基于预训练模型的军事领域命名实体识别研究
来源:优秀文章 发布时间:2023-01-24 点击:
童昭,王露笛,朱小杰,杜一
中国科学院计算机网络信息中心,北京 100083
近年来,随着计算机技术的不断发展,以神经网络为代表的人工智能算法为部队信息化与智能化建设提供了一种有效的手段。知识图谱[1]作为描述真实世界中实体和概念以及他们之间关系的一种工具,能够将复杂、海量的数据整合在一起,利用图谱中的关系和节点描述语义关联信息。知识图谱中的实体是知识库中的基本单位,同时也是构建图谱的核心要素,通过命名实体识别任务中包含的实体,为知识图谱构建提供知识支撑。为了从海量的信息中抽取有价值的数据,发掘隐藏的应用价值,通常需要用到自然语言处理(Natural Language Processing,NLP)技术,而NLP 中应用最广泛的就是命名实体识别(Named Entity Recognition,NER)技术。命名实体识别是指从非结构的文本数据集中抽取出结构化的信息,并分类到预先定义的,如人名、地名、组织机构名等特定类别中。传统的命名实体识别任务主要分为三大类(实体类、时间类和数字类),或者更具体的七小类(人名、地名、机构名、地点、时间、日期、货币和百分比)[2]。命名实体识别是实现信息抽取、搜索推荐等自然语言处理中的基础任务,命名实体的准确识别可以促进智能问答、知识图谱构建等下游任务的研究。本文的研究目标是以自建的军事语料作为数据支撑,以准确高效地识别军事命名实体为目标,利用深度学习的算法作为技术手段,为后续战场信息情报获取、知识图谱构建等提供支持,进一步加速军事作战指挥的智能化转型。
军事命名实体识别涉及的实体范畴远远不止传统命名实体识别的三大类和七小类,由于军事命名实体的构成有其自己独特的命名法则和规律,对于这类实体的识别需要同时兼顾语言的规律性和军事特征,因此本文的研究重点是识别带有军事领域特色的实体。相较于开放式传统三大类和七小类的实体识别,需要构建模型识别特定的军事领域实体。本文将识别的实体分为五类:组织机构、型号、行为、起飞地、目的地。军事实体识别的任务可以描述为:首先,将军事文本语料进行预处理;
然后,从中提取句子特征;
最后,将特征输入到实体识别模型中,从而识别出具有特定意义的军事实体。
通过调研已有文献,军事领域的实体识别的通常做法是借鉴通用领域的主流方法和思想,再根据军事语料中识别实体的特点进行一些适应性的改进。根据选取主流方法的不同,可以分为:基于模板规则匹配的方法[2]、基于传统机器学习的方法[3]和基于深度学习的方法[4]。近年来,鉴于深度学习强大的学习能力和表达能力,越来越多的研究者开始开展基于深度神经网络的研究,通用做法之一是将神经网络模型与CRF 结合。由于NER 任务在自然语言处理中属于序列标注模型,所以通常使用BiLSTM[5]作为序列标注模型的特征提取网络。在处理中文文本时,为了避免分词造成的语义歧义,常采用以字符向量作为输入序列。对军事领域的命名实体识别的优化通常是在特征处理阶段,例如加入字或者词的相关特征即可对识别效果有较大的提升[6]。而对于神经网络模型的优化,文献[7]提出一种层叠式的识别方法:该方法首先结合军事目标及属性特点,采用树结构定义层级式目标及属性实体、活动要素及属性实体,细化实体类别粒度,依据层级式特点对语料进行标注,然后采用标签约束转移矩阵优化后的BiLSTM-CRF 模型进行实体识别,实现细粒度更高的实体与关联属性识别。除此之外,有研究把长短期记忆网络模型(Long Short Term Memory,LSTM)结构替换为更容易训练的门循环控制模型(Gate Recurrent Unit,GRU)结构[8],同时研究人员加入注意力机制[9],在一定程度上提升了神经网络模型的识别性能。
本文针对中文命名实体识别准确率低的问题,提出一种BERT-BiLSTM-CRF 的模型。首先,本文未使用传统的Word2vec 算法生成词向量的表示,而使用表达能力更强的BERT 模型生成词向量的特征表示,将其得到的表示序列输入BiLSTM 网络,获得上下文的全局特征表示,最终经过CRF 模块进行最优标签序列的提取。本文在自建的开源军事语料数据集进行实验,验证本文提出的方法的有效性,同时加入多种baseline 实验进行对比分析,结果表明,在命名实体识别任务中,本文提出的BERT 模型方法在一定程度上解决了边界划分问题,同时解决了在数据集不足的情况下实体识别任务表现不佳的问题。
1.1 实体分类
由于军事语料不同于传统通用的命名实体识别,所以首先需要建立军事领域内的命名实体的分类体系。结合开源语料数据情况并加入专家经验与知识,本文将识别的目标实体分为五类:国家、型号、行为、起飞地、目的地。针对军事业务实际需求,在对通用性与军事领域数据的特点深入分析的基础上,建立了能够准确、全面描述各类型军事知识的实体表征模型,可对复杂多样、动态演化、时空性强的军事知识要素进行表征。五类军事领域目标实体具体的类型名称、代号和示例如表1所示。

表1 目标实体分类Table 1 Target Entity Classification
五类实体中,组织机构指的是不同国家的军种简称,如美空军、美海军;
型号指的是采取行为的主体作战型号,如KC-135R 加油机;
行为是指在每一条非结构化的军事语料中的主体所采取的行动,如返回基地;
起飞地是指主体起飞地点,如南海;
目的地是指主体最终所要抵达的终点,如冲绳嘉手纳基地。
1.2 模型架构
本研究中模型构建的思路是使用预训练语言模型获取中文单字的字向量,利用字向量中的语言规律和语义知识辅助军事实体的识别,以提升实体识别的性能。同时融合字的含边界词性特征,进一步优化神经网络模型的输入。
本文结合BERT 预训练模型[10]的上下文深层语义编码、BiLSTM 神经网络的序列解码和CRF 的序列标注,构建BERT-BiLSTM-CRF 实体识别框架,整体框架结构如图1所示,该框架以文本中的字序列、语义块、字位置及其词性序列为输入,输出为每一个字对应的目标类型的标签序列。下文依次对模型的各个模块进行详细分析。
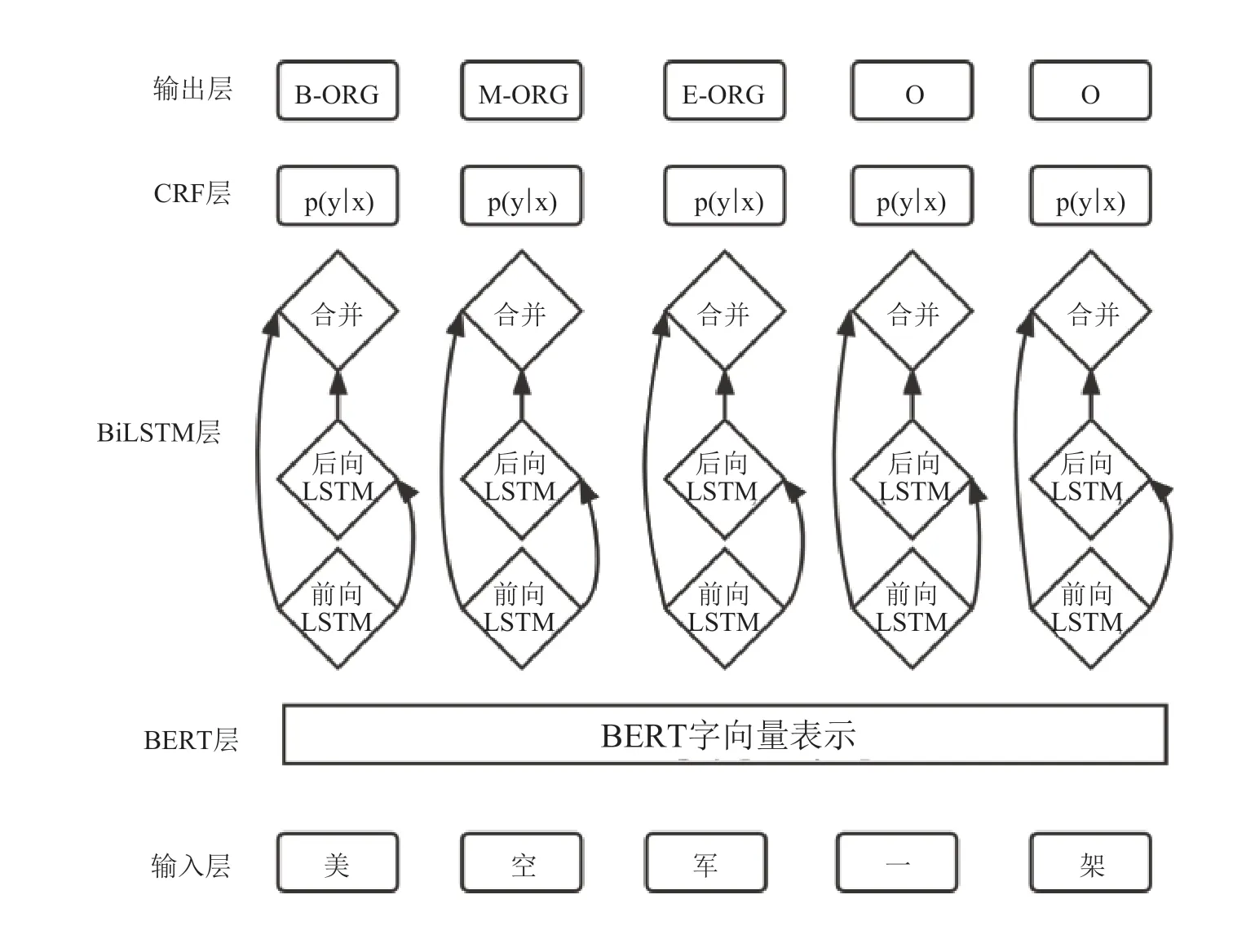
图1 模型架构图Fig.1 Model architecture
1.2.1 BERT 层
传统使用Word2vec 的方式去训练词向量,虽然训练得到的向量可以表示词语之间的关系,但这种方式的一个缺点是词和词之间的表示是一一对应的静态关系,无法根据上下文的语境对输入序列进行动态的表示,也正因为此,使用Word2vec 得到的词向量会对NER 效果产生重要影响。
BERT 模型作为深度双向语言表征模型,被视为一种替代静态词向量表示的方案,它通过利用维基百科等大规模的语料数据进行自监督学习的训练,使用一种称为双向的Transformer 编码结构,使得模型能够获取输入文本中的语义信息,接下来对BERT模型做详细研究分析。
1.2.1.1 输入和输出层
根据下游任务的不同,BERT 模型的输入序列可以单句形式出现,也可以语句对的形式成对出现。在本文中,BERT 的输入为具有连续语义的自然文本。在BERT 中首先会对输入文本进行预处理,在文本开头和句子之间分别插入[CLS]和[SEP]符号。其次,对于最终的向量表示,BERT 使用字符的嵌入向量、分割向量和位置向量叠加得到,其中字符的嵌入向量是输入序列中每个字符本身的向量表示;
分割向量用于区分每一个字符属于句子A 还是句子B。如果输入序列只有一个句子,就只是用EA 表示;
位置向量编码了输入中每个字符出现的位置。这些向量均在训练过程中通过学习得到。对于BERT 模型的输出同样也有两种形式,一种是字符级别的向量表示,对应着输入中的每个字符;
另一种输出形式是句子级别的语义向量,即整个句子的语义表示。在本文的研究中,BERT 模型的输出采用了第一种形式,即输入序列的每个字符都有对应的向量表示,该输出接着作为输入传递给后序模块进行进一步的处理。
1.2.1.2 Transformer 编码层
在BERT 模型中使用了多层双向的Transformer编码器对输入的序列数据进行编码,其模型结构图如图2 所示:其中每个Trm对应一个单元的编码器,E1,E2,...,En是模型的输入,为字符向量,T1,T2,..,Tn为模型的输出向量。
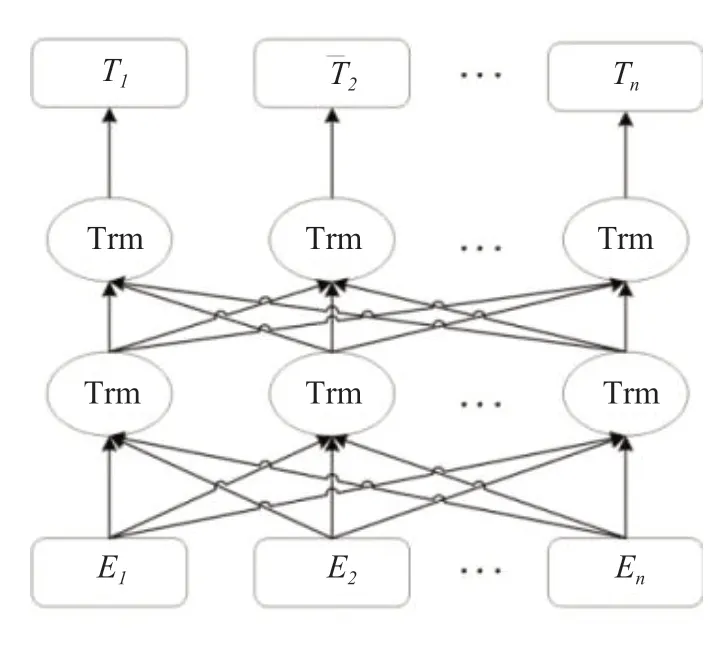
图2 BERT 预训练语言模型Fig.2 BERT Pre-trained language model
从结构来说,BERT 是将多个Transformer 编码器堆叠进行特征提取,而Transformer 编码器是由Self-Attention 层和前向神经网络组成。Self-Attention的核心计算公式如下所示:
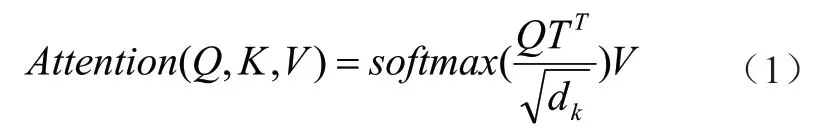
公式中Q,K,V是由矩阵Wq,WK,WV相乘可得,而Wq,WK,WV为可学习的模型训练参数。举例来说,当计算某个词语对其他词语的重要度时,让当前单词的Q向量与其余单词的K向量进行点积数学运算。对点积计算的结果使用这样做的目的是减少语句长短对语句重要度的影响,同时也为了让训练时梯度更加稳定。随后将计算得到的结果分值经过softmax层得到一维的概率向量。使用Soft-Attention机制的意义是不仅可以完成对上下文的重要度进行编码,同时解决了传统循环神经网络长依赖的问题,加速了模型的计算能力。
基于上述的分析,我们可以总结出BERT 模型具有以下优点:
(1)BERT 在进行词向量表示的过程中充分结合编码词的上下文,克服了目前大多数词向量生成机制的单向性问题。
(2)使用基于Transformer 作为特征提取器,底层使用Attention 机制编码,增强了模型的并行计算能力,缩短了训练时间。
1.2.2 BiLSTM 层
BiLSTM 层是由一个前向LSTM 网络和后向LSTM 组成,相比于LSTM,BiLSTM 可以分别获得两个方向的上下文特征。在得到BERT 层的输出后,BiLSTM 层会将句子的字向量序列作为各个时间的输入,通过反向传播算法,模型自动提取句子中的语义特征,学习符合上下文语境语义信息,softmax函数给出当前单词对预设标签的标签概率。基于BiLSTM 的上下文特征抽取模型的结构如图3 所示。
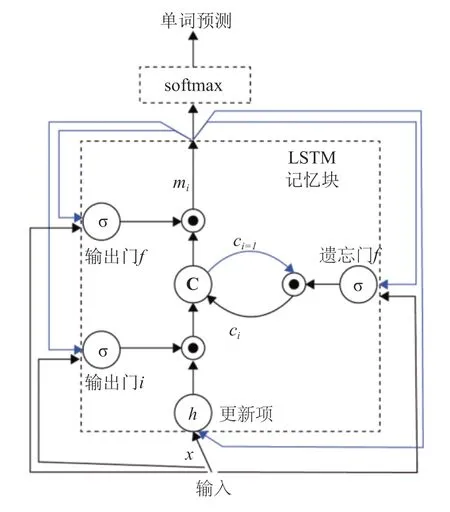
图3 BiLSTM 模型架构图Fig.3 BiLSTM architecture
LSTM 层的主要结构可以表示公式:
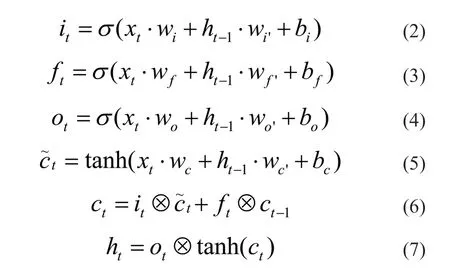
其中,σ 是sigmod函数,i、f、o和c分别表示输入门、遗忘门、输出门和记忆单元;
⊗是点积运算,W和B代表输入门、遗忘门和输出门的权重矩阵和偏置向量;
Xt指的是t时刻的输入,同时是对于表示层的输出。
1.2.3 CRF 层
在神经网络的输出层,一般是用softmax函数,而对NER 这种序列任务建模时,CRF 层的作用是对BiLSTM 网络的输出进行编码和规约,得到具有最大概率的合理预测序列。CRF 使用的是条件随机场,是一种根据输入序列预测输出序列的判别式模型。给定输入X,输出预测结果y的计算公式如下所示:
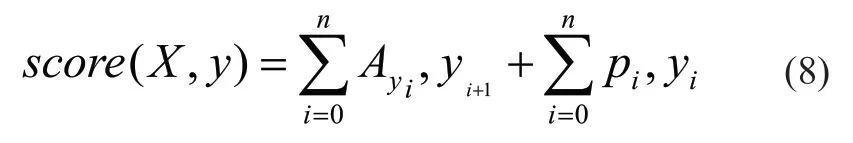
其中,Ayi, yi+1表示从标签yi转移到yi+1的概率值,yi为y中的元素。pi,y表示第i个词语标记为yi的概率值。在给定输入X情况下,输出预测结果y的概率公式为:
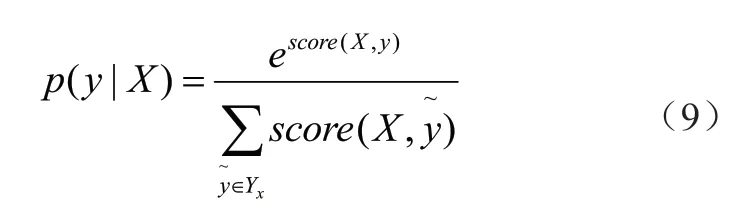
其中,x表示能够组成的所有标签,y表示真实标签。模型的目标是最大化p(y|X),在训练时通过求解似然函数如下:

在训练时,根据公式最大化得分结果:
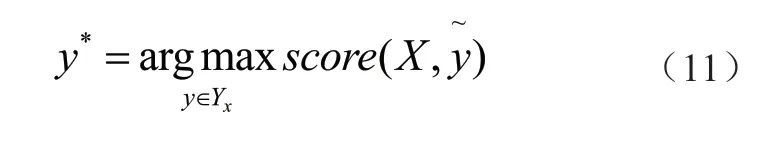
2.1 实验数据
针对军事领域的命名实体识别问题,本文提出了一种基于预训练模型BERT 的军事领域命名实体识别方法。本文针对军事领域中的军事情报数据,以开源数据作为训练语料。对组织机构、型号、行为、起飞地、目的地等五类目标进行识别,验证本文所提出模型的正确性与有效性。
目前由于军事语料领域的特殊性,并未有开源的军事语料以供训练。同时在军事语料领域缺乏统一的标注方法,本文利用网络爬虫技术构建训练数据集,采用开源的工具Doccano[18]和专家知识进行数据预处理与标注,构建中文军事领域开源情报训练数据集。
本实验利用爬虫工具从公开权威的军事网站上搜集得到开源军事新闻语料,来源包括国防科技信息网、网易军事、环球网军事、新浪军事等。从新闻网页上采集语料时以“军情动态”、“军事速递”为主题词,在爬取数据完成后,首先,对文本数据中不符合主题的“脏数据”进行数据预处理的操作,以文本的形式保留在本地磁盘。然后,按照统一的数据规范进行“数据治理”,具体做法是通过正则表达式将爬虫获取后与网页相关的符号、标记等删除,语料爬取完成后,需要对良莠不齐的文本进行分辨,筛选不符合主题的文本将其去除,选取其中高质量、相关度较高的文本,以纯文本的格式保存至本地,按照统一的规范进行预处理,通过代码编写正则表达式将文本内容中无用的网页符号、网页标签和特殊字符剔除掉,将繁体字转换为正常的简体中文字符,以及统一全半角字符,将文本按句进行拆分,每一行代表一句,同时要求长度不得超过LSTM 设置的最大长度。
由于军事领域的命名实体标注尚未确定统一的标准,故本文实验对已构建的小量的数据集采取人工标注并校正的方法。数据的标注采用BMEO 四段标记法:对于每个实体,将其第一个字标记为“B-实体类型”,非首位字符标记为“M-实体类型”,结尾的标记为“I-实体类型”,对于无关字一律标记为O。本文实验需要识别的军事实体共包括5种类型,数据经过BMIO 标注处理后共分15 类,如表2 所示:(B-ORG,M-ORG,E-ORG,B-VER,M-VER,E-VER,B-ACT,M-ACT,E-ACT,B-TAF,M-TAF,E-TAF,B-DES,M-DES,E-DES,O,
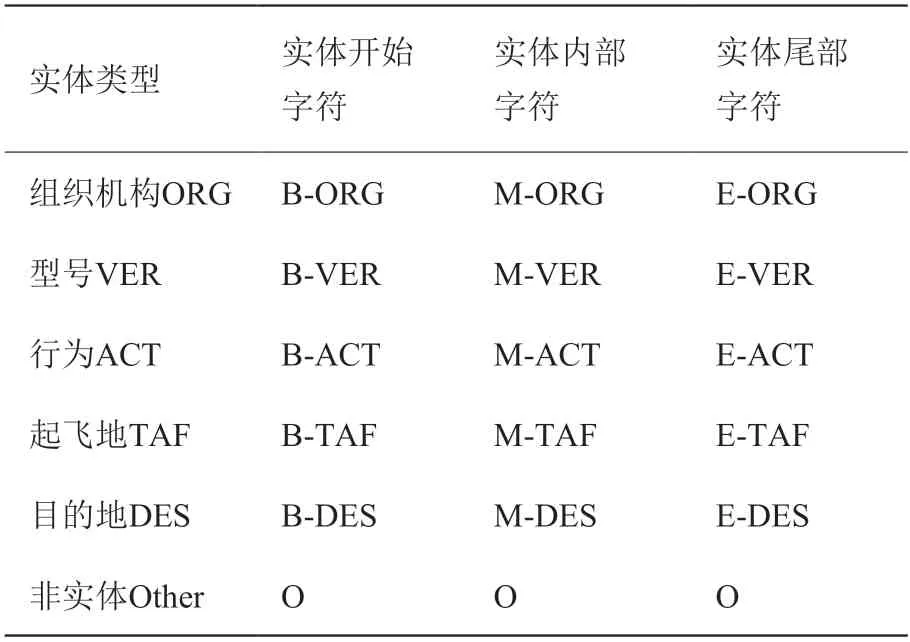
表2 目标实体分类Table 2 Target entity Classification
2.2 结果评价指标
实验采用自然语言处理领域3个通用的评测指标,准确率P、召回率R 和F1 值(F-score),其中F1 值可以体现整体的测试结果,计算公式如下:

最终采用以上3种性能评测指标的加权平均值作为实验的性能评测指标。
2.3 实验设置
本文基于BERT-BiLSTM-CRF 的实体识别模型是使用BERT 进行语料字符级别特征向量的获取,使用BiLSTM 针对字向量进行上下文的特征提取,借文本中长依赖的问题,最后使用CRF 层进行输出标签的规约限制,最终获得全局的最优标签序列。基于BERT-BiLSTM-CRF 的参数设置如表3 所示。
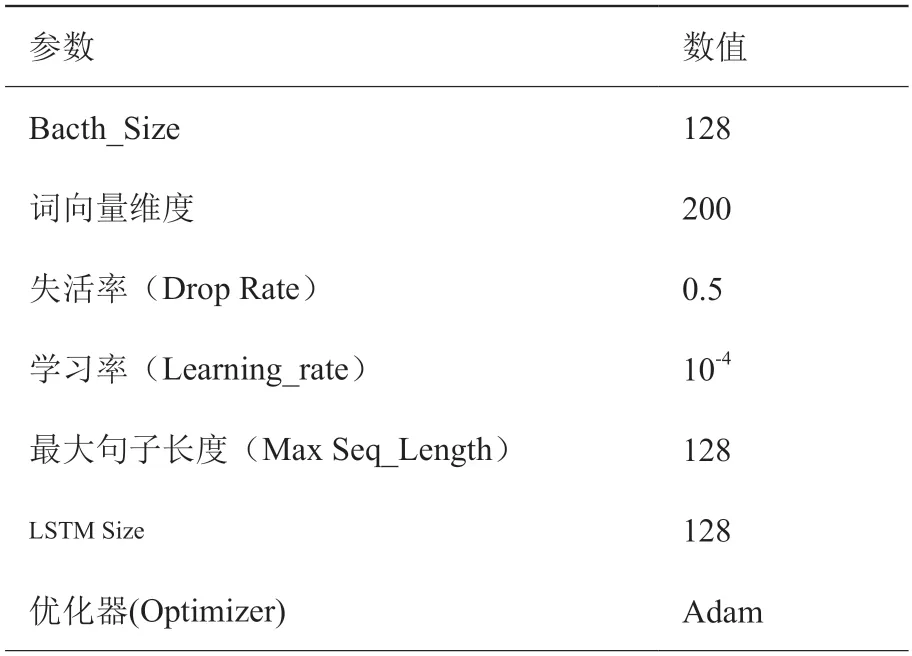
表3 参数配置表Table 3 Parameter Configuration
2.4 实验结果和分析
为验证模型在军事语料领域识别的正确性与有效性,在实验阶段设计了对比实验,在相同数据集上针对不同的模型选取合适的模型超参数进行微调。选取的对比模型有:
CRF:本文以文献[17]提出的基于CRF 的面向军事文本的命名实体识别模型作为基线对比实验,建立融合词特征、词性特征、英文字母和短横线以及数字的组合特征、左右边界词特性和中心词特性的多种特征模板,使用公开的CRF++0.58 训练工具进行模型的训练和效果预测。
HMM:本文以文献[11]提出的基于HMM 作为军事命名实体识别的对比实验,构建状态集合、观测集合以及状态转移矩阵,并使用开源的Scikit-Learn 开源的机器学习框架构建。
BiLSTM:BiLSTM[12]的网络模型是使用双向的LSTM 网络构建特征提取器,并使用开源的Scikit-Learn[13]开源的机器学习框架构建。
BiLSTM-CRF:本文以文献[14]提出的基于BiLSTM-CRF 网络模型的结构作为对比实验。采用Google 开源的词向量工具Word2vec[15]方法训练的字符界别的特征向量,通过在字嵌入层上进行Dropout处理来防止训练模型过拟合,并将该字向量的结果作为BiLSTM 网络模型的输入,得到基于上下文的特征矩阵,最后将特征矩阵交由CRF 模块进行编码与规约,最终得到基于全局的最优标签序列。
2.4.1 对比实验结果分析
从实验结果,如表4 和图4 可以得到,本文提出的基于BERT-BiLSTM-CRF 网络结构的军事命名实体识别模型优于其他4 种实体识别模型。相较于HMM 和CRF 模型,BiLSTM 模型可以学到更多的语义特征信息。本文提出的模型相较与CRF 模型在F 值上提高11.04%,召回率提高10.85%,精准率提高8.32%。相较于不使用BERT的BiLSTM-CRF模型,本文提出的模型在F 值上提高了1.87%,召回率提高了1.71%,精准率提高了2.64%。实验表明,实体识别任务中经常会出现标签之间结果不成立的现象,而CRF 中的转移矩阵能很好地解决标签之间的顺序问题。除此之外,BiLSTM-CRF 比CRF 具有更加优异的性能表现,这是因为BiLSTM 考虑了输入信息之间的双向语义依赖,可以从前后两个方向来捕捉输入信息的特征,对于实体识别这种序列标注问题具有更高的适用性,而结合字级别的特征向量仅考虑字的特征而忽略了结合上下文进行实体识别的不足,本文模型结合了字特征、句子特征、位置特征生成字向量,并使用Transformer[16]训练字向量,充分考虑上下文信息对实体的影响,实验取得了更优的实体识别效果。
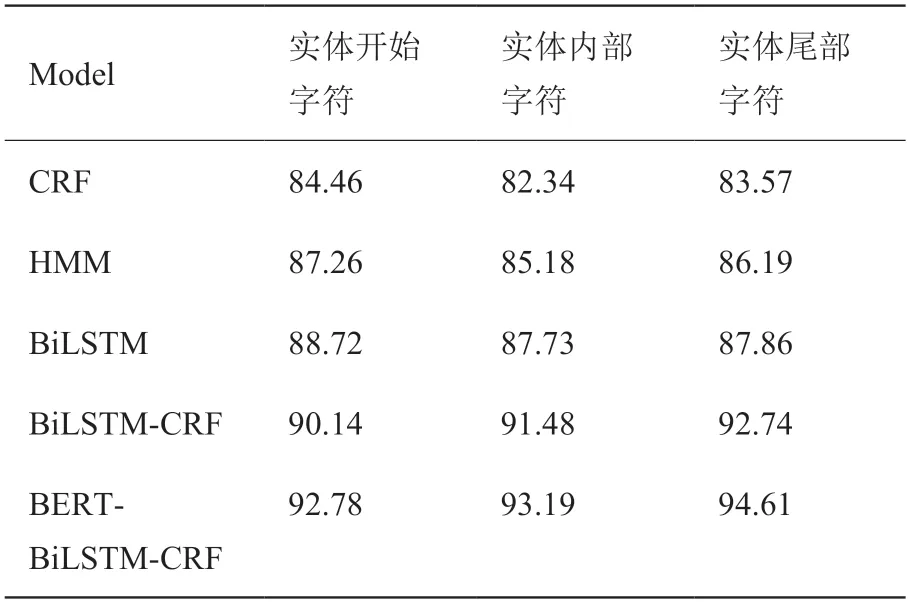
表4 实验结果表Table 4 Experiment Result
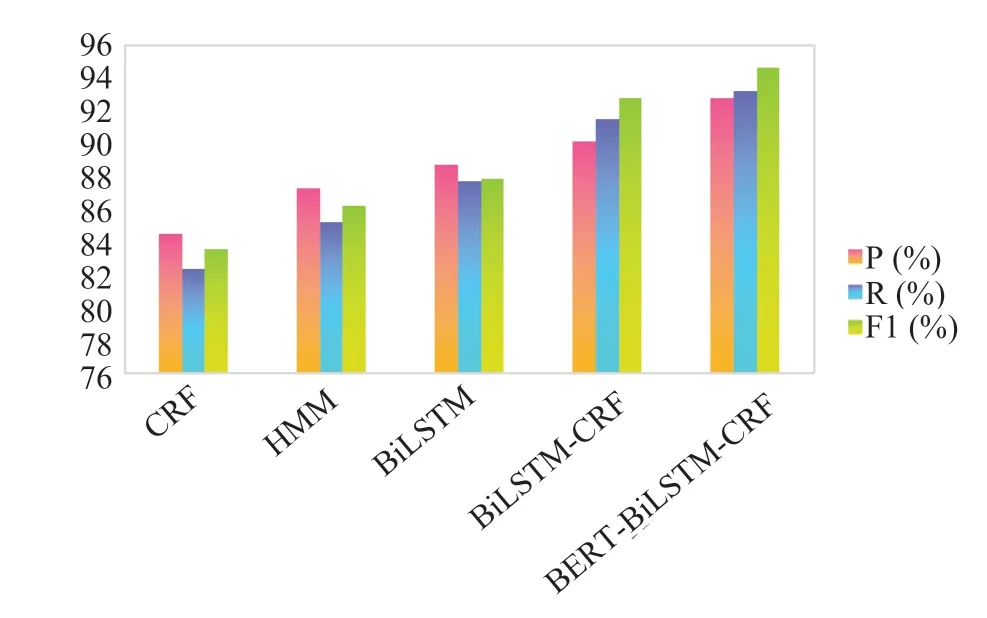
图4 实验结果柱状图Fig.4 Experimental result graph
本文以军事领域目标实体为识别对象,预先设定国家、型号、行为、起飞地、目的地等五类需要预测的目标标签,提出一种将预训练语言模型BERT和BiLSTM-CRF 模型相结合应用于军事语料的命名实体识别的模型。BERT 模型利用大规模的语料进行,不同于传统的静态语言模型,BERT 模型可以根据实际的业务场景以及上下文生成动态的中文词向量,然后与经典的BiLSTM-CRF 神经网络模型进行堆叠,生成对预先定义的五类实体的预测识别。由于本文使用的是在维基百科和书籍语料库中进行预训练的BERT 的双向结构和动态向量表征,能有效地学习更丰富和准确的语义信息,无需人工定义的特征,因此可以提升识别模型的上下文双向特征抽取能力,在相对较少的标注语料成本上也能获得效果的提升。将人工收集的军事演习领域小型语料库经过预处理作为本次实验的训练数据和测试数据,通过实验证明了该方法取得了比其他几种通用方法更好的效果,在一定程度上解决了命名实体的边界划分问题以及实体识别任务在数据集不足的情况下表现不佳的问题。未来,会考虑使用在军事领域的语料预训练的BERT 模型,进一步优化任务表现,提高在军事命名实体识别领域的性能。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢 语料命名向量 向量的分解新高考·高一数学(2022年3期)2022-04-28面向低资源神经机器翻译的回译方法厦门大学学报(自然科学版)(2021年4期)2021-06-22命名——助力有机化学的学习中学生数理化(高中版.高考理化)(2021年2期)2021-03-19聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19濒危语言与汉语平行语料库动态构建技术研究计算机应用与软件(2018年9期)2018-09-26有一种男人以“暖”命名东方女性(2018年3期)2018-04-16为一条河命名——在白河源散文诗(2017年17期)2018-01-31向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23国内外语用学实证研究比较:语料类型与收集方法外语教学理论与实践(2014年2期)2014-06-21推荐访问:实体 命名 识别