融合光照损失的图像超分辨率生成对抗网络
来源:优秀文章 发布时间:2022-12-09 点击:
陈亚瑞,丁文强,徐肖阳,胡世凯,闫潇宁,许能华
(1. 天津科技大学人工智能学院,天津 300457;
2. 深圳市安软科技股份有限公司,深圳 518131)
单幅图像超分辨率(single image super-resolution,SSIR)重建是根据一张低分辨率(low resolution,LR)图像恢复出高分辨率(high resolution,HR)图像的过程.SSIR作为计算机视觉一个非常重要的研究方向,引起了国内外众多学者的广泛关注,其研究成果有大量的商业应用.超分辨率重建在医学成像、卫星成像、人脸识别、视频监控以及恢复重要历史图像资料等诸多领域发挥了非常重要的作用.
在深度学习没有兴起之前,传统的SSIR通常使用插值法[1-3].插值法具有计算简单、计算速度快等优点,但有时会导致生成图像的边缘和细节模糊.随着深度学习的不断发展,深度学习在单幅图像超分辨率领域的优异表现,促进了单幅图像超分辨率研究的快速发展,各种神经网络的变体也应用于单幅图像超分辨率的研究中,包括卷积神经网络[4]、对抗神经网络[5]以及二者的结合等[6].
超分辨率生成对抗网络(super-resolution generative adversarial networks,SRGAN)[7]是将图像超分辨率与生成对抗网络结合,生成视觉效果较好的高分辨率图像.然而,SRGAN模型的训练数据由人工构造,根据已知的高分辨率图像,利用双三次插值法[3]进行下采样,得到低分辨率图像.人工构造的高分辨率-低分辨率(HR-LR)图像对并没有考虑复杂情况下的图像超分辨率问题,例如低光照、模糊、噪声、运动等复杂情况.这导致了用人工构造的HR-LR图像对训练得到的模型在处理人工生成的低分辨率图像时效果很好,但是处理现实生活中低分辨率图像的效果往往不尽如人意.SRGAN模型的损失更加关注峰值信噪比(peak signal-to-noise ratio,PSNR),而忽略了结构相似性(structural similarity,SSIM),这使生成的高分辨率图像虽然有较好的峰值信噪比,但是视觉效果不佳.基于此,本文模型在SRGAN模型的基础上进行了3个方面的改进:首先,构造一个新的损失函数(光照损失),解决低光照条件下的图像超分辨率问题;
其次,增加结构相似性损失,平衡生成图像的PSNR和SSIM,使生成图像的视觉效果更好;
最后,构造新的训练数据集,在传统低分辨率图像的基础上,通过减少图像的灰度值降低图像的亮度,得到全新的HR-LR图像对,此时的LR图像不仅是低分辨率而且还是低光照条件.
1.1 图像超分辨率
从低分辨率图像估计其对应高分辨率图像的挑战性任务被称作超分辨率.传统的图像超分辨率方法通常使用插值法,例如双线性插值法[2]、双三次插值法[3]、Lanczos[7]重采样等.插值法具有计算简单、计算速度快等优点,但是生成的图像往往比较模糊,纹理细节通常比较平滑.在深度学习兴起之后,传统的图像超分辨率方法逐渐走向了没落,而基于深度学习的图像超分辨率方法迅速发展,研究人员提出了很多新的方法.
基于深度学习的图像超分辨率方法主要包括基于卷积神经网络[8-12]、基于递归神经网络[13-15]、基于循环神经网络[16]、基于对抗神经网络[5,17]、基于反馈机制[18-19]、基于通道注意力机制[20-22]等.还有一些特殊的图像超分辨率方法,例如针对多尺度超分辨率重建[23]、基于弱监督学习的超分辨率重建[24-25]、基于无监督的超分辨率重建[26-27]、针对盲超分辨率图像重建[28-30]等.
1.2 基于卷积神经网络的图像超分辨率
由于卷积神经网络在图像分类、识别等领域有着出色的表现,因此Dong等[8]将卷积神经网络(convolutional neural network,CNN)应用到超分辨率重建中,提出了超分辨率重建卷积神经网络(superresolution convolutional neural network,SRCNN).虽然SRCNN模型只有3层神经网络,但是相较于传统的图像超分辨率方法,取得了显著的效果.
由于CNN的优异表现,越来越多的研究人员开始尝试用CNN实现图像的超分辨率重建,并提出了许多新的模型.例如,Dong等[9]改进了SRCNN模型,提出了快速超分辨率重建卷积神经网络(fast super-resolution convolutional neural network,FSRCNN).Kim等[4]提出了超分辨率重建极深卷积神经网络(very deep convolutional network for super- resolution,VDSR)模型,相比于SRCNN模型,VDSR模型使用了更深的神经网络,可以提取更多的特征图,使重建后的图像细节更加丰富.Mao等[10]提出了极深残差编解码网络(very deep residual encoderdecoder networks,RED-Net)模型,该模型用到了编码-解码结构.考虑到DenseNet模型的优点,Tong 等[11]提出了SRDenseNet网络.Yu等[12]在2018年提出了WDSR模型,并取得了当年NTIRE竞赛的冠军. 目前,尽管卷积神经网络在图像超分辨率重建上很难恢复真实的纹理和细节,生成的图像比较模糊,但是其在图像超分辨率领域仍然占据着重要位置,每年都会有许多基于CNN的图像超分辨率模型被提出.
1.3 基于生成对抗网络的图像超分辨率
传统的图像超分辨率方法和基于卷积神经网络的图像超分辨率方法都是以峰值信噪比作为一项重要的评判指标,导致的结果就是随着模型的不断改进,PSNR越来越大,但是生成的图像在视觉感知上质量较差.这也证实了,即使PSNR数值大,图像的感官质量也并不一定就好.为了生成符合人类感官质量的图像,Ledig等[5]提出了SRGAN模型,网络主体采用对抗生成网络(generative adversarial net,GAN),损失函数采用感知损失与对抗损失之和.虽然峰值信噪比不是最高,但是SRGAN模型生成的图像更加自然清晰,更符合人眼的视觉效果.尽管SRGAN模型取得了很好的视觉效果,但是随着网络的加深,SRGAN模型生成的图像也会在细节上出现模糊,在图像纹理上出现伪影.
基于SRGAN出现的问题,Wang等[17]对SRGAN模型进行了改进,提出了ESRGAN模型. ESRGAN模型对SRGAN模型进行了3个方面的改进.首先,引入没有批量归一化的RRDB(residual-inresidual dense block)作为基本的网络架构单元.其次,使用相对平均GAN(RaGAN)改进判别器网络,有助于生成器网络恢复更多的真实纹理细节.最后,提出了一种改进的感知损失,使用激活之前的VGG特征代替SRGAN模型中激活之后的VGG特征,调整之后的感知损失提供了更清晰的图像边缘和视觉上更令人满意的结果.
1.4 创新与改进
不论是传统的图像超分辨率方法,还是基于深度学习的图像超分辨率方法,其关注的研究领域大都是从低分辨率图像恢复出高分辨率图像,较少研究现实生活中存在的复杂的低分辨率图像,例如低分辨率图像同时存在低光照、模糊、噪声等情况.这就导致了在用模型处理现实中的低分辨率图像时,生成图像的效果并不好.
本文的融合光照损失的图像超分辨率生成对抗网络(image super-resolution generative adversarial network based on light loss,LSRGAN)模型是在SRGAN模型的基础上进行创新:
(1)LSRGAN模型能够实现在低光照条件下的图像超分辨率重建.
(2)提出新的损失为光照损失.利用RGB颜色空间与YIQ颜色空间的线性关系计算出图像中的亮度分量,将图像中的亮度作为损失函数,更好地恢复低光照条件下的低分辨率图像.
(3)将图像的结构相似性作为损失函数添加到原有的损失中,这有利于生成更加真实、自然的图像,提高图像的感官质量.
(4)构建新的训练数据集.先将高分辨率图像进行变黑处理,得到人造的低光照图像.然后使用双三次插值法进行下采样,得到低光照条件下的低分辨率图像.
2.1 模型损失函数
LSRGAN模型的网络结构如图1所示.

图1 网络结构图 Fig. 1 Structure diagram of network
LSRGAN模型在对抗过程中的目标函数为

其中:G为生成器网络,θ为生成器网络的网络参数;
D为判别器网络,ϕ为判别器网络的网络参数;
E为期望,IHR为真实高分辨率图像,ILR为低分辨率图像;
Pdata( IHR)为真实高分辨率图像的分布,Pdata( ILR)为低分辨率图像的分布;
G ( ILR)为生成器网络生成的超分辨率图像,D ( IHR)为当输入图像为真实高分辨率图像时判别真伪,D (G( ILR))为输入图像为超分辨率图像时判别真伪.
LSRGAN模型生成器网络的全部损失函数为

其中:α、β、γ、δ为模型的超参数,为光照损失,为内容损失,为结构相似性损失,为对抗损失.

其中:ISR为超分辨率图像;
IHR为高分辨率图像;
Y为图像亮度,Y = 0.299 R + 0.587G +0.144B,R、G、B分别为图像的RGB三通道值.

相较于基于像素的内容损失,基于式(4)内容损失生成的图像具有更好的视觉效果.
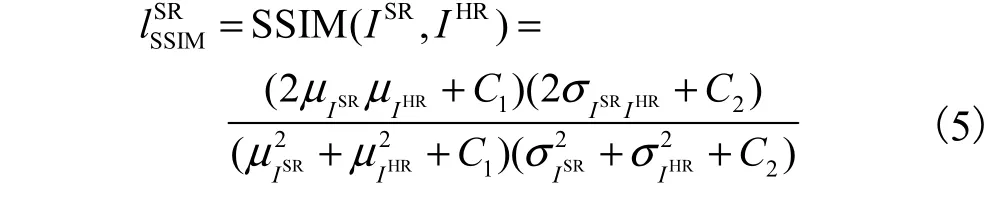
其中:ISR为生成的超分辨率图像,IHR为真实的高分辨率图像;
μISR为ISR的平均值,μIHR为IHR的平均值;
为 ISR的方差,为 IHR的方差,σISRIHR为ISR和IHR的协方差;
C1=( k1l)2,C2= ( k2l)2,C1和 C2为维持稳定的常数,l为像素值的动态范围,k1= 0.01,k2= 0.03.结构相似性的范围为0~1,当两张图像一模一样时,SSIM的值等于1.
对抗损失lDSR是基于判别器网络,判别器网络用于区分真实的高分辨率图像和生成的高分辨率图像,对抗损失可以有效提高生成图像的视觉效果,其表达 式为

其中:G为生成器网络,D为判别器网络,G ( ILR)为生成器网络生成的超分辨率图像,D (G( ILR))为输入图像为超分辨率图像时判别真伪.
LSRGAN模型在训练过程中,根据式(1)中的目标函数,对生成器网络和判别器网络进行交替优化,解决对抗最小-最大问题,得到最优的生成器网络的网络参数θ和判别器网络的网络参数ϕ.
2.2 生成器网络结构
生成器网络包括特征提取单元、深度残差单元以及上采样单元3个主要部分.生成器网络的结构示意图如图2所示,其中特征提取单元包括64个卷积核大小为3×3的卷积层和ReLU层,低分辨率图像先经过该卷积层进行卷积特征提取,然后通过ReLU函数进行激活.深度残差单元包括12个残差块,用于进一步对特征提取单元提取到的特征图进行特征学习并提取高频信息.每个残差块内部依次为卷积层、批标准化BN层、ReLU层、卷积层、批标准化BN层和残差边.卷积层进行特征图的特征提取,批标准化BN层对特征图的特征进行标准化,以减少模型的计算量.用ReLU函数进行激活,给学习到的特征图增加非线性元素.残差边将输入和输出进行叠加操作,避免因网络层数太多而导致梯度消失的问题.上采样单元由1个反卷积层和ReLU层组成,用于根据提取的高频信息将低分辨率图像进行指定倍数的放大〔本文是将低分辨率(LR)图像的长和宽均放大3倍〕,从而得到超分辨率图像.

图2 生成器网络的结构示意图 Fig. 2 Structure diagram of generation network
2.3 判别器网络结构
判别器网络用于区分超分辨率图像和真实的高分辨率图像,促进生成器网络生成效果更好的超分辨率图像.判别器网络的结构示意图如图3所示.判别器网络由卷积块和全连接层组成.其中卷积块由卷积核大小为3×3的卷积层、LeakyReLU层以及批标准化BN层组成,用于不断地提取输入图像的特征.
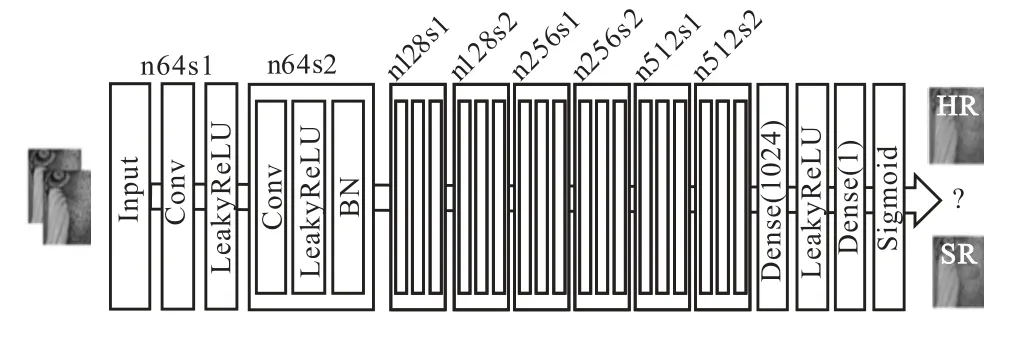
图3 判别器网络的结构示意图 Fig. 3 Structure diagram of discrimination network
输入至判别器网络的图像先经过卷积核大小为3×3、通道数为64的卷积层进行特征提取,然后经过LeakyReLU函数进行激活.通过7个组成相同的卷积块进一步提取图像特征,随着特征图大小的不断减少,通道数不断增多,分别为64、128、128、256、256、512、512,将神经网络学习到的特征存储到通道中.最后经过全连接层进行分类,Sigmoid层计算出输入图像是真实高分辨率图像的概率.
3.1 实验设置
实验在NVIDIA GeForce RTX 3090GPU上训练所有网络,所有实验均在低分辨率和高分辨率图像之间以3倍的尺度因子执行.为了公平比较,所有实验的PSNR和SSIM度量均使用TensorFlow封装好的方法计算.优化器为Adam,学习率为0.0002,数据的批量处理大小为16,更新迭代13000次.
训练数据来自数据集 BSDS200[31]、Genral-100[9]、DIV2K[32]和Flickr2K[33]中随机采样的高分辨率图像,训练数据集详细信息见表1.BSDS200数据集是BSDS500数据集的训练子集,由伯克利大学提供,常用于图像分割、轮廓检测和图像超分辨率重建.General-100数据集有100张图像,里面包含人物、动物、日常景象等.DIV2K数据集有1000张高分辨率图像,其中800张用于训练,100张用于验证,100张用于测试.Flickr2K数据集有2650张高分辨率图像,里面包含人物、动物、日常景象等.

表1 训练数据集详细信息 Tab. 1 Details of training dataset
测试数据来自Set5[34]、Set14[35]、BSDS100[36]和Urban100[19]数据集,测试数据集详细信息见表2. Set5数据集有5张图像,里面含有人物、动物、昆虫等.Set14数据集有14张图像,里面含有人物、动物、自然景象等.BSDS100数据集有100张图像,是BSDS500数据集的测试子集.Urban100数据集有100张图像,里面包含各种建筑物.

表2 测试数据集详细信息 Tab. 2 Details of test dataset
3.2 构建新的训练数据集
对随机采样得到的高分辨率图像进行随机裁剪,裁剪成224像素×224像素大小的高分辨率图像;
挑选裁剪后的图像,剔除不符合要求的图像;
最终得到3428张高分辨率图像.对裁剪、挑选后得到的3428张高分辨率图像先得到其灰度图,然后通过减少灰度图的灰度值减少图像的亮度,接着使用双三次插值法进行下采样,得到低光照低分辨率图像.这一步可以用公式表示为

式中:ILR为所求的低光照低分辨率图像;
IHR为高分辨率图像;
↓s表示下采样;
s为下采样的尺度因子;
f(⋅)为用于将高分辨率图像进行变黑处理的函数,其中 f( IHR) =α⋅ IHR+γ⋅ ones(size( IHR)),α为超参数,γ为黑度参数.
3.3 精度对比
对比Bilinear、SRCNN、SRFBN[19]、SRGAN和LSRGAN这5个模型在黑度参数γ分别为-70、 -130和-160条件下的精度,即对比PSNR和SSIM.
首先在构造的训练数据集(在数据集BSDS200、Genral-100、DIV2K和Flickr2K中随机采样)上进行训练,然后在4个测试数据集BSDS100、Set14、Set5和Urban100上进行测试.测试时,先对测试数据进行3.2节中的变黑处理和下采样处理,然后对处理后的测试数据进行测试,实验结果见表3和图4.
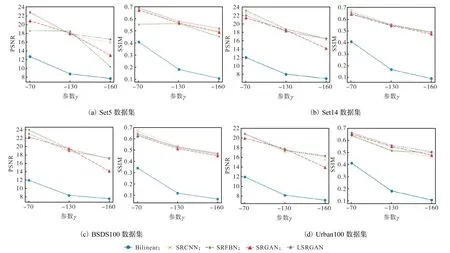
图4 定性结果实验对比 Fig. 4 Qualitative results of experimental comparison
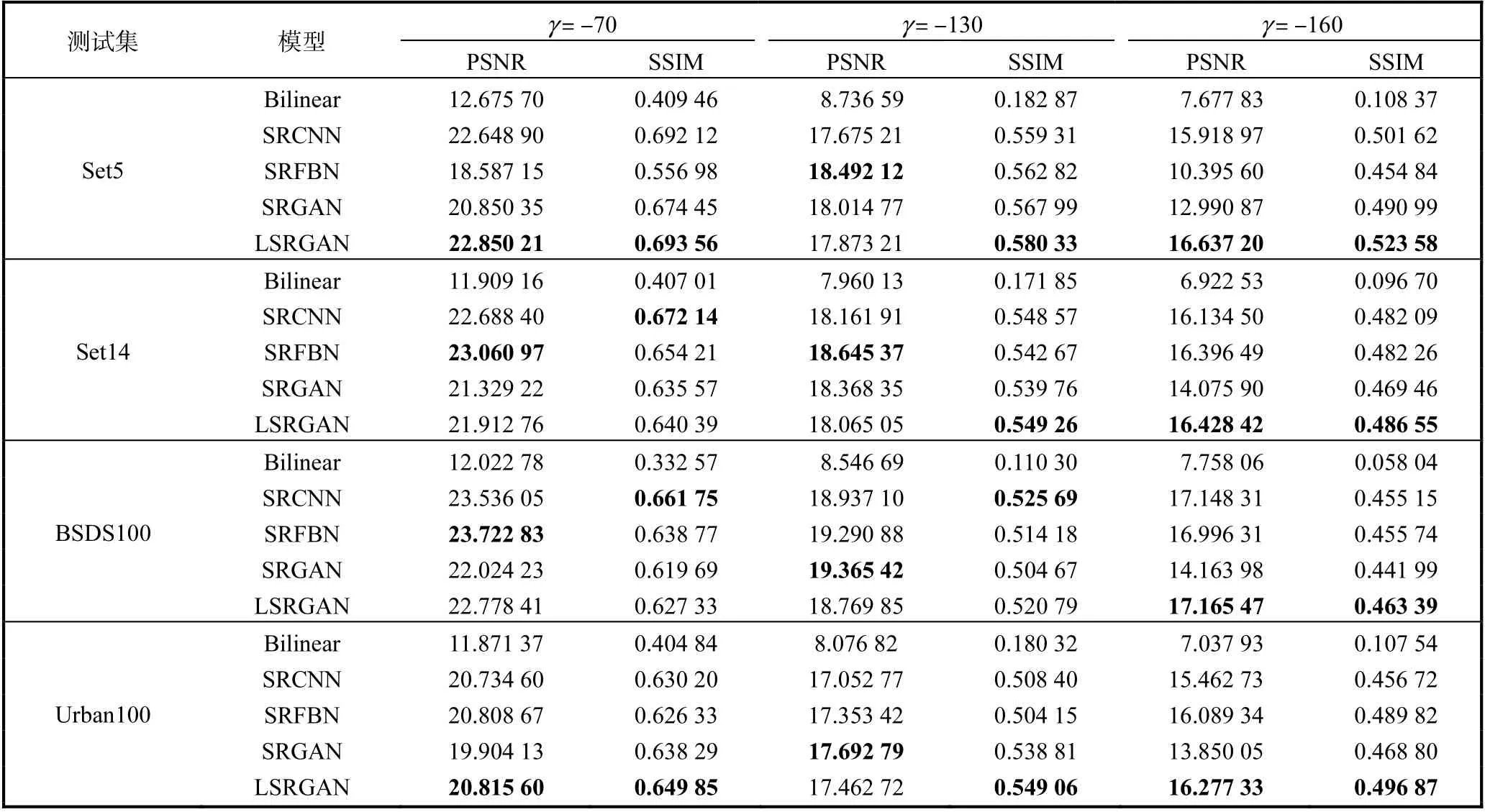
表3 定量结果实验对比 Tab. 3 Quantitative results of experimental comparison
由表3可知:黑度参数γ的值越小,图像的亮度就越低,图像超分辨率重建的难度越大.当黑度参数γ= − 70时,测试图像的亮度改变不大,亮度减小的程度对测试图像的影响较小,此时LSRGAN模型在4个测试数据集上的8个指标中取得了4个最好的结果,SRFBN模型取得了2个最好的结果,SRCNN模型取得了2个最好的结果.当黑度参数γ=− 130时,测试图像的亮度改变较大,亮度减小的程度对测试图像的影响较大,此时LSRGAN模型在4个测试数据集上的8个指标中取得了3个最好的结果,SRFBN模型取得了2个最好的结果,SRGAN模型取得了2个最好的结果,SRCNN模型取得了1个最好的结果.当黑度参数γ=− 160时,测试图像的亮度改变很大,亮度减小的程度对测试图像的影响很大,此时仅凭肉眼很难分辨出测试图像的内容.在这种情况下,LSRGAN模型展现出了绝对的优势,在4个测试集上的8个指标全部取得了最好的定量结果.综上所述,LSRGAN模型在整体上表现最好,且随着图像亮度的降低,LSRGAN模型的生成效果越来越好;
当图像的亮度很低且影响到图像内容的观测时,光照损失发挥了很重要的作用,此时LSRGAN模型具有很好的生成效果.
由图4可知:随着黑度参数γ的值逐渐减小,图像的亮度逐渐降低,图像超分辨率重建的难度逐渐增大,模型的生成能力逐渐减弱.此时,LSRGAN模型的折线斜率变化最小,这表明LSRGAN模型的生成能力受图像亮度降低的影响最小.因此可以得出结论,当图像逐渐变暗时,LSRGAN模型受图像亮度降低的影响最小,LSRGAN模型依然具有很好的模型生成能力,可以生成视觉效果较好的图像.
3.4 生成图像对比
3.4.1 公共测试集
为了进一步展示5种模型的生成效果,在公共测试集Set14中随机选择1张图片,在黑度参数γ分别为-70、-130和-160时进行生成测试,生成结果如图5所示.
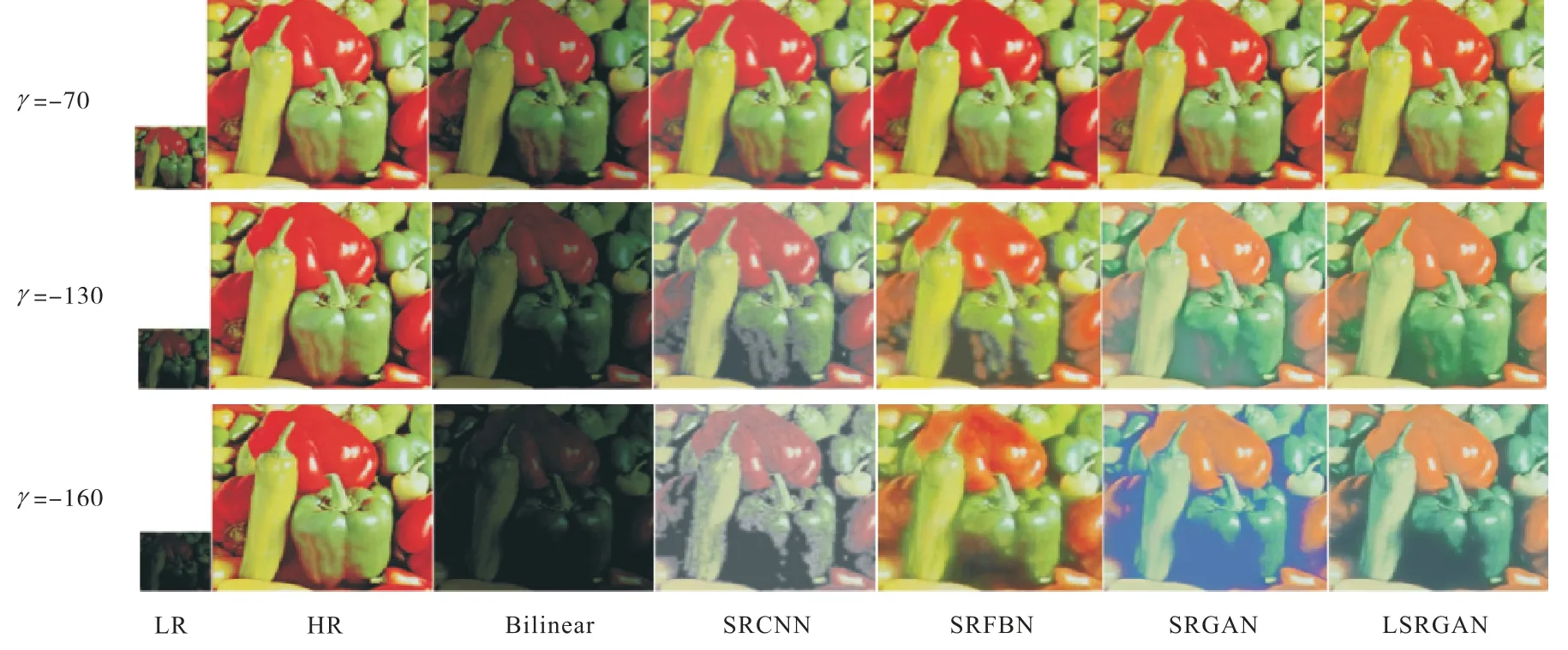
图5 公共测试集Set14的模型生成图像效果展示 Fig. 5 Model generation image effect display of public test Set14
在公共测试集Urban100中随机选择1张图片,在黑度参数γ分别为-70、-130和-160时进行生成测试,生成结果如图6所示.

图6 公共测试集Urban100的模型生成图像效果展示 Fig. 6 Model generation image effect display of public test Urban100
根据图5和图6可知:随着黑度参数γ的值越来 越小,低分辨率图像的亮度越来越低;
当γ=− 1 60时,图像几乎全黑,此时图像中包含的有用信息很少,将其恢复成高分辨率图像是十分困难的.
从生成图像的效果可以看出,LSRGAN模型可以实现在低光照条件下的图像超分辨率重建,并且生成的图像具有较好的视觉效果.
3.4.2 真实图像
在模型的训练和测试时,训练数据和测试数据的低光照条件都是人为构造的,如此得到的低光照图像是线性的,整个图像的亮度一起降低.为了进一步验证模型的生成能力,收集了现实生活中的低光照图像进行测试.将现实生活中的低光照图像进行3倍下采样处理,这里不需要进行变黑处理;
然后将处理后的图像输入模型进行测试,生成结果如图7所示.

图7 现实生活中的低光照图像的模型生成图像效果展示 Fig. 7 Model generation image effect display of low light image in real life
由图7可知:现实生活中的低光照图像情况比较复杂,可能存在局部亮度低的问题,并且导致图像质量不高的原因是多方面的.在这种情况下,LSRGAN模型仍然具有较好的图像超分辨率和恢复光照的能力,可以处理现实生活中的低光照图像.
本文提出了一种融合光照损失的图像超分辨率生成对抗网络LSRGAN模型,并在实验中展示了模型定性指标PSNR和SSIM的值及模型生成图像的效果.与经典SRGAN模型的对比实验显示,该模型不仅能够实现一般情况下的图像超分辨率重建,而且可以实现在低光照条件下的图像超分辨率重建,并取得了较好的实验效果.理论分析及实验结果表明,LSRGAN模型中的光照损失和结构相似性损失可以帮助恢复图像的光照强度,具有较好的恢复效果,同时使生成的图像具有较好的视觉效果.
猜你喜欢 高分辨率光照分辨率 肉种鸡的光照不应性对养殖生产的不良影响分析中国动物保健(2022年10期)2022-11-04基于GEE云平台与Sentinel数据的高分辨率水稻种植范围提取——以湖南省为例作物学报(2022年9期)2022-07-18高分辨率CT+人工智能在新型冠状病毒肺炎诊断与疗效评估中的应用研究中国典型病例大全(2022年12期)2022-05-13探讨高分辨率CT在肺部小结节诊断中的应用价值健康体检与管理(2021年10期)2021-01-03隐蔽的力量小资CHIC!ELEGANCE(2019年40期)2019-12-10基于异常区域感知的多时相高分辨率遥感图像配准计算机应用(2016年10期)2017-05-12ARM发布显示控制器新品重点强化对分辨率的支持CHIP新电脑(2016年3期)2016-03-10水禽舍的光照及其控制水禽世界(2015年6期)2016-03-04蛋鸭的光照管理水禽世界(2014年4期)2014-09-21从600dpi到9600dpi微型计算机(2009年4期)2009-12-23推荐访问:光照 对抗 融合推荐文章
- 2018年江西赣州市医疗急救中心招聘编外人员公告:赣州市医疗急救中心
- 升学宴策划活动方案|2018升学宴活动方案
- 小学六一游园活动总结 [小学六一游园活动策划]
- 2018年中国工商银行广东分行暑期实习生招聘岗位、报名时间:2018中国工商银行广西分行春招
- 澳洲留学八大名校排名申请条件_澳洲留学奖学金申请条件及时间
- [调工商档案介绍信范文] 工商档案查询介绍信
- 加拿大亲属移民政策最新更新|加拿大亲属移民条件
- 初一下册语文练习册答案人教版2018 2018人教版语文练习册答案
- 贵州贵阳房价2018 2018年贵州贵阳中医学院第二附属医院招聘方案
- 【2018广东省湛江市赤坎区审计局招聘公告】2018湛江市赤坎区教师招聘