多尺度残差注意网络的真实图像复原方法
来源:优秀文章 发布时间:2023-01-23 点击:
聂 敏,田 波
(铜仁学院 大数据学院,贵州 铜仁 554300)
在图像采集过程中,经常会出现不同程度的图像降级现象,其中大部分情况是由于照相机的物理限制或不适当的照明条件所致[1-2]。例如,对于光圈很窄和传感器体积较小的智能手机摄像头,其拍摄的图像经常会出现嘈杂的低对比度问题;
而在雾霾严重的天气下拍摄的图像大多背景模糊,颜色失真严重。单一图像恢复(single image restoration,SIR)技术就是采用各类方法通过减少伪像来恢复丢失的细节,旨在将降级的低质量图像恢复到视觉上令人愉悦的高质量图像。作为低级视觉任务,图像恢复技术在计算机监视、交通管理、机器人视觉等多个图像分析应用领域具有广阔的前景[3-5]。
图像恢复是一个从输入图像到输出图像的像素校正响应过程,该过程通过将降级内容与真实信号分离,达到删除退化图像内容,同时保留所需的精细空间细节的目的[6]。但是,图像恢复极具挑战性,因为图像降级过程是不可逆的,导致不适定的逆过程。一般地,图像恢复算法可以分为基于模型和基于学习两大类。基于模型的算法包括非局部自相似、稀疏性、梯度方法以及马尔可夫随机场模型方法等[7]。张雯雯等[8]提出了一种基于非局部自相似性的低秩稀疏图像恢复方法,从自然图像中学习非局部自相似性,将学习的先验模式应用于图像恢复过程中;
Hu等[9]采用最速下降算法和共轭梯度算法相结合的方式来解决图像恢复过程中的平滑优化问题,该方法能够有效恢复图像更多的纹理细节。虽然基于模型的算法能够解决一定条件下的图像恢复问题,但是,这类方法计算量大、耗时长,不能直接抑制空间变异的退化,也不能刻画复杂的图像纹理。近年来,深度学习模型在图像恢复和增强方面取得了重大进展,这是因为它们可以从大规模数据集中学习强大的先验知识。Liu等[10]将深度图像先验框架与传统的全变差正则化方法相结合,用于完成噪声图像和模糊图像的恢复任务;
Li等[11]利用多通道的去噪自编码网络作为图像先验,将提取到的通道先验信息应用到图像恢复过程中来解决红外问题。
虽然基于深度学习的方法在图像恢复方面取得了显著的进步,但将这些方法应用于真实的图像时,其性能并不好。为了提高复原图像的视觉效果,本文提出了一种基于多尺度残差注意网络的真实图像复原方法,该方法首先利用浅层特征提取网络提取退化图像的浅层特征;
然后,采用残差注意网络利用残差结构从不同的感受野上获取上下文信息,并通过注意力机制来获取信道的相关性;
最后,应用重构网络基于原始低质量图像的浅层特征、通道相关性以及上下文深层特征信息完成模型的复原任务。实验结果表明,本文方法能够使用具有不同感受野的特征进行图像复原,极大可能地保留了图像的高频细节信息和低频纹理信息。
本文方法的创新之处是设计了多尺度残差模块,其包含3个关键单元:①用于提取不同感受野信息的多尺度单元;
②用于特征融合和限制低频信息流动的残差密集单元;
③用于捕获通道依赖关系的特征注意单元。简而言之,本文方法通过学习一组丰富的特征来提高真实图像复原的性能。
一般来说,图像复原问题是将退化的图像y恢复到干净的图像x,其过程可以用线性逆问题进行描述为
y=Hx+e
(1)
(1)式中:H表示退化矩阵;
e表示标准差为σ的加性高斯白噪声。不同的退化矩阵,对应不同的图像复原任务。当H为单位矩阵时,复原任务为图像去噪;
当H为模糊算子时,任务是图像去模糊;
当H为模糊和下采样的复合算子时,复原任务则是图像超分辨率。


(2)
(2)式中:logp(y|x)表示退化图像y的似然对数;
logp(x)表示与y无关的先验。实际上,SIR问题通常依赖于正规化的最小二乘公式,因此,(2)式可以修改为
(3)
通常,解决(3) 式的方法可以分为两大类:①基于模型的方法,使用一些优化算法直接求解(3)式,这些算法通常涉及耗时的迭代推理;
②基于学习的方法,在包含退化图像和真实图像的数据集上进行训练,并通过对损失函数进行优化来学习先验参数Θ。基于学习方法的目标定义为
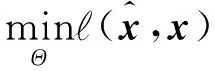
(4)

图1 本文模型的架构图Fig.1 Architecture of the proposed model
2.1 浅层特征提取网络
本文模型的第1个组件是浅层特征提取网络,该网络由2个卷积层组成,用于提取退化图像的浅层特征。其中,第1个卷积层从图像y中提取特征F-1,表示为
F-1=HSFE1(y)
(5)
(5)式中,HSFE1表示第1层卷积运算。第2个卷积层提取到的特征F0定义为
F0=HSFE2(F-1)
(6)
(6)式中,HSFE2表示第2层卷积运算。浅层特征提取网络的输出F0将作为残差注意网络的输入数据。
2.2 多尺度残差注意网络
本文模型的第2个组件是多尺度残差注意网络,该网络包括M个残差注意模块,单个残差注意模块由多尺度单元、残差密度单元和特征注意单元组成,模块使用了局部连接和短跳跃连接进行残差学习,如图2所示。

图2 残差注意模块Fig.2 Residual attention module
为了利用不同感受野提取的深度信息,本文提出了多尺度单元。多尺度单元利用不同尺度的卷积核提取图像的多种特征,小尺度卷积核提取细节特征,大尺度卷积核提取概貌特征,从而有效扩大整个网络的感受野,获得丰富的上下文信息。同时,为了避免过拟合,在卷积层后面设置了ReLU激活层。本文采用1×1、3×3和5×5这3种尺寸的卷积核提取多尺度特征,表示为
(7)
(7)式中:fi表示多尺度图像特征;
si和bi分别表示卷积核和偏置参数。此外,本文将3种尺寸卷积层的滤波器数目设置为64。
将3个不同尺度的特征信息以级联的形式组合起来,构成新的特征图,表示为
F11=[f1(F11),f2(F11),f3(F11)]
(8)
为了使得输出特征的通道与原始特征图保持一致,采用1×1卷积对新特征图进行卷积。
残差密集单元旨在尽可能多地融合来自所有卷积层的信息用于学习并融合特征。在残差密集单元中设置了3个卷积层,卷积核大小设置为3×3,滤波器个数为64。同样,为了避免过拟合,设置了ReLU激活层。采用拼接和1×1卷积层是为了保证与原始特征图的通道保持一致,其计算过程为
(9)
残差注意网络的最后一个单元是特征注意单元。该单元为了利用和学习特征图像的关键内容,将注意力集中在通道特征之间的关系上,图像通常具有低频区域和高频区域,由于卷积层只利用了局部信息而不能利用全局上下文信息,因此,特征注意单元采用全局平均池化操作来表示整个图像的统计信息,然后采用一种自选门控机制从全局平均池化结果中捕获通道依赖关系。根据文献[12],上述机制必须了解通道之间的非线性协同效应以及相互排斥的关系,因此,使用软收缩和sigmoid函数来实现门控机制。假设考虑ψ和φ分别是软收缩和sigmoid算子,那么门控机制可以定义为
rc=φ(HU(ψ(HD(F12))))
(10)
(10)式中:rc表示门控机制输出结果;
HU和HD分别表示通道上采样和通道下采样操作符。残差密度单元的输出结果F12被输入到由软收缩函数激活的下采样卷积层中进行卷积操作,为了区分信道特征,输出随后被馈送到一个由sigmoid激活引起的上采样卷积层,特征注意单元的输出F13由通道特征的输入F12和门控机制的结果rc融合得到,即
F13=rcF12
(11)
因此,第1个残差注意模块的输出F1可以表示为
F1=F13
(12)
第d个残差注意模块的输出Fd表示为
Fd=Fd3
(13)
2.3 重构网络
将浅层特征、深度特征以及通道依赖性馈送到重构网络中。对于不同用途的模型,重构网络可以分为2种。当模型用于图像去噪、去模糊和压缩时,网络由一层卷积和全局残差学习组成,其输出结果定义为
(14)
(14)式中
FGF=HRN(FD)
(15)
(15)式中:HRN为重构卷积运算;
FD表示最后一个残差注意模块的输出特征。
当模型用于图像超分辨时,需要在上述基础上堆叠一个上采样和一层卷积。
为了优化网络模型,重构误差函数定义为
(16)
(16)式中:{xi,yi}N表示训练集中的N个图像对;
xi表示真实图像;
yi表示退化图像;
HNet和θ分别表示所提网络模型和对应的模型参数。
为了验证本文方法的效果,本文选取图像去噪、超分辨率和图像增强3个任务相应的图像数据集来测试其性能,将产生的结果进行定性和定量评估,并与以往的方法进行比较。所提网络的架构是端到端可训练的,不需要子模块预训练。所有实验共有的训练参数如下:使用4个残差注意网络, 模型使用带有默认参数的Adam优化器,初始学习率设置为10-4,然后在105次迭代后减半。在每批训练中,随机抽取16个大小为80×80的LQ-RGB图像块作为图像去噪、超分辨率和图像增强的输入。该网络在Pythorch框架中实现,并使用Nvidia Tesla V100 GPU进行训练。为了增加数据,执行包括90°,180°,270°的随机旋转和垂直或水平翻转。
3.1 数据集和评估指标
1)选择3组图像去噪方面的数据集,即BSD68、CBSD68和SIDD数据集。BSD68和CBSD68数据集[13]由相同的68个图像组成,两者不同之处是BSD68中包含的是灰色的图像, CBSD68中是带有彩色的图像。由于图像是对真实图像退化降级后合成而来,因此,该数据集能够有效评估模型的测试结果。SIDD数据集[14]是一个真实的图像数据集,该数据集是由智能手机摄像头拍摄的,由于手机摄像头传感器和分辨率的局限性,使得拍摄图像中存在较多的噪声。SIDD数据集包含320个用于训练的图像对(噪点图像及其相应的清晰图像),1 280个用于验证的图像对。
2)选取2组超分辨率数据集,即Urban100和RealSR数据集。Urban100数据集[15]是最近提出的包含100张图像的数据集,图像包含人造物体和建筑物,图像的大小和数据集中的结构使得超分辨率任务非常具有挑战性,对于该数据集,本文使用BI化模型来模拟LR图像用于超分辨率图像的测试。RealSR数据集[16]是一个图像超分辨率数据集,包含拍摄于同一场景的真实低分辨率和高分辨率的图像对。RealSR数据集可分为室内和室外2组图像,尺度因子为×2、×3和×4的训练图像对数分别为183、234和178,对于每个尺度因子,RealSR中还提供了30个测试图像。
3)选取2组图像增强数据集,即LoL和MIT-Adobe FiveK数据集。LoL数据集[17]是针对微光图像增强问题而产生的数据集,它提供了485个图像用于培训,15个图像用于测试。LoL数据集中的每个图像对由一个微光输入图像和相应的曝光良好的参考图像组成。MIT-Adobe FiveK数据集[18]包含了5 000张不同照明条件下用单反相机拍摄的各种室内外场景的图像,所有图像的色调属性都是由5个不同的训练有素的摄影师(标记为A—E)手动调整的,其中,前4 500幅用于训练,后500幅用于测试。
为了验证本文方法的有效性,本文利用峰值信噪比(peak signal-to-noise ratio, PSNR)和结构相似性指数(structural similarity index, SSIM)这2个评价指标来评估测试结果。
3.2 消融研究
本文主要研究残差注意模块数量和模块中3个单元对模型性能的影响,以图像去噪为例,在BSD68数据集上进行测试。
1)进行第1个消融研究,考察不同残差注意模块数量对模型性能的影响。图3给出了不同数量时的收敛性分析。从图3可以看出,较大的m将带来更好的性能,这主要是因为m越大,网络越深。
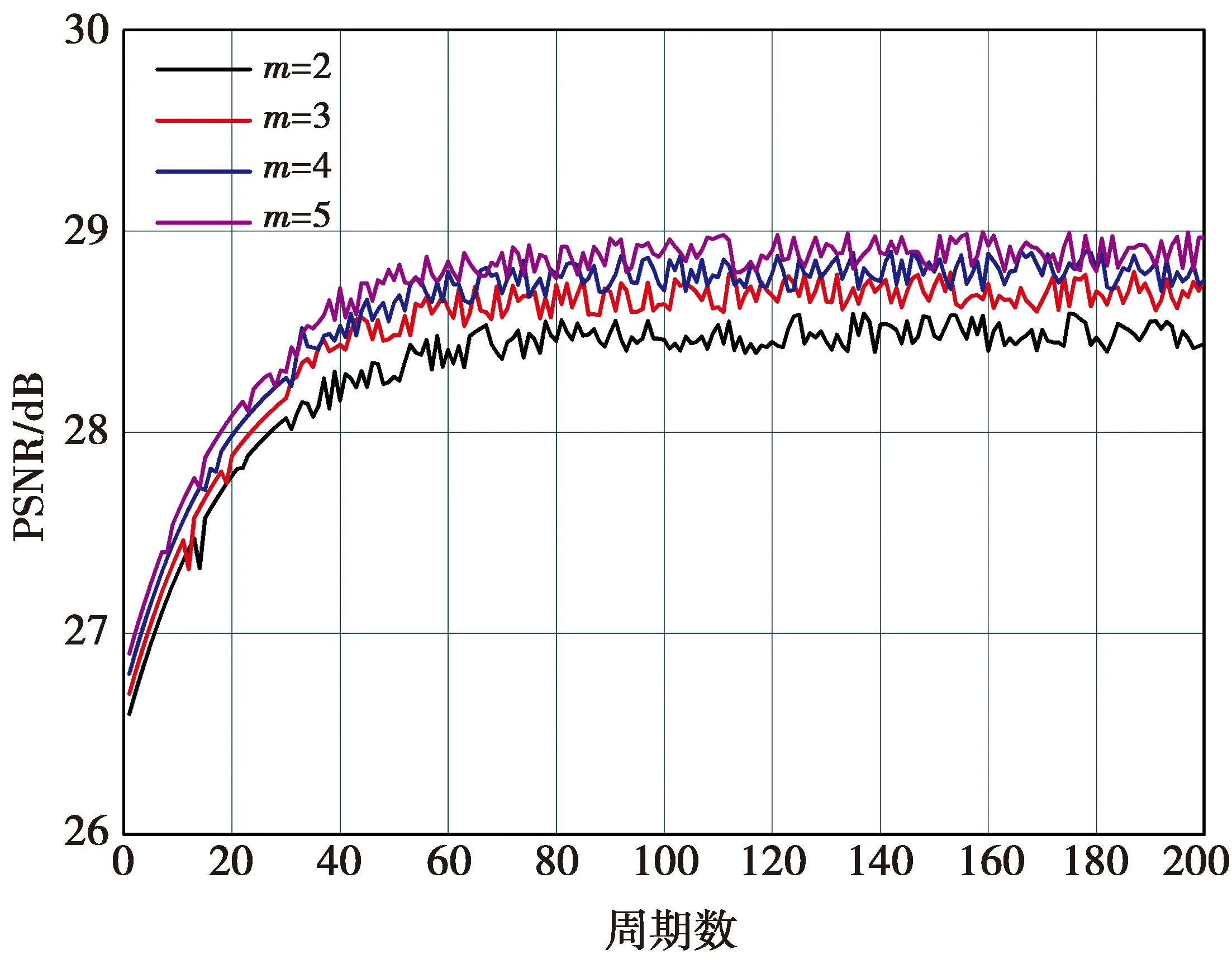
图3 不同残差注意模块数量时的收敛分析Fig.3 Convergence analysiswith different residual attention modules
2)进行第2个消融研究,考察不同模块单元以及全局跳跃连接对模型性能的影响。图4给出了BSD68数据集上的平均PSNR。由图4可见,当所有单元及全局跳跃连接均可用时,将获得最优的性能,而在缺少任何组件时,性能将会降低。
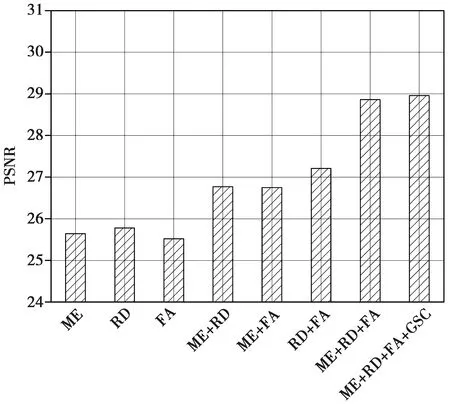
图4 不同模块单元时的PSNR结果Fig.4 PSNR results with different module units
3.3 图像去噪
第1个实验给出了本文方法在图像去噪方面的有效性。在该实验过程中,本文方法分别对灰度图像、彩色图像以及真实世界图像进行了去噪任务,并且使用标准差s为10,30和50的加性高斯白噪声来破坏干净图像。
1)采用由空间不变的加性高斯白噪声所破坏的嘈杂灰度图像评估模型,并将测试结果与RIDNet[13]、FFDNet[14]以及VDN[19]方法进行对比。表1给出了不同方法在PSNR和SSIM指标上的比较结果。从表1可以看出,本文方法在对比方法中去噪效果最好,在PSNR和SSIM指标上都优于其他算法。
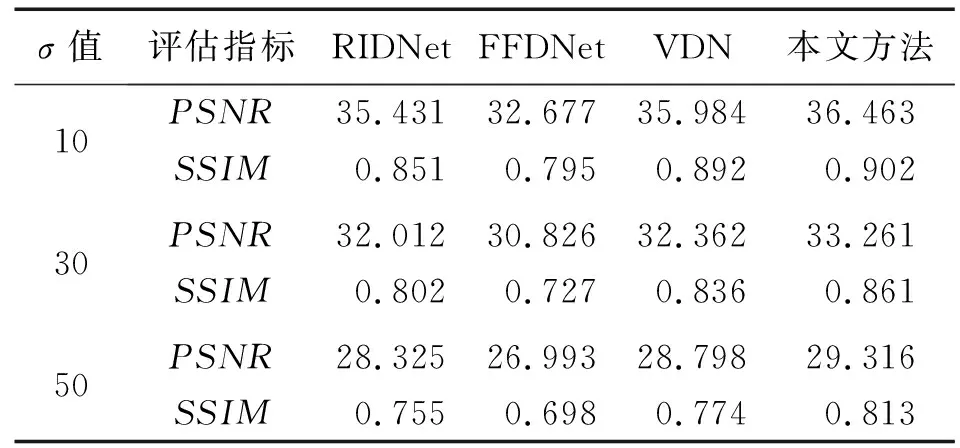
表1 不同去噪方法在BSD68数据集上的定量结果Tab.1 Quantitative results of different denoising methods on BSD68 dataset
图5给出了本文方法与其他对比方法在BSD68数据集上的视觉比较。大多数去除噪声的算法选择牺牲图像细节为代价,生成过于平滑的图像,或者生成带有斑点纹理和色度伪影的图像。例如,FFDNet方法使用噪声估计图作为输入,为了抑制噪声生成过于平滑的图像,而牺牲了结构内容和精细的纹理细节,并且当噪声较大时,图像局部会出现模糊现象;
RIDNet方法和VDN方法生成带有斑点纹理的图像。而本文方法考虑到低频区域和高频区域的局部特征信息是不同的,因此,采用特征注意单元为每个通道特征产生不同的注意力。从图5可以看出,本文方法在去除真实噪声方面是有效的,能够在不引入伪影的情况下保持均匀区域的空间平滑,生成极为清晰的图像。

图5 不同去噪方法在BSD68数据集上的定性评价Fig.5 Qualitative evaluation of different denoising methods on BSD68 dataset
2)对嘈杂的彩色图像去噪。将第1层和最后1层更改为输入和输出3个通道而不是1个通道,将网络其余的所有参数保持与灰度模型相似。表2给出了不同方法的PSNR与SSIM值。从测试结果看,对于CBSD68数据集,本文方法始终优于其他对比方法。此外,随着s的增加,本文方法和对比方法的去噪性能均有所降低,但是,相较于灰度图像的下降速度,本文方法在表2中的性能下降速度较慢,说明本文方法在彩色图像中的效果更佳。

表2 不同去噪方法在CBSD68数据集上的定量结果Tab.2 Quantitative results of different denoising methods on CBSD68 dataset
3)将模型应用于真实的噪声图像。本文方法在SIDD数据集上进行训练并测试评估。表3给出了不同方法在PSNR和SSIM指标上的比较。从表3可以看出,本文方法在对比方法中去噪效果最好,比FFDNet提高了9.08 dB,比RIDNet提高了1.15 dB,比VDN提高了0.58 dB。
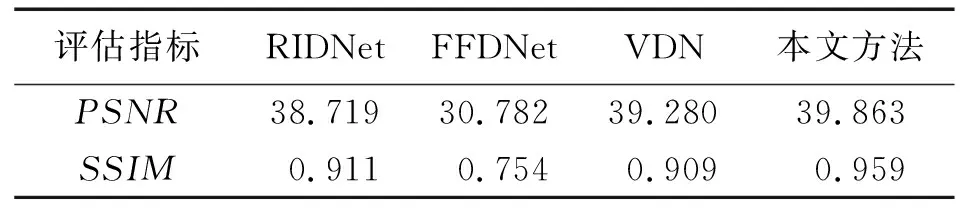
表3 不同去噪方法的定量结果Tab.3 Quantitative results of different denoising methods
图6给出了本文方法与其他对比方法在SSID数据集上的视觉比较。可以看出,本文方法在去除真实噪声方面是有效的,生成最佳的感知质量图像。

图6 不同去噪方法在SSID数据集上的定性评价Fig.6 Qualitative evaluation of different denoising methods on SSID dataset
而大多数其他方法要么生成过于平滑的图像,要么生成带有色度伪影和斑点纹理的图像。
3.4 图像超分辨率
第2个实验是验证本文方法在图像超分辨率方面的有效性。模型在Urban100和RealSR数据集上进行测试,并与U-Net[1]、LP-KPN[16]、SAN[20]以及RCAN[21]方法进行对比。在实验中,还计算了双三次插值Bicubic方法的结果,这是生成超分辨率图像最常用的方法。基于超分辨率的常用做法,本文也使用了YCbCr颜色空间中的Y通道来计算PSNR和SSIM值。
表4—表5分别给出了不同方法在Urban100和RealSR数据集上的PSNR和SSIM度量结果。从表4—表5可以看出,不同缩放因子下的双三次插值得到的结果最不精确,这说明该方法对处理真实图像的适用性较低。其他几类方法虽然在3个缩放因子测试中取得了不错的结果,但是本文方法产生了更好的图像质量结果。以×3时的测试结果为例,在Urban100数据集下,相较于Bicubic、U-Net、LP-KPN、SAN和RCAN方法,本文方法有了明显的改善,分别提高了5.41,2.75,1.07和0.65 dB的性能增益。在RealSR数据集下,则分别提高了2.01,1.19,0.95和0.93 dB的性能增益。
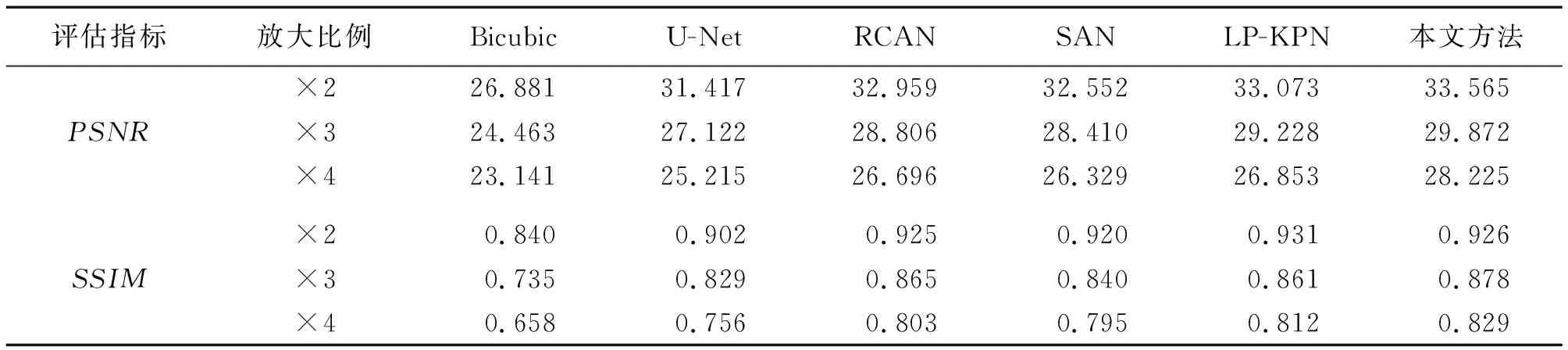
表4 不同超分辨率方法在Urban100数据集的定量结果Tab.4 Quantitative results of different super-resolution methodson Urban100 dataset

表5 不同超分辨率方法在RealSR数据集的定量结果Tab.5 Quantitative results of different super-resolution methodson RealSR dataset
图7—图8分别给出了不同超分辨率方法在Urban100和RealSR数据集中的图像视觉对比结果,其中,放大比例为4。Urban100数据集包含了具挑战性的城市景色,具有不同频带的细节。从图7可以看出,尽管SAN和RCAN可以重建局部细节,但大多数比较方法无法恢复LR图像中丢失的细节。相比之下,本文方法将原始图像的浅层特征、通道相关性以及深层特征信息融合为全局上下文信息,从而可以恢复更锐利和更清晰的边缘,更忠实于真实图像。

图7 不同方法的超分辨率在Urban100数据集上的定性评价Fig.7 Qualitative evaluation of super-resolution by different methods on Urban100 dataset
RealSR数据集包含同一场景、同一相机以不同的焦距采集的数据,该数据集对尺度因子变化十分具有挑战性。从图8可以看出,Bicubic、U-Net、SAN和RCAN的超分辨率结果带有明显的伪影,而LP-KPN方法存在边缘细节丢失的现象,相比之下,本文方法的结果具有丰富的细节和边缘纹理,并产生了色彩自然的图像。此外,本文方法具有很好的鲁棒性,能够适用于不同挑战性的超分辨率。

图8 不同方法的超分辨率在RealSR数据集上的定性评价Fig.8 Qualitative evaluation of super-resolution by different methods on RealSR dataset
3.5 图像增强
第3个实验是验证本文方法在图像增强任务中的有效性。模型在LoL数据集和MIT-Adobe FiveK数据上进行测试,并与KinD[4]、Retinex-Net[17]以及GLAD[22]方法进行对比。表6给出了不同图像增强方法测试的PSNR和SSIM值。从表6可以看出,本文方法比以前的方法有了显著的改进。通过对比发现,对于LoL和MIT-Adobe FiveK数据集,本文方法的性能比KinD、GLAD和Retinex-Net方法分别提高了3.27,4.42,7.37 dB和2.0,3.58,4.82 dB。

表6 不同图像增强方法的定量结果Tab.6 Quantitative results of different image enhancement methods
图9—图10分别给出了不同增强方法在LoL和MIT-Adobe FiveK数据集上的图像视觉对比结果。从图9可以看出,Retinex-Net、GLAD以及KinD方法的对比度较差,而且GLAD存在颜色失真的现象。相比而言,本文方法生成的增强图像既自然又生动,具有更好的全局和局部对比度,在亮度方面也更接近真实情况。

图9 不同图像增强方法在LoL数据集上的定性评价Fig.9 Qualitative evaluation of image enhancement by different methodson LoL dataset

图10 不同图像增强方法在MIT-Adobe FiveK数据集上的定性评价Fig.10 Qualitative evaluation of image enhancement by different methodson MIT-Adobe FiveK dataset
本文提出了一种基于多尺度残差注意网络的复原方法,用于解决在真实图像上深度学习方法性能不佳的问题,提高图像的复原视觉效果。本文方法由浅层特征提取网络、多尺度残差注意网络和重构网络3个模块组成,能够利用具有不同感受野的特征对图像去噪、图像增强和超分辨率等多个任务中的退化图像进行复原。具体地,首先利用浅层特征网络提取原始低质量图像的浅层特征,并基于残差结构馈送入多尺度残差注意网络和重构网络中;
然后,通过多尺度残差注意网络利用多尺度单元、残差密度单元和注意力单元从浅层特征图中学习图像的深层特性信息和通道相关性;
最后,应用重构网络基于浅层特征、深层特征和通道相关性等多层次特征信息对退化图像进行复原。实验结果表明,本文方法在多个任务中取得良好的结果,相较于其他复原算法,本文方法的性能最优。