移动边缘计算中基于联邦学习的视频请求预测和协作缓存策略
来源:优秀文章 发布时间:2023-02-28 点击:
李光辉 李宜璟 胡世红
(江南大学人工智能与计算机学院 无锡 214122)
随着移动互联网的飞速发展以及智能终端功能的逐渐强大,拍摄、处理、上传、分享等功能大大降低了视频制作的难度,进而带动了自媒体短视频、直播等视频服务的兴起。越来越多的人可以通过各种视频网站或社交媒体平台传递信息。随着5G时代的到来,视频正在成为信息的主要载体。根据英特尔委托Ovum最新发布的《5G娱乐经济学报告》,预计未来10年5G用户的月均流量将是4G用户的7倍,到2028年消费者将在视频服务上花费近1.5×1011美元[1]。传统的云中心具有强大的计算和存储能力,但在5G应用场景下,也难以应对用户对数据急剧增加的请求。移动边缘计算(Mobile Edge Computing, MEC)[2]作为一种有潜力的新型计算范式,通过在网络边缘部署计算和存储资源,在更靠近用户的位置提供服务或存储数据,减少数据传输延迟并缓解网络拥塞,弥补了云计算的不足。
内容缓存作为新兴网络体系结构(如以内容为中心的网络和以信息为中心的网络)的基本网络功能,并不是一项新技术,但视频流量的快速增长也导致业界和学术界正在重新设计内容缓存系统,从而适应这种巨大的流量[3]。因此,越来越多的研究者考虑在移动边缘计算的框架下研究内容缓存的相关问题[4-8]。
Thar等人[4]提出将深度学习应用于预测内容的未来流行度,通过在云数据中心训练深度学习模型,做出缓存决策,将缓存决策发送到每个基站以主动存储流行内容。Rathore等人[5]提出了一种基于深度学习的主动缓存框架,通过提取用户和内容的隐藏特征构造用户的内容流行度矩阵,并通过基于特征的协同过滤用该矩阵预测核心网络的流行内容进而缓存。杨静等人[6]提出一种结合特征感知的内容社交价值预测方法,通过预测的价值计算每个内容的总流行价值进而选择缓存内容。上述研究涉及的模型训练都在数据中心完成,因此需要将用户请求的相关信息上传至数据中心,这个过程中需要占用网络流量,消耗通信成本,同时可能引起用户相关隐私泄露的安全问题。为了解决上述问题,Saputra等人[7]提出了一种新颖的基于分布式深度学习框架来预测流行内容,每个边缘节点都从其覆盖区域的移动用户收集信息,并建立动态日志在本地进行预测。刘浩洋等人[8]则提出一种流行度匹配边缘缓存策略,并通过建模实验验证了流行度参数匹配对应的文件缓存概率可以最大限度提升通信可靠性并降低回程带宽压力。上述研究在仿真实验中均得到很好的验证,但与仿真实验中按概率分布生成的数据不同,现实世界的数据更加多样和稀疏,这对预测带来了更多挑战。Google首次提出了联邦学习的概念,不同于普通分布式训练的是,联邦学习的计算节点对数据具有绝对控制权,可以选择随时停止计算和通信,退出学习过程[9]。中心节点无法直接或间接操作计算节点上的数据。此外,在分布式学习中,不同计算节点上的数据划分通常是均匀的,具有独立同分布的特点,这样的特性非常适合设计高效的训练算法,但真实场景下,各边缘节点收集的数据量由其覆盖的用户偏好决定,是不平衡的,因此各个节点的数据往往表现出不同的分布特征。
针对上述问题,本文在移动边缘计算的背景下,提出一种基于联邦学习的视频请求预测和视频协作缓存策略。利用已部署的多个边缘节点对提出的预测模型进行联合训练,在保证预测准确性的前提下提升了训练速度,减少通信成本,并使模型训练和直接访问原始数据解耦,减少隐私泄露的风险。同时,本文提出具有协作意识的缓存策略,进一步降低了时延,并通过减少不必要的冗余缓存提高了有限存储空间中的内容多样性,从而提高缓存命中率,降低缓存成本。为了验证方法的有效性,本文利用现实世界的公开数据集MovieLens[10],模拟了视频请求缓存场景。实验结果表明,本文提出的策略能有效提高缓存命中率,减小时延,并且降低通信成本。
2.1 网络架构
考虑如图1所示的云边协同网络,边缘节点通过无线蜂窝网络为覆盖区域内大量不同地理位置的移动用户提供服务,也可通过回程链路连接到云服务中心。其中,每个边缘节点都部署了用于计算和存储的边缘服务器,因此均能通过计算进行预测,从而提前主动缓存一些用户可能请求的内容,降低用户等待时延,从而提高用户体验质量(Quality of Experience, QoE)。用户可以通过边缘节点在本地获取请求内容,或者经由互联网服务提供商(Internet Service Provider, ISP)从云中心获取请求内容。

图1 网络结构
令N={1,...,n,...,N}表示边缘节点集合,每个边缘节点都设有一定的存储容量C,用于缓存内容。用户集合U={1,...,u,...,U}随机分布在各个边缘节点的服务范围内。F={1,...,f,...,F}表示用户请求内容的集合,每个内容f大小均为sf。具有不同大小的内容始终可以拆分为相同大小的数据段,每个数据段视为一个“内容”,这也是现实中常用的做法。对于视频内容,用户可能仅观看其中一部分,因此只需传输相应部分而非全部内容,从而降低传输延迟[11,12]。Rtn=[r1,r2,...]表 示边缘节点n在时间步t内收到的请求列表,其中ri表 示第i个到达的请求(i= 1,2,...), 并且每个请求r可表示为一个元组(u,f,c,tˆ),u ∈U,f ∈F,其中c表示请求的相关上下文信息,tˆ 为请求r到达的时间戳。在ISP可提供的内容库F中,任意用户u均能在任意时间,任意服务区域内对内容f发出请求r。
2.2 单个边缘节点的功能模块
图2展示了多个边缘节点协同工作时每个边缘节点所具备的功能模块。每个边缘节点通过用户接口模块,以时间步t为一个时间单位接收服务区域内用户发出的请求Rtn,并将请求信息存入本地数据库。边缘节点可以直接将接收的请求信息送入请求处理模块,并用训练好的预测模型对用户的未来请求进行预测(请求预测模块),然后联合邻居边缘节点利用预测信息协作地进行缓存决策(缓存决策模块),具体的协作缓存策略在3.2节详细描述。最后通过缓存管理模块决定在本地主动缓存的内容。由于用户可以不断进入或离开不同边缘节点的服务范围,并且不断有新的内容生成,用户对内容的需求不断变化,不同时期内容的流行度也不同,因此请求预测模型是时间敏感的。为了确保预测模型的有效性,需要适时用新的数据训练更新预测模型。因此当前的本地节点可以联合多个邻居边缘节点,通过联邦学习训练得到新的模型以淘汰过时模型,基于联邦学习的模型训练的具体过程见3.1.2节。

图2 单个边缘节点功能
3.1 基于联邦学习的视频请求预测
本节将主要介绍提出的视频请求预测模型、构造用于训练的数据集处理过程以及模型的训练和更新过程。
3.1.1 视频请求预测模型及数据处理
本文首先建立一个视频请求预测模型,该模型可根据用户对视频发出的历史请求信息预测视频在未来被频繁请求的概率,从而确定视频未来的流行趋势并得到值得提前缓存的视频列表。在本文的请求预测任务中,在分析真实数据集的基础上,提出了一种新的深度请求预测模型(Deep Request Prediction Network, DRPN),具体结构如图3。选择卷积层作为特征抽取器,在特征空间中提供多维输入数据的抽象表示。由于输入请求信息的时序性,在卷积操作后,选择递归神经网络(Recurrent Neural Networks, RNN)学习特征序列间的时间依赖关系。RNN在文本处理、流量预测等领域已被证明有效[13,14],Ale等人[15]也通过双向深层递归网络(Bidirectional Deep Recurrent Neural Network,BDRNN)预测在线活动缓存。在各种类型的RNN中,本文选择长短期记忆网络(Long Short-Term Memory, LSTM)作为递归层,因为它扩展了存储单元,有助于学习长期的时间关系,并在请求预测的问题上能获得很好的性能。图4显示了LSTM单元的内部结构,其主要思想是通过3个门来控制时间轴上的信息更新,从而在每个时间步获取信息。为方便表达,令单元状态为c,输入状态为x,隐藏状态为h,W表示相应权重矩阵,b表示相应偏置。在t时刻,一个LSTM单元包含3个输入:当前时刻的网络输入xt,上一个时刻的输出ht-1,以及上一时刻的单元状态ct-1,同时包含两个输出:当前时刻的输出ht和当前时刻的单元状态ct。遗忘门控制是否继续保留长期状态,即决定了上一个时刻的单元状态ct-1有多少保留到至ct。输入门控制是否将由上一次输出和本次输入计算得到的当前单元状态c′t送到长期状态中,即决定当前时刻将多少网络的输入xt保存到单元状态ct。输出门控制单元状态是否输出,即决定有多少单元状态ct将输出到LSTM的当前输出ht中。遗忘门、输入门、输出门、当前单元状态和输出的具体更新规则为

图3 DPRN 网络结构

DRPN模型包括卷积层、LSTM层和全连接层,用于模拟输入和输出之间的复杂非线性关系。图4展示了CNN_1将输入特征序列转换为结合了邻域信息的特征序列,并为LSTM_1提供输入的过程,也展示了LTSM_1的最后一次输出送到全连接层中进行分类的过程。最后,sigmod函数将网络输出转换为以概率形式表示的视频未来流行度pred_pop(视频在未来被频繁请求的概率)。


图4 LSTM 单元内部结构
在对原始数据进行预处理后,进一步构造可以用于训练预测模型的数据集。文献[4]表明请求数据具有一定序列关系。因此,对于每个视频,用一个时间窗口的数据来预测其在下一个时间步的流行程度。值得注意的是,一个时间窗口包含t¯个连续的时间步长,t¯为可调参数。每个时间步中的样本特征为( req,Preq, g enres )。定义流行内容为请求量排名在前20%的内容,则当某样本对应的视频在下一个时间步中符合流行内容的标准时,将该样本的标签记为1,否则记为0。因此,每个边缘节点n获得相应经过处理后的新数据集Dn,该数据集可用于训练预测模型。
3.1.2 模型训练及自动更新机制
由上一节可得数据集构造过程中,通过自主计算推断出数据特征和标签,而不需要人工打标签,并且每个边缘节点服务覆盖的用户不同,用户进行请求的频率也不同,所以每个节点n的 数据集Dn在数据量上可能存在较大差距,即数据分布不平衡。此外,请求数据来自各个用户设备,本身带有隐私性,数量庞大。这些特性都非常符合用于联邦学习[9]的数据特点。除此之外,随着边缘计算的发展,越来越多的边缘节点被部署在更接近用户的地方以提高QoE。因此,本文提出利用联邦学习机制对预测模型进行训练。




算法1 DRPN模型的分布式联邦训练

由于数据具有时效性,预测模型的精度会随着时间的推移而降低。此外,在真实的无线网络环境中,训练质量会受到数据包错误和无线资源可用性等因素的影响[16],这些因素都可能降低缓存命中率,导致模型失效。于是,提出一个自适应的模型更新规则以保证预测模型的准确性。用户发出请求后,边缘节点记录该请求最终被响应的位置,并以此计算一段时间内的平均缓存命中率。当缓存命中率低于设定阈值时,系统认为模型失效,并自动获取本地近期的请求信息进行数据处理,构造新的训练集,然后用新的数据去训练更新预测模型。
3.2 协作缓存策略
通过预测模型,每个边缘节点n可以利用最近一个时间窗口内的本地数据去预测下一个时间步的视频流行度,从而获得下一个时间步的视频预测列表Ln=[l1,l2,...], 每个l是 一个元组(f,sf,pred_pop),其中f为视频标识,sf为视频内容大小,pred_pop为视频在未来被频繁请求的预测概率,Ln是根据pred_pop降序排列得到的。相比于云中心,边缘节点普遍离用户更近,所以对用户来说,即使当本地节点没有提前缓存用户请求的视频,但其邻居边缘节点缓存了相应视频时,用户通过较短的查询时延后,仍然能以用户和边缘节点间较快的传输速度在邻居节点获取视频内容。为了尽可能减少时延,我们定义时延的减少量为收益,若采用枚举的方法来选出能带来最大收益的缓存策略,假设有F部影片(视频),N个节点,且每个节点可以容纳C个内容,那么对于每个节点来说,该节点的缓存策略数有CFC种,而对于N个节点,则总共会有(CFC)N种缓存策略,当F,C,N3个值增加时(尤其是N)会使得枚举过程的耗时急剧上升。因此需要更快且有效的方法来进行缓存决策,在联合多个边缘节点的情况下,本文提出一种基于贪心算法的协作缓存策略(Greedy algorithm based Cooperative Caching Strategy, GCCS),以尽可能降低时延为目的,并使本地节点和邻居节点协作地缓存一些重复内容,以节省更多空间缓存其他内容,增加内容多样性,进一步提高缓存效果。这对ISP来说,也一定程度上减少邻近区域内不必要的冗余内容,节约了缓存成本。提出的协作缓存策略GCCS具体过程如算法2所示,提出的协作缓存策略在预测得到的pred_pop(算法描述中记作c)的基础上利用贪心算法尽可能降低请求时延。在每一轮迭代中,考虑每个视频f存储到每个节点上的操作可能性,并考虑任一操作实际发生后,在未来接收到与请求预测结果相似的请求序列时,总体响应时延 t otal_gain所发生的变化。对每条预计发生的请求,若该操作会使其命中情况发生变化,则该操作将带来相应的时延收益(c或c )。因此,总体响应时延t otal_gain为对每个节点上的每条预计发生的请求计算得到的总体时延收益。然后选出能带来最大时延收益 best_gain的操作作为本轮迭代中所要执行的缓存操作。

算法2 基于贪心算法的协作缓存策略(GCCS)
4.1 数据集与实验设置
实验使用了公开数据集MovieLens,数据集包括283228个用户对58098部电影的27753444条评级以及电影的相关信息(如电影题材)。类似文献[3],假设评级总数和电影的请求总数相同,且用户对电影评级的时间与用户对电影发出请求的时间相同。为了模拟用户移动性,设置用户移动系数m=0.1,因此每经过一个时间周期T,边缘节点服务的用户将有占比为m的用户被随机替换。用户和云中心之间的传输速率为1~3 MBps,用户和边缘节点之间的传输速率为3~5 MBps。在每个通信轮次,系统随机选择比例为k=0.5的边缘节点参与训练,并将其对应的数据集中80%用于训练,20%用于验证,防止过拟合。对于每个选中参与联邦训练的边缘节点,设置其本地训练的轮次E=10,batch size =128,Adam为优化函数,学习率η=10-6。
4.2 评价指标
4.2.1 预测准确性
本文提出的协作缓存策略基于未来的视频流行度,即DRPN模型预测未来视频频繁被请求的概率。基于这个预测结果,边缘节点利用存储空间主动缓存那些未来可能被频繁请求的视频。因此,预测模型的准确性会影响缓存策略的性能。为了评价预测模型的准确性,本研究选择BCE来衡量预测误差,并使用归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)评估预测模型的性能。NDCG是一个常用的基于排名的指标,强调排名靠前的重要性。有较高请求的内容比较低请求内容更影响最终的指标得分,且高请求的内容出现在更靠前的位置时,指标越高,因此NDCG越高,指标越好。


同时,为了计算NDCG,还需计算理想情况下的最大DCG值(Ideal Discounted Cumulative Gain, IDCG)。因此根据真实情况下视频的请求数zi对列表重新降序排序计算IDCG

4.2.2 性能指标



为了更直观地展示算法的性能,定义了相比于边缘节点无缓存情况下,用户等待时延的降低率
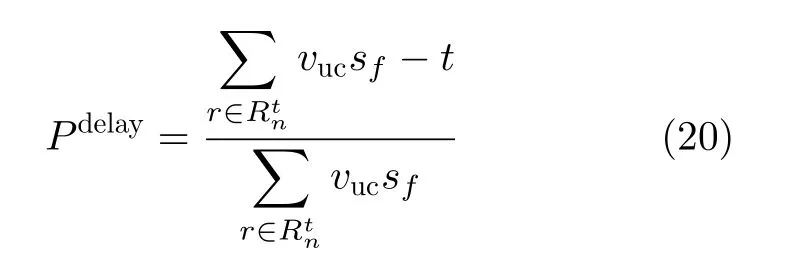
4.3 实验结果分析
为了证明基于联邦学习的视频请求预测的优势,本研究对比了DRPN模型在不同训练模式下的预测质量,包括中心式训练、联邦训练和本地训练。如图5所示,由联邦学习训练得到的模型能达到中心式训练得到的模型相近的预测质量。在请求数据规律性较强的时间段,联邦训练的效果甚至比中心式训练的效果更好,因为联邦学习在多个节点共同训练模型的同时权衡了全局数据特性和局部特性。本地训练只训练本地数据集,没有学习其他地区的视频流行度规律,因此无法适应用户移动性所带来的视频流行度的规律变化,整体效果不佳。由于用户请求的统计特性在不同时段存在变化,在请求数据规律性较弱的时段,如请求数量非常少的时段,NDCG的值也普遍会下降。

图5 不同训练模式下DRPN预测模型的训练质量(NDCG)
图6描述了DRPN预测模型在不同训练模式下的收敛过程。在中心式训练方法下,预测模型在第60个通信轮次才达到收敛,但在联邦训练方法下,预测模型使用较少的通信轮次就能稳定收敛到相同效果。实验结果表明,联邦学习下的DRPN的收敛速度比中心式训练快,并且通过增加边缘节点上的本地训练轮次可以进一步减少模型收敛所需的通信轮次,从而降低通信成本。对于边缘节点而言,相比于总数据集,本地的数据集较小,计算成本也较小,因此可以通过增加本地计算的方式来降低通信成本。

图6 DRPN预测模型在不同训练模式下的收敛情况
图7和图8对比了各种缓存策略在不同条件下的性能表现,其中LRU, FIFO和 LFU为经典缓存替换方法,Ideal为在已知当天请求量排序的情况下,依次缓存之前出现过且请求量较高的内容的结果,决定了预测方法在缓存性能上的理论上限,但由于当天的内容请求情况无法提前获得,实际系统中无法实现。为了保证实验的公平,在测试对比方法时,本研究同样允许边缘节点间存在协作性,各边缘节点间可以协作地响应用户发出的视频请求。
图7是不同缓存策略在部署3个边缘节点,不同缓存容量下的性能变化。从图7(a)和图7(b)可以看出本文提出的GCCS策略的平均缓存命中率和平均时延降低率均高于经典缓存策略。首先,DRPN预测模型可以更好地预测视频未来被请求的概率,从而为缓存策略提供良好基础。其次,GCCS通过贪心算法,以最大化时延收益为目的,让节点之间能够协作地完成本地缓存计划,不仅节省出更多空间来增加内容多样性以提高命中率,并且最大限度地降低了用户的等待时延。由于对时延的评价指标是降低率,因此即使是很小的提升,对于实际时延的影响依旧是很大的。此外,随着存储容量的增加,缓存性能指标也相应提高,这是因为有更多的空间来缓存相对不那么流行的视频,而在缓存空间受限时,GCCS策略很大程度缩小了缓存命中率与理论上限之间的距离。
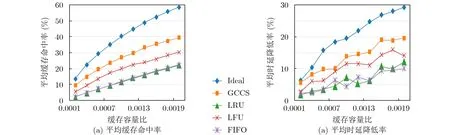
图7 不同缓存策略在不同缓存容量比下的性能指标
图8则展现了不同缓存策略在固定缓存容量比为0.0011,不同边缘节点部署数量下的性能变化。从图8可以观察到边缘节点数目的增加对传统缓存策略的影响较小,但对于本文提出的GCCS策略,增加一定数目的边缘节点则能明显提升性能。因为随着节点的增加,每个节点服务的区域范围缩小,使其训练得到的预测模型更具有针对性,对此区域内关于视频未来请求的预测也会更准确。但当节点数量不断增加至多个节点的服务范围之间开始重叠时,再增加节点并不会带来额外的信息收益,反而增加了部署和维护节点的成本,因此并非部署越多的边缘节点就能获得越好的效果,实际情况下应该通过权衡成本和性能来决定部署边缘节点的数目。

图8 不同缓存策略在不同边缘节点数目下的性能指标
本文在移动边缘计算的背景下,提出了基于联邦学习的视频请求预测和视频协作缓存策略。联合已部署的多个边缘节点对提出的DRPN预测模型进行联合训练,从而降低通信成本,同时保护请求数据的隐私性,并根据后续真实请求情况的反馈主动更新模型,保证预测模型的准确性。此外,本文以最大化时延收益为目标,联合多个边缘节点协作地进行缓存,不仅有效降低了整体时延,还可以节约缓存成本,在有限的缓存空间中储存更多的内容,提高缓存命中率。由于在多个边缘节点进行协作时,需要无线通信,在真实的无线环境中存在的不确定性可能影响模型预测的准确性,我们将在下一步工作中考虑更真实场景限制下,提高方法的可用性,并通过与差分隐私、多方安全计算等方式的组合,提供更强的隐私保护能力。
猜你喜欢 时延边缘节点 CM节点控制在船舶上的应用机械工业标准化与质量(2022年6期)2022-08-12基于AutoCAD的门窗节点图快速构建装备制造技术(2020年2期)2020-12-145G承载网部署满足uRLLC业务时延要求的研究通信电源技术(2020年8期)2020-07-21概念格的一种并行构造算法河南科技学院学报(自然科学版)(2020年2期)2020-05-22基于GCC-nearest时延估计的室内声源定位电子制作(2019年23期)2019-02-23VoLTE呼叫端到端接通时延分布分析信息通信技术与政策(2018年9期)2018-10-09一张图看懂边缘计算通信产业报(2016年44期)2017-03-13简化的基于时延线性拟合的宽带测向算法现代防御技术(2016年1期)2016-06-01抓住人才培养的关键节点中国卫生(2015年12期)2015-11-10在边缘寻找自我雕塑(1999年2期)1999-06-28推荐访问:缓存 联邦 协作