基于混合语义的图神经网络小样本图像分类方法
来源:优秀文章 发布时间:2023-02-27 点击:
付炳光,杨 娟,汪荣贵,薛丽霞
(合肥工业大学 计算机与信息学院,合肥 230601)
在计算机视觉的多个领域中,深度神经网络[1-2]均取得了优异的效果。深层的网络模型在训练时通常需要大量的标记数据,昂贵的数据标注成本使得模型训练成本大幅增加。同时在许多实际应用场景中,也不具备获得足够多标注样本的条件。在这种情况下,如何利用有限的标注样本获得性能较好的网络模型也随即成为一个亟待攻克的热点研究方向。基于此,小样本学习受到了广泛的关注。研究可知,元学习方法[3-4]在训练阶段和测试阶段构造相似的情节(episodes)任务,模拟人类总结任务经验的能力以使得机器从相似任务中获取通用知识并快速适应新任务,缓解了过拟合问题,成为了众多小样本学习方法的通用机制。
图神经网络[5](graph neural networks,GNN)通过构建结构化信息的方式有效地提升深度学习模型的性能,许多研究[6-9]也开始尝试将图模型应用到小样本学习中。Garcia 等人[6]实现图模型预测值到标签值之间的后验推理,基于消息传递的想法,利用图推理将标签信息传递到没有标签的样本上,进而判别样本类型。Liu 等人[7]使用转导推理的方法,将所有无标注数据和有标注数据共同构建一个无向图,然后通过标签传播得到所有数据标签。与前面方法中图结构仅使用一组边特征表示类内相似、类间不同的节点关系不同,Kim 等人[8]构造了2 组边特征,将节点间相似关系和不相似关系分开考虑。Ma 等人[9]使用支持样本和查询样本组合构成关系对并作为图节点,在传播和聚合节点信息过程中同时考虑节点间的相似性联系和节点内支持样本和查询样本关系。现有基于图神经网络的小样本学习方法通过构建出不同的图结构,虽然取得了优异的分类效果,但未考虑与图像相关的标签语义信息。与之不同,人们从少数样本中学习新概念时,不仅对比不同样本之间的差异,同时也考虑与之相关的文本知识。因此本文提出的方法尝试在使用图神经网络考虑图像特征间关系的同时,融入图像标签语义信息。
元学习方法的灵活性为学习新概念时引入其他模态提供可能。不同模态蕴含的信息有互补性和一致性[10],不同模态间既含有类似的信息,同时也可能含有其他模态所欠缺的信息。在图像任务中,引入文本信息可以更全面地描述样本实例。Frederikd等人[11]为获得更可靠的原型,通过生成对抗网络(generative adversarial networks,GAN)将语义特征对齐到图像特征空间,生成新特征改进图像类原型特征计算。Peng 等人[12]根据数据集标签在WordNet 中的关系,由标签语义特征通过图卷积神经网络(graph convolution network,GCN)推理得到基于知识的分类权重,并与视觉分类权重融合得到新类的分类权重。Chen 等人[13]提出了Dual TriNet,通过编码器将图像特征映射到语义空间,以随机添加高斯噪声等方式对该特征增广后,由解码器反解码形成各层特征图,由于可以无限增广,对此扩充训练特征。Li 等人[14]将标签语义特征经由多次kNN 聚类得到多层超类语义特征,并构造底层为标签语义,上面多层为超类语义的树形结构的分层语义。如此一来,图像经由分级分类网络的同时在不同层会进行分类,训练得到良好的特征提取器。这些方法主要考虑类级别的语义信息,而忽略具体实例间的差异,一定程度上丧失了识别能力。为此,本文方法通过混合语义模块将实例级的图像特征对齐到语义空间并与其标签语义融合,为语义特征添加实例间的差异信息。此外,还通过补充语义信息增强标签语义的表达能力。
综上所述,本文提出了基于混合语义的图神经网络小样本分类方法。在常用小样本数据集上进行试验,并取得了良好的分类效果。
1.1 问题定义
小样本图像分类目的是在仅有少量目标类标注样本的情况下,训练得到泛化性能良好的分类网络模型。通常将数据集划分为类别互不相交的训练集、测试集和查询集。同时采用episode 训练机制[15],分为训练阶段和测试阶段,每个阶段由许多相似的n -wayk -shot 分类任务组成(现常见5-way 1-shot 和5-way 5-shot 两种类型)。具体地,训练阶段每个分类任务从训练集中随机抽取n个类,每类随机抽取k +q张图片,构成当前任务的支持集S ={(xi,yi),i =1,2,…,nk}和查询集Q ={(xj,yj),j =1,2,…,nq},其中xi,xj表示图像,yi,yj表示该图像对应的标签。模型利用支持集样本的图像和标签信息判断查询样本的标签信息,并通过最小化已设计好的损失函数,反向传播更新网络模型参数达到模型训练的效果。训练阶段包含模型验证,从验证集随机采样构造n -wayk -shot任务,检测模型泛化能力,保存最优的模型参数。最终,测试阶段在测试集上验证泛化性能。由于训练阶段和测试阶段构造类似的分类任务,由训练得到的模型能很好地迁移到训练集任务上。
1.2 基于混合语义的图神经网络模型
本文提出的模型结构如图1 所示,包含图像特征信息传播模块、混合语义模块和决策混合模块。在每个分类任务中,图像通过图像特征提取网络得到图像特征,标签由GloVe[16](Global Vector)计算得到标签语义特征。随后,图像特征信息传播模块使用图神经网络考虑任务上下文关系,更新得到任务相关的图像特征表示。混合语义模块利用补充语义信息和特征提取网络得到的视觉信息,增强标签特征的表达能力,得到混合语义特征。最后由决策混合模块组合图像特征和混合语义特征进行分类。

图1 基于混合语义的图神经网络模型Fig. 1 The model of hybrid semantic-based graph neural network
1.2.1 图像特征信息传播模块
图像特征信息传播模块使用图神经网络考虑图像特征上下文关系进而传播聚合特征信息,并更新特征表示。模块包含L层图像关系图Gl =(Hl,El),l =1,2,…,L。第l层的图节点Hl由特征节点组成,特征节点与特征节点间的相似度可表示为,两节点之间的相似度越高,越接近1,反之接近0。该层所有的节点相似关系构成了邻接矩阵。
对于图像xi,输入到特征提取网络Fex后,经过池化层和拉平层得到独热编码(one-hot coding)形式的图像特征向量Fex(xi),将其作为图中初始节点特征(xi)。初始邻接矩阵E0采用公式(1)进行初始化:

相同标签的支持集节点间的特征边设置为1,而不同标签的支持集节点间设置为0。此外,由于查询样本的标签未知,统一将支持集节点和查询节点的特征边设置为1/nk。同时,根据描述节点间相似度关系的邻接矩阵,节点相互传播信息并聚集更新得到下一层节点。随后,更新节点间相似度得到下层的邻接矩阵。多层更新后得到每个样本的最终图像特征。具体地,对于第k层更新过程表示为:


1.2.2 混合语义模块
GloVe[16]和Word2Vec[17]等文本嵌入方法根据词语在语料库中的分布,将词语转换为独热编码(one-hot)表示的语义特征。语义特征不仅含有词语信息,还蕴含语料库不同词语间的联系。“卡车”与“汽车”间相对于“狗”与“汽车”间具有更强的关联性。换而言之,对于一个与“汽车”关联性很强的未知词语,该词语为“卡车”的概率比为“狗”的概率更大。据此,本节提出混合语义模块,通过文本嵌入的方法计算得到类别标签的语义特征,并引入其他词语作为补充描述,以增强其表达能力。
相比于因有限窗口大小而仅可捕捉局部信息的Word2Vec,本文使用可以捕获全局信息的GloVe 方法计算标签的语义特征,并将所有支持集类别作为补充词语。混合语义模块如图2 所示。由图2 可看到,当前任务类别标签和补充词语由GloVe 方法计算得到标签语义特征集St∈和补充语义特征集Sa∈,这里的dw表示语义特征的维度。运行时,先将St和Sa分别进行线性变换后输出Q和K,接着将Q和K做矩阵乘法之后再乘以缩放系数经过softmax函数输出注意力分数矩阵A,由此推得的各数学公式分别如下:
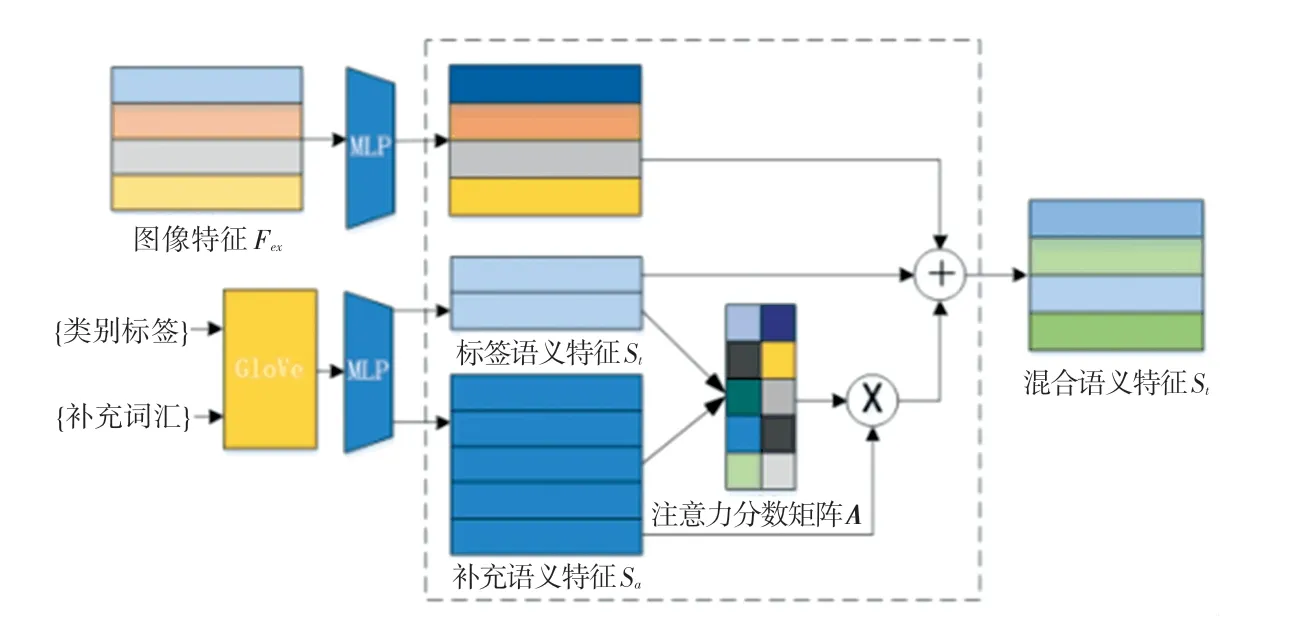
图2 混合语义模块Fig. 2 The hybrid semantic module
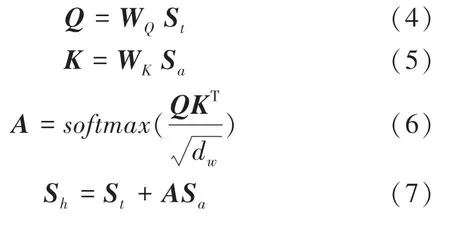
式(4)和式(5)中,WQ,WK∈为权重矩阵,引入缩放系数得到更为平滑的输出。式(7)将注意力分数矩阵A与Sa做矩阵乘法后,再以相加的方式与标签语义特征融合,得到增强语义特征集Sh ={sh1,sh2,…,shN}。在理解特定对象时,不同词语的重要性不同。正如“卡车”与“汽车”之间的联系比“狗”与“汽车”之间的联系更强,“卡车”的语义对理解“汽车”更为重要,注意力分数矩阵A起到了相似的作用,反映了Sa中的每个语义特征补充描述St中语义特征时的重要程度。
此外,在n -wayk -shot 任务下可能有多张图片属于相同类别,不同图像特征对应同一语义特征忽略了同类图像特征之间的差异性。不同模态间往往具有相关的信息[10],本文模型尝试将图像特征对齐映射到语义特征空间中,与混合语义特征融合构建实例级的语义特征表示。对于支持集图像特征Fex(xi),其映射得到的特征为:
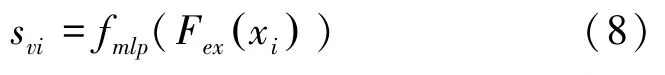
将svi与实例xi标签的增强语义特征shy融合得到该实例的混合语义特征si:

1.2.3 决策融合
由图像特征信息传播模块可以得到考虑图像上下文关系的图像特征,而混合语义模块得到支持集实例的混合语义特征。不同模态间存在互补性[10],可能包含其他模态所欠缺的信息,利用多个模态的信息有助于更好地描述实例。本方法通过式(10)组合支持集图像特征和混合语义特征:
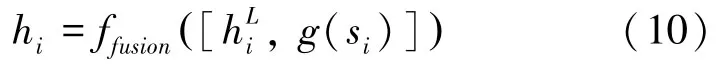
其中,“[,]”表示级联操作。式(10)中将实例xi的混合语义特征si输入网络g后,与其图像特征,再经由网络ffusion得到混合模态特征hi,g和ffusion均由多层感知机和ReLu激活函数构成。
1.3 损失函数

其中,i,j分别为支持样本和查询样本下标,onehot(yj) 是支持集样本j标签的独热编码。在给定episode 任务下,利用最小化分类损失函数来训练模型:
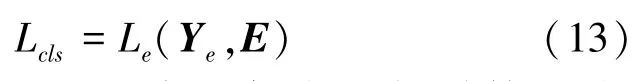
其中,Ye是真实的相似度邻接矩阵,计算Ye与预测矩阵E之间的二值交叉熵作为分类损失函数。
图像特征信息传播模块的邻接矩阵同样也可以预测节点分类,增加式(14)的损失函数用来改善训练过程中的梯度更新,但仅用E作为查询样本的标签判断。式(14)的数学表述具体如下:

GloVe[16]将语料库中词汇X在词汇Z出现的情况下出现的概率PX|Z与词汇Y在词汇Z出现的情况下出现的概率PY|Z的比值,称为共现概率比。当X与Z的关联性和Y与Z的关联性都很强或者都很弱时,共现概率比趋于1,否则共现概率比趋于很大或者趋于零。通过引入第三个词汇Z,共现概率比很好地描述了词汇X和词汇Y间的相似性。受此启发,为使公式(8)中图像特征更好地映射到语义空间,通过计算映射后的特征与整体补充语义特征的相似度矩阵Av,a,实例标签语义特征与整体补充语义特征的相似度矩阵At,a,并计算2 个相似度矩阵之间的相似熵损失:

模型的总损失如式(16)所示:

其中,λ1,λ2为超参数,用于调整损失Le和LKL对网络模型训练的影响。
2.1 数据集
为了更好地对比分析模型性能,本文在小样本学习方法常用的Mini-ImageNet 和Tiered-ImageNet数据集上进行了实验。本节中所有实验均在搭载NVIDIA GeForce TiTan X 12 GB 显卡、Intel i7 -9700KF 处理器并具有16 G 运行内存的PC 机上完成,采用Linux 版本的PyTorch 10.2 深度学习框架实现模型的搭建。
Mini-ImageNet 数据集是ImageNet[18]的子集,有100 个类别,每类由600 张图片组成。有2 种常见的使用方法。一种方法将80 个类别作为训练集,剩余的20 个类别作为验证集。另一种方法将数据集划分为包含64 个类别的训练集、16 个类别的验证集和20 个类别的查询集。本文使用后一种方法。
Tiered-ImageNet 数据集同样节选于ImageNet数据集。不同的是该数据集比Mini-ImageNet 包含更多的类别,也包含更多的图片数量。在规模上,包含了608 个小类别,平均每个类别有1 281 个样本;
在语义结构上,是将数据集划分成34 个父类别来确保类别之间的语义差距。在以往的工作中,将20 个父类别作为训练集、对应351 个子类别,6 个父类别作为验证集、对应97 个子类别以及8 个父类别作为测试集、对应160 个子类别。
2.2 实验配置
本文分别采用2 种流行的网络Conv4 和ResNet-12[15]作为图像特征提取网络,使用GloVe计算语义特征。Conv4 主要由4 个Conv -BN -ReLU块组成,每个卷积块包含一个64 维滤波器3×3 卷积,卷积输出分别输入到后面的批量归一化和ReLU非线性激活函数。前2 个卷积块还包含一个2×2 最大池化层,而末端2 个卷积块没有最大池化层。ResNet12 主要有4 个残差块,每层残差块由3层卷积层接连组成,并在残差块后添加了2 × 2 的最大池化操作。遵循大多数现有的小样本学习工作所用的标准设置,使用5-way 1-shot 和5-way 5-shot 两种实验设置和提前结束策略,并将Adam 作为学习优化器。在Mini-ImageNet 上训练时,使用随机采样并构建300 000 个episode,设置Adam 初始学习率为0.001,每15 000 个episode 将学习率衰减0.1。对于Tiered-ImageNet 数据集,使用随机采样并构建500 000 个episode,设置Adam 初始学习率为0.001,每20 000 个episode 将学习率衰减0.1。
2.3 模型对比实验和分析
本文模型与其他使用图模型和使用语义模态的小样本学习方法在Mini -ImageNet 和Tiered -ImageNet 数据集上的实验结果见表1、表2。表中,标注N/A 表示该实验结果在原文献中并未展示出来。

表1 在Mini-ImageNet 数据集上不同模型的准确率Tab.1 Accuracy of different models on the Mini-ImageNet dataset

表2 在Tiered-ImageNet 数据集上不同模型的准确率Tab.2 Accuracy of different models on the Tiered-ImageNet dataset
表1 给出了在Mini-ImageNet 数据集上,本文模型与其他小样本方法在5-way 1-shot 和5-way 5-shot 两种任务下的实验结果。从实验结果中可以看出,本文方法明显优于当前大多数小样本学习方法。本文方法与经典小样本学习方法 Matching Network[19]、MAML[3]、Prototypical Network[20]、Relation Networks[21]相比,准确率有明显的提升。与基于图神经网络的小样本方法相比,在1-shot 情况下本文方法比GNN[6]准确率高出5.47%,在5-shot情况下高出5.15%,而与TPN[7]相比,本文在1-shot情况下准确率高出了2.05%,5-shot 情况下高出了2.13%。此外,与同样使用语义信息的TriNet[20]相比,本文模型在1-shot 情况下高出0.82%,但是在5-shot情况下,TriNet[12]的准确率高于本文模型。同样使用Conv4 特征提取网络,与近年来最新的FEAT[24]、MELR[25]模型对比,本文模型虽然在5-shot的情况下准确率略低,但在1-shot 情况下准确率仍然高过这些基准参照模型。
表2 给出了在Tiered-ImageNet 数据集上,本文的模型与其他小样本方法在5-way 1-shot 和5-way 5-shot两种任务下的实验结果。从实验结果中可以看出,本文方法明显优于当前大多数小样本学习方法。本文方法与经典小样本学习方法Matching Network[19]、MAML[3]、Prototypical Network[20]、Relation Networks[21]相比,准确率均有较大提升。与基于图神经网络的小样本方法对比,在1-shot 情况下本文方法比GNN[6]准确率高出11.47%,在5-shot 情况下高出16.4%;
与TPN[7]相比,本文方法在5-shot 情况下准确率高出了0.34%,但在1-shot 情况下TPN[9]有着更高的分类准确率。
在Mini-ImageNet 和Tiered-ImageNet 数据集上,将5-way 1-shot 和5-way 5-shot 两种情况进行对比可以发现随着支持集的样本数量增加,分类的效果也更好。将Conv4 和ResNet12 两种骨干网络进行对比发现,采用更加深层的特征提取网络能得到更高的准确率。
2.4 消融实验
本节通过在Mini-ImageNet 数据集上进行消融实验证明本文模型的有效性以及检验部分参数对模型训练的影响。
首先,本文探究图像特征关系传播模块迭代更新层数对模型准确率的影响。图像特征关系传播模块使用图神经网络充分挖掘图像特征之间的关联信息,由多层包含特征节点和相似度邻接矩阵的相同结构组成,网络层数影响着模块的参数,对整体性能起着非常重要的作用,所以有必要对层数进行消融实验分析。选择5-way 1-shot 作为任务设定,层数分别选择1、2、3、4、5,模型准确率如图3 所示。从图3 中可以看出,当层数由1 到3 时,模型分类准确率有着明显提升,说明在层数较少时,增加模型的层数可以提升整体模型的分类效果。当层数从3 到5 时,模型分类效果有些许波动,但整体而言准确率趋于稳定,不断增加模型层数不能持续提升模型的分类准确率。因此本文在其他所有实验中,模型层设定为3,既能得到较高的模型分类准确率,同时也避免了过多耗时的计算量。
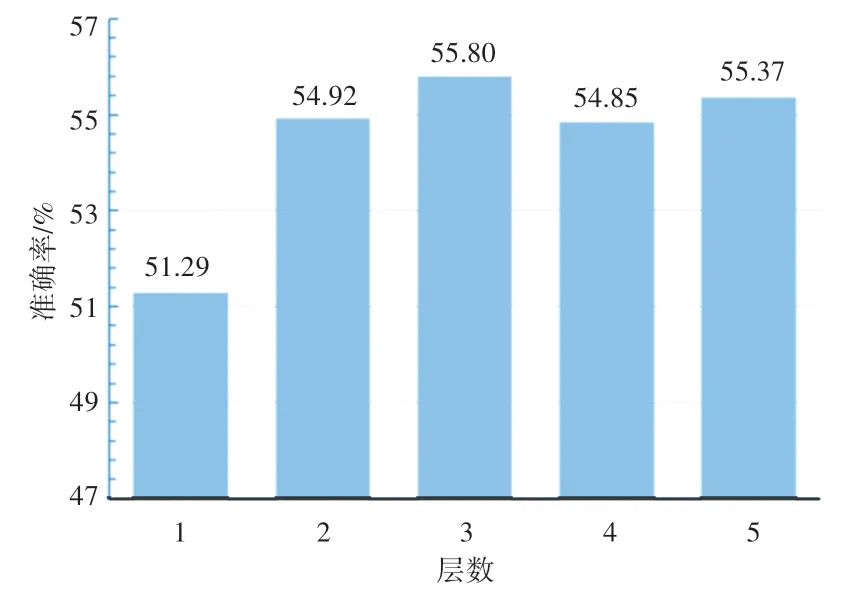
图3 5-way 1-shot 任务下,图像信息传递模块层数对模型分类准确率的影响Fig. 3 Influence of image information transfer module layers on model classification accuracy under 5-way 1-shot task
此外,为探究混合语义模块在模型训练中发挥的作用,对混合语义模块进行消融实验。Mini-ImageNet 数据集上,混合特征模块消融实验结果见表3。表3 中,“仅图像”表示仅使用本文中的图神经网络进行训练分类。“标签语义”表示混合语义模块直接使用标签语义而忽略其他语义信息。“标签语义+视觉对齐语义”虽然使用补充语义信息,但是补充语义仅使用在损失函数中改进模型训练。从实验结果可以看出,引入语义信息能提高小样本图像分类的表现效果。此外,使用混合语义模块在5-way 5-shot 任务下准确率的提高要逊色于5-way 1-shot 任务,主要原因是在5-shot 情况下,图像信息将更加丰富,而语义信息模型效果的提升就很有限。
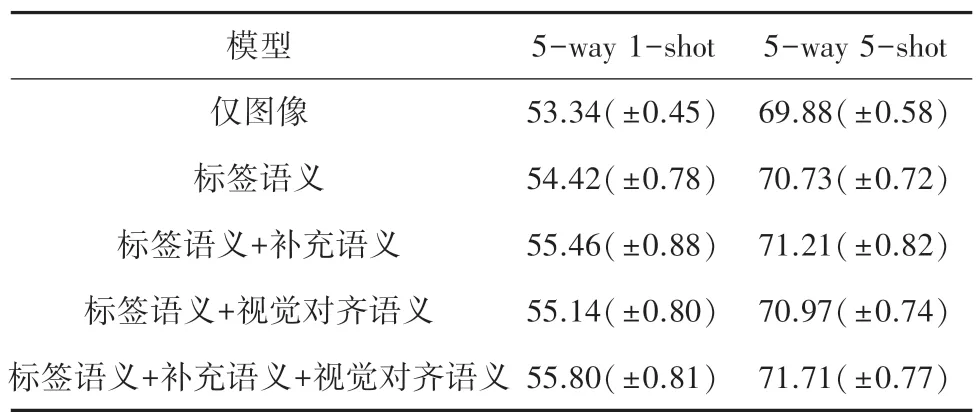
表3 Mini-ImageNet 数据集上混合特征模块消融实验结果Tab.3 Ablation experimental results of hybrid feature module on Mini-ImageNet dataset
本文首先提出了基于混合语义的图神经网络小样本分类方法。该方法考虑实例图像特征和语义特征之间的互补性,由此得到的融合特征,能更全面描述实例信息。其中,使用图神经网络模型综合考虑支持集和查询集图像之间的关系,并使用补充语义来增强标签语义特征的表达能力,以及利用图像对齐语义特征构造了实例级语义特征。本文模型在Mini-ImageNet 和Tiered-ImageNet 数据集上取得了良好的分类效果。考虑到现有模型面对不同任务时,会遗忘已有的分类知识的灾难性遗忘问题,进一步扩展模型应对小样本增量学习则是未来研究工作的重点。
猜你喜欢 语义标签准确率 乳腺超声检查诊断乳腺肿瘤的特异度及准确率分析健康之家(2021年19期)2021-05-23不同序列磁共振成像诊断脊柱损伤的临床准确率比较探讨医学食疗与健康(2021年27期)2021-05-132015—2017 年宁夏各天气预报参考产品质量检验分析农业科技与信息(2021年2期)2021-03-27语言与语义开放教育研究(2020年2期)2020-03-31无惧标签 Alfa Romeo Giulia 200HP车迷(2018年11期)2018-08-30高速公路车牌识别标识站准确率验证法中国交通信息化(2018年5期)2018-08-21不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09批评话语分析中态度意向的邻近化语义构建中国修辞(2017年0期)2017-01-31“社会”一词的语义流动与新陈代谢中国社会历史评论(2016年2期)2016-06-27“吃+NP”的语义生成机制研究长江学术(2016年4期)2016-03-11推荐访问:神经网络 语义 样本