深度学习在webshell检测中的应用研究
来源:优秀文章 发布时间:2023-01-24 点击:
邓全才 郭雅静 张子翼
(河北建筑工程学院数理系,河北 张家口 075000)
Web应用(网站)已渗透到电子商务、教育、社交网络等众多领域.网络入侵事件时有发生,当黑客入侵成功后,WebShell被攻击者上传至Web服务器,用于控制Web服务主机,非法访问网站资源,甚至控制具有Web功能的关键设施,严重威胁着国家网络空间安全,Web的安全问题变的日益严峻.因此,对WebShell检测技术的研究是有必要而且有意义的[1].
1.1 WebShell产生原因
Web通常具有允许用户进行文件上传、下载的功能.但是,如果下载检测程序未严格检测下载文件的格式,或者服务器软件中有解析漏洞,那么它就可以使黑客能够下载WebShell并对其进行解析,从实现对网站的控制.WebShell是一种可以进行文件操作和命令执行的恶意程序.WebShell通过Web服务获得Web服务器的管理权限,从而对Web服务器进行深入渗透和控制.WebShell中“Web”指Web服务器的服务功能,“Shell”指为使用者提供服务的一些操作权限,如文件管理、数据库连接、命令执行等.
1.2 WebShell分类及其攻击原理
WebShell根据脚本可以分为PHP脚本木马,ASP脚本木马, .NET脚本木马、JSP脚本木马、以及与python网页相关的WebShell.攻击者在入侵一个Web站点时,将这些脚本文件上传至Web服务器目录下.通过浏览器访问的方式,访问脚本文件的同时,可以控制Web服务器[2],如果Web权限比较高,甚至可以直接运行系统命令.WebShell具体分类如图1所示[3].

图1 WebShell分类
1.3 WebShell的作用
WebShell主要有两方面的作用[4],一是用于Web服务器的管理等;
另一方面可以被入侵者利用,从而达到控制目标服务器的目的.除了以上作用外,WebShell还有其它更多丰富的功能:探测服务器上是否存在其他WebShell、连接数据库、集成其它提权工具等.WebShell作为一个恶意动态脚本,具有隐蔽性,可以利用服务器漏洞进行隐藏,其通信和普通网页一样都是通过服务器软件端口(默认为80端口),因此不会被防火墙拦截.
2.1 ADFA-LD数据集
ADFA-LD数据集[5]是澳大利亚国防学院对外发布的一套主机级入侵检测系统的数据集合,被广泛应用于入侵检测类产品的测试.ADFA-LD数据集已经将各类系统调用完成了特征化,并针对攻击类型进行了标注,其中攻击类型为WebShell的数据集放在ADFA-LD文件下,数据集分为三组,每一组都包含了原始系统调用顺序.每个训练集(Training_Data_Master)和验证集(Validation_Data_Master)的数据都是在主机的正常操作过程中收集的.其中训练集数据大小在300比特到6kb之间,验证集数据在300kb到10kb之间.攻击数据集(Attack_Data_Master)里共有6种攻击方式.
2.2 数据预处理
用x=和y=两个变量分别存储正常数据和异常数据,并设置正常数据标签为0,异常数据标签为1.通过train_test_split函数随机分配训练集和测试集,训练集数据和测试集数据的比例为7:3,random_size:设置随机数种子,通过设定为相同的数值,使每次分割的结果都相同,具体实现如下所示.
x_train,x_test,y_train,y_test=train_test_split(x,y,test size=0.3,random_state=9)
测试数据使用和训练数据一样的词汇表:使用词袋模型转换为系统调用向量.运用词袋模型,把所有的词汇装到一个袋子里,不考虑其词法和词序的问题,即每个词汇都是独立的.权重只与每个单词出现的频率有关.词袋模型会先进行分词,通过统计每个词汇出现的次数,就可以得到该文本基于词汇的特征,将文本中的词汇与其对应的词频放在一起即为向量化.
采用Pytorch分别构建BP神经网络和LSTM神经网络模型.Pytorch是一个开源的Python机器学习库,一个以Python优先的深度学习框架.
3.1 BP神经网络
BP神经网络的层数设为4层,其中隐藏层层数为2层,第1层隐藏层有100个神经元,第2层隐藏层有50个神经元.激活函数为logistic函数,也就是sigmoid函数,权重优化采用随机梯度下降算法,最大迭代次数为100.初始学习率设置为0.001.
3.2 LSTM神经网络
模型的具体实现步骤如下:
1.定义LSTM神经网络模型,通过继承nn.Module类来实现.同时,定义输入x的特征维度为124,隐藏层的层数默认为1,隐藏层的特征维度(隐藏层神经元)为100.创建LSTM层提取特征和Linear层用作最后的预测,LSTM算法通过三个不同的因素来控制之前信息对当前信息的影响:先前的隐藏状态,先前的单元状态和当前输入.
2.定义好每层之后,通过forward函数以前向传播的方式将相邻的两层串起来,即如何根据输入x计算返回所需要的模型输出.forward函数的任务需要把输入层、隐藏层、输出层连接起来,该函数的参数一般为输入数据,返回值是输出数据.
3.将数据集转换为tensor,Pytorch使用张量tensor存储数据,并将训练数据转换为输入序列和相应的标签.
4.模型训练:设置迭代次数为100次.每组数据有20个,学习率为0.001.enumerate函数用于在循环中得到计数,利用它可以同时获得索引、步数和值.梯度初始化为0,应用反向传播求梯度,防止梯度爆炸或者梯度过小时,设定阈值,当梯度小于/大于阈值时,更新的梯度为阈值.设置步长为5,选取softmax函数作为分类函数,softmax可以更好的处理多分类问题.该函数将多个神经元的输出映射到大于0小于1的区间内,输出是属于各个分类的概率,在最后选取输出结点的时候,选取概率最大(多分类的输出值对应最大值)结点,作为预测目标.
实验环境:操作系统为Windows 10,内存8G,CPU:Intel(R)Core(TM)i5-10210U CPU@1.60GHz 2.11 GHz,开发语言为Python3.6,BP神经网络、LSTM神经网络检测WebShell实验结果如图2、图3所示.

图2 BP神经网络模型实验结果
从图2可以发现,BP神经网络虽然设置的最大迭代次数为100次,但是由于连续10个周期针对损失降低不超过0.001,故程序只迭代了61次,经过训练测试模型loss值在0.03左右摆动,模型最终在测试集准确率为:95%.
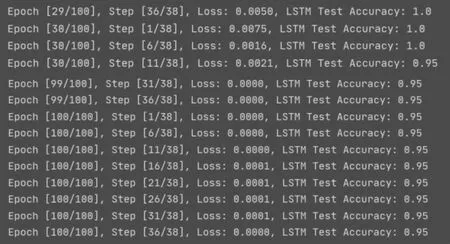
图3 LSTM神经网络模型实验结果
图3截取了LSTM模型训练测试中间结果和最终结果,可以发现模型loss值很小,模型在测试集上中间出现准确率为100%的情况,然后随着数据量的增加准确率稳定在了95%.
综合上述分析,BP、LSTM两个模型能较高准确率检测出WebShell的存在性,说明构建的两个神经网络模型在模型结构、参数设置较合理,但是从结果来看BP模型的loss值高于LSTM模型loss近10倍,但两个模型检测精度最终均为95%,对于模型的解释性有待进一步研究.
本文针对Web站点存在的安全问题,WebShell进行了介绍.通过构建两种不同的深度学习算法模型,分析了基于BP神经网络和LSTM网络的两种WebShell检测技术,为后续WebShell检测技术的研究奠定了基础.
猜你喜欢 脚本梯度服务器 酒驾作文小学中年级(2022年11期)2022-11-25磁共振梯度伪影及常见故障排除探讨中国设备工程(2022年19期)2022-10-12服务器组功能的使用网络安全和信息化(2020年9期)2020-12-31理解Horizon 连接服务器、安全服务器的配置网络安全和信息化(2020年7期)2020-08-07PowerTCP Server Tool网络安全和信息化(2019年8期)2019-08-28一个具梯度项的p-Laplace 方程弱解的存在性华东师范大学学报(自然科学版)(2019年3期)2019-06-24自动推送与网站匹配的脚本电脑爱好者(2018年6期)2018-04-23基于AMR的梯度磁传感器在磁异常检测中的研究电子制作(2018年1期)2018-04-04基于数字虚拟飞行的民机复飞爬升梯度评估北京航空航天大学学报(2017年12期)2017-04-23计算机网络安全服务器入侵与防御网络空间安全(2016年3期)2016-06-15推荐访问:深度 检测 研究