MCP-Logistic模型在银行客户流失数据的应用
来源:优秀文章 发布时间:2023-01-26 点击:
林怡婷,蔡 涛,邓喜珊,张天羽,张婷婷,王延新
(宁波工程学院 理学院,浙江 宁波 315211)
大数据时代,众多数据呈现海量、高维、复杂等特点,这使得传统的统计方法受到巨大挑战。高维数据变量选择成为现代统计的前沿热点问题,解决高维数据稀疏化的最有效最常用手段是基于罚函数的正则化方法。近20年来,统计家们提出了很多罚方法同时进行变量选择和参数估计。目前较为流行使用的惩罚函数主要有Lasso、SCAD[1]、MCP[2]以及这三者的衍生。刘建伟等[3]总结了多种正则化稀疏模型,曾津等[4]介绍了多种处理高维数据的变量选择方法;
他们均提到了Lasso、SCAD和MCP具有较强的变量选择能力。但Lasso方法是有偏估计,而SCAD和MCP罚方法具有无偏性、稀疏性和连续性。相对SCAD估计而言,MCP变量选择的结果更加稀疏。
Logisitc回归模型常常用于分类问题,但在高维情形下,会出现估计结果不稳定的问题。进而,基于惩罚函数的Logistic回归模型被提出并得到广泛应用,该模型可以有效克服参数估计的不稳定性和模型过拟合问题,同时进行变量选择和参数估计。
鉴于上述原因,本文提出基于MCP罚的Logistic回归模型,并以某商业银行客户流失历史数据为例探究MCP-Logistic模型选取变量的能力以及预测效果。特别地,在正则化参数选择方面,提出一种正则化参数直接给定方法,不需要预调节,极大减少了计算量。在实际数据分析中,将MCP-Logistic模型与基于Lasso、SCAD的Logistic模型以及决策树模型[5]对比,验证本文提出方法的有效性。
(1)MCP-Logistic模型
MCP方法是在所有满足无偏性条件的惩罚函数中,拥有较好的理论性质的一种方法。ZHANG[2]证明了MCP是一个近似无偏稀疏的方法。李春红等[6]证明了MCP估计的渐进正态性。MCP适合应用于自变量相关性较高的情形,特别是在处理相关性较高变量都是重要变量的数据结构,当一个很强的变量被选入模型之后,其他相关变量就很难进入模型。MCP回归随着βj的增大,惩罚力度从λ逐渐减少至0,对回归系数采取有差别的惩罚,以此来得到更精确的估计。
设有独立同分布的观测(xi,yi)(i=1,2,…,n),其中xi=(xi1,…,xip)T是解释变量,记X=|x1,…,xn|为预测矩阵,y=(y1,…,yn)(yi∈{0,1})是二元响应变量,β=(β1,…,βp)T表示模型的回归系数。因此,Logistic回归模型的MCP估计为:

上式中,MCP的惩罚函数定义为:

其中λ≥0,γ>1。当对MCP的惩罚函数进行一阶求导时,可得到

从上式可看出:随着βj逐渐增大时,惩罚力度呈线性下降;
而当βj>γλ时,惩罚力度为0。这一结果说明MCP满足了稀疏以及无偏性的特征。
(2)Lasso-Logistic模型和SCAD-Logistic模型
Lasso是通过在RSS最小化的计算中加入一个l1范数作为惩罚项对系数进行压缩。Lasso估计的优点在于可以同时进行变量选择和参数估计,缺点在于对回归系数的全部分量都进行相同程度的惩罚,这导致了对目标变量回归系数的有偏估计。Lasso-Logistic模型如下:

由于Lasso不具备变量选择的Oracle性质,FAN和LI[1]提出一种无偏估计方法,即SCAD。基于SCAD估计的Logistic回归模型为:

其中,SCAD的惩罚函数定义为:

(3)决策树模型
作为对比,本文利用CART分类树模型,其算法使用基尼系数来代替原先经典算法(比如ID3、C4.5)的属性度量标准,即通过计算模型的不纯度作为分类的标准。当基尼系数越小,不纯度越低时,代表该特征选择得越好。
设样本X的个数为N,共有K个类别,且第k个类别的数量为nk,第k个类别的概率为,则样本X的基尼系数的表达式如下:

若根据特征A将样本X分成X1和X2,则在特征A条件下,样本的基尼系数表达式为:
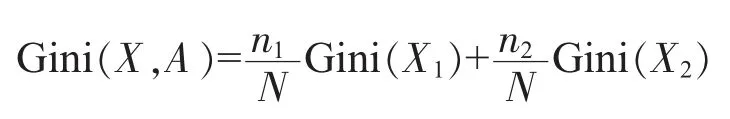
2.1 正则化参数选择
对于MCP、Lasso和SCAD这3种正则化方法,常见的正则化参数选取方法有:交叉验证CV和信息准则IC[7]。交叉验证是一种评估模型的泛化能力的方法,统计学界还细分了多种交叉验证方法:简单交叉验证、留一交叉验证、K折交叉验证、自助法等[8]。
但以上方法需要实现给定一系列正则化参数,然后根据以上准则选择最优正则化参数值,存在计算量大的缺点,而且CV方法容易出现模型过拟合现象。本文提出正则化参数给定方法如下

其中,n表示样本量,p表示数据的维数,ε>0取值为0.05或者0.01,c为给定常数。利用公式(4),正则化参数无需调节(tuning free),故我们称该方法为TF方法。同时,作为对比,本文选用CV方法来选取罚Logistic模型的正则化参数。
2.2 模型评价标准
对分类模型进行评估的常用指标主要是混淆矩阵和ROC曲线、AUC面积。混淆矩阵是衡量分类型数据模型准确度中最基本,最直观,计算最简单的方法,也是绘制ROC曲线的基础。从混淆矩阵可衍生出很多指标,常用的指标有准确率ACC和F值。准确率ACC指的是分类模型中判断正确的结果占总观测样本的比重;
精确率PPV指的是真正例占预测为正例样本的比重;
召回率TPR指的是真正例占真实情况为正例样本的比重;
F值指的是精确率PPV和召回率TPR加权调和平均数。一般来说,ACC、PPV、TPR、F值越接近1,模型越好。表1为评价指标的公式表:

表1 评价指标公式表
ROC曲线的纵坐标是真正例率(TPR),横坐标是假正例率(FPR)。AUC值为ROC曲线下方的面积求和,其范围在0到1之间,若AUC值越接近1,说明模型的泛化能力越好。本文将主要从准确率ACC、F值和AUC值来综合评价银行流失客户预测模型的能力。
本节将对银行客户流失预警进行实证分析,并且通过不同的模型评价标准来比较各模型的预测能力与变量选择能力。算法方面,Lasso、SCAD和MCP估计使用R软件中的glmnet包实现,决策树利用rpart包实现。正则化参数选择方面,利用TF方法和CV方法。
3.1 数据预处理
1)异常值处理
本文数据来自某商业银行客户流失历史数据[9],该数据集中包含17 241条样本,50个字段。这些字段主要包括客户基本信息和业务指标两个方面。其中客户信息指标主要包括开户时长、性别、年龄,业务指标包括存款笔数、交易金额、交易笔数等。在各变量中,由于本币活期月均余额占比与本币定期月均余额占比之和为1,因此删去冗余变量本币活期月均余额占比。此外,手机银行交易总数这一变量的值均为0,因此删去该变量。
2)特征构造
由于原始信息可能对因变量产生的影响不够显著,因此通过构造衍生变量的方法,使得新变量具有商业意义,并能够提取出有用的信息。表2展示了部分衍生变量的构造方法,这些特征对目标变量相关且具有实际意义。

表2 部分衍生变量的特征构造公式表
特征构造后数据集的字段增加到69个。在确定自变量的个数之后,为了避免由于变量间量纲的不同造成模型的误差,事先将各指标变量进行标准化处理。
3.2 类别标签不平衡处理
银行客户流失数据往往是非平衡二分类数据集,即数据中的响应变量分布不均衡,响应变量值为0的观测数目远远大于响应变量为1的观测数目。常用样本平衡的处理办法是欠采样法、过采样法、人工数据生成法和代价敏感学习。欠采样主要是减少来自多数类的观测值,从而达到数据集的平衡,其缺陷就是可能损失大量信息。过采样主要是增加来自小数类的重复观测值,其缺陷就是容易出现过拟合的现象。
由于欠采样法与过采样法均有明显的缺陷,因此本文通过欠采样与过采样相结合的方式解决二分类数据集不平衡的问题,利用R软件中的ROSE包可实现数据集的处理。
3.3 MCP方法的模型结果及比较分析
通过坐标下降算法估计MCP-Logistic模型参数,通过TF方法选择正则化参数。模型估计结果如表3所示。

表3 MCP-Logistic非零参数估计表
由表3可知:MCP估计在选择变量后得到了7个重要变量的估计系数。从结果来看,本币活期月均余额、本币定期销户总金额、本币总取款笔数这3个指标的数值越大,银行客户流失的可能性越大。其余的4个负系数值对应的指标值越大,银行客户流失的可能性越小。其中,本币活期存款总余额、本币总取款笔数是左右银行客户流失的重要因素。该结果比较符合实际。
接下来分别对MCP-Logistic模型、Lasso-Logistic模型、SCAD-Logistic模型和决策树模型进行模型评估。表4给出了不同模型的效果比较表:

表4 模型评价指标结果表
由表4可知:一方面,通过正则化参数选取方式的对比,发现利用TF方法确定的正则化参数在压缩变量方面具有显著的优势,选择了更加稀疏的模型;
而从预测效果方面,在CV方法和TF方法下,3类正则化方法的准确率、F值及ACU值各指标取值相当。
另一方面,通过模型之间的对比,可发现MCP-Logistic模型在高维变量选择和预测方面都表现出较为良好的性能。从压缩变量程度来看,MCP-Logistic模型和决策树模型对处理自变量高相关性的效果均较好。从准确率与AUC值来看,Lasso-Logistic模型的准确率略高于其他模型,MCP-Logistic模型的AUC值略高于其他模型,4种模型的准确率与AUC值相差不大,因此不能判断模型的优劣。由于该数据集更注重的是正确预测客户流失数,因此单从准确率和AUC值来判断模型优劣是不合理的,而F值是精确率PPV和召回率TPR加权调和平均数,所以本文通过F值(β取2)来判断模型的预测分类能力,使得结果在保证精确率PPV的条件下,尽量提升召回率TPR。从F值来看,MCP-Logistic模型的F值较大,尤其是决策树模型的F值远不如MCP估计下的模型,因此可认为MCP方法具有更好的预测分类能力。
综合上述的结果分析,可以得出MCP估计的Logistic回归模型在处理高维数据变量选择问题方面具有较好的效果。
本文主要探究MCP-Logistic模型在银行客户的流失情况分析中的应用,并提出了正则化参数的确定方法。从研究结果来看,MCP-Logistic模型最终选取得到7个重要变量的系数估计以及计算得到F值为0.421 0,这说明该模型对于高维数据变量的压缩效果更好,且具有较好的分类预测能力。
猜你喜欢 高维正则惩罚 基于相关子空间的高维离群数据检测算法计算技术与自动化(2022年1期)2022-04-15π-正则半群的全π-正则子半群格兰州理工大学学报(2021年3期)2021-07-05Virtually正则模兰州理工大学学报(2021年3期)2021-07-05双冗余网络高维离散数据特征检测方法研究宁夏师范学院学报(2021年1期)2021-03-18基于深度学习的高维稀疏数据组合推荐算法计算机技术与发展(2020年2期)2020-04-15带低正则外力项的分数次阻尼波方程的长时间行为南京大学学报(数学半年刊)(2020年1期)2020-03-19神的惩罚小读者(2020年2期)2020-03-12Jokes笑话阅读(快乐英语高年级)(2019年11期)2019-09-10任意半环上正则元的广义逆上海师范大学学报·自然科学版(2018年3期)2018-05-14高维洲作品欣赏世界知识画报·艺术视界(2017年7期)2017-07-27推荐访问:流失 模型 客户