基于TBTA网络的高光谱图像分类
来源:优秀文章 发布时间:2023-04-14 点击:
唐 婷,潘 新*,罗小玲*,闫伟红
(1. 内蒙古农业大学计算机与信息工程学院,内蒙古 呼和浩特 010018;
2. 中国农业科学院草原研究所,内蒙古 呼和浩特 010020)
高光谱图像(Hyperspectral Image,HSI)作为一种特殊类型的高光谱分辨率遥感图像,在光谱维度和空间维度[1]上都包含了丰富的信息,并已被广泛应用于许多领域,包括环境检测[2]、精细农业[3]和海洋水文检测[4]等。监督分类是HSI的一项基本任务,是上述应用中常用的技术,然而,过度冗余的光谱波段信息和有限的训练样本,给HSI分类带来了巨大的挑战。
早期的HSI分类是基于光谱特征,包括支持向量机(SVM)[5]、多项logistic回归(MLR)[6]和随机动态子空间[7]。但是基于光谱的方法没有考虑到高光谱图像丰富的空间信息,导致特征提取不够完整。另外,大多数方法都需要花费大量的人力和时间去判别和标注数据。
深度学习(Deep Learning,DL)在自动提取非线性和层次特征方面表现出强大的能力,近年来被广泛应用于高光谱遥感图像分类中,如深度信念网络(Deep Belief Network,DBN)[8]和栈式自编码器(Stacked Autoencoder,SAE)[9]网络。然而,在上述方法中,输入是一维的,虽然利用了空间信息,但却破坏了初始结构。由于卷积神经网络(CNN)可以在保留原有结构的同时利用空间特征,一些引入CNN的新的解决方案被提出。Lee等[10]提出了一种具有更深更广网络的CDCNN,可以通过联合利用相邻单个像素向量的局部时空关系来优化探索局部上下文的相互作用。Chen等[11]提出了融合正则化的3D-CNN特征提取模型,用于提取光谱空间特征进行分类。结果表明,3D-CNN的性能优于1D-CNN和2D-CNN。
DL虽然给HSI分类带来了很好的改进,但是DL对训练样本的需求是巨大的,而人工标注HSI的成本是非常昂贵的。一般来说,更深的网络可以捕获更精细的特征,但却增加了训练的难度。残差网络(ResNet)[12]和密集卷积网络(DenseNet)[13]的出现缓解了深度网络的训练难度。受ResNet的启发,Zhong等[14]提出了一种频谱空间残差网络(SSRN),该网络在训练样本有限的情况下更有效。Wang等[15]提出了一种用于高光谱图像分类的端到端快速密集光谱-空间卷积(FDSSC)算法。
Ma等[16]提出了一种由卷积块注意模块(CBAM)[17]驱动的双分支多注意机制网络(DBMA),并获得了最佳的分类结果。该网络有两个分支分别提取光谱和空间特征,以减少这两种特征之间的干扰,并针对这两个分支的不同特征,在这两个分支中分别应用了两种类型的注意力机制,确保更有区别地利用光谱和空间特征,然后融合提取的特征用于分类。
受DBMA算法和自适应自注意机制双注意网络的启发,本文设计了用于HSI分类的三分支三注意机制网络(Triple-Branch Ternary-Attention,TBTA)。该网络包括光谱、空间X、空间Y三个分支,首先分别捕捉光谱和空间X、Y特征。其次,采用光谱注意机制、空间X注意机制和空间Y注意机制对特征图进行细化。然后,通过连接三个分支的输出,得到融合的光谱空间特征。最后,确定分类结果使用softmax的方法。本文的三个重要贡献如下:
1)基于DenseNet和3D-CNN,本文提出了一种基于三分支三注意力机制的端到端的网络(TBTA)用于HSI分类。该网络的光谱分支、空间X分支和空间Y分别提取光谱、空间X和空间Y特征,可以将三种特征分离开。
2)在光谱、空间X和空间Y上分别引入了其特征方向的注意力机制。针对信息丰富的光谱波段设计了光谱注意块,针对信息丰富的像素点分别设计了空间X和空间Y注意块。
3)在训练数据有限的情况下,该方法在四个数据集中取得了最好的分类精度。
本节将介绍TBTA中使用的基本模块,包括带BN(Batch Normalization,BN)的3D-CNN、ResNet和DenseNet、注意力机制。由于HSI频谱的数量和卷积核通道的数量都可以被称为通道,所以将HSI频谱的数量称为光谱,将卷积核通道的数量称为通道,以避免混淆。
2.1 带BN的3D-CNN
传统的基于单个像素的分类算法仅使用光谱信息进行分类,而基于立方块的算法同时使用光谱和空间信息。基于单个像素的方法仅使用光谱信息来训练网络,而基于3D立方块的方法则以目标像素及其相邻像素作为输入。一般来说,基于单个像素的方法与基于3D立方块的方法的区别是前者的输入大小为1×1×b,后者的输入大小为p×p×b,其中p×p为相邻像素的个数,b为光谱带的个数。之所以使用基于立方块的方法,是因为空间中相邻块的信息对于分类也有借鉴作用。
就像激活函数层、卷积层、全连接层、池化层一样,BN也属于网络的一层,主要用于卷积层后的数据正则化处理。带BN的3D-CNN[18]是基于3D立方块的深度学习模型中的常见元素。1D-CNN和2D-CNN只使用了光谱特征或只捕捉了像素的局部空间特征,3D-CNN同时使用了光谱和空间信息对HSI进行分类。因此,TBTA采用3D-CNN作为基本结构,此外,在每个3D-CNN层中增加了BN层,以提高数值稳定性。
对于pm×pm×bm大小的nm特征图,一个3D-CNN层中,包含大小为αm+1×αm+1×dm+1的km+1个通道,生成尺寸为pm+1×pm+1×bm+1的nm+1输出特征图。第(m+1)个带BN的3D-CNN层的第i个输出计算为
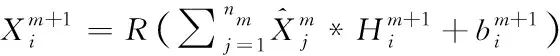
(1)

(2)

2.2 ResNet和DenseNet
通常,卷积层越多,网络的性能就越好。然而,太多的图层可能会使渐变消失和爆炸的问题更加严重。ResNet[12]和DenseNet[13]是解决这一难题的有效方法。
在ResNet中,一个跳跃连接被添加到传统的CNN模型中。跳跃连接可以看作是将前面层的信息和后面层的信息直接连接起来,这样可以避免信息经过网络流动后丢失。残差块是ResNet的基本单位,第l残差块的输出可以计算为
xl=Hl(xl-1)+xl-1
(3)
DenseNet基于ResNet,直接连接各层,确保网络各层之间的信息流动最大。DenseNet不像ResNet那样通过累加来组合特性,而是通过在通道维度上连接它们来组合特性。密集块是DenseNet中的基本单位,第l个密集块的输出计算为
xl=Hl[x0,x1,…,xl-1]
(4)
其中Hl是一个包含卷积层、激活层和BN层的块,x0,x1,…,xl-1表示生成的密集块,连接越多,密集网中的信息流就越多。具体来说,层数为L的密集网络有L(L+1)/2个连接,而层数相等的传统卷积网络只有L个直接连接。
2.3 注意力机制
3D-CNN的一个缺点是所有的空间像素和光谱波段在空间域和光谱域中拥有等价的权值。显然,不同的光谱波段和空间像元对提取特征的贡献是不同的。注意力机制是解决这一问题的有力手段。注意力机制受人类视觉感知过程的驱动,更多地关注信息区域,而较少考虑非必要区域。注意力机制已经被用于图像分类[19],在图像标题、文本图像合成、场景分割等领域也得到了很好的应用。在一些研究中采用光谱注意块和空间注意块来增强光谱和空间的权重,以下将详细介绍这两部分内容。
2.3.1 光谱注意块
如图1光谱注意块所示,光谱注意力映射X∈Rc×c是直接从初始输入A∈Rc×p×p计算出来的,其中p×p是输入的块的大小,c表示输入通道的数量。首先,将A与AT进行矩阵乘法运算,得到通道注意映射X∈Rc×c,将softmax层连接为
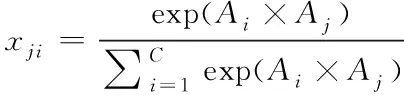
(5)
其中xji表示第i个通道对第j个通道的影响。其次,将XT与A的矩阵乘法结果变形成Rc×p×p。最后,通过尺度α的参数对重构后的结果进行加权,并加上输入A,得到最终的光谱注意图E∈Rc×p×p

(6)
式中α初始化为零,可以逐步学习。最终的图E包含了所有通道特征的加权总和,可以描述一个依赖关系,增强特征的可辨别性。
2.3.2 空间注意块

图1 光谱注意块和空间注意块的细节
如图1空间注意块所示,给定一个输入特征图A∈Rc×p×p,采用两个卷积层分别生成新的特征图B和C,其中{B,C}∈Rc×p×p。首先,将B和C变形成Rc×n,其中n=p×p为像素数目。其次,在B与C之间进行矩阵相乘,随后附加一个softmax层,计算空间注意特征图S∈Rn×n:

(7)
其中sji表示第i个像素到第j个像素的影响。两个像素的特征表示越接近,代表它们之间的相关性越强。
将初始输入特征A同时送入卷积层,得到一个新的特征映射D∈Rc×p×p被变形为Rc×n。最后在D和ST之间进行矩阵的乘法运算,结果被变形为Rc×p×p:
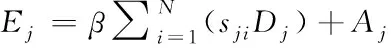
(8)
式中β初始值为零,可以逐步学习并分配更多的权重。由式(8)可知,将所有的位置和原始特征加上一定的权重,得到最终的特征E∈Rc×p×p。因此,将空间维度上的上下文信息被模型化为E。
TBTA(Triple-Branch Ternary-Attention,TBTA)算法的过程包含三个步骤:数据集生成、训练和验证以及预测。图2说明了本文方法的整个算法流程。
假设HSI数据集X由N个标记像素{x1,x2,…,xn}∈R1×1×b组成,其中b为波段,对应的类别标签集为Y={y1,y1,…,y1}∈R1×1×c,其中c为土地覆盖类别数。
在数据集生成步骤中,从原始数据中选取中心像素xi的p×p邻近像素,生成三维立方块的集合{z1,z2,…,zn}∈Rp×p×b。如果目标像素位于图像的边缘,则将缺失的相邻像素值设置为零。在TBTA算法中,p为补丁大小,设置为9。然后,将三维立方块集随机分为训练集Ztrain、验证集Zval和测试集Ztest。相应的b标签向量分为Ytrain、Yval、Ytest。由于相邻像素的标签对网络是不可见的,所以只使用目标像素周围的空间信息。

图2 三分支三注意(TBTA)的算法流程
在训练和验证步骤中,训练集用于更新多次迭代的参数,而验证集用于监控模型的性能并选择训练最好的模型。
在预测步骤中,选择测试集来验证训练模型的有效性。在HSI分类中,常用的衡量预测结果与真实值之间差异的定量指标是交叉熵损失函数,定义为

(9)

3.1 TBTA网络结构
TBTA网络的整体结构如图3所示。为了方便起见,将上面的分支叫做光谱分支,下面的分支分别叫做空间X分支和空间Y分支。分别输入光谱支路、空间X支路和空间Y支路,得到光谱特征图和空间特征图。然后采用光谱、空间X特征图和空间Y特征图的融合运算得到分类结果。以下部分以Indian Pines (IP)数据集为例,介绍了光谱分支、空间分支以及光谱与空间的融合操作。样本立方块大小为9 × 9 × 200,如下提到的矩阵(9×9×97,24),9×9×97表示3d立方块的高度、宽度和深度,24表示由3D-CNN生成的3D立方块的数量。IP数据集包含145 × 145像素,200个光谱波段,即IP的大小为145 × 145 × 200。只有10249个像素有相应的标签,其它像素是背景。
TBTA网络的结构,设计了由密集光谱块和光谱注意块组成的光谱分支来捕捉光谱特征,利用空间特征,设计由密集空间块和空间注意块构成空间X分支和空间Y分支
3.1.1 三分支前的降维层
由于HSI的光谱通道特别多,其对于分类来说是冗余的,通常HSI分类算法都会先进行降维操作,减小冗余,从而提高分类正确率。TBTA则使用了一个卷积核大小为1 × 1 × 7的3D-CNN层,步幅设为(1,1,2),以减少通道数量,捕获(9×9×97,24)的特征图作为三分支的输入特征图。
3.1.2 带有光谱注意块的光谱分支
在降维层的特征图后添加带BN的3D-CNN Dense光谱块,每个Dense光谱块的3D-CNN有12个通道,卷积核大小为1×1×7。经过Dense光谱块后,由式(5)计算得到特征图的通道增加到60条,此时特征图的大小为(9×9×97,60)。接下来,在最后一个卷积核大小为1 ×1 × 97的3D-CNN之后,生成一个(9×9×1,60)的特征图。然而,这60个通道对分类做出了不同的贡献。为了细化光谱特征,采用了2.3.1节介绍的光谱注意块,其强化了有用信息的权重,削弱了冗余信息的权重。在得到加权的光谱特征图后,采用BN层和dropout层来提高稳定性和鲁棒性。最后,通过全局平均池化层,得到1×60的特征图。
3.1.3 带有空间注意块的空间分支
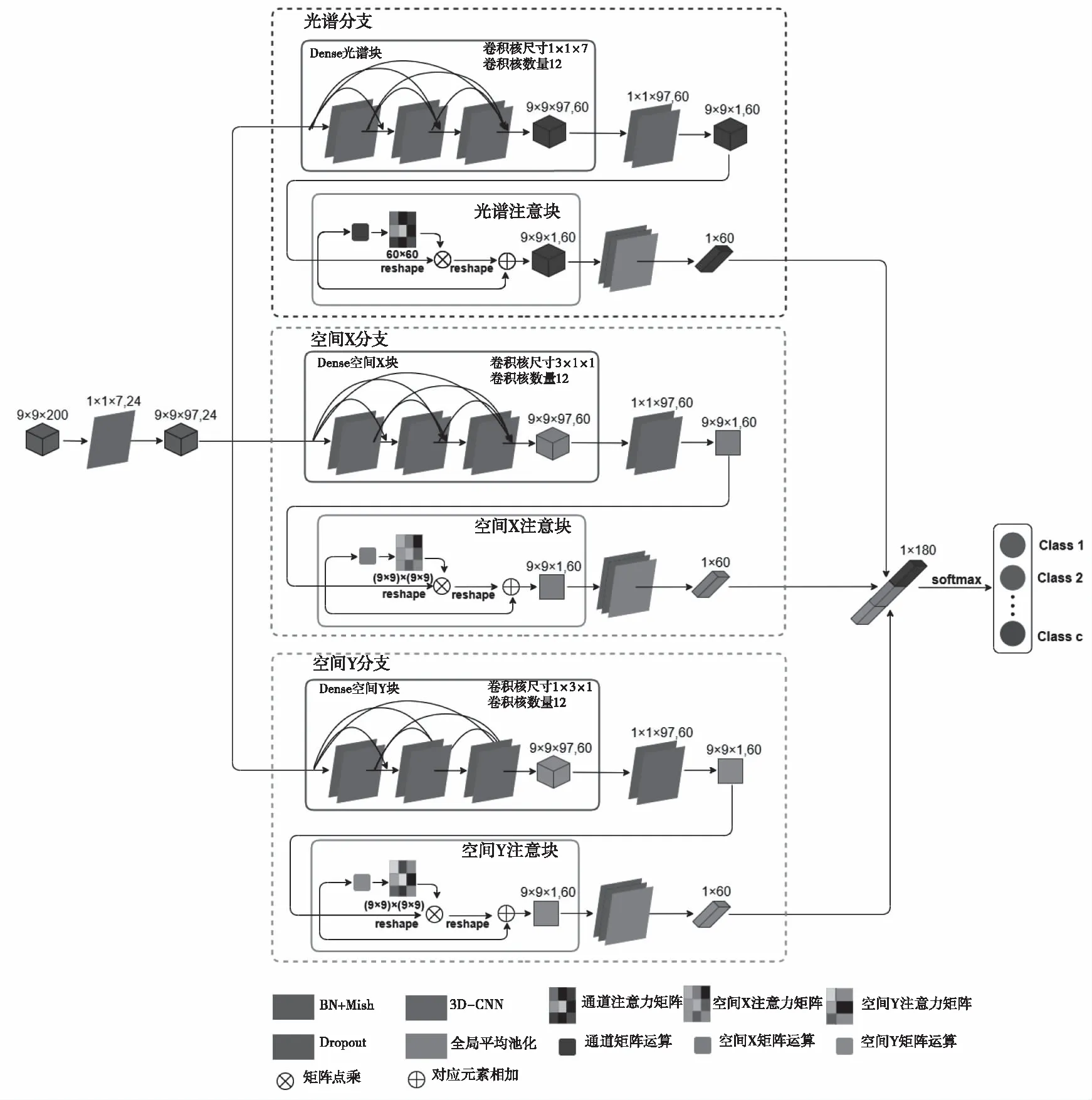
图3 TBTA网络整体结构图
同时,将(9×9×97,24)的特征图输入到空间X分支,然后添加带BN的3D-CNN Dense空间X块。每个3D-CNN在Dense空间X块中有12个通道,卷积核大小为3 ×1 × 1。接下来,将(9 × 9 × 1,60)的特征图输入到空间X注意块中,利用注意块,对每个像素的系数进行加权,得到更具判别性的空间X特征图。在获取加权的空间X特征图后,通过BN层、Dropout层和全局平均池化层得到1×60的空间X特征图。
同样的,将(9×9×97,24)的特征图输入到空间Y分支,然后添加带BN的3D-CNN Dense空间Y块。每个3D-CNN在Dense空间Y块中有12个通道,卷积核大小为1 ×3× 1。将(9 × 9 × 1,60)的特征图输入到空间Y注意块中,利用注意块,对每个像素的系数进行加权,得到更具判别性的空间Y特征图。在获取加权的空间特征图后,通过BN层、Dropout层和全局平均池化层得到1×60的空间Y特征图。
3.1.4 光谱与空间融合用于HSI分类
结合光谱分支、空间X分支和空间Y分支,得到了光谱特征图、空间X特征图和空间Y特征图,然后,连接三个特征图进行分类。另外,采用串联运算而不是相加运算的原因是,光谱特征、空间X特征和空间Y特征都在不相关的域中,串联运算可以使光谱特征、空间X特征和空间Y特征保持独立,而相加运算则会使光谱特征、空间X特征和空间Y特征混合在一起。最后,通过全连接层和softmax层得到分类结果。
对于其它数据集,网络实现原理是相同的,唯一的区别是光谱带的数量不同。
3.2 防止过拟合的措施
过多的训练参数和有限的训练样本导致网络容易出现过拟合,因此,本文采取了一些措施来防止过拟合。
3.2.1 Mish激活函数介绍
激活函数给神经网络带来了非线性的概念,适当的激活函数可以加快网络的反向传播和收敛速度。TBTA采用的激活函数是Mish,这是一个自正则化的非单调激活函数,而不是传统的ReLU(x)=max(0,x)。Mish的公式是:
mish(x)=x×tanh(softplus(x))
=xi×tanh(ln(1+ex))
(10)
其中x表示输入。Mish为上界无界,下界范围为[≈-0.31,∞]。Mish的微分系数定义为
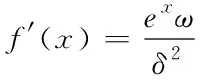
(11)
其中ω=4(x+1)+4ex+e3x+ex(4x+6),δ=2ex+e2x+2
ReLU是一个截断所有负输入的分段线性函数。因此,如果输入是非正的,那么神经元就会“死亡”,不能再被激活,即使负的输入可能包含有用的信息。负输入被Mish保留为负输出,可以更好的保证信息传播及网络稀疏性。
3.2.2 Dropout层、最优权重的选择和动态调整学习速率
在光谱分支、空间X分支和空间Y分支的最后,BN层和全局平均池化层之间分别使用了Dropout层[20]。Dropout是一种简单但有效的方法,可以防止过拟合,经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。因此,在TBTA中p被选为0.5。
关于最优权重的选择,在训练过程中,验证集上的准确率高的优先,如果验证集的准确率一致,则选择在训练集上损失最小的。
学习速率是训练网络的一个重要超参数,动态学习速率可以帮助网络避免局部极小值。采用余弦退火方法动态调整学习速率,如下式

(12)
为了验证所提模型的准确性和有效性,在4个数据集上进行了实验,并与其它4种方法进行了对比。采用综合精度(OA)、平均精度(AA)和Kappa系数(K)三个定量指标来衡量每种方法的精度。具体来说,OA表示单个类别的平均准确率。AA表示所有类别的平均准确率。Kappa系数反映了真实标签与分类结果的一致性。三个度量值越高,分类结果越好。
对于每个数据集,从标记数据中按一定百分比随机选取一定数量的训练样本和验证样本,其余数据作为测试样本。由于TBTA主要解决小样本高光谱图像分类问题,因此将训练样本和验证样本的数量设置在较低水平。
4.1 关于数据集的介绍
本文采用4个广泛使用的HSI数据集,即Indian Pines (IP)数据集、Pavia University (UP)数据集、Salinas Valley (SV)数据集和博茨瓦纳数据集(BS)进行实验。
深度学习算法是数据驱动的,依赖于大量带标签的训练样本,输入训练的标记数据越多,准确率就越高。然而,更多的数据意味着更多的时间消耗和更高的计算复杂度。本文提出的TBTA能够在训练样本非常缺乏的情况下保持良好的性能。因此,在实验中,训练样本和验证样本的大小被设定在较小的水平。对于IP和BS,选择3%的样本进行训练,3%的样本进行验证。由于UP和SV的每一类都有足够的样本,所以只选取0.5%的样本进行训练,0.5%的样本进行验证。
4.2 实验设置
为了验证TBTA的有效性,将基于深度学习的分类器CDCNN、SSRN[14]、FDSSC[15]和最先进的双分支多注意机制网络(DBMA)[16]与本文提出的算法进行了比较,此外,还对比了RBF核支持向量机[9]。每个分类器的滑动窗口大小按照其原始论文设置。实验都在相同的平台上执行,配置16GB内存和NVIDIA GeForce RTX 1080Ti GPU。所有基于深度学习的分类器使用PyTorch实现,支持向量机使用sklearn实现。
CDCNN、SSRN、FDSSC、DBMA,以及本文提出的方法TBTA,批处理大小均设为16,优化器设为Adam,学习率为0.0005。关于最优权重的选择,迭代次数均设为150,并使用3.2.2节中最优权重选择的方法进行实验和测试。
4.3 分类图及分类结果
4.3.1 IP数据集的分类图和分类结果
表1展示了IP数据集使用不同方法的分类结果,其中各类最佳精度用粗体表示,不同方法的分类图和真实标签如图4所示。
本文提出的算法得到了最佳的结果,OA为95.40%,AA为94.30%,Kappa为0.9475。

表1 使用3%训练样本的IP数据集的分类结果
基于RBF的SVM方法准确率最低,OA仅达到了68.76%。FDSSC采用密集连接代替剩余连接,提高了网络的性能,在OA方面比SSRN提高了0.58%。DBMA由于样本极度缺乏,DBMA可能对训练数据产生了过拟合,即使使用了注意力机制,其OA依然不理想。然而,当训练样本非常缺乏时,本文提出的TBTA网络,通过灵活、自适应的注意力机制、适当的激活功能以及其它防止过拟合的措施,在有限数据的情况下能够实现稳定可靠的性能。
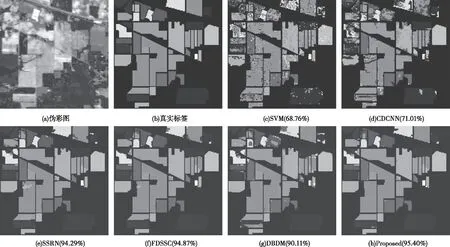
图4 使用3%训练样本的IP数据集的各个方法分类图
4.3.2 UP数据集的分类图和分类结果
对于UP数据集,使用不同方法的分类结果如表2所示,其中各类最佳精度用粗体表示,不同方法的分类图和真实标签如图5所示。
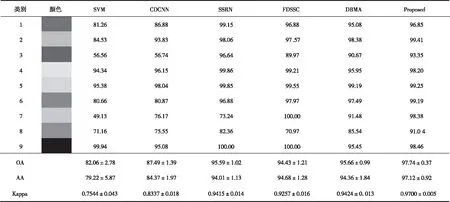
表2 使用0.5%训练样本的UP数据集的分类结果
从表2可以看出,本文提出的方法在三个指标上均取得了最好的结果。虽然不能使每个类的精度都达到最好,但对每个类的精度都超过了91%,这意味着本文的方法能够捕捉到不同类之间的特征。由于UP数据集中的样本是足够的,所以仅选择了0.5%的数据作为训练集。

图5 使用0.5%训练样本的UP数据集的各个方法分类图
4.3.3 SV数据集的分类图和分类结果
对于SV数据集,使用不同方法的分类结果如表3所示,其中各类最佳精度用粗体表示,不同方法的分类图和真实标签如图6所示。

表3 使用0.5%训练样本的SV数据集的分类结果
从表3中可以看出,本文提出的方法在三个指标上均取得了最好的结果,OA为95.19%,AA为96.66%,Kappa为0.9465。其中OA比DBMA高出1.6%。

图6 使用0.5%训练样本的SV数据集的各个方法分类图
4.3.4 BS数据集的分类图和分类结果
不同方法对BS数据集的分类结果如表4所示,其中各类最佳精度用粗体表示,不同方法的分类图和真实标签如图7所示。
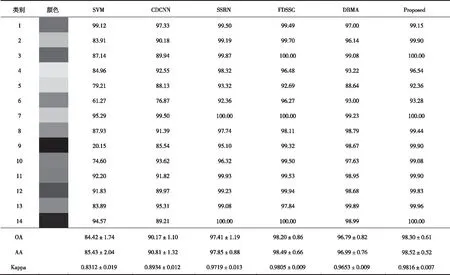
表4 使用3%训练样本的SV数据集的分类结果
由于BS数据集很小,只有3248个标记样本,当训练样本为3%时能更好地区分算法性能,所以本文选择3%的样本作为训练集,3%的样本作为验证集。尽管如此,本文提出的方法获得了98.30%的OA性能,比DBMA高出1.51%,原因之一是本文的方法可以更有效地捕捉空间和光谱特征。

图7 使用0.5%训练样本的SV数据集的各个方法分类图
在这一部分,将对TBTA进行进一步的评估。首先,将不同比例的训练样本输入网络,结果表明,该方法在训练样本非常有限的情况下仍能保持有效性。其次,消融实验结果证实了注意力机制的必要性。最后,不同激活函数的结果表明,在TBTA中,Mish优于ReLU。
5.1 不同训练样本对实验的影响
由于深度学习是一种数据驱动的算法,依赖于大量高质量的标记数据集。在这一部分,将对不同比例的训练样本进行研究,对于IP和BS数据集,分别使用0.5%、1%、3%、5%和10%的样本作为训练集。对于UP和SV数据集,分别使用0.1%、0.5%、1%、5%和10%的样本作为训练集。实验结果如图8-11所示。
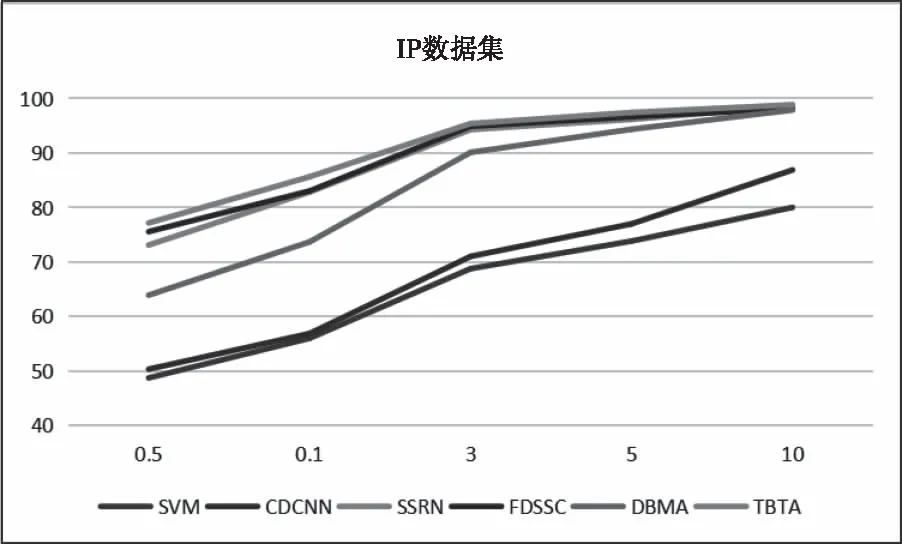
图8 各种方法不同训练样本比例在IP数据集上的实验结果
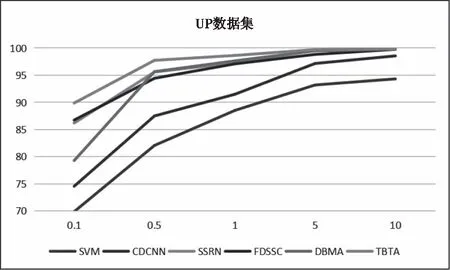
图9 各种方法不同训练样本比例在UP数据集上的实验结果

图10 各种方法不同训练样本比例在SV数据集上的实验结果
随着训练样本数量的增加,准确率也会提高。所有基于3D-CNN的方法,包括SSRN、FDSSC、DBMA以及所提出的算法,只要提供足够的样本(约占整个数据集的10%),就可以获得近乎完美的性能。同时,随着训练样本的增加,不同模型之间的性能差距逐渐缩小。尽管如此,本文提出的方法还是优于其它方法,尤其是在样本不足的情况下。由于标记数据集的成本较高,因此该方法可以节省人工和成本。

图11 各种方法不同训练样本比例在BS数据集上的实验结果
5.2 注意力机制的有效性
为了验证注意力机制的有效性,将分别去除TBTA的光谱-注意力模块、空间-注意模块力和两个注意力模块,并比较这三个“不完全TBTA”和“完全TBTA”的表现。
从图12可以看出,光谱注意力机制和空间注意力机制的存在确实提高了4个数据集的分类准确性。
在四个数据集上,注意力机制平均提高了4.20%的OA。在大多数情况下,单一空间注意力机制(平均提高2.35%)优于单一谱注意力机制(平均提高1.08%)。

图12 注意力机制的有效性
5.2 激活函数的有效性
在第3.2.1节中,说明了为什么采用Mish激活函数,而不是通常使用的ReLU。在这里,将对基于Mish的TBTA和基于ReLU的TBTA的性能进行比较。图13显示了它们的分类OA。
如图13所示,基于Mish的TBTA优于基于ReLU的TBTA。其中,IP、UP、SV和BS数据集的OA分别提高了2.22%、2.16%、4.14%和1.34%。因为Mish可以加速反向传播,所以就产生了性能上的差异。
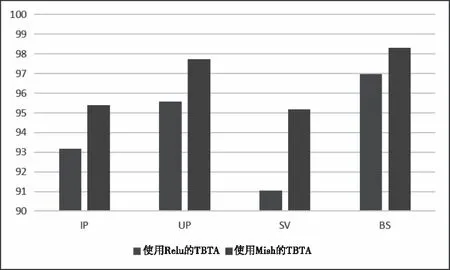
图13 激活函数的有效性
本文提出了一种基于三分支三注意力机制的端到端的网络TBTA用于HSI分类。TBTA网络的输入是原始的3D像素数据,没有任何繁琐的预处理来降维。基于BN密集连接的3D-CNN层,设计了三个分别捕捉光谱特征、空间X特征和空间Y特征的分支。同时,在其特征方向上分别引入了注意力机制。引入Mish作为加速反向传播和收敛过程的激活函数。为了防止过拟合,还采用了动态学习率、最优权重的选择和Dropout层。
大量的实验结果表明,本文提出的TBTA算法优于目前分类效果比较好的DBMA算法,特别是在训练样本有限的情况下。同时,与FDSSC和DBMA相比,注意块和激活函数Mish加速了模型的收敛速度,减少了时间消耗。因此,通过实验结果可以得出,即使在训练集匮乏的情况下,本文提出的方法依然能保持良好的HSI分类性能。
猜你喜欢训练样本分支光谱基于三维Saab变换的高光谱图像压缩方法北京航空航天大学学报(2022年8期)2022-08-31人工智能科技创新与应用(2020年6期)2020-02-29巧分支与枝学生天地(2019年28期)2019-08-25一类拟齐次多项式中心的极限环分支数学物理学报(2018年1期)2018-03-26宽带光谱成像系统最优训练样本选择方法研究北京理工大学学报(2016年6期)2016-11-22融合原始样本和虚拟样本的人脸识别算法电视技术(2016年9期)2016-10-17基于稀疏重构的机载雷达训练样本挑选方法系统工程与电子技术(2016年7期)2016-08-21星载近红外高光谱CO2遥感进展中国光学(2015年5期)2015-12-09苦味酸与牛血清蛋白相互作用的光谱研究食品工业科技(2014年23期)2014-03-11铽(Ⅲ)与PvdA作用的光谱研究无机化学学报(2014年1期)2014-02-28推荐访问:光谱 图像 分类推荐文章
- [高考励志:倒计时冲刺语录] 高考倒计时励志语录
- 2018江苏高考成绩查询入口,点击进入:江苏高考2018成绩查询
- [英语阅读:细数英语中那些出口的汉语]带汉语的英语阅读视频
- 双语阅读:英文吐槽“变凉”的天气_喜剧中心吐槽大会2018
- 2018年福建高考成绩查询网址:http://www.eeafj.cn/:2018福建二建成绩查询
- 小学五年级下册语文阅读理解练习题五道_5年级下册语文书人教版
- 河北教育考试院2018高考查分_福建教育考试院网2018年高考查分系统
- 2018年山西省拟录用公务员公示 [2018年浙江瑞安市各级机关公务员拟录用人员公示(五)]
- 好舌头绕口令 [英语绕口令:挑战你的舌头]
- [2018福建高考成绩什么时候可以查询] 2018中级会计成绩查询