
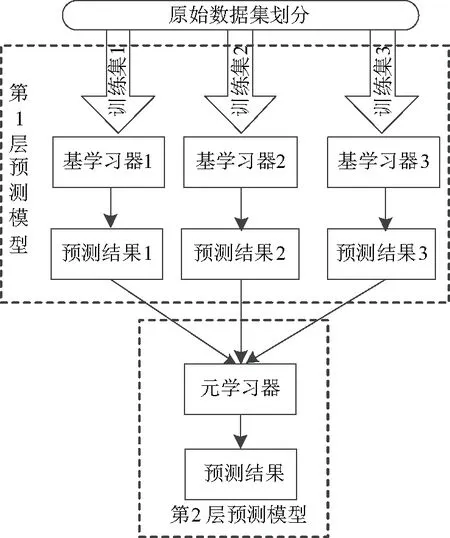
图1 Stacking集成学习模型学习方法
模型的训练方法如下:
对于数据集S={(xn,yn),n=1,…,N},xn为第n个样本的特征向量;
yn为第n个样本对应的预测值;
p为包含的特征个数。即每个特征向量为(x1,x2,…,xp)。将数据随机分成k个大小相同的子集S1,S2,…,Sk。
以第1个基学习器为例,每个子数据Si(i=1,2,…,K)作为测试集,剩下的作为训练集,得到预测结果,组合成集合L1[20]。L1长度与S相同。
所有L={L1,L1,…,Ln}基学习器得到集合L1,L1,…,Ln作为新的数据集L,作为第2层的输入,第2层对第1层的误差进行修正,从而提高诊断模型的准确性[21]。
Stacking集成模型第1层选择不同类型的基学习器对数据进行多角度分析。第2层元学习器要泛化能力强的模型,这有助于纠正第1层诊断错误并获得最佳诊断结果[22]。
基于基学习器的预测能力,在Stacking模型的第1层选择XGBoost模型、长短时记忆网络(Long Short Term Memory, LSTM)和梯度提升决策树(Gradient Boosted Decision Tree,GBDT)。这是因为LSTM能够充分挖掘包含在大量数据中的有效信息,具有长期记忆以及深度学习的能力[23]。采用bagging 集成的GBDT适用于高维数据,学习能力较强,拥有并行处理能力[24]。采用boosting方法集成的XGBoost增加了正则化项,有效地防止了过度拟合,效率较高[25]。
第2层选择泛化能力强的模型。根据该模型,总结和纠正了各种学习算法对训练集的偏差,并通过集合方法防止了过度拟合效应。在第2层中, XGBoost 被选为元学习器,模型架构如图2所示。

图2 Stacking集成模型结构
2.3 预测方法
预测方法的具体步骤如下:
步骤1:输入原始数据;
步骤2:数据预处理。补充缺失数据,删除异常数据,对所有数据进行归一化;
步骤3:通过灰色关联度分析对指标体系进行构建;
步骤4:降低样本数据指标的维度,消除指标之间相关性的影响,从而更好地对样本进行分类;
步骤5:利用改进的k-均值聚类技术对台区进行聚类;
步骤6:选择XGBoost模型、GNDT模型和LSTM模型作为元学习器,建立Stacking集成学习模型预测线损率;
步骤7:与传统模型进行对比比较。图3所示预测方法的流程。
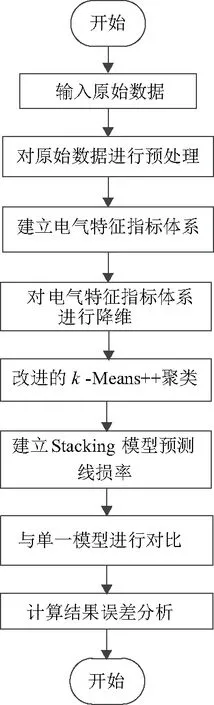
图3 预测方法流程
3.1 试验参数
此次试验的CPU为Intel i52450m,操作系统为Windows 10 64位旗舰,内存为64 G,硬盘为1 T,频率为2.5 GHz,仿真软件为MATLAB。为了验证所提方法的优越性,选取了9 000个有源台区对线损率进行了计算和分析。训练集与测试集的比值为2:1。算法参数如表1所示,算法参数通过参考文献[26-27]和多次试验取值。
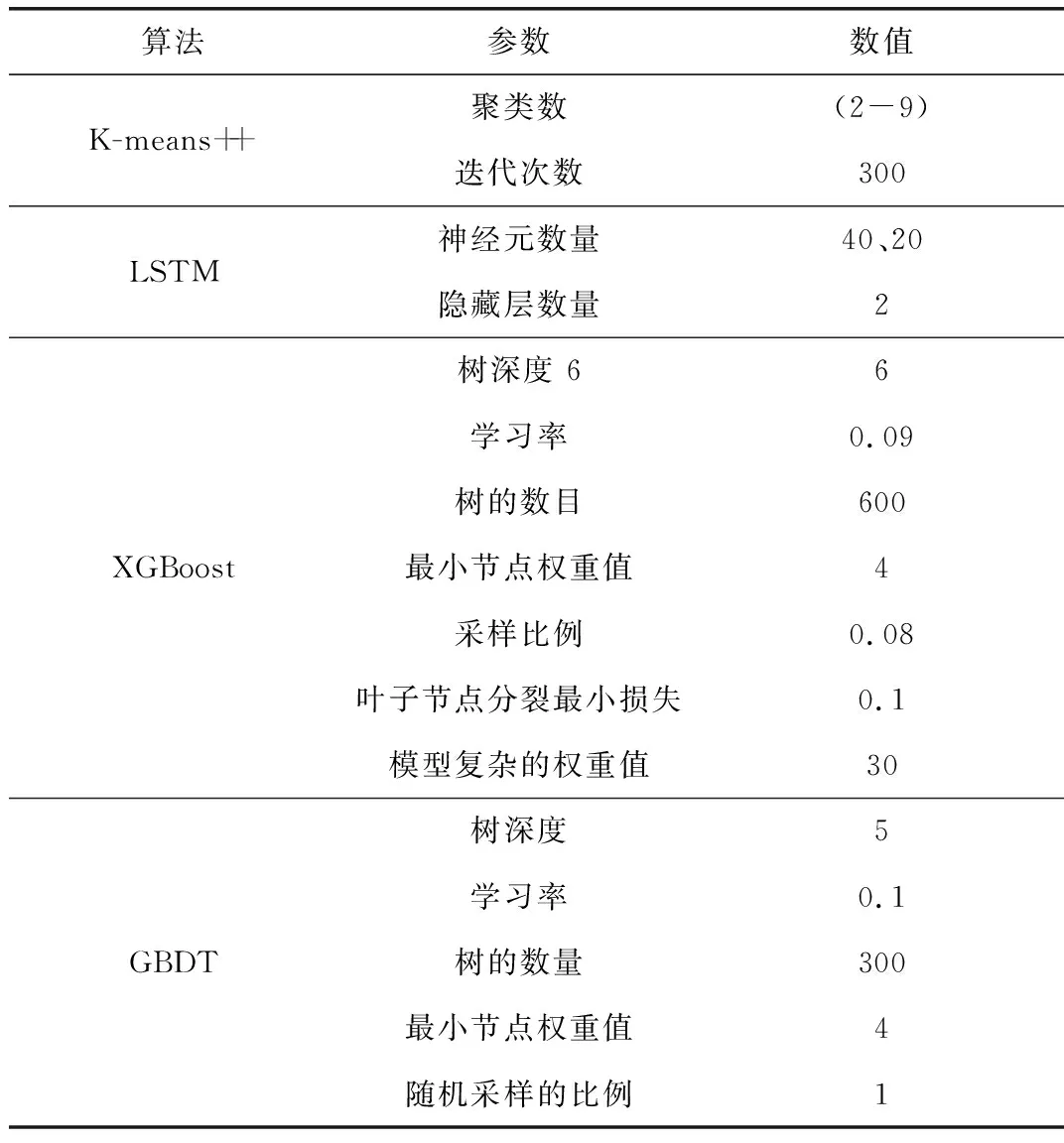
表1 算法参数
为了更好地评估文中模型的性能,选择两个指标对模型进行评估,均方误差(Mean Square Error,MAE)和R2,如式(9)和式(10)所示:
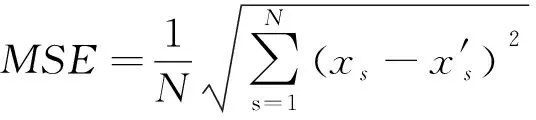
(9)
(10)
式中xs和x′s分别为s时刻台区线损率的实际值和预测值;
N为计算的总时间;
x′为台区线损率平均值。
3.2 试验分析
使用所提的聚类算法对数据进行聚类,将初始聚类数k从2增加到9,并计算不同k值的轮廓系数,如表2所示。

表2 不同 k时的轮廓系数
从表2可以看出,当k=5时,轮廓系数的值为最大值0.341,聚类效果最优。文中选取k=5。
将样本根据PE从小到大分为五类,样本中心是初始聚类中心。五个中心的样本数如表3所示。

表3 各类样本数
基于上述分类结果,使用Stacking集成学习对5类样本的训练集进行训练,测试样本用于预测训练模型的线损率,并与传统模型(XGBoost、GBDT、LSTM)进行比较。预测结果如表4所示,部分评估结果如表5所示,运行时间如表6所示。

表4 不同模型的预测误差对比
从表4和表5可以看出,文中模型预测结果中相对误差小于5%或10%的台区占比高于传统方法,相对误差大于20%占比与其相反。说明所提方法预测精度最高,与实际值最为接近。这是因为所提方法融合多种模型进行互补,预测结果较为精准。由表6可以看出,文中模型相比于单一模型运行时间最长。这是因为集成模型中每个基分类器都需要交叉训练,导致运行时间过长。

表5 部分评估结果

表6 不同模型运行时间对比
为了进一步验证所提方法的优越性。MSE和R2被用作衡量不同模型拟合程度的指标,如图4和图5所示。

图4 不同方法MSE结果对比
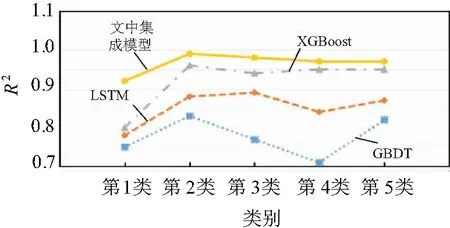
图5 不同方法R2结果对比
从图4和图5可以看出,文中模型的MSE值一直处于最低水平,R2值一直处于最大值,说明文中预测方法相比于传统XGBoost、GNDT、LSTM模型具有更好的预测效果,结果更加准确,泛化能力更强。
提出了一种改进的k-均值聚类方法和Stacking集成学习模型相结合用于预测台区线损率。通过聚类算法进行聚类,在通过Stacking集成学习模型对台区线损率进行预测。Stacking集成学习模型由XGBoost模型、GBDT模型、LSTM模型构成。结果表明,与传统预测模型相比,该方法具有更好的性能,预测结果更加准确、泛化能力更强和实用价值更高。鉴于目前的测试设备和数据规模,文章对线损率预测方法的研究还处于起步阶段。由于采用Stacking集成学习模型,计算时间较长。因此,未来的研究需要结合分布式计算,逐步提高模型的性能,有效减少模型的执行时间。
猜你喜欢 损率台区聚类 我国水库淤损情势分析水利学报(2022年3期)2022-06-07配电台区变-户拓扑关系异常辨识方法河北电力技术(2022年1期)2022-03-25基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08降低台区实时线损整治工作方法电子制作(2017年2期)2017-05-17无功补偿极限线损率分析及降损措施探究电子制作(2017年2期)2017-05-17基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-2610kV变压器台区设计安装技术研究电子制作(2016年1期)2016-11-07供电企业月度实际线损率定量计算方法电子制作(2016年1期)2016-11-07基于用电信息采集系统的台区线损管理研究中国市场(2016年45期)2016-05-17基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04推荐访问:模型 集成 预测