新型的锅炉燃烧系统数据处理复合模型
来源:优秀文章 发布时间:2022-11-19 点击:
刘 超 唐志卓 曹宇佳
(1.大唐吉林发电有限公司,2.大唐长春第三热电厂)
火力发电系统的核心工艺为:在锅炉内煤粉燃烧产生蒸汽,进一步驱动蒸汽轮机,实现电能的生产。锅炉燃烧系统是发电站的核心系统,是提高锅炉系统的燃烧效率,提升火力发电系统整体效益和节能的重要途径。传统燃烧系统中,在燃烧室内引燃通过给煤系统喷入煤粉和压缩空气的混合物,驱动四管(水冷壁、过热器、再热器和省煤器)循环系统实现对蒸汽压力、循环水温度的控制,是锅炉燃烧系统的核心功能。当前锅炉燃烧系统的控制过程中,利用各种物联网探头采集锅炉燃烧系统数据,使用更大算力的计算中心主机系统进行数据分析,进而控制各种泵压、阀门状态、给煤量、压气量等对燃烧过程进行优化,其中存在较多的技术提升切入点。文章重点就电站锅炉燃烧系统的数据采集、融合过程构建复合模型,以实现相关技术的提升。
锅炉燃烧系统主要由2个组成部分,一是压气循环系统,负责将煤粉与压缩空气混合后送入燃烧室进行燃烧,进而将烟气排出燃烧系统;
二是水蒸气循环系统,将低温水经过省煤器泵入炉壁进行加热形成蒸汽,再通过过热器、再热器系统,使蒸汽的温度和压力达到炉外系统的做功需求,详见图1。
温度与压力是锅炉燃烧系统的主要采集数据参数,同时通过采集压气循环系统中的气体分压,确定燃烧程度。锅炉燃烧系统的数据采集任务包括监测四管的多点温度、压力、燃烧室的温度分布,监测四管的压风循环进出口气体温度及压力,监测尾气输出端尾气成分。数据反馈任务包括:压气系统压力控制所需的风门控制策略,主鼓风机控制策略、尾气负压控制策略等,以及低温水回流泵的控制策略、水蒸气循环系统中各电控阀门的控制策略等。详见图2。

图1 锅炉燃烧系统
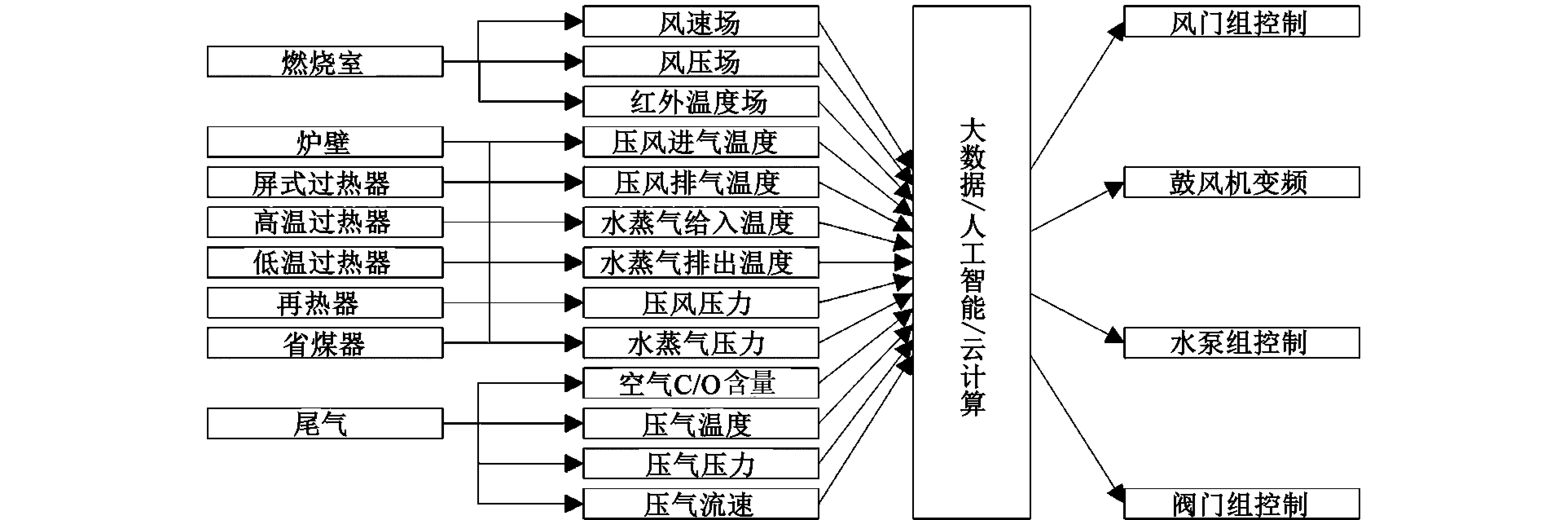
图2 锅炉燃烧系统数据流图
图2中,采集所有四管系统中四个接口的压风和水蒸气温度,同时检测系统中的压风和水蒸气压力;
对尾气来说,检测其中的C元素和O元素含量,同时对其温度、压力、流速进行监测;
燃烧室中的监测稍复杂,需要对温度、风压、风速进行场分布监测。
2.1 传统模式下的数据复合模型
受到篇幅限制,此处不详细展开每个具体数据的采集过程和原始数据特征,但所有采集数据均为带量纲数据,数据的量纲和区间都有不同,进入大数据系统后,必须进行去量纲处理并统一其在数据区间中的投影落点。当前电力控制系统的大数据去量纲算法一般采用Z-Score算法:
(1)
式中:Xi和Yi为数据列中第i个去量纲数据的输入值和输出值;
μ为该列数据的算数平均数;
σ为该列数据的标准差。
(2)
(3)
式中:N为该列数据的总记录长度。
公式(1)的完整形式为:
(4)
可见,在持续产生数据的电站锅炉运行系统中,不论数据分析窗口的长度N定义为多大,数据均会根据分析窗口的移动,影响μ和σ的结果,使相同监测数据在不同时间窗口内的最终输出结果Yi发生变化,即相同的Xi和Yi对应关系并非保持恒定。这是传统模式下数据复合模型的最大缺点。
2.2 改进的数据复合模型
鉴于所有数据进入到大数据分析系统前,均需要进行去量纲处理,即数据本身的物理学意义对实际数据分析决策并不能产生实质性影响,所以,可以抛弃传统数据复合模型中的移动窗口概念,采用实时数据,使用单行数据进行数据去量纲计算,即将所有的温度、压力、风速、含量数据进行前置加权整合数据落点后,对其再进行一次基于公式(1)和公式(4)的数据去量纲处理,形成实时数据的复合处理。
数据的前置落点策略:
(5)
式中:Xi,Yi为该列数据的第i个输入值和其对应的第i个输出值;
min,max为该列数据的理论最小值和理论最大值;
min′,max′为统一落点区间的最小值和最大值;
经过公式(5)处理后,未经过去量纲处理的数据落点也会被统一到[min′,max′]区间上,为数据的后续处理提供数据治理过程。此后,将实时数据中产生的温度、压力、风速数据形成单独数据列,代入公式(4),获得相应的数据复合结果。
选择某发电站1号机组锅炉燃烧系统在2019年运行数据作为数据仿真测试的背景数据,保持该锅炉燃烧系统的云计算系统(C.C.)、大数据系统(B.D.)、人工智能系统(A.I.)整体架构不变,根据上述对传统数据复合模型和改进数据复合模型的设计,使用Simulink数据仿真平台模拟改进系统的燃烧过程,使用Python数据分析平台软件构建仿真实验室平台。分析得到锅炉的燃烧效率、单位煤耗、单位电耗和经济效益视角下的利润比等数据,如表1所示。

表1 数据复合模型技改前后的实测数据比
使用改进的数据复合模型,煤炭燃烧效率从76.7%提升到89.3%。在电站其他系统架构和调试参数保持不变的前提下,单位煤耗从0.463 kgce/kWh降低到0.397 kgce/kWh,节煤率为14.25%;
消耗的厂用电从0.169 kWh/kWh压缩到0.094 kWh/kWh,节电率为44.38%。
该电站4个机组2019年全年全电站耗16万tce,单纯采用新型数据复合模型的技术改进策略,可节约2.28万tce,实现CO2减排6.93万t。即该数据复合模型可实现经济效益,获得显著的环境效益。该电站2019年全年税前毛利润1 251万元,其电站理论利润提升108.2万元。
该数据复合模型的技术提升创新点在于充分排除移动数据窗口策略条件下因为数据发生值的变化对数据投影带来的扰动,使数据采集和数据复合过程的扰动情况得到充分遏制,从而提升数据精度,优化了人工智能系统的运行稳定性和可靠性。仿真试验证明,在保持其他系统运行状态和调试策略不变的前提下,单纯优化电站锅炉燃烧系统的数据复合模型,可节约2.28万tce,CO2减排6.93万t,理论新增税前毛利润108.2万元,可见该数据复合模型获得了显著的经济效益及环境效益。
猜你喜欢 落点电站控制策略 AMT坡道起步辅助控制策略汽车实用技术(2022年15期)2022-08-19基于强化学习的直流蒸汽发生器控制策略研究舰船科学技术(2022年11期)2022-07-15钳工机械操作的质量控制策略内燃机与配件(2022年2期)2022-01-17蔚来部署第二代换电站最大容量13块电池中国计算机报(2021年10期)2021-04-27关注有效落点 优化交往策略——小学英语课堂师生交往策略福建基础教育研究(2019年3期)2019-05-28采用并联通用内模的三相APF重复控制策略电机与控制学报(2018年9期)2018-05-14心的落点当代文萃(2010年5期)2010-05-21心的落点小品文选刊(2009年10期)2009-05-27推荐访问:数据处理 锅炉 模型