财务困境预测:二元Logistic回归分析与GABP算法比较
来源:优秀文章 发布时间:2023-01-18 点击:
米万东
(兰州财经大学 会计学院,兰州 730030)
随着新冠肺炎疫情的爆发,交通运输行业受到管控,我国制造业上市公司面临着原材料的获取困难、销售订单的取消和减少、存货周转困难和现金流短缺等危机,这可能导致公司现金流断裂,发生财务危机,使得公司走上舞弊甚至破产的道路。对投资者来说,对该公司的投资会带来较大的风险。对委托审计机构来讲,准确地预测公司财务状况可以在审计前对被审计单位有更充分的了解,以及也可以更好的控制审计过程中的风险,因此对公司财务困境的预测具有一定的研究意义[1]。ST是指我国沪深交易所对出现财务状况异常的公司进行的特别处理,被ST标志着该上市公司陷入了财务困境,公司的财务健康状况较差。被ST公司的财务状况受到宏观经济、公共政策、经营策略等因素的影响,并且公司财务状况逐步恶化最终陷入困境,通过对公司财务状况的动态监测可以尽早发现存在的问题,防微杜渐。
通过梳理国内外的研究,公司财务困境预测的方法大致分成三种,分别是单指标分析法、多指标分析法和利用神经网络、SVM等机器学习分析法。在单指标分析法中,Title[2]用净利润与股东权益的比值以及股东权益与负债总额的比值两个变量;
Beaver[3]用现金流量和负债总额的比值分别来评估并预测公司陷入财务困境的可能性。单指标分析法预测可能存在不同的指标预测出的财务状况不一致,因为随着经济的发展公司财务状况变得复杂,财务指标也随之增加,单个指标不能充分说明财务状况。Altman[4]提出了Z-score多指标模型,运用多个财务指标的加权平均构建了被评价公司财务状况的体系。吴世农等[5]提出了多变量线性判定方法来预测公司陷入财务困境的模型。多指标模型相对单指标模型,在多个指标构建的综合判断上提高了预测的准确性和可靠性。20世纪80年代,随着大数据、人工智能的发展,越来越多的学者开始尝试将机器学习应用在财务预测方面。赵辰等[6]利用MEA-BP神经网络构建了对财务困境预测的模型,并得出了较好的预测成果,但此研究对财务困境的预测只有“是”和“否”两种结果,但在实际的场景中情况更为复杂,输出[0,1]的连续值来表示财务健康状况将更具有研究价值。
单指标预测模型和多指标预测模型存在一定的局限性,首先由于公司的财务困境是多种因素造成的,单指标分析模型和多指标分析模型很难包含较为全面的影响因素,应对可能的影响因素做较为全面的组态分析;
其次之前的研究大多仅采用财务指标分析,现在越来越多的学者开始研究非财务指标(例如管理层结构、管理层专业背景、公司股权结构、员工数目、男女比例和薪资水平)对公司运营的影响;
再者具体指标的财务预测模型可能会使管理层出现逆向选择,使管理层的经营目标是对某些指标的“粉饰”而非公司价值最大化。在“大智移云”时代下,各种指标和数据爆炸式增长,机器学习便展现出较大的优势,在处理大量数据和一些非线性复杂问题方面被广泛应用且效果良好。
选取2018年至2021年共303家A股上市公司(不包含金融公司)的85项指标进行分析(数据来自于CSMAR数据库)。303家A股上市公司中有114家首次被ST,189家非ST,符合ST与非ST按1∶2选取的大致原则。ST公司的数据为首次被ST年度(不含当年)的前三年数据,非ST公司则统一选取2018年度至2021年度的数据,利用平均值法对少部分缺失数据进行填充。数据噪声指数据出现了不合理的情况,例如员工人数为负的数据需要进一步进行剔除,最终选取的财务与非财务指标如表1所示。

表1 财务与非财务指标
2.1 建立回归模型
二元Logistic回归是一种线性回归分析。多元线性回归适合分析被解释变量为连续变量的情况,当被解释变量取值为“是”或“不是”、“买”或“不买”这种分类变量时,适合利用Logistic回归分析。预测公司是否会被ST,用Y=(1,0)表示公司会被ST,Y=(0,1)表示公司不会被ST,建立二元Logistic模型:
(1)
(2)
式中:xi表示解释变量;
P表示Y=(1,0)的概率;
i=1,2,…,85;α表示常数项;
βi表示xi的回归系数。
2.2 主成分分析
选取的指标越多,越可能对问题的分析带来更详细的信息,但较多的指标会带来共线性问题,带来冗余的信息。主成分分析是一种数学上的降维方式,旨在通过正交变换,将原先较多的变量组合成个数较少且互不相关的综合变量,通过较少的变量尽可能多的反映原始信息,有利于下一步的分析。
基本原理:将原来的m个变量转化为新的n个变量,设表示第i个主成分:
(3)

2.2.1 归一化处理
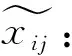

(4)

(5)

(6)
式中:Tij表示第i个指标在第j个公司处的值;
min(T)、max(T)分别为指标i的最小值、最大值;
[Q1,Q2]是该指标最佳值的隶属区间。
2.2.2 建立变量间的相关系数矩阵R
R=(rij)m×m
(7)
(8)
式中:rii=1;
rij=rji;
rij是第i个指标与第j个指标的相关系数。
2.2.3 计算相关系数矩阵R的特征值和特征向量
计算相关系数矩阵R的特征值a1≥a2≥…≥am≥0,及对应的特征向量∂1,∂2,…,∂m,其中,∂j=(∂1j,∂2j,…,∂nj)T,由特征向量组成m个新的指标变量:
(9)
式中,yi是第i个主成分。

图1第二列总计值代表变量的特征值,特征值大于1是选取主成分的重要标准之一,根据图1和图2选取前27个特征值大于1的指标作为主成分,保存为新的变量Vi进行下一步分析。
2.3 回归结果分析
在构建回归方程前,需对各解释变量进行共线性检验以保证回归方程的准确性和稳定性,共线性检验证明27个主成分的方差膨胀系数值小于10,说明在降维后变量之间的共线性较弱,可以构建Logistic回归模型。模型检验结果如表2所示,系数显著性检验的sig值小于0.05,表明最终进入模型的解释变量与logit(P)的线性关系显著,Hosmer和Lemeshow检验的值为0.749,大于0.05,说明模型拟合较好,模型总体预测准确率为90.8 %,预测结果较好。

表2 模型检验结果
3.1 BP神经网络
BP神经网络是一种多层前馈神经网络,它的拓扑结构由输入层、隐含层和输出层构成,BP神经网络拓扑结构如图3所示。在传导过程中信息xi先输入到输入层的神经元中,由输入层经过权重ωij的变化传输到隐含层的神经元中,再经过权重ωjk和阈值θj的变换传输到输出层的神经元中,最终经过输出层阈值δk的变换输出信息yk。在层与层的传导中,每个神经元通过激励函数和阈值变换构建联系,对信息进行计算和处理。
BP神经网络训练过程如图4所示,利用BP神经网络预测可分为训练和预测两步,首先将数据集分为训练集和测试集。初始化各节点和层级的参数后,利用训练集中的数据对神经网络进行训练,将网络运算得到结果的误差值与期望误差值进行比较,若输出结果的误差大于期望误差值,神经网络将逐层返回调整网络的权值,经过多次迭代至网络运算结果误差值小于期望误差值或达到最大学习次数为止,找到最佳的参数后再对测试集中的解释变量进行运算,将输出的结果与(1,0)和(0,1)进行比较,判断神经网络预测此公司是否会被ST,最后将预测结果和实际结果相对比,计算出预测的准确率。
3.2 遗传算法优化的BP神经网络
遗传算法(Genetic Algorithm,GA)是一种模拟自然界生物进化过程,利用优胜劣汰的原则寻找全局最优解的方法。将需要解决的问题转化为类似染色体基因交叉、变异等过程来对一些较为复杂的拟合问题进行优化。
对于BP神经网络的输入层、隐含层和输出层节点的阈值和节点之间的权值,程序会在[-0.5,0.5]之间随机确定一个数作为初始权值,初始权值对神经网络的训练结果起到重要作用。利用随机值训练会使神经网络出现训练时间过长,容易陷入局部最优的困境,而遗传算法可以找到最优的初始阈值和权值,来提高神经网络预测的准确率。遗传算法优化具体步骤如下:
步骤1:编码。将种群中的每个个体用二进制数组进行编码,以便于计算机识别和储存。使用的网络结构是85-25-2,权值和阈值的编码个数如表3所示。

表3 权值和阈值的编码个数
步骤2:选择适应度函数。适应度函数是描述种群中某个个体适应环境能力大小的关系。选择种群中适应度高的“优秀个体”,是找到最优解的必要条件。利用神经网络做预测,优化的目的是使预测的准确率尽可能提高,因此假设预测值与期望值误差的倒数为适应度函数,计算公式如下:
(10)

步骤3:选择操作。在选择时,根据优胜劣汰的原则将适应度高的个体选出作为下一代的个体。选择算子选用轮盘赌选择法,其原理是依据轮盘被选中区域代表被选中的个体,轮盘上面积越大代表个体适应能力越大,被选中的机率也越大。pk为个体xk被选中的概率,d表示个体个数,计算公式如下:
(11)
步骤4:交叉操作。交叉操作是指相互配对的一对染色体交换部分基因,从而形成新个体的过程。选用单点交叉算子,交叉方式如下:
Akj=Akj(1-b)+Aijb
(12)
Aij=Aij(1-b)+Akjb
(13)
式中:Akj和Aij是第k个基因和第i个基因在j处交叉生成的新基因对;
b是[0,1]中的随机数。
步骤5:变异操作。变异操作是指基因座上的某处基因被等位基因替换,从而生成新的个体。变异方式如下:
(14)
(15)
式中,基因Amn的上下界为Amax和Amin;
r是0到1之间的随机数;
r′是随机数;
g是当前迭代次数;
Gmax是最大进化代数。
步骤6:将优化后的值赋给BP神经网络的阈值和初始权值。种群初始化规模取40,进化代数取50,交叉概率为0.7,变异概率为0.01。
3.3 实证分析
将303家公司分为训练集和测试集,训练集中包括80家ST公司和132家非ST公司,测试集中包括34家ST公司和57家非ST公司,将归一化后的数据放入matlab中处理,BP神经网络预测结果如图5所示。图5是仅用BP神经网络预测,即使用随机的权值和阈值的结果,将预测错误的用圈圈出。
均方误差(Mean Squared Error,MSE)是参数估计值与参数真值之差平方的期望值。遗传算法优化,BP神经网络在第六次迭代时达到收敛,均方误差最小为0.001 157 1,此时网络达到最优状态,迭代次数如图6所示。通过遗传算法的优化,使误差从4.8降到了3.8附近,进化过程如图7所示。
遗传算法优化下的BP神经网络预测,GABP预测结果如图8所示。在测试集91组数据中,前34组数据是ST公司(1,0),后57组数据是非ST公司(0,1),将预测出错的项用圈圈出。仅用BP神经网络预测正确70组,GABP方法下预测正确86组。BP与GABP结果对比如表4所示。

表4 BP与GABP结果对比
实证分析证明通过遗传算法优化初始权值和阈值后的BP神经网络解决了陷入局部最优的问题,预测效果明显好于单纯使用BP神经网络。
聚类分析是一种根据数据特征,将相似的数据归为一类的分析工具,通过对GABP预测出的结果聚类分析,可以得出当前市场财务健康状况的分类情况。将单个公司的预测结果与分类结果相对比,可以得知该公司财务状况在市场上的相对情况。K-means是一种常用的聚类方法,其基本原理是:在数据集中随机选取k个点,然后计算数据集中每个点到这k个点的距离,将每个点都划分到离它最近的点形成的簇中,这样就首次分成了k类,接着找这k个簇的质心,再次计算数据集中每个点到这k个质心的距离,然后形成新的k个分类,通过不断的迭代上述过程,找到最优的分类结果。在预测正确的86组数据中,利用K-means聚类方法对数据进行聚类分析,最终分为5类,K-means聚类如图9所示。将86家公司财务状况相近的聚为一类,最终聚类形成5种类型,从类型1至类型5公司的财务健康程度越来越差,越容易陷入财务困境。
K-means聚类结果如表5所示,中心点坐标表示该种类型所在簇的质心坐标,频数是该簇中包含的数据个数,百分比是该簇中数据数占总数的百分数。从结果中可以看出当前市场中处于类型1的公司占到52.326 %,说明当前市场超过一半的公司财务健康程度很好,类型1、2、3代表公司财务健康程度较好,合计达到66.279 %,这部分公司目前没有较大的财务问题,需要继续保持当前经营策略。类型4和类型5是财务健康程度较差的公司,占到总公司数的33.721 %,处于这两种类型的公司即将陷入财务困境,需要调节公司的经营策略,改善公司的财务状况。

表5 K-means聚类结果
对财务困境的预测是将尽可能多的影响因素纳入模型对风险进行量化,对投资者来说可以根据公司的财务健康状况有选择地进行投资;
对经营者来说可以动态监测财务状况的变化,找到其原因并及时解决;
对审计人员来说可以在审计前对公司的经营风险进行了解,审计中可以有计划的制定审计程序,将审计风险控制在可接受的范围内。
GABP在BP神经网络的基础上通过遗传算法进行优化,克服了BP神经网络收敛速度慢、易陷入局部最优的问题。通过建立二元Logistic模型和GABP模型对财务困境做出预测,这两种方法不同处有三点:
(1)在数据处理能力方面,选取303家公司3年的85个指标后直接进行Logistic回归会因数据量过大而无法得出预测结果,只能先进行主成分分析再进行回归预测,然而确定的27个主成分只能解释不到80 %的总信息(一般要求85 %以上),而BP和GABP均能够对数据直接进行分析且模型内部会处理变量之间的共线问题,不需要事先经过主成分分析,可见在处理大量数据拟合的问题上,机器学习的方法会比线性回归更适合。
(2)在模型预测精度方面,二元Logistic回归分析总体预测正确的百分比达到90.8 %,预测效果良好,BP神经网络预测准确率仅为78 %,经过遗传算法优化后,准确率达到了94.5 %,预测的结果更加可靠。
(3)在信息可用性方面,二元Logistic回归分析输出结果为0或1的离散变量,对现实情况刻画不足,GABP可得出[0,1]之间的连续变量,最终将GABP输出的结果通过K-means进行聚类分析,使得公司的财务状况能够进行纵向和横向对比,纵向分析可以看出公司的发展趋势,横向分析可以得出公司财务状况在当前市场的地位,为下一步战略的规划和实施提供依据。
机器学习模型的预测相对于二元回归模型准确率较高、适用性较强,但需要大量的数据来训练模型,对于公司数量较少的行业适用性较差,并且机器学习的训练过程具有黑箱的性质,只能分析出自变量与因变量间的相关关系,对于两者间的因果关系,需进行下一步的案例分析深入研究。
猜你喜欢 遗传算法神经网络变量 基于神经网络的船舶电力系统故障诊断方法舰船科学技术(2022年11期)2022-07-15基于递归模糊神经网络的风电平滑控制策略现代电力(2022年2期)2022-05-23抓住不变量解题小学生学习指导(高年级)(2021年4期)2021-04-29基于遗传算法的高精度事故重建与损伤分析汽车工程(2021年12期)2021-03-08基于遗传算法的模糊控制在过热汽温控制系统优化中的应用电子制作(2019年16期)2019-09-27基于神经网络的中小学生情感分析电子制作(2019年24期)2019-02-23基于遗传算法的智能交通灯控制研究电子制作(2019年24期)2019-02-23基于Q-Learning算法和神经网络的飞艇控制北京航空航天大学学报(2017年12期)2017-04-23基于改进多岛遗传算法的动力总成悬置系统优化设计汽车科技(2015年1期)2015-02-28分离变量法:常见的通性通法新高考·高二数学(2014年7期)2014-09-18推荐访问:算法 困境 回归