融合图卷积和胶囊网络的内容感知排序推荐
来源:优秀文章 发布时间:2023-03-23 点击:
周文荣,张 ,肖 述
(1.湖北大学 校园建设与信息化办公室,湖北 武汉 430062;
2.湖北大学 计算机与信息工程学院,湖北 武汉 430062)
近年来,随着深度学习研究在推荐系统领域不断深入,大多数研究人员从经典的内容感知推荐方法[1,2]开始转向利用深度神经网络学习文本内容信息相关特征,将这些特征用于推荐系统的建模,获得不错的推荐性能[3,4]。
现有内容感知推荐方法取得了很好的推荐性能,但是仍然存在一些问题亟待解决:
问题1:大多数内容感知推荐方法采用评分预测模型实现项目推荐。但是,实际推荐场景中,项目在推荐列表的排序更加吸引用户[5]。然而如何将异构的文本内容信息融合到统一的排序推荐模型中,是一项具有挑战的工作。
问题2:大多数内容感知推荐模型在学习文本特征信息中缺乏对于文本中单词之间的长程语义关系及其相关依赖性的描述,同时也忽略了文本的层次结构信息。
针对上述问题,本文提出了一种融合图卷积网络和胶囊网络建模文本内容的联合排序推荐算法(ranking lear-ning fused with capsule networks and graph convolutional network,RL-CNGCN)。具体而言,首先,构建图卷积网络学习文本特征并捕捉文本单词之间丰富关系,同时采用胶囊网络提取文本信息的高阶层次结构信息,从而通过融合图卷积网络和胶囊网络实现文本特征的细粒度学习。然后基于扩展的排序学习模型对用户与项目交互的联合关联以及项目与项目描述相关文本内容之间的关系进行联合建模,实现精准用户偏好的推断。基于公开亚马逊数据集进行广泛的实验结果表明,本文所提出的方法具有更好的推荐性能。
本节从如下两个方面回顾与本文相关的内容感知推荐算法研究技术:
(1)基于评论和评分信息实现内容特征学习。传统方法基于主题模型从评论中提取主题实现用户和项目的特征表示学习,然后基于评分预测模型进行推荐[2]。由于主题模型是标准的词袋模型,使得上述传统方法大多受限于词袋模型固有的缺陷,不能有效利用内容文本中的上下文信息和单词序列。当前深度学习模型偏好利用深度学习理论学习文本信息的潜在完整特征,从而达到缓解上述问题的目的。Zheng等[3]采用两个并行的CNN从评论文本中对用户行为和项目属性进行建模。而Xia等[6]则基于注意力的GRU网络从用户和项目评论中学习上下文感知表示,然后进行评分预测。Liu等[7]则提出一种基于混合神经网络融合评分和评论的推荐模型。受限于卷积操作接受域或局部注意力等,使得大多已有深度学习方法在文本特征学习时,忽视了文本中语义信息上下文特征相关性的学习以及文本中固有的高阶层次结构信息,无法突出文本中不同语义特征的差异性、多样性和重要性。
近年来,随着图神经网络研究的深入,GCN超强的特征学习能力为深度学习方法在内容特征建模中遇到的上述问题提供了一种新的解决方案。Wu等[8]基于多视图的理论,提出了一种新的融合注意力机制和图神经网络实现文本信息建模的方法。TextGCN模型[9]则基于词共现和文本-词关系构建单个文本图,然后基于图卷积网络实现词和文本的特征学习。
(2)基于排序的推荐方法。基于内容的推荐方法大多偏好采用评分预测模型,仅仅依靠评分大小的顺序并不能准确体现用户的偏好。用户在实际场景中更关心项目的排序,而基于排序学习的推荐算法直观展示了推荐结果。其中最具代表性的基于排序学习推荐模型是逐对排序推荐模型-BPR模型。Shang等[10]将BPR排序模型与贝叶斯模型结合用于事件推荐。Wu等[11]的工作则是将BPR模型和图嵌入模型结合用于推荐模型。而Gao等[12]利用地理社交相关性,提出一种新的BPR成对排序假设,从而构建一个三级联合成对排序模型用于兴趣点推荐,获得了更好的推荐性能。
本文基于融合图卷积网络和胶囊网络的方法学习文本信息的细粒度特征表示。然后,提出基于一种新的联合逐对排序推荐算法实现用户-项目-文本三者的融合,从而提升推荐性能。
本节中,主要介绍所提出的RL-CNGCN算法框架,如图1所示。本文首先给出相关问题的形式化描述,然后提出融合图卷积网络和胶囊网络的细粒度文本特征学习,再构建一个基于联合函数的内容感知排序推荐模型,实现用户-项目交互的联合关联以及项目与关联词之间的关系建模的融合,从而将评分和评论信息的文本特征表示融合到一个统一的排序推荐模型中,提供精准推荐服务。

图1 RL-CNGCN 算法框架
2.1 问题形式化和预备知识
在本文中,让U、I和N分别表示用户、项目和词的集合。对于用户和项目之间的交互,表示为Cu,i={(u,i)|u∈U,i∈I}, 以及项目和单词之间的关系,表示为Ci,z={(i,z)|i∈I,z∈N}, 其中每个项目的单词是从其描述文本中提取的。同时,给定一个无向图G=(V,E), 其中,V是顶点集, |V| 表示顶点的数量,E是边集。每个顶点都与一个维度为d的特征向量相关联,文档特征矩阵X∈R|V|×d用于表示所有顶点的特征,它也被设置为单位矩阵。边集E通常由邻接矩阵A∈R|V|×|V|表示,其中Aim,jn是第im个顶点和第jn个顶点之间的边的权重。度矩阵B∈R|V|×|V|是对角矩阵,Bim,jn=∑jmAim,jn。
构建的文本图中的节点数 |V| 是文本的数量加上数据集中唯一词的数量。一个文本节点和一个词节点之间的边的权重是该词在文本中的词频-逆文本频率,其中词频是指该词在文本中出现的次数,逆文本频率是包含该词文本数量的对数比例倒数。

本文的目标就是通过采用融合图卷积网络和胶囊网络的混合网络学习文本细粒度特征,然后整合用户-项目、用户-文本、项目-文本之间的关联来构建联合排序推荐模型学习用户偏好,从而为每个用户提供个性化项目排名列表。
2.2 文本细粒度特征学习
本节描述如何融合图卷积网络和胶囊网络学习文本细粒度特征。由于文本中存在的层次结构常常在特征学习时被忽略[13],为了学习文本的细粒度特征,本文受到胶囊网络[14,15]的启发,利用胶囊网络提取文本中的层次结构信息,从而融合图卷积网络和胶囊网络来学习文本细粒度特征。如图2所示,基于图卷积模型构建相关文本中单词的图模型表示,精准捕获了文本中单词的长期且非连续关系。然后将获得的文本单词特征表示视为一个胶囊,通过构建含有两个胶囊层的胶囊网络,实现图卷积网络和胶囊网络的密切融合,达到学习文本的细粒度特征表示的目的。在融合图卷积网络的胶囊网络中,两个连续胶囊层间基于多次迭代的路由算法进行更新,进而提取文本信息中层次结构信息,这有助于捕获到复杂场景中文本的细粒度特征。

图2 文本细粒度特征学习
2.2.1 构建基于图卷积网络的文本单词特征学习
首先,本文为每个文本创建一个无向图来对其内容信息进行建模。给定一个文本,将内容中的词作为图的顶点。与Wu等[13]一样,本文也采用逐点互信息(PMI)来计算边的权重,从而保留了全局词共现信息。具体来说,在源域和目标域中的所有文本上使用固定大小的滑动窗口来收集单词共现统计信息。
计算词对的PMI如下
(1)
(2)
(3)
其中,Hw(zi) 是包含单词zi的滑动窗口数,Hw(zi,zj) 是包含单词zi和zj的滑动窗口数, |Hw| 是滑动窗口的总数。由于PMI分数可以反映词之间的相关性,PMI分数越高,则反映语义相关性越强[8]。因此,本文只保留具有正PMI分数的词对之间添加边
(4)
其中,ai,j是词zi和zj之间的关系。经过这个过程,得到了全局语料上的词关系,邻接矩阵A是每个文档中词关系的子集。
然后,本文采用多层GCN模型实现节点级单词的文本特征学习。本文通过堆叠多个图卷积层来合并高阶邻域信息,为节点生成新的向量表示l,得到如下公式
l0=X
(5)
(6)
(7)

2.2.2 融合图卷积网络和胶囊网络的文本细粒度特征学习
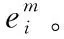

(8)
其中,挤压函数squash() 确保每个特征向量的方向不变,而其胶囊的长度缩小。

(9)
(10)
(11)

(12)
2.3 联合排序模型
首先,本节深入分析用户与项目及项目与文本之间的关系,同时受到Chen等[16]设计的排序学习模型启发,基于本文提出的模型假设,分别建模项目偏好排名和词相关性排序模型。然后描述所提出的联合排序模型,并给出采用模型的推导与优化过程和参数学习过程。
2.3.1 用户项目偏好排序学习
基于BPR模型实现项目偏好排名模型,本节通过利用三元组Du作为训练数据来优化项目对的正确排名,基于观察到的用户-项目交互为每个用户生成个性化的项目排名列表。该模型的似然函数如下

(13)
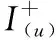
q(j>u|Θ)=η(〈Θu,Θj-Θ′j〉)
(14)
其中, 〈·,·〉 表示两个向量之间的点积, Θu和Θj分别表示上节中用户u∈U和项目j∈I的d维向量表示,j>uj′表示用户u更喜欢项目j而不是项目j′, 对于每个三元组 (u,j,j′)∈Du,j>uj′。
〈Θi,Θj-Θ′j〉 表示对关于项目j和j′与项目i的相似度建模,η(·) 表示sigmoid函数。
2.3.2 项目文本相似性排序学习
基于BPR扩展模型,本文根据项目的描述对项目和相关词之间的关系基于排序学习模型进行建模。受到Xu等[17]基于单词分布学习单词语义建模技术的启发,本文提出最大化相关(正)项目-词对的似然函数,通过利用Di中的项目-单词-单词三元组作为训练数据,而不是每个项目的不相关(负)项目词对,因此有如下公式
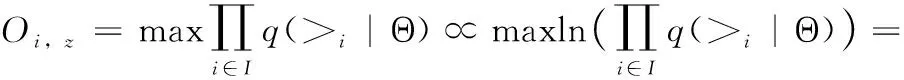
(15)
其中, >i表示项目i的成对单词相关性(即,ez>iez′表示单词z比单词z′与项目i的相关性更高,对于每个三元组 (i,z,z′)∈Di,ez>iez′)。q(ez>iez′|i) 计算为
q(ez>iez′|i)=η(〈Θi,Θz-Θz′〉)
(16)
其中, Θz是来自单词z∈Z的d维行向量表示, 〈Θi,Θz-Θz′〉 表示对关于单词z和z′的项目i的词相关性排序建模。η(·) 表示sigmoid 函数。
2.4 联合排序模型学习与优化
文本信息来源的重要来源是项目描述。在相关文本信息的描述中,用户对有些关键词更加关注,因为这些词能够更加体现项目的特征(例如它们的长度、年龄或风格),从而潜在的反应用户的偏好。因此,本节提出构建一个融合文本内容基于排序学习的联合推荐模型。
首先,本文给出如下定义:
(1)〈Θu,Θj-Θj′〉:
对用户u关于项目j和j′之间的项目偏好排名进行建模;
(2)〈Θi,Θj-Θj′〉 表示对关于项目j和j′与项目i的相似度建模;
(3)〈Θu,Θz-Θz′〉:
对用户u关于词z和z′的词相关性排名进行建模;
(4)〈Θi,Θz-Θz′〉:
对关于词z和z′的项目i的词相关性排名进行建模。

因此本文设计一个联合似然函数,该函数联合考虑上述定义中(1)~(4)所示的4种类型结构。即分别由上述2.3.1小节和2.3.2小节的排序学习模型组成:
>u和>i。
显然>u和>i本质上是相互依赖的,因为给定用户交互的项目在这两个排序学习结构中重叠。本文设计的这个联合似然函数的目标是找到一个联合表示矩阵Θ,从而最大化观察到的用户-项目和项目-词对,并描述上述4种复杂关系
(17)
其中, >u表示给定用户u∈U的两个项目之间的偏好结构, >i表示给定项目i∈I的单词之间的相关性结构。
基于上述假设的上述联合似然函数的计算如下

(18)

(19)
其中,ζΘ是特定于模型的正则化参数。
根据学习率ϖ更新模型参数
(20)
在本文中,式(17)中的目标函数采用异步随机梯度下降算法—ADMA算法来最大化公式以并行有效地更新参数。具体来说,对于每个给定的 (u,i) 对,本文为用户u随机抽取一个正项目作为j,将一个负项目作为j′, 为项目i随机抽取一个正负单词对作为 (z,z′), 从而得到三元组 (u,j,j′)∈Du和 (i,z,z′)∈Di用于更新参数,梯度定义为

(21)

算法:融合图卷积和胶囊网络的内容感知排序推荐算法
输入:用户评分数据信息、项目属性信息、目标用户,文本信息
输出:目标用户的排序列表q(j>uj′,ez>iez′|Θ)
具体的步骤如下:
步骤1 对用户评分数据进行预处理;
步骤2 根据式(1)~式(4)构建文本信息中单词图模型;
步骤3 根据式(5)~式(7),基于图卷积网络学习文本单词特征的表示为lm;

步骤5 利用用户-项目-项目三元组Du, 根据式(13)~式(14)优化项目的正确排名q(j>u|Θ);

步骤7 根据给出的定义,基于式(17)~式(18),构建联合排序学习损失函数q(j>uj′,ez>iez′|Θ)。
步骤8 采用异步随机梯度下降算法-ADMA算法,基于式(18)~式(20)来优化上述损失函数,并更新相关参数。
3.1 数据集与数据处理
与Liu等[18]类似,本文也采用4个不同领域的亚马逊数据集上进行实验,验证本文提出推荐算法的性能,其数据集描述见表1。显然,这4个数据集具有不同的特征。对于这些亚马逊数据,本文在实验中采用了用户项目评分和项目描述,将评分项目视为正面反馈,其余视为负面反馈,并删除评分少于3个项目的用户。所有的实验数据集都包含用户-项目交互和文本项目描述。在预处理中,本文将用户-项目交互转换为隐式反馈。对于项目描述,本文过滤掉词频小于5的词或文本频率小于相应语料库10%的词。表1列出了每个数据集的预处理数据的统计信息,包括单词数、隐式反馈量(U-I边)以及项目和单词之间的关系数(I-W 边)。同时遵循Liu等[18]的方法,对数据集的评论信息还进行了如下预处理:①删除停用词;
②将原始文本的长度设置为300;
③计算每个单词的词频与文本频率成反比的值。

表1 亚马逊数据集统计
3.2 评估指标与参数设置
本文基于两个评估指标进行Top-N推荐的性能评估:召回率(表示为Recall@N[8])和归一化折扣累积增益(表示为NDCG@N[8])。对于所有数据集,本文将用户-项目交互随机分为70%和30%,分别作为训练集和测试集。每个用户的推荐集是作为正面项目的集合生成的,其中包含1000个随机选择的负面项目。
在本文的实验中,RL-CNGCN和GCN中文本特征的维度为150,ζΘ=0.025, 学习率ϖ=0.05, 窗口大小设置为10,p在训练中从0到1。NCTR和DAML中批次大小设置为128,丢弃率为0.2,学习率是0.0001,维度大小设置为100,卷积核数量为100,滑动窗口的大小是5,迭代次数设置为200。JRL的批次大小是64,学习率是0.5,维度大小为300。MCRec的批量大小为256,学习率为0.001,正则化参数为0.0001,维度大小为128。RMG的学习率为0.001,潜在维度为32,丢弃比率为0.1,正则化项为0.1。
3.3 实验方案设计
本文从如下3个不同的角度进行实验测试,以验证文中算法的有效性:
(1)将本文提出的算法与4个主流先进推荐算法进行对比;
(2)基于提出的融合图卷积网络和胶囊网络的方法与3个基准方法进行对比,这些基准方法是推荐系统中常用的;
(3)讨论了维度参数对于推荐结果的影响。
实验中选取如下几种基准算法进行对比:
(1)DAML[18]:一种基于双层注意力互学习机制的基于内容的推荐算法。
(2)JRL[19]:一种基于图神经网络的推荐算法,它在图神经网络框架下对协同知识图中的高阶关系进行显式建模,基于不同信息源中学习联合表示以进行Top-N推荐。
(3)MCRec[20]:一种融合正则化和基于路径的推荐算法,这种模型结合了正则化和基于路径的方法。
(4)NCTR模型[7]:一种混合神经网络融合评分和评论信息进行项目推荐算法。
为了评估本文提出的方法和下面几种学习方法进行比较:
(1)GCN[9]:基于图卷积网络学习文本特征;
(2)GRU[6]:基于GRU网络学习文本特征;
(3)RMG[8]:基于层次图神经网络和注意力机制学习文本特征。
3.4 实验结果分析
3.4.1 实验模型性能对比
实验结果见表2和表3,显然,本文提出的RL-CNGCN在所有数据集上始终优于其它上述对比主流先进推荐算法。也验证了本文提出的模型的有效性和高效性。可能原因如下:①对于内容特征学习这个方面,本文采用融合图卷积神经网络和胶囊网络的混合神经网络有着更强的学习能力;
②基于扩展BPR模型的逐对排序推荐性能优于基于评分预测的推荐性能,同时融入项目-文本的交互实现了对用户特征向量的一定约束从而得到了用户偏好更细粒度的描述,很明显,这也再次验证了文本内容信息能够对于用户的偏好产生一定的影响。MCRec是基于元路径实现用户和项目的精准表示,但是其过于依赖元路径的质量,使得其需要极其广泛的领域知识来实现元路径的定义。DAML和NCTR都是基于深度学习的方法融合评论和评分信息进行推荐,其中NCTR缺乏对于用户和项目高阶交互信息的建模,使得其性能落后于DAML。而DAML模型一方面相对于MCREC, 容易受到数据稀疏的影响,另外一方面,也如同3.4.2小节所验证的,基于图卷积模型对文本的表示学习优于采用基于卷积操作的文本内容特征学习。JRL模型虽然采用了TOP-N推荐框架,但是它没有采用深度学习的方法,而是利用doc2vec模型实现了内容特征的学习。在文本内容建模过程中,没有突出文本中关键词的权重,也没有考虑文本上下相关词的特征之间的影响,使得其只实现对文本内容的粗粒度建模,同时上述实验结果也恰好再次验证了基于深度学习的方法对比传统方法可以实现文本内容特征更加精准的学习。

表2 基于Beauty数据集和Application数据集的性能对比

表3 基于Software数据集和Fashion数据集的性能对比
3.4.2 文本特征建模对比
本节将本文采用的方法与几种主流方法进行对比。
实验结果见表4和表5,RL-CNGCN在4个数据集上的表现最好并且明显优于所有对比模型,这展示了所提出的方法的有效性和高效性。其将胶囊理论融合到图神经网络中实现了文本内容表示学习,生成的图和胶囊不仅保留了层次结构等相关的信息,还保留与图属性有关的其它信息,这些信息可能对后续建模工作有用。其作为一种新颖的框架,显然融合胶囊网络的图卷积网络实现了更有效的图表示学习。对于其更深入的性能分析,本文也发现其在稠密数据集上性能优于稀疏数据集。GCN相对比RMG、GRU,其自身图卷积结构的特点决定了在捕捉文本-词关系和文本中全局词-词关系,使得其优于GRU方法和RMG方法。但同时GCN也受限其自身运行机制,在文本内容特征抽取中,大多忽略了文本中层次结构关系。GRU模型性能最弱,可能的原因因为基于 RNN 的方法擅长处理序列信息,特别是短期序列信息,但其无法对非连续短语和长距离词依赖信息进行建模,从而无法获得文本中长距离的关键关系。RMG稍强于GRU,可能的原因因为它们利用层次图神经网络加上注意力的方式学习文本特征,通过利用注意力机制来突出文本特征中单词、句子、段落等重要性。

表4 基于Beauty数据集和Application数据集文本特征建模对比

表5 基于Software数据集和Fashion数据集文本特征建模对比
3.4.3 参数影响分析
这一节主要介绍相关参数设置对RL-CNGCN的影响。主要从文档潜在因子的维度这个方面对RL-CNGCN算法进行分析,结果见表6和表7。
从表6和表7的结果中,可以观察到:①通过增加潜在维度,模型性能得到了提高。可能的原因是过于小的维度不足以充分表达用户的潜在特征。但是,当潜在维度增大到一定范围时,模型趋于稳定,如果继续增加潜在维度,则推荐性能不再提高。造成这个现象的原因可能是模型也随维度的增加从而导致过拟合现象的出现。因此,本文将潜在维度设置为150;
②在4个数据集上均呈现相似的变化,但是相同的潜在维度在不同的数据集上具有不同的性能。可能的原因是各个数据集的稀疏度各不相同。

表6 基于亚马逊数据集潜在维度Recall值分析
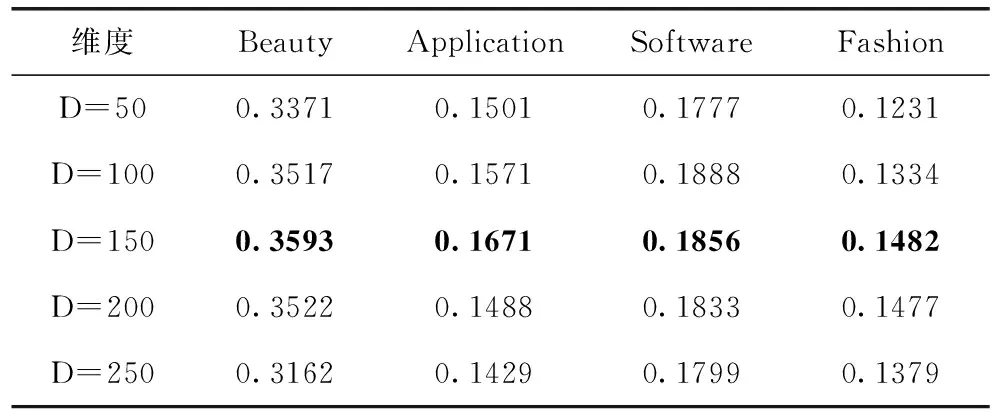
表7 基于亚马逊数据集潜在维度NDCG值分析
在本文中,提出了一种内容感知推荐算法。它融合图卷积网络和胶囊网络来建模文本评论内容,全面捕获文本中的语义信息和层次信息。然后将推荐问题视为排序问题,基于扩展的BPR标准,设计一个统一的联合损失函数,拟合用户-项目交互的联合关联,并融合项目与相关文本之间的关系,最终实现用户偏好的精准推断。实验结果表明,所提出算法优于基准推荐算法。未来工作,将进一步研究图神经网络在内容感知推荐系统的应用。
猜你喜欢 排序卷积建模 排序不等式中学生数理化·七年级数学人教版(2022年11期)2022-02-14基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02联想等效,拓展建模——以“带电小球在等效场中做圆周运动”为例中学生数理化(高中版.高考理化)(2020年11期)2020-12-14恐怖排序科普童话·学霸日记(2020年1期)2020-05-08卷积神经网络的分析与设计电子制作(2019年13期)2020-01-14从滤波器理解卷积电子制作(2019年11期)2019-07-04节日排序小天使·一年级语数英综合(2019年2期)2019-01-10基于PSS/E的风电场建模与动态分析电子制作(2018年17期)2018-09-28不对称半桥变换器的建模与仿真通信电源技术(2018年5期)2018-08-23基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20推荐访问:卷积 感知 胶囊推荐文章
- 2018年江西赣州市医疗急救中心招聘编外人员公告:赣州市医疗急救中心
- 升学宴策划活动方案|2018升学宴活动方案
- 小学六一游园活动总结 [小学六一游园活动策划]
- 2018年中国工商银行广东分行暑期实习生招聘岗位、报名时间:2018中国工商银行广西分行春招
- 澳洲留学八大名校排名申请条件_澳洲留学奖学金申请条件及时间
- [调工商档案介绍信范文] 工商档案查询介绍信
- 加拿大亲属移民政策最新更新|加拿大亲属移民条件
- 初一下册语文练习册答案人教版2018 2018人教版语文练习册答案
- 贵州贵阳房价2018 2018年贵州贵阳中医学院第二附属医院招聘方案
- 【2018广东省湛江市赤坎区审计局招聘公告】2018湛江市赤坎区教师招聘