基于无人机LiDAR的单木生物量估测
来源:优秀文章 发布时间:2023-02-12 点击:
武晓康, 王浩宇, 冯宝坤, 王成,2,, 张高腾
(1.桂林理工大学测绘地理信息学院, 桂林 541004;
2.中国科学院空天信息创新研究院数字地球重点实验室, 北京 100094;
3.云南师范大学地理学部, 昆明 650000)
近年来随着无人机激光雷达技术的快速发展,其可高效、准确地获取森林植被的三维点云数据,在森林垂直结构信息和林分特征参数反演具有独特的优势,成为当前林业调查强有力的技术支持,特别是在单木分割及结构参数提取方面,具有地面实地调查不可比拟的优势,通过单木尺度或样方尺度构建局部回归模型,为精确估算生物量提供可靠的基础数据支持[1-3]。
森林生物量作为森林生态系统基本属性数据,其测定和准确估计成为森林研究的热点问题[4]。传统生物量估算采用的是实地样本调查法,例如,李羚菱等[5]利用样本调查法对对昆明地区干湿两季与不同叶龄的桉叶进行研究,结果表明湿季和干季对桉叶面积的影响存在较大差异,生物量对干季与湿季的响应也呈现出明显的不同。袁云香[6]采用样本调查法研究了芦苇的地上生物量动态变化情况,结果表明各项的生物指标与芦苇生长规律符合,芦苇生长状态良好。传统样方调查法需砍伐采集样本进行研究,存在一定的限制性,难以应用到大范围的研究。中外学者开展了基于机载LiDAR数据的参数及生物量反演研究,总体来说可分为林分法和单木法。林分法是以样地为单位,建立LiDAR数据获取的点云高度、密度、强度等变量与实测生物量的模型[7]。Gleason等[8]利用高密度点云数据,分别采用了线性回归和机器学习的方法估测森林生物量,结果表明支持向量机方法精度最高,点云密度、模型差异可能是影响不同方法精度的主要原因。方志良等[9]结合机载激光雷达数据提取的15个特征变量和实测生物量,基于机器学习的方法构建森林生物量估算模型,分析了不同的异速生长方程对森林生物量估算结果的影响,结果表明在4种估算模型中,随机森林方法精度较高。林分尺度下不同森林类型的生物量与LiDAR变量的相关性关系不一,同时模型不同,精度也不尽相同[10]。单木尺度下生物量估算需先识别株树,建立树木结构参数与实测生物量的相关系[11]。Usoltsev等[12]引入虚拟变量构建桦树的异速生长模型来反演生物量,不仅取得了较高的精度,而且模型具有较好的实用性。刘东起等[13]利用小光斑激光雷达数据和实测数据提取树木树高和冠幅,建立回归模型估算了小兴安岭凉水地区的生物量。李桂林等[14]利用无人LiDAR数据提取的树高、冠幅与地基三维激光扫描数据提取的胸径,构建对数和非对数模型,并对模型估算中的不确定性进行探讨,结果表明树高和冠幅的对数模型能更好地估算刺槐生物量,生物量的高低与其健康状态有着很强的相关性。单木尺度下,一定程度上研究区域树种类型、树种分布以及LiDAR数据误差会对生物量估测造成影响[15],但是,在高空间分辨率、高精度的生物量制图中,单木尺度下森林生物量估算起着不可或缺的作用,同时还可为森林生态系统相关研究提供重要的基础资料[16]。
从三维结构出发,参数模型更好解释[17-18],而在众多研究中多元线性模型是最常用的森林参数估测模型,也有研究表明,对于蓄积量、生物量估测而言,非线性模型的精度优于线性模型[19]。因此为提高单木生物量估测的精度和效率,现以广西灵川县桉树(Eucalyptus)和马尾松(Massonpine)为研究对象,从单木三维垂直结构出发,基于地面实测和无人机LiDAR数据,在单木尺度下分树种估测单木生物量,以此来探究不同模型对森林生物量估测的差异,为生物量精确估测提供理论依据。
1.1 实验数据
大疆M600 Pro搭载Riegl VUX-1系统,于2021年10月中旬在广西灵川县获取了多个样地的高密度(平均每平方米192.5个点)点云数据,树种主要为桉树和马尾松。同步获取了4个样方(15 m×15 m)实测数据(单木编号、位置、高度、胸径、冠幅等),共获取了131棵单木,其中3个样方为纯桉树林,1个样方为纯马尾松林。4个样方的统计信息如表1所示。根据外业实测单木结构参数与国家林业局发布的桉树与马尾松异速生长方程[20],计算每个单木地上生物量作为实测生物量。桉树与马尾松的异速生长分别为
W=0.024 073 89(D2H)0.976 805 8+0.004 925 56×
(D2H)0.844 904 4+0.000 708 8(D2H)0.935 545+
0.006 352 5(D2H)0.873 816 2
(1)
W=0.038 120(D2H)0.879 4+0.002 917×
(D2H)1.063 8+0.001 161(D2H)0.999 4+
0.004 785(D2H)0.882 3
(2)
式中:W为地上生物量;
D为实测胸径;
H为实测树高。

表1 样方统计信息
1.2 研究方法
1.2.1 数据预处理
采用基于距离的去噪算法去除离群点[21],然后采用自适应较强的移动曲面滤波分离地面点[22],利用反距离加权插值法(inverse distance weight, IDW)对地面点进行插值生成数字高程模型[23](digital elevation model, DEM),最后为消除地形起伏对植被点云的影响,对植被点云进行归一化处理[24],归一化后的植被树顶点到地面的距离即为单木树高。
1.2.2 提取单木树高与冠幅
单木分割是根据林木间树顶间距大于树冠底端的特点,以局部最大值法搜寻的最大值为种子点,计算种子点与相邻点之间的距离,由树的极大点向最低处按照顺序分类[25]。首先从树顶自上而下,根据所设阈值进行点与点之间距离的判断,不断迭代把每一个点划分到不同的目标树聚类中来实现分割[26]。在Anaconda3中运行算法分割单木,算法提取的极大值,即为树高,取冠层东西、南北两个方向的冠幅并取平均,即为冠幅。
1.2.3 计算冠幅面积与体积
二维凸包算法是计算树冠投影面积的常用算法,凸包是指包含平面点集内所有点并且顶点属于平面点集的凸多边形,从而可根据凸多边形面积估算树冠投影面积[27]。渐进凸包算法是将树冠分割多层规则来模拟树冠形态,计算树干的高度和树高横截面积,然后按照规则体的体积公式分别计算各层体积,最后将各层体积累加求和,即是冠层体积[28]。
1.2.4 生物量模型构建
根据点云提取的单木垂直结构参数构建二变量、三变量及四变量的多元回归模型。以国家林业局发布的树种异速生长方程计算的实测生物量为因变量,点云数据提取的树高、冠幅、冠幅面积及体积为自变量构建多元线性模型[式(3)~式(5)]。非线性模型,其中相对生长模型是最具代表性也是应用最为普遍的,分为CAR(constant allometric ratio)模型和VAR(variable allometric ratio)模型[29]。胥辉[30]利用再抽样的方法观察两种模型的估计误差,评价模型的优劣,结果证明CAR模型优于VAR模型。因此将提取的参数为自变量构建CAR模型[式(6)~式(8)]。
W=b1+b2H+b3C
(3)
W=b1+b2H+b3C+b4S
(4)
W=b1+b2H+b3C+b4S+b5V
(5)
W=b1Hb2Cb3
(6)
W=b1Hb2Cb3Sb4
(7)
W=b1Hb2Cb3Sb4Vb5
(8)
式中:b1、b2、b3、b4、b5为模型待定回归系数;
W为生物量;
H为树高;
C为冠幅;
S为冠幅面积;
V为体积。
1.2.5 模型的精度评价
决定系数(R2)、均方根误差(root mean square error,RMSE)、平均相对误差(mean relative error,MRE)、归一化均方误差(normalized mean squared error,NMSE)和均方根误差百分比(percentage root mean square error,RMSE%)[31]5个指标用于评价所构建模型的精度。
2.1 单木分割
本文研究使用样方2、3、4进行试验,其中包括2个马尾松林和1个桉树林样方。使用1.2.2节的方法进行分割树木,首先以局部最大值法提取最大值为种子点,通过设置树顶间的最小间距、最小冠幅、最小树高阈值进行分割树木。通过比较不同参数设置的分割试验结果,采用效果最佳的0.3 m树顶最小间距、2 m最小树高及1 m最小冠幅的参数分割树木。研究区域数预处理结果如图1所示;
树顶点提取结果如图2和图3所示。

图1 研究区点云数据处理Fig.1 Data processing of point cloud in study area
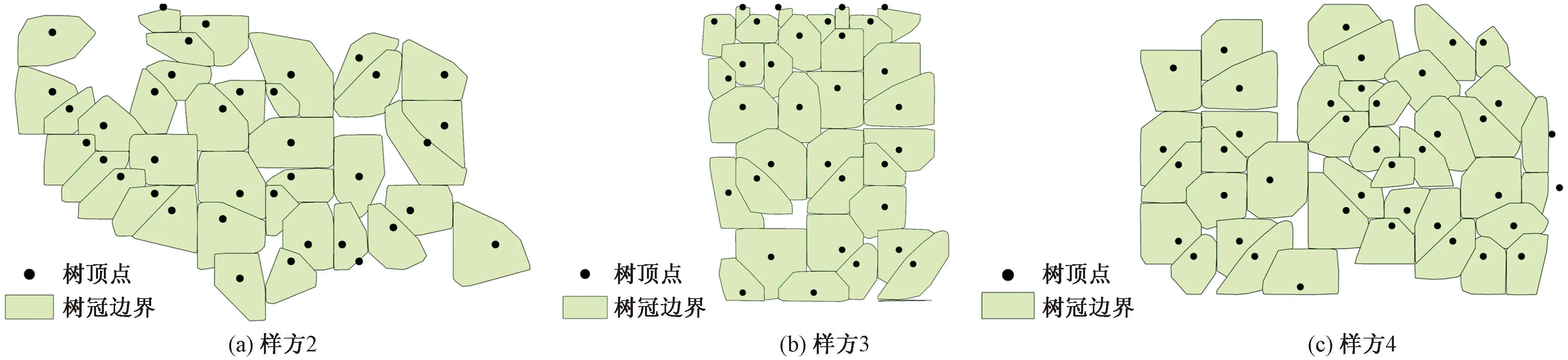
图2 样方树冠结果图Fig.2 Tree crown result map of sample plot

图3 树木分割结果图Fig.3 Individual segmentation result diagram
将算法单木分割的结果与实测数据进行精度评价,采用分割准确率(accuracy rate,AR)、过分割误差(commission error,CE)、欠分割误差(omission error,OE)指标评价分割精度[32]。计算公式为

(9)

(10)

(11)
式中:Tp为树木正确识别的数量;
FN为树木过分割的数量;
FP为树木漏分割的数量;
Z为树木总数量。
精度分析表如表2所示。从表2可知,各样方分割准确率高于84%,过分割误差低于9%;
所有样方整体分割精度较好,精度高于86%,过分割误差和欠分割误差均低于8%。

表2 单木分割精度
2.2 树高与冠幅提取结果
分割算法正确识别马尾松57株、桉树32株,基于单木分割的基础上,采用算法提取的桉树单木树高在6~19.65 m,均值为9.42 m;
马尾松单木树高在8~15.6 m,均值为11.72 m。桉树样地树高的决定系数R2为0.92,RMSE为0.72 m;
马尾松样地树高决定系数为0.94,RMSE为0.69 m。
基于点云数据提取的桉树冠幅在1.07~5.64 m,均值为1.81 m;
马尾松冠幅在1.0~2.9 m,均值为1.82 m。桉树样地冠幅的相关系数R2为0.72,RMSE为0.56 m;马尾松样地冠幅相关数为0.78,RMSE为0.49 m。结果表明基于算法提取的冠幅具有较好的可靠性。
利用二维凸包算法分别计算桉树、马尾松样地的投影面积,渐进凸包算法分别计算桉树、马尾松的体积。桉树、马尾松样地冠幅面积、体积统计结果如表3所示。

表3 冠幅面积、体积统计结果
2.3 生物量模型拟合结果
通过比较决定系数和均方根误差得到最优的生物量模型(表4)。可见在估测森林生物量参数中,树高和冠幅对生物量模型的拟合具有重要的贡献。线性模型在未引入之冠幅、冠幅面积和体积之前,桉树R2为0.712,RMSE为22.471 kg/株;
马尾松R2为0.693,RMSE为26.570 kg/株;
引入这些参数后,R2增大,均方误差RMSE下降;
而CAR模型在引入冠幅面积及体积后模型精度明显提高,桉树R2由0.719提高到0.821,RMSE由22.215 kg/株下降到17.731 kg/株;
马尾松R2由0.715提高到0.830,RMSE由24.832 kg/株下降到19.149 kg/株。进而得到线性与改进CAR生物量最优预测模型。
线性模型桉树最优模型:W=-22.706+7.620 3H+13.013 8C+2.106 4S-4.258 1V,马尾松最优模型:W=-137.823 9+9.230 2H+14.780 5C+2.453 0S+4.550 9V。桉树最优CAR模型为W=8.538 0H1.511 2C0.797 6S0.576 7V-1.507 2,马尾松最优CAR模型为W=0.071 1H1.450 8C0.211 3S0.270 9V1.023 2。可见,除了树高,冠幅、冠幅面积及体积与生物量之间也有高度相关性。
如表4和表5所示,改进后CAR模型精度要优于线性模型,桉树和马尾松样地生物量模型MRE和NMSE分别在-2.44%~0.245%、0.080~0.109,而RMSE%在22.689%~44.787%;
以四变量构建的生物量模型,其各项评价指标最优。
2.4 适应性检验
当CAR模型引入冠幅面积、体积变量后,模型精度最优,其中桉树最佳拟合R2为0.821,RMSE为17.731 kg/株;
马尾松最佳拟合R2为0.830,RMSE为19.149 kg/株。较最优线性模型,桉树CAR最优模型R2提高了0.071,RMSE下降了3.203 kg/株,马尾松R2提高了0.090,RMSE下降了4.538 kg/株。将实测生物量与线性、CAR最优模型估测的生物量分别进行最小二乘法拟合。如图4和图5所示,在引入参数相同的情况下,CAR模型拟合结果优于线性模型,其中如图4桉树单木生物量拟合结果图所示,线性拟合结果中高大树木实测生物量值较大时,点的分布较为离散,说明高大树木生物量估测精度小于中等树木[33],而CAR模型拟合结果中高大树木的生物量估测精度要高于线性模型。表明CAR模型,引入冠幅、冠幅面积及体积后,可以很好地提高生物量估测的精度。
2.5 单木生物量误差对比
实测生物量与线性、CAR最优模型预测生物量误差如表6所示。多元线性模型桉树和马尾松单木平均误差分别为1.89、2.65 kg/株,而CAR模型桉树和马尾松单木平均误差分别为1.23、1.22 kg/株。相较于线性模型,CAR模型桉树和马尾松单木平均误差分别下降了0.66、1.43 kg/株。
基于无人机LiDAR数据和地面数据对桉树和马尾松样地进行生物量估测,利用点云数据提取树木的垂直结构参数,如树高、冠幅、冠幅面积及体积[34],构建不同树种的生物量模型,通过与国家林业局颁发的异速生长方程估算的生物量比较,即使在构建生物量模型中胸径不作为变量,也可以取得较好的拟合精度,这一结果表明无人机LiDAR在估测生物量的潜力。庞勇等[35]利用不同森林类型的机载激光雷达数据对生物量进行估测研究,结果表明森林地上生物量模型R2高于0.8,本研究与这一结果相吻合,说明了利用无人机LiDAR估测生物量的可行性。

表4 生物量模参数估计及拟合精度
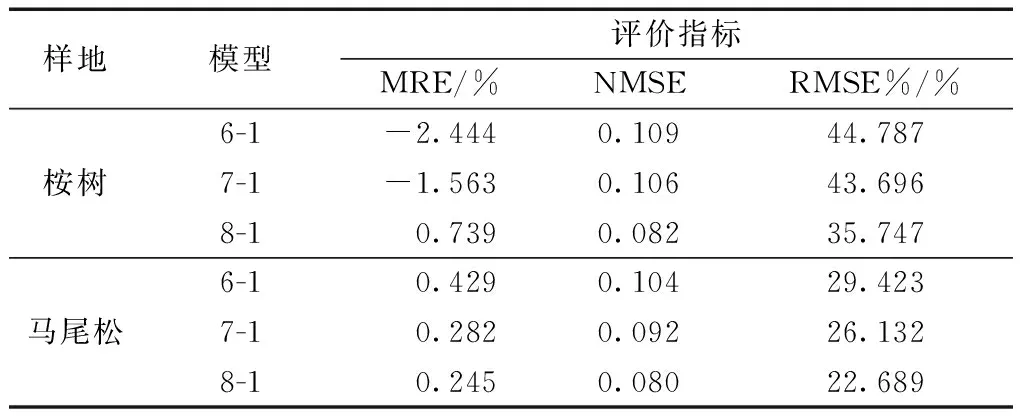
表5 CAR生物量估测模型评价指标

图4 桉树生物量拟合图Fig.4 Eucalyptus biomass fitting diagram
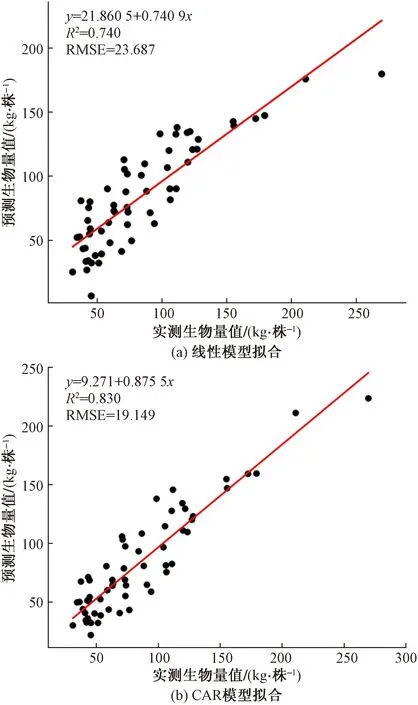
图5 马尾松生物量拟合图Fig.5 Masson pine biomass fitting diagram

表6 单木生物量误差表
无人机LiDAR在单木分割时,利用种子点迭代聚类,会出现“过分割”和“欠分割”的情况,这是因为树木间的间距过小,导致树木间冠层的重叠,难以正确地识别树木冠层的边界,使得提取的冠幅数据存在误差;
由于林分样地的高郁闭度,使得激光点难以穿透林木冠层达到地面,地面点减少对于树高的提取会有一定的影响,因此在单木提取时选择合适的算法会提高生物量估测精度。
通过对比所构建的CAR模型和多元线性模型,可发现当引入树冠因子时,CAR模型估测生物量精度明显提高,其中单木的体积对生物量模型的贡献更为显著,主要由于树冠的生物量与树冠的形状、大小及树木的长势密切相关,与冠幅面积相比体积能更好地反映树木的长势,因此与生物量较为紧密。选取桉树和马尾松样地作为研究区域,其中桉树属于阔叶林,马尾松属于针叶林。通过数据对比分析:在模型评价中,马尾松生物量模型的各项指标优于桉树生物量模型,分析原因是阔叶林冠层较大,冠幅面积、体积在单木生物量占比较多,且阔叶林树冠冠层多变,针叶林冠层结构单一,因此使得桉树单木结构提取精度的降低。
基于无人机LiDAR点云引入树冠因子作为生物量模型的变量,虽可以保证模型的精度,但还存在一定的局限性。在分割单木树冠时,会存在“过分割”或“欠分割”的错误现象,进而在一定程度上影响生物量模型的精度,因此在今后的研究中需要提高分割单木的精度。本文研究中研究区域的单木样本相对较少,在后续研究中需增加样本的数量。
基于桉树和马尾松样地的地面实测数据与无人机LiDAR点云,采用CAR模型对生物量进行估测,表明加入单木垂直结构参数可提高森林生物量模型的精度,通过比较各个模型的拟合效果,可得出以下结论。
(1)将算法提取的树高、冠幅与实测树高、冠幅进行最小二乘法拟合,结果显示提取参数与实测参数具有较好的相关性,利用点云数据提取单木结构参数是可行的。其中桉树单木树高在6~19.65 m,均值为9.42 m;
马尾松单木树高在8~15.6 m,均值为11.72 m;
桉树样地冠幅在1.07~5.64 m,均值为1.81 m;
马尾松样地冠幅在1.0~2.9 m,均值为1.82 m,这与样地实际情况相符合。
(2)当引入树冠因子时,CAR模型估测生物量精度明显提高,桉树、马尾松R2分别为0.821、0830,RMSE为17.731、19.149 kg/株。
(3)较线性最优模型,以树高、冠幅为自变量的模型,CAR模型引入冠幅面积及体积桉树、马尾松样地R2提高了0.071、0.090,RMSE下降了3.203、4.538 kg/株。因此,引入冠幅、冠幅面积及体积可以提高生物量估计的精度。
猜你喜欢 单木冠幅马尾松 马尾松种植技术与栽培管理农业灾害研究(2022年6期)2022-12-02不同施肥种类对屏边县秃杉种子园林木生长的影响安徽农业科学(2022年19期)2022-10-29地基与无人机激光雷达结合提取单木参数农业工程学报(2022年14期)2022-10-19无人机载激光雷达人工林单木分割算法研究激光与红外(2022年5期)2022-06-09峨眉含笑绿色天府(2022年2期)2022-03-16施肥对三江平原丘陵区长白落叶松人工林中龄林单木树冠圆满度影响林业科技情报(2021年3期)2021-09-01马尾松栽培技术与抚育管理措施农家科技中旬版(2020年10期)2020-07-12马尾松种植技术及在林业生产中的应用研究农家科技中旬版(2020年2期)2020-03-18马尾松栽培技术及抚育管理绿色科技(2019年5期)2019-11-29基于双尺度体元覆盖密度的TLS点云数据单木识别算法森林工程(2018年5期)2018-05-14推荐访问:生物量 估测 无人机