一种融合实体类别特征的医疗领域关系抽取方法
来源:优秀文章 发布时间:2023-02-10 点击:
游新冬,赵明智,王星予,徐戈,吕学强
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;
2.闽江学院 计算机与控制工程学院,闽江 350108;
3.福建省信息处理与智能控制重点实验室,闽江 350108)
关系抽取是要在包含两个或多个实体的句子中,抽取出其中每两个实体之间的关系及其类别。在当前大数据背景下,关系抽取可以帮助人们快速地从网络上繁多的医疗信息中获取所需信息,在构建知识图谱中也发挥了举足轻重的作用,逐渐成为了学者们研究的热点。
关系抽取任务的首次提出是在1998年的MUC-7会议[1]上,自此关系抽取得到了学术界的广泛关注。Wei等[2]提出一种抽取化学药品和疾病之间关系的方法,但效果不是很理想。张玉坤等[3]提出将卷积神经网络(convolutional neural network,CNN)与支持向量机、条件随机场相结合的联合神经网络模型,分别通过任务联合、模型联合和特征联合对关系抽取任务进行联合学习,在药品说明书语料库中效果显著。罗计根等[4]提出了一种融合双向长短时记忆(bidirectional long short-term memory,BiLSTM)人工神经网络和梯度下降决策树(gradient boosting decision tree,GBDT)的关系识别算法(BiLSTM-GBDT),在中医等多个语料库取得了比较精确的结果。宁尚明等[5]提出recurrent+transformer的方法,针对电子病历文本的特点,设计多通道注意力三层核心网络结构,并且提出类别权重的计算方法,相比传统的注意力机制,强化了对句级别语义特征的提取,整体复杂度显著降低,缺点是计算效率低。武小平等[6]提出改进的双向变形编码器卷积神经网络,对心血管疾病的中文语料进行关系抽取,使用基于Transformer的双向编码器表示(bidirectional encoder representation from Transformers,BERT)模型解决了长期依赖问题,但对输入数据的顺序与位置问题考虑不全面。高峰等[7]提出了一种基于规则和词频分析的关系抽取方法,第一轮使用规则聚类的方法抽取关系发现词,第二轮采用补充算法抽取关系发现词,将发现词作为额外特征送入模型进行医疗关系抽取,由于人工和语料规模的限制,有的句子无法抽取出关系发现词。
以上的关系抽取方法中,都存在着大量的关系重叠[8]问题,即同一实体处于多种关系中。例如:在“心肌酶增高提示为心肌炎表现为心慌”文本中,“心肌炎”实体同时出现在(心肌酶,升高,心肌炎)和(心肌炎,表现,心慌)两组关系中。针对此问题,本文提出一种融合实体类别的医疗领域关系抽取方法——CBBS(category BERT BiLSTM Sigmoid),在关系抽取任务中融入实体类别特征,并通过序列标注的方法,有效解决了关系重叠问题,提升了关系抽取的效果。
本研究构建了一个医疗领域关系抽取人工标注语料库:将医疗领域文本分别进行实体类别标注和关系标注;
然后使用CBBS方法对语料库进行关系抽取。
CBBS方法模型结构如图1所示。首先第一层是输入层,如图1中输入样例“[CLS]白细胞增多为肾炎[SEP]”;
将输入样本采用BERT模型进行向量化操作;
然后将向量输入BiLSTM层进行特征提取[9],对应识别出实体标签序列,ki(i=1~10)为长短时记忆(long short-term memory,LSTM)单元,经过双层LSTM单元,得到对应的向量特征Pi(i=1~10);
标签嵌入(Label Embeddings)层将标签计算为对应的向量,与Pi进行拼接,最终在分类层使用Sigmoid函数得到关系抽取结果。
CBBS方法模型结构设计分为4个部分:实体关系类别;
序列标注;
BERT模型进行向量化操作和 BiLSTM模型提取特征部分。在实体关系类别部分对医疗领域中的检验指标、疾病、症状这3类实体间的关系进行定义,但发现在医疗领域文本中常常会出现关系重叠问题,对此采用序列标注的方法,此外还标注了实体类别特征,提升关系抽取效果。为了获取到更加丰富的语境信息,本文采用 BERT模型进行向量化操作,提高生成的字向量的准确性,将生成的字向量输入BiLSTM模型提取特征,最终实现分类,抽取出医疗领域实体间的关系。每一部分具体设计介绍如下。
1.1 实体关系类别
医疗领域中的关系抽取主要是抽取检验指标、疾病、症状这3类实体间的关系。在进行关系抽取之前,首先需要对所需抽取的实体间的关系类别进行定义。本文构建出所研究的医疗领域实体间关系类别表,如表1所示,即检验指标、症状、疾病实体间的“包含、升高、降低、阳性、表现、检查、并发、进展、可能”关系。

图1 CBBS方法模型结构

表1 关系类别表
1.2 序列标注
在进行医疗领域关系抽取研究中,首先要对医疗文本进行预处理操作:对获取到的文本进行序列标注。而采用不同的序列标注方法,将会直接影响到抽取出的关系及关系抽取结果的准确性。
在医疗领域文本中,常常会出现关系重叠问题,即在单条语料中同一医疗实体往往存在于两种及两种以上的多种关系中。针对这一问题,本文通过序列标注,对文本中的每个字定义标签类别,有效解决了医疗领域文本中存在的关系重叠问题,标注样例如表2所示。
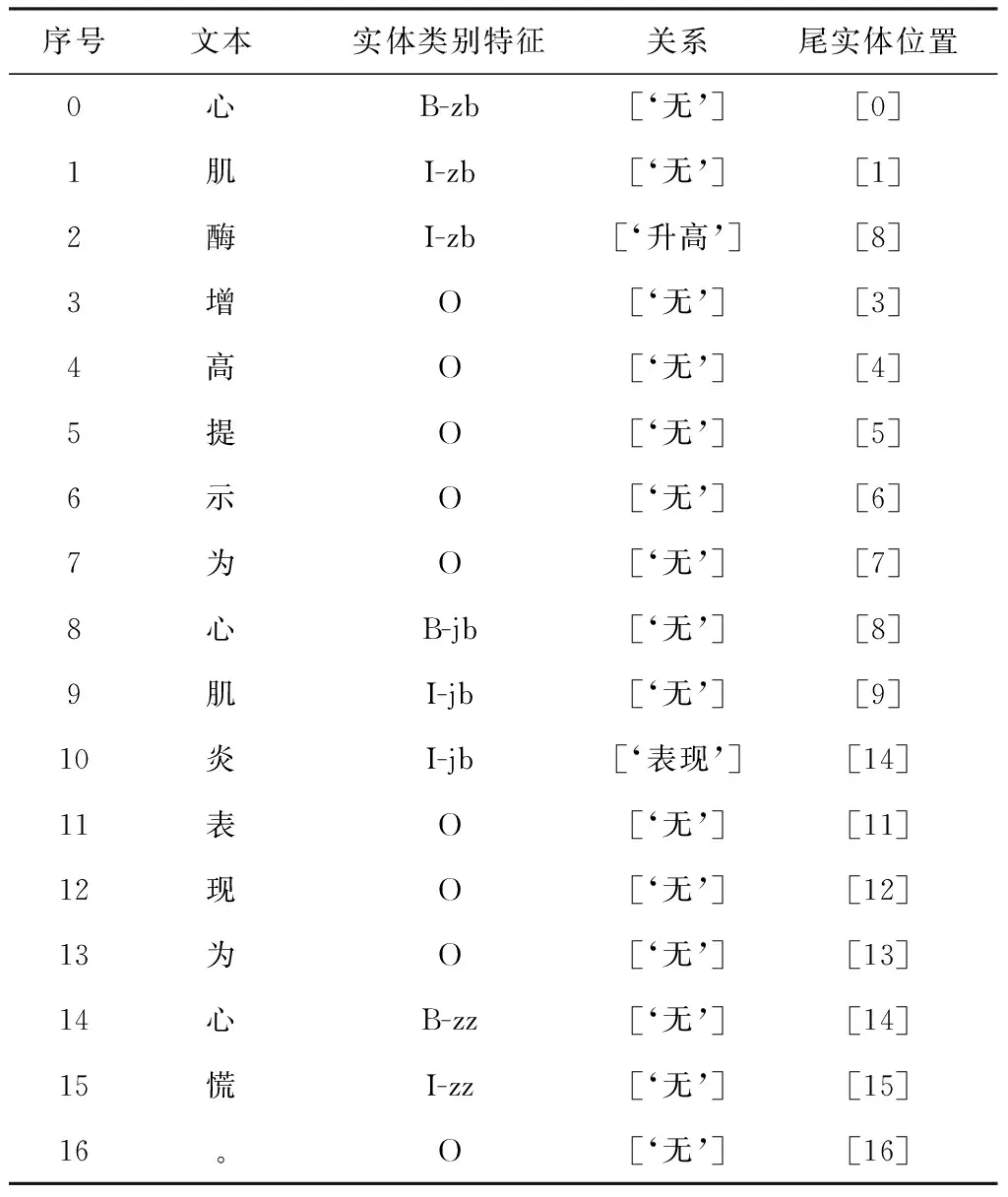
表2 标注样例表
在进行序列标注的过程中,添加标注了实体类别特征,如表2中第3列所示:“O”为非实体、“B”为医疗实体的开始字符、“I”为非头实体,“-”后代表了实体所属的类别,其中“zb”代表实体类别为检验指标、“jb”代表实体类别为疾病、“zz”代表实体类别为症状。根据医疗实体所属类别来辅助判断医疗实体间的关系,提高医疗实体间关系的抽取效果。
表2中第4列标注了医疗实体间存在的关系,所属关系标注在头实体的最后一个字符的位置,如果存在某种关系,则标注出尾实体的位置,如表2中第5列。采用这样的标注方法可以有效解决医疗领域文本中存在的关系重叠问题,如示例文本中存在(心肌酶,升高,心肌炎)和(心肌炎,表现,心慌)两个三元组,采用本文方法中的标注方式,可以准确地提取出这两个三元组。
1.3 BERT模型
本方法采用BERT模型[10]进行向量化操作。BERT模型采用了双向Transformer[11]的编码结构,在进行编码时,可以根据前向和后向两个方向的文本内容,获取到丰富的语义信息,能够提高生成的字向量的准确性,进而提升医疗关系抽取的效果。
对本研究而言,BERT模型可以获得较长距离医疗文本间的依赖关系,得到更高质量的向量化结果,为医疗关系抽取任务提供支撑。BERT模型字向量生成图如图2所示,将已标注的医疗文本Xi(i=1~6)输入BERT模型,经过字嵌入、句子嵌入以及位置嵌入这3个嵌入(Embedding)操作,再将这3个Embedding对应位置生成的结果组合起来,最终得到医疗文本的向量Ei(i=0~8)。

图2 BERT模型字向量生成
1.4 BiLSTM-Sigmoid模型
循环神经网络(recurrent neural network,RNN)内部结构如图3所示。RNN使用当前节点的输入和前一节点的输出进行计算,得到隐藏层输出,这一输出将提供给下一个节点使用。RNN能够对之前时刻的语义信息进行记忆,同时这部分记忆也会影响当前时刻的输出,因而循环神经网络在处理语义关系复杂的文本序列时,能够达到较好的处理效果,得到富有语义信息的输出结果;
但从其输入过程可以看出,RNN只能从前向后处理单项文本信息,无法融入下文信息。
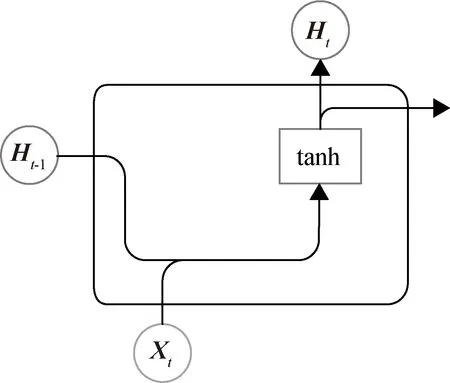
图3 RNN内部结构
BiLSTM[12]中输入层的数据会经过向前和向后两个方向推算,最后输出的隐含状态再进行拼接,再作为下一层的输入。针对医疗文本表达内容丰富多样的特性,本文采用BiLSTM模型对医疗实体间的关系进行抽取。
Sigmoid函数又被称为Logistic函数,函数表达式如式(1)所示,其中x为BiLSTM与Label Embeddings拼接得到的向量值。Sigmoid通过把得分结果转换为(0,1)范围内的概率值,进一步实现分类。Sigmoid在处理分类问题中有着计算量小、收敛速度快等优点,因此本文采用Sigmoid作为分类层实现医疗领域实体间关系抽取。
(1)
2.1 数据集的构建
由于中文医疗领域关系抽取任务的数据集较少,且未有符合本方法的数据集,因此需要构建一个适合本研究的医疗领域关系抽取数据集。
数据集的构建方法如下:首先需要获取医疗领域非结构化数据,针对医疗领域对数据的准确性要求较高的特点,本实验中的数据来源于可靠的医疗教材与较为权威的专业性医疗网站,如快速问医生和39健康网上医生的解答等。获取到的实验数据共有3 295条,每条数据长度为20~60个字符。然后将实验数据按照本文1.2节中介绍的序列标注方式进行标注。实验数据样例如图4所示。数据集关系类型数量表如表3所示。

图4 实验数据样例

表3 医疗关系抽取数据集关系类型数量表
2.2 评价指标
本文采用精确率(P)、召回率(R)和F1值来评价本方法的有效性,验证CBBS方法在医疗领域数据集上的关系抽取效果。其中精确率、召回率和F1值的计算如式(2)、(3)、(4)所示。
(2)
(3)
(4)
式中:nTP为识别正确的关系总数;
nFP为错误关系识别为正确的关系总数;
nFN为识别错误的关系总数。
2.3 对比实验
医疗关系抽取实验使用本文构建的医疗领域关系抽取数据集,实验在Ubuntu16.04操作系统上运行,使用32 G Tesla V100显卡,Python版本为3.6,深度学习PyTorch框架版本为1.10。
为了验证本文方法的有效性,将其与现有的医疗文本关系抽取方法进行对比,实验结果如表4所示。
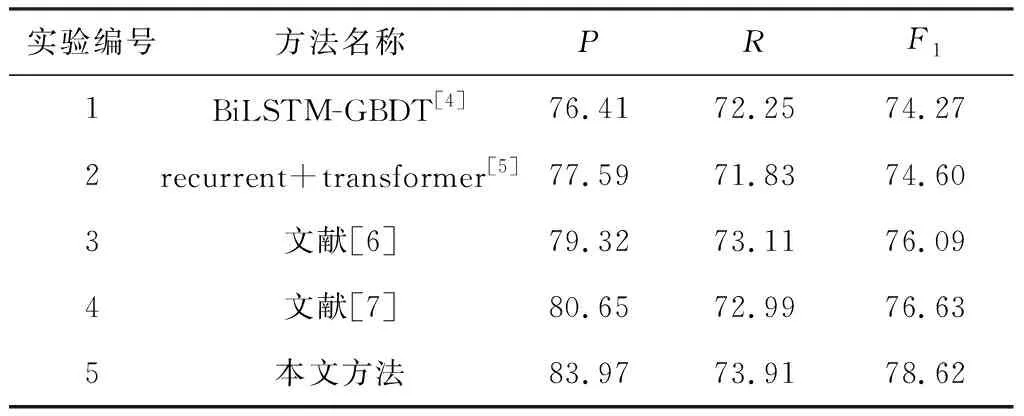
表4 对比实验结果 %
实验1采用文献[4]中的BiLSTM-GBDT方法,该方法由GBDT和BiLSTM组成。BiLSTM模型一直沿用至今,证明了其性能是比较好的。最终的实验结果F1值达到了74.27%。
实验2使用文献[5]中的recurrent+transformer方法,transformer中使用的注意力机制区别于传统深度学习方法,引入了Q、K和V向量矩阵,能够挖掘深层次的语义信息;
相较于实验1,精确率提升了1.18个百分点;
但召回率略低于实验1,最终的F1值提升仅为0.33个百分点。
实验3为对比文献[6]中的BERT(wwm)-CNN方法,该方法使用了自然语言处理领域“里程碑”式的BERT模型;
在实验结果中精确率、召回率以及F1值都有提升,且提升效果明显;
相较于实验2,F1值提升了1.49个百分点。
实验4设计为文献[7]中的方法,该方法融合关系发现词和BiGRU-2ATT模型来进行关系抽取,证明了关系发现词在关系抽取中是有一定效果的,但是效果提升并不明显;
与实验3对比而言,召回率反而有一定的下降,最终的F1值仅提升了0.54个百分点。
实验5为本文提出的CBBS方法,本文方法首先融入了实体类别特征,然后采用BERT-BiLSTM-Sigmoid模型进行医疗领域关系抽取。
从实验结果来看,无论是精确率、召回率还是F1值,本文方法在所有实验方法中均取得了最好的成绩。
2.4 消融实验
在模型的结构上,本文还设计了消融实验,实验结果如表5所示。

表5 消融实验结果 %
实验1采用较为基础的BiLSTM模型进行医疗关系抽取,BiLSTM模型常用于解决关系抽取问题。
实验2在实验1的基础上采用Word2Vec进行向量化操作,再由BiLSTM模型抽取医疗实体间的关系。在BERT模型出现前Word2Vec是十分常用的向量化操作模型。通过对比实验1发现,实验结果略有提升,其中精确率和F1值提高较少,分别提高了0.65和0.33个百分点;
召回率提升最多,较实验1提升了1.37个百分点。
实验3采用BERT-BiLSTM模型实现医疗领域的关系抽取,与实验2相比使用了不同的向量化模型。目前BERT模型被广泛应用于信息抽取等自然语言处理任务中,并取得了不错的效果,因此采用BERT模型进行向量化操作。实验结果提升明显,针对于实验2在各个评价指标上提升均超过了3个百分点,证明了采用BERT模型进行向量化操作,能够更好地获取文本中的语义信息,提高生成字向量的质量,从而得到更好的效果。
实验4为本文方法。本文方法是在实验3模型的基础上融合了医疗实体类别特征。实验结果对照实验3有所提升,其中召回率提升了2.75个百分点,F1值提升了2.11个百分点。验证了医疗实体类别特征对关系抽取任务有着积极的作用,证明了本文研究方法设计的合理性。
通过以上消融实验可以发现,本文方法在各项评价指标上都得到了最好的成绩,可见本文方法能够有效解决医疗领域关系抽取问题,提升医疗领域关系抽取的效果。
本文提出的CBBS方法,融合了实体类别特征,采用BERT-BiLSTM混合模型对医疗领域实体间的“包含、升高、降低、阳性、表现、检查、并发、进展、可能”关系进行抽取,CBBS方法抽取出的医疗领域实体间关系样例展示如表6所示。通过融合实体类别特征来辅助关系抽取任务,提高了医疗领域关系抽取的效果,因此本研究提出的CBBS方法是可行的。

表6 本文方法关系抽取结果样例展示
本文方法融合医疗领域实体类别特征,采用BERT-BiLSTM-Sigmoid模型实现了医疗领域在检验指标、症状和疾病实体间的关系抽取。通过对比实验,表明本文方法能够有效解决医疗领域关系抽取问题;
同时也通过消融实验证明了本文研究方法设计的合理性。在后续的研究过程中,需要进一步研究医疗领域关系抽取中的实体重叠问题。