一种基于深度强化学习的高速列车自动停车算法
来源:优秀文章 发布时间:2023-02-02 点击:
张云霞,梁东岳,杨卫华
(1.山西省财政税务专科学校 公共课教学部,山西 太原 030024;
2.太原理工大学 数学学院,山西 晋中 030600)
列车自动驾驶(Automatic Train Operation,ATO)作为智慧轨道交通的重要组成部分得到了广泛的关注.列车自动停车(Automatic Train Parking,ATP)技术是ATO系统的关键技术之一,直接影响轨道交通的服务质量、运行效率和乘客满意度.高速列车运行通常具有行车速度高、行驶距离长、站台复用度高、所处环境复杂等的特点.列车司机在列车进站时根据驾驶经验手动调整制动手柄,改变制动级进行停车的稳定性不高[1,2].因此,开发精确的ATP算法实现高速列车自动、精准停车具有重要研究意义.
当前研究ATP的控制方法主要包括迭代学习控制、预测控制、滑模控制、遗传算法控制、基于比例积分微分(Proportion-Integration-Derivative,PID)的模糊控制、传统机器学习控制等[3-5].Hou等人[6]将终端迭代学习方法应用到列车站台停车控制中,利用先前制动过程中的终端停车位置误差来更新当前控制曲线.Wu等人[7]引入参数估计以实现对列车制动系统模型参数的在线辨识,并利用二次规划算法设计了自适应广义预测控制算法,其能较好地处理模型参数的不确定性和外部扰动.Wang等人[8]运用终端滑模控制原理设计了列车自动停车控制系统,并引入了参数自适应机制来增强控制系统的适应性.Yin等人[9]提出了一种遗传算法以求解应答器布置优化模型,并基于北京地铁亦庄线的现场数据进行了数值实验验证.
在城市轨道交通中,列车站台停车主要使用传统的PID控制器来跟踪目标曲线[10,11].Yasunobu等人[12]将模糊推理和模糊控制算法引入列车自动停车控制,该方法通过将停车阶段分为多个不同的区段以运用推理规则,并且将最终结果和传统的PID控制效果进行了比对,验证了模糊控制方法的有效性.李中奇等人[13]通过提出一种改进的模糊PID-Smith控制器,以解决动车组制动过程中电制动与空气制动切换时控制模型参数变化和空气制动延时大的问题.由于列车制动系统的控制参数变化的问题,PID的精确控制效果较差且容易造成挡位的快速切换.PID方法的挑战之一就是如何确定最佳的PID参数.现有的一般做法是基于人工经验和经过多次重复测试专业判断得出,这样做效率较低而且难以适应快速变化的高铁运行实际环境.
人工智能方法越来越多的被应用在ATP问题上.Chen等人[14]利用应答器提供精确的位置信息基于启发式、梯度下降和强化学习提出了三种在线学习控制策略.Li等人[15]通过结合强化学习(RL)理论和栏杆信息提出新的列车站台停车框架,提高了停车位的准确性、鲁棒性和自学习能力.Yin等人[16]利用随机最优选择算法、Q学习算法和基于模糊函数的Q学习算法,以减少停车城市轨道交通中的错误.同时,采用五种制动率作为三种算法的作用向量,并建立了一些统计指标来评价停车误差.Cui等人[17]提出了一种基于知识和双深度Q网络的列车自动停车控制方法(ATP Method Based on Knowledge and Double Deep Q-Network,KDDQN)以解决制动指令的时间分配问题,知识用来估计制动指令以提高深度强化学习的学习效率,而深度强化学习用于决策指令的执行时间以避免频繁的指令切换.一般的研究多针对单车单线路情况,而很少考虑实际中更加常见的多车多线路停车情况,因此使得算法的实际应用受限.
针对以上问题,本文提出了一种关于ATP问题的深度强化学习算法.建立了基于多车多线路模型的强化学习环境使得算法适用场景更加广泛;
受深度循环Q网络[18]算法以及Wide & Deep模型[19,20]的启发,设计了一种结合长短期记忆(Long Short Term Memory,LSTM)网络[21]与全连接网络(Full Connected Network,FCN)的多输入单输出神经网络结构使算法在制动过程中实时调整最优控制参数.

图1 列车停车过程速度和位置的变化
高速列车停车问题被描述为:高速列车以初始速度v0进入停车区域后,根据状态信息,例如列车的瞬时位置l和速度v,实时选择制动指令u,目标是使得列车速度均匀下降,直至指定位置时速度恰为零.如图1所示,L0和LT分别表示停车区域的起点和终点.
本文使用单质点模型来描述高速列车在轨道上的运动.该模型中不考虑车辆之间的受力,火车被视为单个质点.高速列车的运动可用以下方程式描述:
fa=f1+f2+f3
(1)
fb=d1*v2+d2*v2+d3*v2
(2)
fr=fa+fb
(3)
(1-r-)*a=f+fr
(4)
其中r-是列车回转质量系数,a是列车运行时的总加速度,是单位质量列车的制动力,fr是行驶阻力.fb是基本阻力[14],fa是附加阻力.符号d1,d2和d3是基本阻力系数,合记为向量d.符号f1,f2和f3分别代表由坡度、弯道和隧道引起的阻力.
1.1 制动模型
制动模型是ATP实现精确停车的重要依据,文献[22]对列车的制动模型做了研究.制动模型描述了从输入制动指令u开始,经系统延时到制动力输出及动车组列车制动的过程.该过程可用以下方程式描述:
(5)
(6)
(7)

1.2 性能指标
为了衡量提出算法的性能,本文主要考虑下述指标[14,22,23]:包括停车误差、舒适度和指令切换次数.
1.2.1 停车误差

ei=L-Lr
(8)
(9)
em=max|ei|
(10)
(11)
(12)
(13)
(14)
其中Lr列车的实际行驶距离,k10和k30分别表示停车误差在0.100 m和0.300 m以内的停车误差样本总数.
1.2.2 舒适度

(15)
(16)
其中Ti是第i次实验中根据最小采样间隔所记录的减速度变化次数,a(tj)是列车在tj时刻的实际加速度.
1.2.3 指令切换次数

(17)
(18)
Nm=maxNi
(19)
其中Ti表示第i次实验中根据最小采样间隔记录的指令个数.若指令uj+1=uj,则nj=0;
否则,nj=1.指令切换次数过大影响列车设备寿命,过小则难以精确控制,所以算法需要将指令切换次数控制在合理范围中.
本节首先介绍一种基于长短期记忆与全连接网络(LSTM&FCN)的神经网络结构,该神经网络结构将应用于深度强化学习以解决停车过程中的控制参数寻优问题.如图2所示,强化学习主要由环境和智能体两个相互作用的部分构成.智能体即为本文所设计的算法,包含两个模块:知识模块和多输入单输出的深度强化学习模块.知识模块用于估计列车当前状态的执行指令;
深度强化学习模块进一步决策该指令的持续执行时间.下面分别描述每个部分及模块的细节.

图2 列车自动停车方法的流程图
2.1 环境
在实际的列车制动停车过程中,同一车型的不同列车,甚至是不同车型的列车都会在多条停车区间线路上进行停车,为了环境更符合真实情况,本章将根据相关企业提供的某实际线路的运行列车以及线路坡度数据建立多车多线路模型,数据见表1.高速列车的动力学模型见第1节相关描述.关于环境主要考虑下述两种扰动:由于列车制动系统的磨损和老化所导致的制动系数扰动;
由于湿度、温度等因素变化所导致的阻力系数扰动.与环境的交互对于算法利用任务的特定特征调整动作策略至关重要[24].

表1 不同列车的制动系数和不同线路的坡度函数
2.2 智能体
2.2.1 知识模块
文献[14]应用一种启发式算法来估计列车制动过程中的减速度,这里将利用该启发式算法计算由公式(20)所定义的列车理想加速度aI.特别地,此处高速列车执行的是离散的制动指令而不是连续的制动减速度.由于瞬时速度v和指令集合={u0,u1,u2,u3,u4,u5,u6,u7}是已知的,因此可以通过公式(21)获得列车每个指令对应的估计减速度ai.根据理想减速度aI可计算理想指令uI,计算公式为(22)-(23).为了防止列车速度在停车过程的后期变化过剧,当列车速度大于参考速度vrkm/h时,算法将采取在uI的一定邻域内且能产生较大减速度的指令.在调节参考速度vr的值时应注意避免列车过早停车.从公式(20)看出当列车超过终点时,最大制动指令将被执行.知识模块用于得到列车的可执行指令.
(20)
ai=G(ui,v),i=0,1,…,7
(21)
(22)
uI=uid
(23)
其中aα(l)是由线路坡度引起的加速度.
2.2.2 多输入单输出的深度强化学习模块
在知识模块计算得到可执行的理想指令之后,深度强化学习模块将计算决策理想指令uI的持续执行时间mt.由于列车自动停车控制问题的控制参数具有时间依赖性,因此使用LSTM网络来学习时间序列信息之间的这种长期依赖.一方面,在列车制动过程中,其位置、速度等信息每时每刻都在发生变化,其蕴涵的时序性较强;
另一方面,列车制动模型的参数摄动是一个慢时变过程,一般认为其提供给算法的参考制动系数在一个回合中是不变的,因此这类信息将不考虑其中的时序性.

o=(o1,o2)
(24)
o1=(l,v,u,m)
(25)
o2=(b1,b2,b3,b4,b5,b6,b7,α)
(26)
(27)
(28)

(29)

(30)
(31)
其中:λ为学习率,γ为奖励折扣因子.
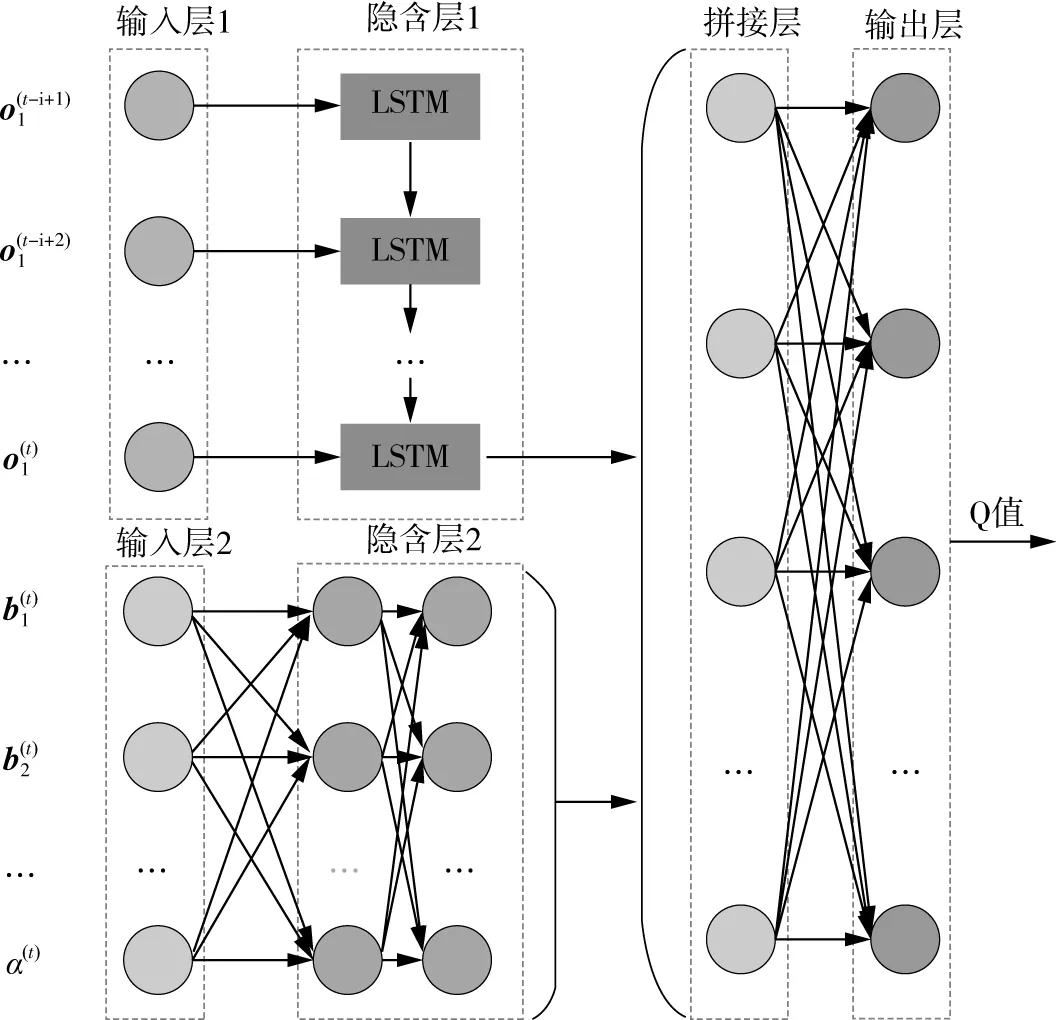
图3 LSTM&FCN神经网络结构图
为了验证算法的控制效果,以某实际线路环境,以及运营列车真实数据作为数据来源进行仿真,对比实验次数10万次.本节实验是基于Python 3.6.8实现的,并使用开源深度学习框架Tensorflow1.8.0构建上一节中设计的神经网络.
3.1 参数与扰动设定
为了模拟现实世界中列车的停车过程,学习的环境将模拟列车制动中的随机扰动.列车进入停车区域的最大初始速度需在一定范围内,否则,即使列车执行最大的制动指令,也将不会达到要求的误差范围[14].始终设定列车停车区域长度为1 km,初始速度不超过125 km/h.为使系统能够同时针对多车多线路情形进行学习,在每个训练回合中,设定环境从80 km/h到125 km/ h范围内随机生成初始速度;
列车停车区间的线路坡度参数从表1中十一个选项中随机选择一项;
列车的参考制动系数b将由表1中三个制动系数中随机选择一个.具体的列车动力学模型参数和算法所使用的超参数分别见表2和表3.

表2 列车动力学模型参数

表3 算法的超参数
环境扰动设定如下:首先,随着列车运行里程的增加,列车制动系统和物理结构将产生磨损和老化,从而导致制动系数的扰动[7].因此在每个回合开始,实际制动系数将由所选定的b值的90%至110%之间随机生成(即对实际制动加速度添加最大10%的噪声).其次,湿度、温度等因素会影响列车的实际阻力[14].因此在每个回合中,基本阻力系数的随机实例将从给定d值的80%至120%生成(即对实际阻力加速度添加最大20%的噪声).制动系数和基本阻力系数的变化是一个慢时变过程.因此,变化的系数在一个回合中可以视为未知的固定值.
3.2 实验结果与分析
数值实验主要对比基于LSTM&FCN和基于KDDQN的ATP方法.为公平起见,在KDDQN方法中将图3中的输入合并为一维向量作为其状态特征.两种方法的超参数设定一致.图4展示了KDDQN方法(a)和LSTM&FCN方法(b)在1 000个回合的训练过程中停车误差的收敛变化.每个点代表一个回合的停车误差.回归曲线使用了二阶多项式来拟合学习过程中产生的停车误差样本点.如图4所示,两种算法的收敛速度基本相同.停车误差趋于稳定后,两种算法的收敛范围亦基本相同.

图4 两种算法停车误差收敛对比
表4列举了LSTM&FCN方法的主要自动停车性能指标.从表中数值可以看出,LSTM&FCN方法的P30指标可达到100%,P10指标也达到99%以上,说明LSTM&FCN方法在扰动情况下,在10万次的停车误差测试实验中没有停车误差超出0.300 m以上的样本,而且停车误差超过0.100 m的样本数量不超过1%.停车误差最大值em为0.226 m,略高于KDDQN方法的最大停车误差,两种方法均满足最大误差不超过0.300 m的要求.从表4中可以看出,使用LSTM&FCN方法时的动作指令平均切换次数为12,而KDDQN方法的动作指令平均切换次数为13,说明在单位时间内LSTM&FCN方法的动作指令切换频率较低,更有利于保持制动设备健康,延长其寿命.使用LSTM&FCN方法时的平均舒适度指标为0.018 m/s3,而KDDQN方法的平均舒适度为0.020 m/s3,根据平均舒适度指标的定义说明LSTM&FCN方法的列车加速度变化更小,列车制动过程更加平稳,旅客体验更好.

表4 两种算法的性能指标结果
综上,对比于KDDQN方法,LSTM&FCN方法在保证必要停车精度的同时,能够更进一步降低动作指令切换频率,从而提升列车设备健康水平和旅客舒适程度.另外,在多车多线路模型下本文算法通过引入额外的环境特征使得训练好的停车控制参数能够应用于多种车型以及线路环境,在提高运行效率的同时能够有效降低算法训练成本,是一种符合实际需求的高效率学习算法.
本文分析了高速列车站台停车的过程,建立了单质点动力学模型.利用运营列车和线路的真实数据建立了基于多车多线路模型的强化学习环境,使得算法适用场景更加广泛,有效降低算法训练成本.
提出一种结合LSTM网络与全连接网络的多输入单输出神经网络结构用来寻找制动过程中的最优控制参数.并提出一种基于深度强化学习的高速列车站台停车制动控制算法.仿真结果表明,本文算法得到的平均舒适度为0.018 m/s3,指令切换次数平均值为12,算法绝对停车误差最大值为0.226 m,满足误差小于0.300 m的要求.
应用LSTM&FCN的深度强化学习方法与已有方法相比较在指令切换频度与舒适度方面有提升,但是在停车精度方面未体现出明显提升.后续将尝试如构造新型神经网络结构等手段,以提升算法性能.
猜你喜欢 指令列车系数 基于符号相干系数自适应加权的全聚焦成像中国特种设备安全(2022年5期)2022-08-26登上末日列车小哥白尼(趣味科学)(2021年4期)2021-07-28关爱向列车下延伸云南画报(2021年4期)2021-07-22《单一形状固定循环指令G90车外圆仿真》教案设计学校教育研究(2020年11期)2020-06-08简析80C51单片机的数据传送类指令通信电源技术(2020年9期)2020-01-08穿越时空的列车小学生学习指导(低年级)(2019年6期)2019-07-22苹果屋娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01嬉水娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01中断与跳转操作对指令串的影响科技传播(2015年20期)2015-03-25西去的列车中国火炬(2014年11期)2014-07-25推荐访问:算法 列车 停车