基于聚类思想的转炉终点碳含量预测方法
来源:优秀文章 发布时间:2023-04-10 点击:
贺东风 黄涵锐
(北京科技大学 冶金与生态工程学院)
转炉终点碳含量作为转炉炼钢的控制目标之一,其预测精准度一直是实现转炉智能控制的关键。学者们研发了众多高精度的转炉终点预测模型[1-3],但由于转炉冶炼的复杂性,高精度模型在应用过程中往往达不到预期效果,对实际冶炼的帮助有限。所用模型存在适应性问题,而现有转炉冶炼多依靠人工经验判断,即根据铁水温度、成分含量和物料种类等炉况不同,采取相应的冶炼策略。若将各类炉况混为一谈进行建模、预测,会导致模型精度降低。
过去的研究为提高模型精度,往往选择筛选出典型的炉况进行预测,即针对部分关键属性进行择优,并在此基础上建模预测,因此在实际应用时,当关键属性不符合范围要求的案例出现时,模型的精度将大幅降低[4-6]。
文章提出利用聚类算法将相似炉况的冶炼数据归纳分类,更好地挖掘各种炉况下转炉冶炼的规律。具体方案:将炼钢过程加入的各类不同炉料数据纳入模型考虑,并采用适合炼钢高维复杂数据的SNN共享最近邻算法,用于表征数据间的相似情况。将其与近邻传播聚类算法结合后,对现有数据进行聚类,并针对不同炉况类别下数据分别建立基于BP神经网络的转炉终点碳含量预测模型。
1.1 SNN_AP聚类思路
为了更准确地利用训练样本内包含的不同内在规律,需用聚类算法将数据分类。由于转炉冶炼数据具有维数高、密度大和种类少的特性,文章提出基于SNN相似度的AP聚类算法。
近邻传播算法(Affinity Propagation)是基于数据间相似度的聚类算法中的一种,于2007年由Frey等人提出[7]。AP算法的基本思想是通过根据n个数据点之间的相似度计算得到一些信息,在信息传递的基础上进行聚类[8]。由于AP聚类算法具有运行结果稳定、无需主动选定类别数量和不依赖数据的优点[9],文章选用其作为划分数据集的核心算法。以数据量为n的m维数据集Dn×m为例,此算法以集内两数据i、k间相似度s(i,k)为基础,提出了两个信息量参数:用于描述点k适合作为数据点i的聚类中心的程度的吸引度r,由此组成的吸引度矩阵R;
用于描述点i选择点k作为其聚类中心的适合程度的归属度a,由此组成的归属度矩阵A。
R=[r(i,k)]n×n
(1)
A=[a(i,k)]n×n
(2)
两种信息量代表了不同的竞争目的。r(i,k)表达的是点k作为中心点对点i的吸引程度。a(i,k)则代表当k作为中心点时,点i归属于点k的合适程度。
R、A两个信息矩阵均由数据集内数据的相似度矩阵计算得出,相似度矩阵是AP算法的基石,能否得到合适的相似度矩阵将决定聚类效果的优劣[10]。经典AP聚类算法基于欧式绝对距离对数据间相似度进行描述。对于转炉冶炼的生产数据而言,由于其高密度、高维数的特点,采用欧式绝对距离无法满足对其相似性描述的要求。充分考虑数据情况及影响后,引入一种以数据点之间共享最近邻为指标的相似性度量方式。
SNN(Shared Nearest Neighbour)相似度全称为共享最近邻相似度[11],是基于最近邻思想的一种相似度,其认为若两数据点有共同的最近邻数据,则两数据点相似,共同的最近邻数据量即为两者间相似度。SNN相似度提出之初就是为了解决高维数据相似描述的问题,目前也已有文献实践证明这种方法对工业生产中的高维数据有效[12]。其定义公式:
SNN(zi,zj)=|V(zi)∩V(zj)|
(3)
式中:V(z)为与量测点z距离最接近的K个数据点的集合,称为z点的最近邻数据集。此处K值代表算法计算过程中选取的量测点z最近邻点的个数,其数值大小对SNN相似度效果影响较大,需经过实验人为选择最适合目标数据集的数值;
||表示数据集内元素个数。若点间没有共同的近邻点,则SNN(zi,zj)=0。
传统近邻传播聚类算法以负的欧式绝对距离度量两数据相似度,基本规则是数据越负,两点越不相似,自相似度为最大值0。若要以SNN相似度度量代替欧氏绝对距离度量,需对SNN相似度结果进行调整。文章最终所用相似度计算公式为:
(4)
式中:当i≠k时,所用方法是在计算数据点两两之间的SNN相似度后,将其减去最近邻点个数K。当i=k时,相似度s(i,i)代表点本身能够作为聚类中心的参考度,值越大优先度越高。由于距离相似度量的特性,这个值默认为零,是整个相似度矩阵S中的最大值,不利于算法正确聚类,因此需在开始前额外设置参考度值P,用以输入模型。
SNN_AP算法的具体计算过程为:
(1)计算数据集的相似度矩阵S=[s(i,k)]n×n,同时将R、A两个矩阵进行初始化。
(2)以相似度矩阵S=[s(i,k)]n×n为基础,在迭代计算过程中,对吸引度矩阵R=[r(i,k)]n×n、归属度矩阵A=[a(i,k)]n×n两个信息量矩阵进行交替更新。更新公式分两步,分别为:
吸引度更新公式:
rt+1(i,k)=(1-λ)·rt+1(i,k)+λ·rt(i,k)
(5)
归属度更新公式:
at+1(i,k)=(1-λ)·at+1(i,k)+λ·at(i,k)
(6)
式中:t代表迭代次数,rt(i,k)即表示第t次迭代时点k对点i的吸引度。在进行迭代更新计算后,为防止迭代过程中计算结果发生剧烈振荡,算法引入阻尼系数λ,在每次迭代计算后对结果进行优化。λ值可根据计算情况在0.5至1之间进行修改。
每次迭代计算完成后,算法以一定规则为准选择出聚类中心。以r(i,i)+a(i,i)>0作为条件,即当点i对自身的责任度和自身的可信度之和大于0时,选择对应点作为聚类中心。
(3)重复进行步骤(2)。当多次迭代计算得到的聚类中心集均未变化,或迭代次数达到预设最大值时,结束迭代,并得到最终的聚类中心点集。
(4)以max{a(i,j)+r(i,j)}作为规则,将中心点外的其余点分配至合适的聚类中心下,从而得到最终的隶属关系与聚类结果。
1.2 聚类模型建立
文章选用数据来自某钢厂某类钢种10个月的实际生产数据,筛除异常记录后可用数据共计2 776炉次。
基于冶金原理[13],在计算各数据项与终点碳含量间的灰色关联度后,选用其中与终点碳含量关联较高的12个数据项作为模型的考虑因素,具体见表1。

表1 聚类模型所用数据
为求证这些数据项对终点碳含量结果的影响,将上述数据整理,用于输入聚类模型,并最终得到聚类中心与聚类结果。
1.3 基于SNN_AP聚类思路的终点碳含量预测模型
在得到分类的数据后,针对每类数据分别建立预测模型,以验证该聚类方法对提升预测模型精度的效果。文章选用BP神经网络模型作为预测方式,具体模型结构将根据每类数据情况进行调整。模型整体结构见图1。
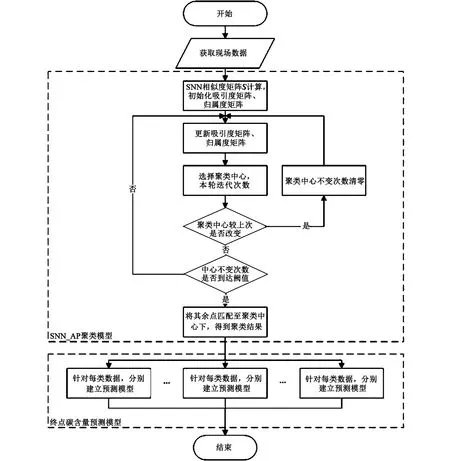
图1 基于SNN_AP聚类思路的终点碳含量预测模型结构
按照1.2、1.3章节的描述,将数据输入聚类模型中,最近邻个数K选择300,阻尼系数取0.95,参考度P取-45。最终数据被分为9类。其中心点部分数据项见表2。
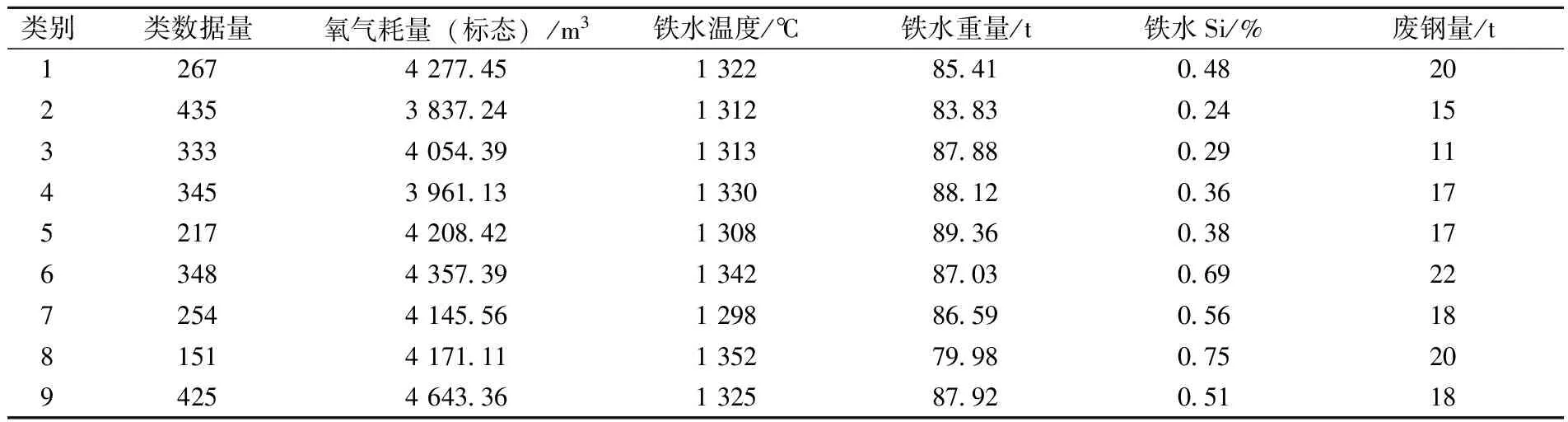
表2 SNN_AP聚类中心部分数据项
聚类后每类情况均有一定数据量作为保证,认为满足进行预测建模的数据量要求。观察聚类结果后发现,分类后各类别中部分关键数据项分布情况出现了较明显的差异,其中氧气耗量、铁水温度、铁水重量、铁水Si含量、废钢量五项数据的类间差异性最为显著。针对这些数据项进行描述,每类数据与未分类时全局数据的均值、标准差见表3。作为对比,将分布情况差异并不明显的铁水Mn含量数据也罗列其中。

表3 SNN_AP聚类结果各类数据关键数据
首先,每类数据各数据项的均值较未分类时均发生变化,这种变化能一定程度说明数据的某种工况特征。以类别2为例,氧气耗量、铁水温度、铁水重量、铁水Si含量、废钢量平均值分别为3 824.87 m3、1 312 ℃、84.84 t、0.38%、13 t,皆低于全局均值。说明在铁水较少且温度较低的工况下,实际冶炼中倾向选择加入较少废钢,所耗氧气也会降低。而在类别9中,铁水重量为88.09 t高于全局均值,平均铁水温度1 324 ℃亦高于全局均值,这种情况下铁水热量条件较好,可以接受更多的废钢,因此平均废钢量19 t高于全局均值,相对应的,此类别平均氧气耗量4 631.50 m3也较全局均值有明显增加。
其次,在几项关键数据的标准差值方面,大多数类别均较全局数据标准差有所降低。标准差是反映数据集的离散程度的指标之一,各类别内部数据项的标准差下降,表明类别内部这一数据更为集中。以氧气耗量数据为例,每个类别的氧气耗量标准差都有不同程度的降低,类别1的标准差达到82.24 m3,较全局标准差有明显减少。这说明每个类别中的氧气耗量数据均相较全局数据更加集中,验证了同一类别数据内部本身的相似性。
值得注意的是,部分类别中有部分数据项的标准差没有变化甚至增大,例如各类别中铁水Mn含量标准差均较全局标准差0.10%相近,类别4的铁水Mn标准差则略增至0.11%。这说明在实际生产调整冶炼方案时,并未将这项数据纳入考虑,或针对该数据进行的冶炼方案调整并未对钢水中碳含量造成明显影响。例如铁水Mn含量,转炉吹炼生产过程中一般不做处理;
铁水Si含量则主要影响转炉造渣制度,对吹炼制度和碳含量影响较小。
综上,经过聚类算法后,类与类之间数据在几项关键数据项中已经产生了差异,且类别内部数据也有一定的统一性,可见算法在区分不同类别数据上有一定效果。这种类间差异性与类内统一性在实际冶炼中表现为炉况的不同,实际应用时可根据铁水重量、铁水温度等参数的不同情况作为冶炼数据类别判断的标准。
针对聚类得到9个类别数据,分别建立BP神经网络进行预测。选用的网络结构与最终预测结果见表4。表中的激活函数、隐藏层节点数、学习率为建立神经网络所需的网络结构参数。以终点碳含量预测结果在一定绝对误差值范围内的命中率作为衡量模型性能的指标,分别是±0.01%、±0.02%、±0.03%。

表4 各类别下最佳BP模型结构
可以看到,未分类时的全局预测模型命中率在±0.02%内命中率达到56.55%,±0.03%内命中率达到75.54%,而经过SNN_AP聚类后,依据每类数据分别建立的几个模型的命中率均有不同幅度的提升,最终模型总命中率在±0.02%内命中率达到64.52%,±0.03%内命中率达到82.27%,模型命中率有较为明显提升。
(1)文章针对生产数据维数高、密度大的特点,使用改进的SNN_AP聚类算法,对数据集进行了聚类划分,并分析了聚类后类内数据情况,最终得到的聚类结果中,同类别数据具有一致性,不同类别间数据差异明显,认为聚类模型对区分工况是有效的。
(2)在对各类别数据分别建模预测后发现,聚类后各工况下模型精度均有提升,说明将不同工况数据区分后分别建模预测以提升模型精度的方式是有效的,可以作为提升转炉预测模型精度的一种重要思路。
猜你喜欢 数据项铁水类别 山钢5100m3高炉提高铁水装准率的实践山东冶金(2022年1期)2022-04-19基于相似度的蚁群聚类算法∗计算机与数字工程(2021年6期)2021-06-29低铁比条件下低硅、低温铁水加煤块冶炼生产实践山东冶金(2019年5期)2019-11-16非完整数据库Skyline-join查询*计算机与生活(2019年11期)2019-11-12基于Python的Asterix Cat 021数据格式解析分析与实现科技与创新(2019年14期)2019-08-12壮字喃字同形字的三种类别及简要分析民族古籍研究(2018年1期)2018-05-21基于Bootstrap的高炉铁水硅含量二维预报自动化学报(2016年5期)2016-04-16卢成:发展集装箱铁水联运大有可为专用汽车(2016年8期)2016-03-01服务类别新校长(2016年8期)2016-01-10多类别复合资源的空间匹配浙江大学学报(工学版)(2015年1期)2015-03-01推荐访问:转炉 终点 含量