基于联邦学习的SDN,异常流量协同检测技术
来源:优秀文章 发布时间:2023-04-25 点击:
陈何雄,罗宇薇,韦云凯,郭 威,杭菲璐,何映军,杨 宁
(1.云南电网有限责任公司 信息中心,昆明 650011;
2.电子科技大学 长三角研究院(衢州),浙江 衢州 324000;
3.电子科技大学 信息与通信工程学院,成都 611731)
软件定义网络(Software-Defined Network,SDN)通过采取数控平面分离、控制逻辑集中等方式提高了网络可编程性和灵活性,并简化了网络配置过程,有利于实现网络性能拓展,保障网络高效运行[1],被广泛应用于云数据中心、政企网络等场景[2]。但与此同时,SDN 也面临了分布式拒绝服务(Distributed Defend of Services,DDoS)[3]、拓扑中毒、端口扫描等网络攻击,考虑到攻击发生时常常伴有流量异常现象,因此实施异常流量检测以提升网络对攻击的识别能力是加强网络安全的重要手段。
异常流量检测与识别算法大致可分为基于规则和基于机器学习[4-5]两类检测算法。基于规则的检测算法一般会通过分析与流量特征相关的统计数据、参数信息等来鉴别异常流量。文献[6]提出一种应用于SDN 网络的基于参数统计的识别算法,由控制器负责对流量数据包大小、持续时间等信息量进行统计,以此作为异常流量的判断依据。文献[7]提出一种基于目的IP 地址熵变化的检测算法来检测SDN 网络中的DDoS 攻击,根据网络流量调整熵阈值,以此判断是否受到攻击。这类基于规则的检测算法通常针对某一类特征明显的攻击行为,可识别的异常类型较少,且识别效果主要取决于与异常类型紧密联系的阈值设定,不具备学习性,不利于推广和拓展。支持向量机[8-9](Support Vector Machine,SVM)、K 最邻近(K-Nearest Neighbor,KNN)规则分类[10]、K 均值聚类[11]等基于机器学习的检测算法得到了更广泛的研究与应用[8],但这些算法虽然能够检测出流量异常,却忽略了异常行为之间可能存在的关联度,难以检测与时间相关的多步攻击行为[12]。文献[13]提出一种基于卷积神经网络(Convolutional Neural Network,CNN)和长短期记忆(Long Short-Term Memory,LSTM)网络的异常流量检测方法,通过提取流量数据的时空特征来提高异常流量检测性能。
然而,由于流量的动态变化,网络规模、终端设备等因素都会引起流量的特征差异[14],因此异常流量检测效果还与检测范围等因素密切相关。对于规模较大的网络,如果只在SDN 控制器处部署检测节点,会导致覆盖检测范围不足,难以有效防御网络攻击。而在部署多个检测节点的情况下,在检测模型训练时,节点可能面临训练数据缺乏、协同性较差的问题。文献[15]提出将联邦学习架构与机器学习算法相结合,以解决训练数据缺乏的问题,并提升了检测准确率。但是,在传统联邦学习中,由于参数更新时直接使用全局参数进行训练,最终得到的是全局唯一的模型,并未考虑检测模型的应用环境和数据差异,因此模型性能很难在不同应用环境下得到充分发挥。
为解决以上问题,本文提出基于联邦学习的异常流量协同检测技术。结合SDN 网络拓扑与流量特征,构建基于联邦学习的协同检测架构,以克服单个检测设备可能面临的训练数据缺乏问题,增强检测设备的协同能力。依据各检测节点流量特征及其变化关联关系,设计协同训练中的参数聚合权重优化算法,利用全局参数和各检测节点的本地参数进行模型训练,实现差异环境中检测模型的整体优化。
考虑到网络异常流量检测的场景特点,本文从信息熵与相对熵的角度分析流量特征及其变化,并基于联邦学习技术提出异常流量协同检测架构。
1.1 联邦学习
联邦学习的本质是一种分布式机器学习技术,以解决机器学习在发展过程中所面临的数据安全与数据孤岛问题。在联邦学习中,各训练节点在参数聚合节点的协调下共同训练模型[16],实现了在不交换原始数据的情况下更新客户端应用。
联邦学习技术作为网络安全领域的研究热点,受到了研究人员的广泛关注[17]。由于应用场景不同,训练节点的数据集特点不同,依据数据集的特点,联邦学习可分为横向联邦学习、纵向联邦学习和联邦迁移学习[18]3 种类型。横向联邦学习的本质是样本的联合,在训练完成后进行独立预测,适用于各训练节点的数据集样本对象重叠少、特征信息重叠多的场景。纵向联邦学习的本质是将多方对相同样本目标的不同特征描述进行训练提取[19],在训练结束后需要多方协同完成预测,适用于各训练节点的数据集样本对象重叠多、特征信息重叠少的场景,例如不同行业的企业间合作建立模型。在联邦迁移学习中,可以在目标任务训练数据较少的情况下,将前一个任务的知识转移到目标任务上[20],常用于解决当各训练节点的样本对象和特征信息重叠都较少时标签样本和数据缺乏的问题。在SDN 网络异常流量检测的场景中,网络流量的特征信息大抵相同,但不同位置的检测节点能用于训练的流量样本大多不同,这与横向联邦学习的应用场景特点相符。
1.2 信息熵与相对熵
网络流量数据由离散的信息源组成,熵可以度量系统参数分布的变化情况,描述流量在某些维度上的分布状况,信息熵、相对熵等[21]常用于分析流量变化。将流量特征属性看作随机变量,通过计算各特征属性的信息熵,可以有效反映当前网络流量的特征属性变化和分布情况。流量特征的信息熵[22]可据式(1)进行计算:
相对熵可以度量两个随机序列之间的距离,从统计学角度上来看,它是指两个随机序列的相似程度[23]。令两个 随机序列为P和Q,有P={pv|v=1,2,…,V},Q={qv|v=1,2,…,V},其相对熵D(P||Q)可以据式(2)进行计算:
当P=Q时,D(P||Q)=0,即当两个序列完全相同时,它们的相对熵值为0。D(P||Q)的值越小,表示序列P和Q越相似,反之则相差较大。
考虑到信息熵常用于提取流量数据特征[24],本文通过计算各检测节点的流量熵形成特征序列,再由参数聚合节点计算特征序列的相对熵,以衡量检测节点的变化关联性,作为参数权重优化的依据。
为解决SDN 网络中流量检测节点间协同不足、异常流量动态变化适应能力差等问题,本文结合SDN 的拓扑特点与流量特征,应用联邦学习技术增强检测节点间的协同能力,建立基于联邦学习的异常流量协同检测架构,并提出参数聚合权重优化算法,整体优化检测模型,提升网络对异常流量的识别能力。
在当前面向SDN 的智能检测模式中,各检测节点往往基于本节点所属区域进行检测模型的训练与实施。这种方式导致了检测节点的检测类型局限性与对流量变化适应能力差等问题。考虑到网络攻击可能发生在网络的任意区域,攻击目标也可能是全局网络的任意区域,本文提出基于联邦学习的异常流量协同检测架构,从而提高检测节点对多区域攻击和动态攻击的适应能力。如图1 所示,在所提协同架构中,检测节点分布于SDN 各区域网络,这些检测节点使用联邦学习方式聚合所训练的模型,并由此优化各检测节点自身的检测模型。结合SDN网络的特征,联邦学习中的参数聚合节点可以部署在SDN 控制器或者是与SDN 控制器高速连接的服务设备上。在联邦学习时,各检测节点首先利用本地数据进行检测模型训练,上传模型参数至参数聚合节点处汇总,然后由参数聚合节点依据参数聚合权重更新各检测节点的模型参数,以供各检测节点进行下一轮训练。在实际检测中,分布在网络不同位置的检测节点实施多点检测。需要注意的是,检测节点的部署应以网络规模与结构特点为导向,可结合实际需求参考现有部署方案确定。检测节点通常连接在某个网络交换设备上,由该交换设备将网络流量转发到检测节点。考虑到检测需求,检测节点一般不会部署在网络的边缘区域,而是连接到容量较大的核心交换设备上。因此,这种流量转发方式局限于检测节点与核心交换设备之间的高速链路,不会对该链路带来较大的通信负担,更不会影响该链路以外网络业务的正常运行。
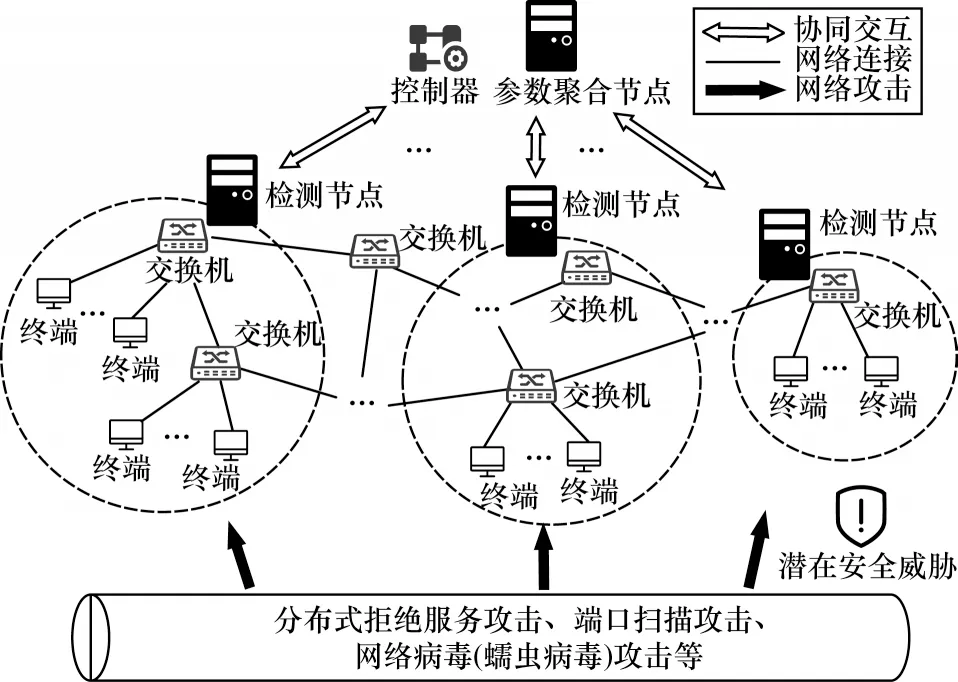
图1 基于联邦学习的异常流量协同检测架构Fig.1 Architecture of collaborative anomaly traffic detection based on federated learning
因此,本文所提的基于联邦学习的异常流量协同检测技术的核心在于基于联邦学习的多检测节点协同流程,以及在该流程下的参数聚合权重优化算法。
在基于联邦学习的多检测节点协同流程中,参数聚合节点协同分布在网络不同区域,检测节点在联邦学习架构下训练异常流量检测模型。检测节点先利用本地流量数据进行模型训练得到本地参数,再根据参数聚合节点所更新的模型参数在协同架构下训练模型;
参数聚合节点先根据各检测节点的本地参数计算全局参数,再依据参数聚合权重优化算法确定各检测节点在参数聚合中的本地参数权重和全局参数权重,并基于此权重更新各检测节点用于下一轮训练的模型参数。通过参数聚合节点对各检测节点的协同,间接利用全局数据特征以改善数据不足的问题;
通过加权方式更新检测节点的模型参数,避免直接利用全局参数导致本地数据特征被覆盖。
为在利用全局数据特征和保留本地数据特征之间寻求权衡,基于上述协同流程提出参数聚合权重优化算法。该算法包含特征提取和关联度与权重计算两个阶段。在特征提取阶段,检测节点通过处理其所处区域的流量数据提取特征序列,先根据检测需求等实际因素选取流量特征,再计算检测节点的流量特征熵,形成流量特征序列来反映检测节点的流量变化情况。在关联度与权重计算阶段:首先,参数聚合节点基于各检测节点的特征序列,计算近似反映全局流量变化的特征序列;
然后,依据检测节点特征序列与参数聚合节点特征序列的相对熵,量化检测节点的流量变化关联度;
最后,基于此关联度确定各检测节点相应参数聚合时的本地参数权重和全局参数权重。通过对检测节点本地参数和全局参数的加权聚合,提升模型的检测准确率和对差异环境的适应性。
本节将对基于联邦学习的SDN 网络异常流量协同检测架构中的多检测节点协同训练流程,以及训练过程中的参数聚合权重优化算法进行具体介绍与说明。
3.1 多检测节点协同机制
将参数聚合节点表示为C,则C在联邦学习中计算的全局参数为gC;
将检测节点集合表示为D,其数量表示为m,则有D={d1,d2,…,dm},检测节点dj(j≤m,j∈N+)在联邦学习中所训练模型的本地参数为gj;
将全局参数gC与本地参数gj在参数更新时的权重分别表示为。在多检测节点协同过程中,检测节点dj在参数聚合节点C的组织下协同训练检测模型。基于协同检测架构的多检测节点协同训练流程如图2 所示。

图2 多检测节点协同训练流程Fig.2 Procedure of multiple detection nodes collaborative training
首先,参数聚合节点C基于流量变化关联度求出各检测节点在参数更新中的全局参数权重与本地参数权重wdj。
然后,在检测节点dj使用本地数据训练得到本地参数gj后,将gj上传给参数聚合节点C,参数聚合节点C据式(3)计算全局参数gC:
最后,参数聚合节点C据式(4)计算检测节点dj用于下一轮训练的参数,并将g"j发给检测节点dj,dj使用更新后的参数更新本地模型。
重复上述步骤,直到损失函数收敛,或者达到迭代次数上限,就停止训练并保存当前检测模型,具体步骤如算法1 所示。
算法1多检测节点协同训练算法
利用联邦学习架构实现多检测节点检测模型的协同训练与更新,通过加权方式结合本地参数和全局参数实现模型优化。对于联邦学习面临的通信成本问题,通常可从减少通信轮次和降低通信数据量两方面进行考虑[25],例如应用AdaGrad[26]等算法加速模型收敛,减少通信轮次,或应用PowerSGD[27]等算法压缩所需传输的模型,降低通信数据量。考虑到由检测节点流量采集、检测节点与服务器间参数交换带来的两种流量在网络交换设备与检测节点间的链路上是叠加的,因此对通信需求进行分析。以神经网络为例,模型参数数量的量级约为107[28],若每个参数占8 个字节,则所需传输的原始数据量约在百兆字节,而通过量化压缩等算法可以将该数据量降低两个数量级[29],则所需传输数据量可降至兆字节。考虑到检测节点与交换设备之间的高速链路带宽一般在百兆至千兆,因此由流量采集和参数交换所引入的通信需求仍在链路的承受范围内。
3.2 参数聚合权重优化算法
为寻求全局参数和本地参数的权衡,关联各检测节点数据特征变化与其模型训练优化,在基于联邦学习的多检测节点协同机制下提出参数聚合权重优化算法。
如图3 所示,参数聚合权重优化算法分为特征提取和关联度与权重计算两个阶段。在特征提取阶段,各检测节点通过计算流量数据的信息熵形成特征序列。在关联度与权重计算阶段,由参数聚合节点基于特征序列计算相对熵得到各检测节点对应的参数权重。

图3 基于关联度的参数权重计算示意图Fig.3 Schematic diagram of parameter weight calculation based on correlation
3.2.1 特征提取
数据包的源、目的特征的统计特点在一定程度上反映了网络流量的状态变化,本文选择计算T个单位时间ti(i≤T,i∈N+)内流量特征的信息熵变化来分析检测节点的流量变化情况。本文以源IP 地址与目的IP 地址为例进行分析,在实际应用时,可据具体需求选取流量特征,T和ti的取值应当依据实际网络情况确定。参数聚合节点综合各检测节点的信息熵变化来近似得出整体网络的流量变化情况。将在第i个单位时间ti内检测节点dj的流量总数表示为,其源IP 地址有种,其目的IP 地址有种,将流量的源IP 地址表示为随机变量X,用xk(k∈N+)表示某一源IP 地址的出现次数,则检测节点dj处的源IP 地址信息熵可据式(5)进行计算:
3.2.2 关联度与权重计算
D(Hdj||HC)的值越小,说明序列Hdj与HC差异越小,反之说明序列Hdj与HC差异越大,当且仅当序列Hdj、HC完全相同,即Hdj=HC时,有D(Hdj||HC)=0。
的值越大,表明在协同更新中,全局参数在检测节点dj的参数更新时所占比例越大,反之,本地参数在检测节点dj的参数更新时所占比例越大。
参数聚合权重优化算法的具体步骤如算法2所示。
算法2参数聚合权重优化算法
由于信息熵计算是基于本地数据进行的,因此信息熵的计算过程不会引入额外通信开销。同时,在一次模型训练中,与信息熵相关的数据传输为一次性事件,不需要周期性上传。具体而言,在检测节点将基于信息熵计算得到的特征序列上传到聚合节点的过程中,需要传输的数据量受检测节点数、序列长度与特征值存储大小所影响。若训练节点数量级为103,序列长度量级为103,单个特征值存储占8个字节,则所需传输数据量大约在几兆到几十兆字节。考虑到SDN 网络的信道速率通常在百兆至千兆字节,信息熵的计算与传输引入的通信负载影响可以忽略不计。
基于Pycharm 平台与PyTorch 软件框架进行仿真,通过对数据量、包含攻击类型等因素进行考虑,选择UNSW-NB15 数据集[30]。通过删除可以清楚反映异常情况的特征和脏数据等方式对原始数据集进行预处理,选取与30 个网络IP 关联的83 545 条流量数据,再采用k-折交叉验证法以4∶1 的比例将数据集转化为训练集和测试集。仿真设置3 个检测节点负责网络不同区域的检测,由参数聚合节点协同各检测节点分别训练各自的GRU 模型作为检测模型,使用Adam 优化器,将交叉熵作为损失函数,每批次数据量为64,训练轮次为3 轮,初始学习率为1×10-4,分别采用本地独立训练、传统联邦学习和本文所提参数聚合权重优化算法训练模型,并对所得模型进行分析对比。
为全面验证本文所提算法的异常流量检测结果,仿真中使用分类任务常用的准确率(A)、分类器精度得分(F1)和曲线下面积(Area Under Curve,AUC)3 个度量指标[13],其中,准确率能直观表现模型识别结果,分类器精度得分是精确率与召回率的调和均值,能同时体现模型精确率与召回率的情况,AUC 值为ROC(Receiver Operating Characteristic)曲线下的面积,能直观反映分类器的性能。A和F1 值计算公式如式(12)和式(13)所示:
其中:TTP表示归类正确的目标样本数;
TTN表示归类正确的其他样本数;
FFP表示识别错误的目标样本数;
FFN表示被遗漏识别的目标样本数。
在上述设置下,在本地独立训练、传统联邦学习和本文所提算法的训练模式下检测节点1、节点2、节点3所得模型的准确率和ROC 曲线,如图4~图6 所示。训练过程的准确率比较如图4(a)、图5(a)、图6(a)所示,从训练轮次和收敛情况来看,本文所提算法并未影响模型训练的收敛,收敛后的准确率能达到90%以上。模型的ROC 曲线如图4(b)、图5(b)、图6(b)所示,综合来看,本文所提算法的性能较好,其中性能提升最明显的是节点1,其AUC值能提高到0.834 8,而本地独立训练和传统联邦学习下的AUC 值仅为0.501 6 和0.641 5。

图4 不同训练模式下节点1 所得模型的准确率与ROC 结果Fig.4 Accuracy and ROC results of the model obtained from node 1 under different training modes

图5 不同训练模式下节点2 所得模型的准确率与ROC 结果Fig.5 Accuracy and ROC results of the model obtained from node 2 under different training modes

图6 不同训练模式下节点3 所得模型的准确率与ROC 结果Fig.6 Accuracy and ROC results of the model obtained from node 3 under different training modes
不同训练模式下各检测节点的模型准确率、F1值、AUC 值分别如表1~表3 所示。不同训练模式下的度量指标均值如图7 所示。由表1~表3 和图7 可以看出:在本地独立训练时,不同检测节点的模型性能优劣不均,例如节点1,虽然其准确率较高,但是F1 值极低,ROC 曲线和AUC 值的表现也不好;
在传统联邦学习模式下,各检测节点的模型性能均有所提高,但较为平均,虽然有效改善了独立训练时的较差模型性能,但对较好模型的性能有较大损害。

图7 不同训练模式下的度量指标均值Fig.7 Mean value of measurement indexes under different training modes

表1 不同训练模式下的模型准确率Table 1 Accuracy of the model under different training modes

表2 不同训练模式下的模型F1 值Table 2 F1 value of the model under different training modes

表3 不同训练模式下的模型AUC 值Table 3 AUC value of the model under different training modes
总体而言,传统联邦学习模式较本地独立训练并没有使各检测模型的识别性能得到整体的优化和提升,而本文所提算法在准确率、F1 值和AUC 值的均值上均有所提升,提升情况如表4 所示。由表4 可以看出,相比于本地独立训练和传统联邦学习,本文所提算法的模型准确率分别提升了31.69% 和7.92%,F1 值分别提升了94.04%和37.97%,AUC 值分别提升了31.99%和23.10%。综上,本文所提算法有效地提高了检测模型的识别准确率,实现了不同节点检测模型的整体优化。

表4 本文所提算法度量指标均值的提升情况Table 4 Improvement of mean value of measurement indexes for the proposed algorithm %
针对SDN 网络的异常流量检测问题,本文构建基于联邦学习的异常流量协同检测架构,并设计多检测节点协同机制和参数聚合权重优化算法,以克服单个检测设备可能面临的训练数据缺乏问题,同时增强多个检测设备间的协同能力,提高检测模型的准确率与适应性。仿真结果表明,参数聚合权重优化算法相比于本地独立训练和联邦学习算法能更有效地提升检测模型的识别准确率。后续将基于联邦学习算法进行网络流量异常检测与隐私安全保护,同时将本文异常流量协同检测技术应用于分布式网络,扩展其适用范围。
猜你喜欢联邦权重协同蜀道难:车与路的协同进化科学大众(2020年23期)2021-01-18一“炮”而红 音联邦SVSound 2000 Pro品鉴会完满举行家庭影院技术(2020年10期)2020-12-14权重常思“浮名轻”当代陕西(2020年17期)2020-10-28303A深圳市音联邦电气有限公司家庭影院技术(2019年7期)2019-08-27“四化”协同才有出路汽车观察(2019年2期)2019-03-15为党督政勤履职 代民行权重担当人大建设(2018年5期)2018-08-16基于公约式权重的截短线性分组码盲识别方法电信科学(2017年6期)2017-07-01三医联动 协同创新中国卫生(2016年5期)2016-11-12协同进化生物进化(2014年2期)2014-04-16层次分析法权重的计算:基于Lingo的数学模型河南科技(2014年15期)2014-02-27推荐访问:协同 联邦 检测技术