面向CNN,加速器的一种建模与优化设计方法研究①
来源:优秀文章 发布时间:2023-01-23 点击:
祁玉琼 张明喆 吴海彬 叶笑春③
(*中国科学院计算技术研究所计算机体系结构国家重点实验室 北京100190)
(**中国科学院大学 北京100049)
目前已有多种用于解决各类识别与分类相关问题的卷积神经网络(convolutional neural network,CNN)被提出,例如AlexNet[1]、VGG[2]及ResNet[3]等。同时,针对一些特定领域也演化出了很多CNN相关的神经网络。例如用于生成图像数据集、实现文字到图像转换的生成式对抗网络(generative adversarial network,GAN),用于物体识别、人脸识别的深度迁移学习算法(transfer learning),用于自动驾驶和安防监控的目标检测算法(YOLO 等)以及用于机器人、游戏自动化的强化学习算法(DQN 等)。因此可以看到,由于CNN 可以有效地处理各类复杂问题,其在现实生活中被各行各业所广泛使用。
为了能够有效地处理各种基于CNN 的算法,越来越多的CNN 加速器被提出,例如Eyeriss[4]、DaDianNao[5]、ShiDianNao[6]等。大部分CNN 加速器的存储结构分为3 层,即片外存储(DRAM)、片上存储(SRAM)以及计算单元(processing element,PE)中的寄存器(Register),且不同加速器中相同存储结构的大小、容量都各不相同。此外不同加速器的PE阵列(PE array)大小和对应的计算能力也均不同。由此可见CNN 加速器的设计包括很多方面,是一个相对复杂的工作。
当CNN 加速器设计完成后,硬件工程师需要使用硬件描述语言(Verilog 或VHDL)对其进行基于寄存器传输级的抽象和实现。这一步的工程量巨大,需要耗费大量的时间以及人力。此后通过仿真工具和逻辑综合器对寄存器传输级的设计进行仿真和综合,可以得到该加速器的性能、能耗以及面积的评估。
不同应用场景对性能以及能耗的要求都不同,例如数据中心主要用于处理大量后端应用,因此其更关心处理器的性能功耗比[7];边缘物端如IoT,则对处理器功耗的要求更为严格[8];而在高实时性要求的智能驾驶场景下,处理器的性能则是重点关注指标。因此针对特定领域,若设计出的加速器其仿真综合后得到的性能和能耗指标不符合应用需要,硬件工程师则需要重新设计CNN 加速器的结构,再用硬件描述语言修改相应的寄存器传输级设计。
加速器的执行时间或能耗可以通过多种策略进行优化。若选择增加静态随机存储器(static random access memory,SRAM)的带宽来减少能耗,则不仅要修改SRAM 的结构,同时还需要增加PE 阵列中的寄存器大小。若选择增加PE 阵列大小来减少执行时间,则需要修改片上NoC 以及SRAM 的带宽。所以当CNN 加速器某个结构设计发生改变后,加速器中其他部分的结构设计也会有相应的改变。因此,为了符合应用的性能与能耗需求,在探索CNN加速器结构设计方案时,每一次方案的调整都会造成硬件工程师大量修改多个部件、不同部件间连线以及相关信号的寄存器传输级实现。
为了能够尽可能地减少或避免上述调整与修改,本文提出了一种CNN 加速器性能与能耗通用评估模型(general performance and energy consumption model for CNN accelerator,CNNGModel)。CNNGModel 通过CNN 加速器中不同结构的具体设计,可以估计该加速器处理不同任务时所需的时间与能耗。从而在硬件工程师使用硬件描述语言实现该加速器前,提前判断当前CNN 加速器的设计是否符合应用需求,减少后续不必要的时间与人力的浪费。最后依据CNNGModel,本文还给出了CNN 加速器优化策略,以此帮助硬件架构师对加速器架构的调整。
本文的主要贡献包括以下5 个方面。
(1)基于CNN 加速器的通用硬件结构,提出加速器中数据传播路径的概念。
(2)提出了CNN 加速器性能与能耗通用评估模型(CNNGModel),并实现了其中的核心部分——通用模型库,同时规定了模型的输入与多层输出。
(3)定义了CNN 加速器中的3 种数据传播方式,用于CNNGModel 的输入。
(4)实验部分首先设计实现了3 个CNN 加速器,其次分析对比了通过CNNGModel、模拟器VTA以及仿真综合3 种方式得到的每个加速器在处理不同CNN 时的多项结果。
(5)依据CNNGModel,给出了对于CNN 加速器优化的多项策略。
本节首先介绍目前被广泛关注的一些CNN 加速器,其次给出目前已有的CNN 加速器性能评估模型,并对这些模型进行分析与总结。
DaDianNao[5]主要用于处理大型的CNN,具有伸缩性。当单层CNN 的参数量超过DaDianNao 单片存储极限时,DaDianNao 通过其伸缩性,可以将单层CNN 划分到多个芯片上执行。ShiDianNao[6]则更倾向于物端场景,它直接与视频图像传感器相连接,直接以传感器采集到的数据作为加速器的输入。因此ShiDianNao 中输入访存的数据量更少,片上配置的SRAM 更加精巧,常被用来处理较小规模的CNN 传输。Eyeriss[4]则是一个高能效、可重配的神经网络加速器。其核心设计是RowStationary 数据流,可以有效减少数据搬运带来的大量时间和能耗。Origami[9]利用其提出的一种新型卷积网络架构,使加速器的性能达到TOP/s 量级的同时,保持较高的面积和能耗效率。NeuFlow[10]是一种运行时可重配置的数据流结构,一般用于嵌入式系统,可以处理人脸识别、场景分割等。
当使用分块技术和量化技术对CNN 加速器进行优化时,可以对加速器的性能进行模拟,同时只针对低位宽的CNN 加速器[11]。SCALE-Sim[12]是对基于Systolic 架构的CNN 加速器进行建模。其中规定,在PE 阵列中数据只能在同一行或同一列中传播。因此对于一些基于RowStationary 等数据流的加速器(这些加速器中的数据需要在不同行(列)间传播),SCALE-Sim 无法对其性能进行建模。文献[4]主要估计了CNN 加速器内的传输能耗。首先该工作面向的是不同数据流,而不是不同的加速器。其次在进行能耗估计前,需要提前假设CNN 中3 种类型数据在加速器中的传输路径。文献[13]提出了一种针对CNN 加速器中数据划分和调度的分析模型,因此并不能用来估计所有CNN 加速器的性能、能耗等。本文提出的CNNGModel 是依据不同加速器处理CNN 的真实过程设计的,主要考虑了以下3点:(1)CNN 3 种类型数据在加速器中的传输路径;(2)路径中上下层存储的大小;(3)加速器对于某一路径的数据处理模式。因为CNNGModel 可以给出不同加速器在处理不同CNN 时消耗的时间与能耗,所以可用于每个真实的CNN 加速器。
本节首先对CNN 卷积神经网络进行介绍,其次给出CNN 加速器的通用硬件结构,最后介绍CNN加速器中的数据传播路径。
2.1 CNN 网络参数
CNN 网络主要由卷积层(CONV)、池化层(POOL)以及全连接层(FC)构成。这些层均包含2种数据类型,即输入特征图(input feature map,ifmaps)及输出特征图(output feature map,ofmaps)。其中ofmaps 是通过累加中间结果(partial sums,psums)得到的。此外卷积层和全连接层还包含第3种数据类型滤波器(filters)。图1 给出卷积层示例,其ifmaps 的大小是I×I×C,个数为N;ofmaps 的大小是O×O×M,个数为N;filters 的大小是F×F×C,个数为M。表1 给出了图1 中各个参数的定义。

图1 CNN 卷积层

表1 CNN 的参数
2.2 CNN 加速器的通用结构
对于大多数CNN,卷积层和全连接层的计算量在整个网络中占比很大(超过90%),所以本文只对CNN 中的卷积层进行分析(全连接层与卷积层的计算过程相同)。本节首先介绍CNN 加速器的2 种常见数据处理方式,其次给出每种数据处理方式对应的CNN 加速器通用结构。
图2 给出了目前比较常见的2 种CNN 加速器数据处理方式。其中单卷积(single convolution,Sconv)指加速器执行过程中,每次循环包含的数据为一个二维卷积;多卷积(multiple convolution,Mconv)指每次循环包含的数据为多个二维卷积(Tm表示每次处理的filters 的个数,Tc表示每次处理ifmaps 或filters 中的通道数)。本文将处理器每次循环包含的数据称为一个基本处理单元(BasicUnit)。图2 中,对于Sconv 的一个BasicUnit,filters 大小为F×F,ifmaps 的大小为I×I,ofmaps 大小为O×O;对于Mconv 的一个BasicUnit,filters 的大小为F×F×Tm×Tc,ifmaps 的大小为I×I×Tc,ofmaps大小为O×O×Tm(对于Sconv,其BasicUnit 中包含的数据量可能会更小,但只会涉及ifmaps 中一个通道的相关数据)。
基于图2 的2 种数据处理方式,图3 给出了相应的加速器通用结构。图3(a)为Sconv 类型加速器的通用结构,其中包含加速器片上结构(accelerator chip)和外部存储(external memory chip,EXMC)。在accelerator chip 中,处理PE array 中的每个PE 只有一个乘加计算部件(multiply-accumulate unit,MAC)。对于PE 中的存储部件寄存器(Register),一共有2种结构,一种是分散式存储(dispersive register,DR),即每个PE 中都有寄存器;另一种是集中式存储(concentratedregister,CR),即将每个PE中的寄存器集中起来,统一放到PE array 外部。需要说明的是,不同加速器的寄存器大小以及片上网络(network on chip,NoC)结构都不同。

图2 2 种数据处理方式

图3 CNN 加速器通用结构
图3(b)为Mconv 类型加速器的通用结构图。其与Sconv 的不同处为:(1)每个PE 不只有一个MAC;(2)片上存储结构一共有2 层,一层为片上缓存(on-chip buffer,OCB),用来缓存ifmaps、ofmaps以及filters;另一层为寄存器。表2 给出了一些典型的CNN 加速器的数据处理方式和寄存器类型。

表2 典型CNN 加速器分类
2.3 数据传播路径
根据图3 中加速器的存储结构,表3 给出了数据在这些存储结构中的传播路径。这里需要说明的是:(1)当加速器片上结构中有寄存器时,路径中的“→PE”表示数据传输到寄存器中(CR 或DR),否则表示数据直接传输到PE 中的计算单元(MAC);(2)“←PE”表示计算结果从DR 或者MAC 中送出;(3)对于传播路径④“Among PEs”,当加速器中的寄存器类型为DR 时,其表示数据在PE 间的寄存器中传播。当加速器中的寄存器类型为CR 时,其表示PE 阵列对CR 的访问;(4)本文忽略数据在DR 和MAC 之间传播所需要的时间和能耗;(5)对于EXMC→PE 和EXMC←PE,上层存储均是EXMC,下层存储均是PE。

表3 数据传播路径
传播路径④“Among PEs”共有3 种类型,ofmaps传播(ofmaps propagation,OP)、ifmaps 传播(ifmaps propagation,IP)和多类型数据传播(multiple propagation,MP)。每个加速器中只能存在其中一个类型。在OP 类型加速器中,对于一个BasicUnit 中的数据,常见的情况为ifmaps 被直接送到对应PE;filters 被提前固定在PE 中;ofmaps 的中间结果在PE间传播累加,最终结果在其遍历完所有PE 后生成。NeuFlow[10]、CNP[14]均属于OP。
在IP 类型加速器中,对于一个BasicUnit 中的数据,常见的情况为filter 被直接送到对应PE,ofmaps 固定在PE 中直到得到最终结果,ifmaps 在PE间传播。ShiDianNao[6]即属于IP。MP 类型加速器指同时会有多种类型的数据在PE 间传播。CE[15]、Origami[9]、Eyeriss[4]均属于MP。表4 给出了一些CNN 加速器的结构以及其中的数据传播路径。

表4 一些典型加速器的结构与数据路径
图4 为本文所提出的CNN 加速器评估模型(CNNGModel)。当加速器在处理每层CNN 网络时,评估模型需要做以下工作:(1)加速器相关参数和数据传播路径会作为模型的输入,其中每条数据传播路径为模型的处理单元。(2)通过调用模型库中的估算模型,得到每条数据传播路径的中间输出。(3)合并统计数据传播路径的中间输出,得到最终输出。

图4 CNN 加速器通用评估模型
3.1 评估模型输入
本文评估模型的输入包括4 部分:(1)CNN 加速器参数(表5和表6);(2)CNN加速器内部数据传播类型,分为IP、OP 和MP3 类(详细介绍见2.3节);(3)CNN 加速器中3 种数据类型的传播路径(详细介绍见2.3 节);(4)NoC 估计模型[17]用于估计“Among PEs”路径带来的时间与能耗开销。

表5 CNN 加速器中的一些硬件参数(I)

表6 CNN 加速器中的一些硬件参数(II)
表5 中的参数为加速器设计时需要考虑的参数,主要用于在评估模型中得到中间输出。其可以分为两类:加速器结构参数以及数据处理方式参数。其中第1 类包括3 部分:加速器存储结构、计算部件以及片上网络的相关参数。第2 类包括加速器中BasicUnit 以及psums 处理方式的相关参数。表6 中的参数为加速器中不同部件的实际参数,例如频率、不同存储结构的单次访问能耗等。这些参数主要用于在评估模型中得到最终输出,使用Parameters.Variable来表示这些参数(例如IOCB.size)。
3.2 评估模型输出
基于3.1 节的输入,如图5 所示,本文的评估模型将首先给出中间输出ATimes、AVolume 以及Pro-Times;其次依据中间输出最终得到目标CNN 加速器的性能以及能耗。

图5 CNN 加速器评估模型输出
首先对于中间输出给出以下定义:当加速器在处理一个BasicUnit 时,数据在每条传播路径中对上层存储的访问次数被定义为ATimes;在每条传播路径中,下层存储在初始化时获得的数据量被定义为AVolume;当路径为“Among PEs”时,PE 间传播的数据量被定义为ProTimes。其次对于最终输出给出以下定义:Ttransfer 为由数据传输带来的时间;Etransfer 为数据传输所带来的能耗;Tcompute 为由计算带来的时间;Ecompute 为由计算带来的能耗。
因为大多数CNN 的输入输出数据量都很大,如AlexNet 过滤器的数据量为61 MB、Overfeatfast 为146 MB、VGG16 为138 MB,所以当加速器在处理这些CNN 时,无论是从片外到片上,还是只在片上,都会存在大量的数据搬移。从表7 可以看到,大部分CNN 加速器的存储结构面积均超过总面积的一半,其中Eyeriss 甚至高达81.1%。所以CNN 加速器工作时,存储间的数据传输将消耗大量的时间与能耗。因此本文将重点分析CNNGModel 中的Ttransfer 与Etransfer。

表7 CNN 加速器存储结构面积
Ttransfer 通过AVolume 计算得到。因为只需要考虑数据在不同存储结构之间传输所需的时间中不能被计算时间所覆盖的部分,而造成这部分不能被覆盖的时间的数据量为AVolume。对于Etransfer,通过CACTI-6.5 可以得到单次访问DRAM 的能耗,同时可以获取不同工艺下,单次访问不同存储结构(DRAM、SRAM、Register 等)产生的能耗之间的相对比值。因此进一步分别统计3 种数据类型(ifmaps、filters、ofmaps) 对于不同存储结构的访存次数(ATimes),就可以计算出Etransfer。Tcompute 可以根据硬件的峰值性能得到,Ecompute 将通过任务的计算量以及硬件工艺参数得到。
3.3 CNN 加速器通用模型库
CNNGModel 的基本处理单元为目标加速器中的每条数据传播路径。因此当加速器在处理每层CNN 网络时,CNNGModel 将会依据如下步骤工作:首先针对每一条数据传播路径选择通用模型库中对应的估算模型;其次依据输入的CNN 加速器各项参数(表5),通过估算模型得到每条路径的ATimes、ProTimes 以及AVolume;最后整合所有路径的计算结果,依据表6 中的参数得到Ttransfer 与Etransfer。
3.3.1 ATimes、ProTimes 以及AVolume
根据2.3 节,目标加速器中一共会存在12 种路径。将其分为3 类:(1) IFTransfer(6 条):ifmaps 和filters 的路径EXMC→PE、EXMC→OCB 和OCB→PE;(2)OTransfer(3 条):ofmaps 中间结果(psums)的路径EXMC←PE、EXMC←OCB 和OCB←PE;(3)PETransfer(3 条):ifmaps、ofmaps 以及filters 的路径AmongPEs。接下来将分别介绍上述3 类路径的ATimes、AVolume 和ProTimes 估算模型。图6 给出了通用模型库中所有路径的子路径以及对应的估算模型。

图6 CNNGModel 通用模型库的内部结构
3.3.1.1 IFTransfer
在这类路径中,当EXMC→PE 和OCB→PE 的下层存储结构为DR 时,本文规定所有PE 中寄存器的总大小为下层存储大小。IF_Transfer 的ATimes以及AVolume 估算模型可以依据以下3 类子路径讨论。
(1) 下层存储充足(EnoughS)
该类子路径下层存储的大小大于或等于一个BasicUnit 中ifmaps 或filters 的数据量(依据路径中的数据类型来判断是ifmaps 还是filters)。对于该路径,只有当一个BasicUnit 中的数据都存储到其下层存储后,加速器才会开始工作。所以该路径的AVolume 等于BasicUnit 中对应数据的数据量。对于ATimes,若路径下层存储为DR,则与NoC 的吞吐量有关;若为CR 或OCB,ATimes 与上层存储带宽相关,因此:

(2)下层存储不足但数据可重复使用(UEnoughS_Re)
该类子路径下层存储的大小小于一个BasicUnit 中的数据量,但每个数据只需要从上层存储中读取一次。这里将分为两大类对该子路径的估算模型进行讨论,一类为路径的下层存储是DR,另一类为下层存储是CR 或OCB。
首先对下层存储为DR 的路径进行讨论。这里对下层存储为DR 的路径归纳了3 类数据存取模式,并给出了对应的估算模型(未来若有新的模式,也可以依据本文的评估模型得到对应的估算模型)。
不同PE 每次从上层存储得到完全相同的数据,且每次存取的数据量也相同,一般存在于OP 类型加速器。对于属于这种数据存取模式的路径,对应加速器中的PE 一般没有存储相应数据的寄存器,因此数据只能送到PE 中的计算单元。所以AVolume 与每个PE 中计算单元的个数相关。ATimes 则与一个BasicUnit 中对应数据的数据量以及PE 每次得到的数据量AVolume 相关。综上,对于该类数据存取模式的路径:

不同PE 每次从上层存储得到完全不同的数据,且每个PE 每次得到的数据量不一定相同,一般存在于IP 类型加速器。对于拥有这种数据存取模式路径的加速器,其中PE 间会互相传输数据,以此实现数据的重复利用。因为这类加速器在工作时,每个周期都有新数据读入,所以这里的ATimes 等于完成一个BasicUnit 的周期数。而AVolume 与每个PE 初始化时需要的数据量以及加速器中PE 的个数有关。综上,对于该类路径,有:
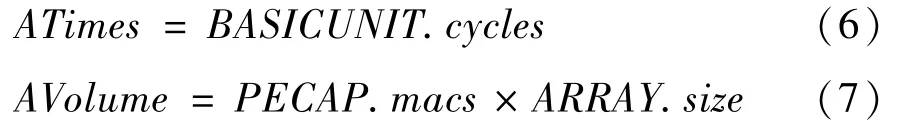
同组PE 每次从上层存储得到相同的数据,且每次得到的数据量不同,一般存在于MP 类型加速器。这种数据存取模式的ATimes 一般与PE 的组数GROUP.num以及每组得到数据的次数GROUP.cycle相关。其中GROUP.cycle与每个PE 中相关数据的寄存器大小以及该数据本身的大小相关(根据NoC结构的设计,这里假设不同组的PE 不会同时取数据)。所以

而AVolume 与PE 中相关数据的寄存储大小相关,则
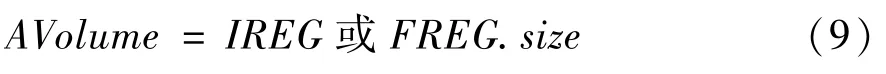
接下来本文讨论UEnoughS_Re 类型路径中,下层存储为CR 或OCB 的情况。因为属于UEnoughS_Re 的路径的下层存储大小小于一个BasicUnit中的数据量,所以CR 或OCB 中的数据会被多次替换,因此ATimes 等于替换次数。这里令替换次数为TimeRelpace1,该参数与加速器的设计相关。例如对于Origami 中ifmaps 的路径EXMC→OCB,每次滑动窗口在ifmaps 上滑动时,OCB 中部分ifmaps 的值将被替换,因此该路径的TimeRelpace1=O×O,AVolume 为初始化时送入下层存储的数据量即下层存储的大小。综上,对于该类数据存取模式的路径:

(3)下层存储不足且数据不重复使用(UEnoughS_URe)
该类子路径下层存储的大小小于一个BasicUnit 中的数据量,且每个数据需要从上层存储中读取多次。该类型路径的下层存储一般为CR 或OCB,因此其中的数据会被多次替换,这里设替换次数为TimeRelpace2,与TimeRelpace1 相同,其与加速器内部设计相关。因此:

3.3.1.2 OTransfer
本节将讨论OTransfer 类型路径中ATimes 以及AVolume 的估算模型。因为OTransfer 路径中的数据为ofmaps 的中间结果psums,而在初始化时OTransfer 类型的路径不会有psums 产生,所以:

其次,对于ATimes,若该类型路径的下层存储是PE,则

因为此时psums 是从DR 或MAC 送出,所以ATimes与BasicUnit 中psums 的大小以及NoC 有关。
对于ATimes,若该类型路径的下层存储是OCB,则

这是因为OCB 是用来存储中间结果的,即只有最终结果才会被从OCB 送出到EXCM,而一个BasicUnit产生的结果为psums。
3.3.1.3 PETransfer
在本节中,将讨论PETransfer 类型路径中Pro-Times 的估算模型。
首先对于ifmaps 和filters,依据加速器中寄存器的类型,ProTimes 的计算方式一共可以分为2 类。若加速器中的寄存器为DR,根据3.2.1 节的分析,因为在下层存储为DR 的路径中每个数据只需要从上层存储读取一次,所以PE 间被重复利用的数据都是通过PE 间传播得到的。同时由于计算1 个MAC 需要1 个ifmap 和1 个filter,因此通过将计算1 个BasicUnit 所需的MAC 数量与1 个BasicUnit 中ifmaps 或filters 的数据量相减,可以得到此处的Pro-Times。综上,有:

若加速器中寄存器的类型为CR,则意味着PE里没有存储,所以PE 在每次计算时都需要访问CR。因此ProTimes 可以通过PE 阵列单次计算能力以及计算1 个BasicUnit 需要的能力得到(PE 阵列的非充分利用将在后续的工作中讨论)。综上,有:

对于psums,ProTimes 主要与2 个参数相关。一个是单个PE 计算1 个psum 时提供的MAC 数量,可以通过得到。另一个为1 个psum从在PE 阵列中的初始状态转变为送出到上层存储时的状态需要的总MAC 量,用PSUMS.macs表示。因此:

3.3.2 Ttransfer 与Etransfer
CNNGModel 将通过中间输出ATimes、ProTimes以及AVolume 得到Ttransfer 以及Etransfer。
ProTimes 为“Among PEs”路径在一个BasicUnit中产生的在PE 间传播的数据总量,其中每一个数据均需要通过NoC 从某个PE 传播到相应的目的PE。因为每个数据在PE 间传播的路线都不同,所以传播每个数据所带来的能耗与时间都不同。依据大多数NoCs 使用的健忘路由算法[19],可以得到每个PE 阵列中存在的所有数据传播路线。本文将考虑最差的情况,因此假设所有数据在PE 间的传播路线均是PE 间最长的数据传播路线,即一共经过K个PE,则每个数据在PE 间传播所消耗的能耗均为K×I(F/O)REG.accessE,所消耗的时间均为K个cycle。此外考虑到NoC 中会出现拥塞情况,根据文献[17]中给出的拥塞最差情况模型,本文为每条传播路线增加了因拥塞造成的额外时间与能耗。
ATimes 为每条传播路径在1 个BasicUnit 中对上层存储的访问次数,因此通过将ATimes 与对应路径上层存储结构的单次访存能耗相乘,可以得到每条路径因访问上层存储而消耗的能量。
AVolume 为每条传播路径在1 个BasicUnit 中,下层存储在初始化时获得的数据量。如果路径中的下层存储有双缓存,则加速器初始化时,由传输ifmaps 和filters 所造成的时间只与第一个BasicUnit中的AVolume 相关,否则与所有BasicUnit 相关。
算法1 给出了计算Etransfer 的详细步骤。(1)需要获得通用评估模型输入中所有的数据传播路径;(2)通过上一节的估算模型,可以得到对于一个BasicUnit,每条路径的ATimes 和ProTimes;(3)根据1 个卷积层中BasicUnit 的总量,可以获得每条路径ATimes 和ProTimes 的总量;(4) 根据对应路径ATimes 或ProTimes 的总量,获得每条路径消耗的能量;(5)通过将每条路径因访存消耗的能量相加,获得加速器在处理当前卷积层的Etransfer。

算法2 给出了计算Ttransfer 的详细步骤。与计算Etransfer 相同,这里也需要获得每个卷积层所有的传播路径以及累加每条路径所造成的传输时间。此外由于加速器中大多数传输时间可以被计算时间所覆盖,因此Ttransfer 只考虑不能被计算时间所覆盖的部分,其主要与AVolume 相关。

本节设计了3 个CNN 加速器——Sconv-DR-OP、Sconv-CR-IP 和Mconv-CR-MP 用于验证CNNGModel的有效性。3 个加速器基于的原型分别为Neu-Flow[10]、ShiDianNao[6]以及Origami[9]。实验中,首先使用开源模拟器VTA[20]实现了上述3 个加速器;其次基于TSMC 16 nm 技术,使用硬件描述语言Verilog 和Synopsys 设计编译器(DC)对上述3 个加速器进行仿真与综合;最后使用CNNGModel 对3 个加速器的性能与功率进行估计。
4.1 Sconv-DR-OP、Sconv-CR-IP 及Mconv-CRMP
如图7(a)所示,Sconv-DR-OP 的数据传播方式为OP,寄存器类型为DR 且数据处理方式为Sconv。其中的数据传播路径有:(1)ifmaps 的EXMC→PE;(2)filters 的EXMC→PE;(3)ofmaps 的PEAmong;(4)ofmaps 的EXMC←PE。对于每个ifmaps 神经元,Sconv-DR-OP 只需要从EXMC 读取一次,且每个时钟周期只读取一个并送到所有PE。对于filters权重,其会被提前固定在不同的PE 中。而对于ofmaps,当其中间结果遍历完所有的PE 与FIFO 后,会从最后一个PE 输出。
如图7(b)所示,Sconv-CR-IP 的数据传播方式为IP,寄存器类型为CR 且数据处理方式为Sconv。其中的数据传播路径与Sconv-DR-OP 相比,只有传播路径(3)不同,为ifmaps 的PEAmong。在Sconv-CR-IP 中,首先相同的1 个filters 权重会送到所有的PE。其次对于ifmaps 神经元,其在每个时钟周期会送到不同的PE。而对于ofmaps,每个PE 一次只负责计算1 个ofmaps。
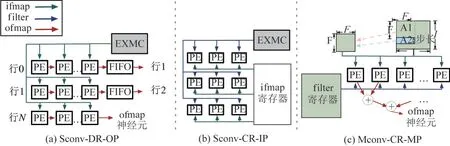
图7 3 个CNN 加速器
如图7(c)所示,Mconv-CR-MP 的数据传播方式为MP,寄存器类型为CR 且数据处理方式为Mconv。其中的数据传播路径有:(1)ifmaps 的EXMC →OCB;(2) ifmaps 的 OCB →PE;(3) ifmaps 的PEAmong;(4)filters 的EXMC →PE;(5) filters 的PEAmong;(6) ofmaps 的EXMC←PE。对于该加速器,多个filters 权重和ifmaps 神经元会被同时送到每个PE,每个PE 一次负责计算1 个ofmaps。为了保证流水线,其中每个PE 只负责乘法,剩余的加法操作会在PE 外执行。
表8 给出了3 个加速器的参数。

表8 3 个加速器的参数
4.2 实验结果分析
如表9 所示,选择AlexNet、VGG 以及ResNet 中的部分卷积层作为实验数据集。
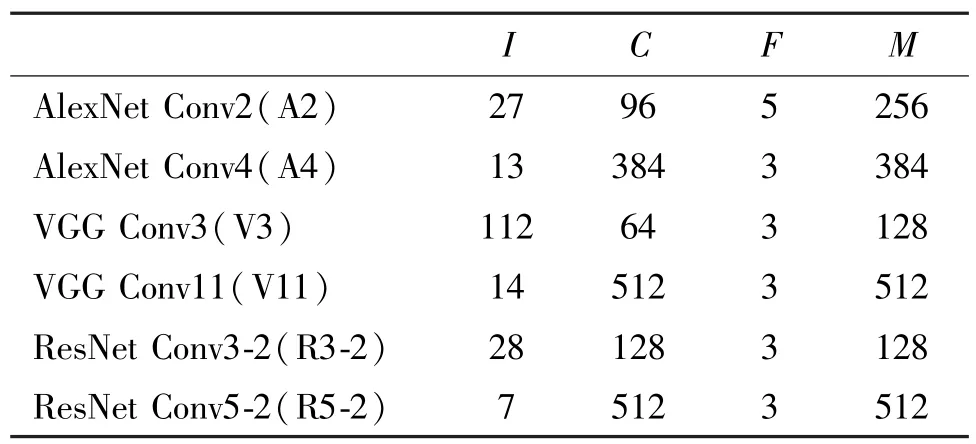
表9 用于实验的卷积层参数
4.2.1 性能结果对比
对于加速器的性能,本节将重点分析PE 阵列的工作时间(CAL-cycle)以及加速器工作总时间(Time)。
图8(a)给出了Sconv-DR-OP 在处理6 个卷积层时PE 阵列的工作时间(CAL-cycle),其中CNNGModel 的结果与仿真结果的差距分别为5.2%、5.4%、4.6%、4.0%、4.9%和5.4%。可以看到这里的CNNGModel 结果始终比仿真结果小。这是因为虽然CNNGModel 考虑了由NoC 传播以及拥塞所造成的时间,但其使用了加速器的峰值性能。另一方面,CNNGModel 与模拟器VTA 的差距分别为0.5%、1.4%、0.7%、0.3%、1.5%、1.2%,说明在不浪费大量人力和时间的情况下,CNNGModel 可以提供与模拟器VTA 相近的性能。
图8(b)给出了Sconv-DR-OP 在处理6 个卷积层时的总时间(Time),其中CNNGModel 的结果与仿真结果的差距分别为6.7%、7.0%、6.1%、5.4%、5.2% 和6.4%。造成上述现象的原因有:(1)CNNGModel 对于CAL-cycle 的估计值小于仿真结果;(2) CNNGModel 没有考虑加速器的配置时间、BasicUnit 间有效信号、状态信号等的传输时间以及数据在FIFO 中的传播时间。与CAL-cycle 类似,对于工作总时间Time,CNNGModel 结果与模拟器VTA结果十分接近,差距分别为1.8%、2.3%、0.9%、1.3%、0.7%、1.7%.

图8 Sconv-DR-OP 的CAL-Cycle 以及Time
图9 和图10 给出了其他2 个加速器在处理6个卷积层时的CAL-Cycle 以及Time。与Sconv-DROP 中的结果相似,CNNGModel 的估计值始终比仿真结果小,但与模拟器VTA 的结果十分接近。

图9 Sconv-CR-IP 的CAL-Cycle 以及Time
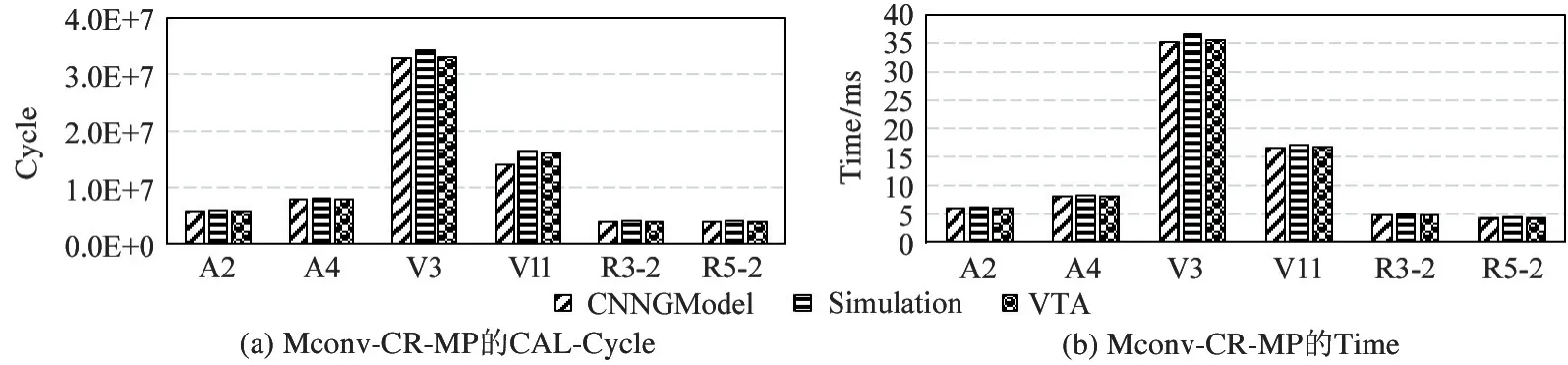
图10 Mconv-CR-MP 的CAL-Cycle 以及Time
4.2.2 功率结果对比
加速器的能耗主要由传输能耗和计算能耗组成。由于模拟器VTA 只能给出加速器的工作时间,所以本节将只比较CNNGModel 与仿真综合的结果。首先将分析加速器工作时对不同存储的访问次数,这些次数可用于得到传输能耗为模型的中间输出。
图11(a)给出了Sconv-DR-OP 在处理6 个卷积层时对EXMC 的读次数(EXMCR-ATimes),其中CNNGModel 的误差率分别为0.13%、0.32%、0.56%、0.51%,0.13%和0.47%,与仿真结果十分接近。图11(b)给出了Sconv-DR-OP 在处理6 个卷积层时的PE 间传播次数(ProTimes),其中CNNGModel 的误差率分别为0.57%、1.31%、1.03%、0.37%、2.98% 和0.54%。可以看到CNNGModel比仿真结果稍小,而造成该现象的原因是CNNGModel 没有考虑在PE 间传播的一些额外控制信号(如当stride 不为1 时,会有一些额外的控制信号送到PE 中)。图11(c)中给出了Sconv-DR-OP 在处理6 个卷积层时对 EXMC 的写次数(EXMCWATimes),其中CNNGModel 的误差率分别为2.84%、4.20%、6.98%、1.25%、7.44%和8.04%。可以看到这里的建模结果比仿真结果稍小,而造成该现象的原因是由于Sconv-DR-OP 在仿真时写回的位宽是固定的,所以当有效结果的总位宽低于写回位宽时,也会按写回的固定位宽来统计从而增加了额外的写回次数。图12、图13 给出了Sconv-CR-IP、Mconv-CRMP 在处理6 个卷积层时各个参数的CNNGModel 值和仿真值。可以看到这些参数的CNNGModel 结果和仿真结果基本相同。

图11 Sconv-DR-OP 的中间输出

图12 Sconv-CR-IP 的中间输出
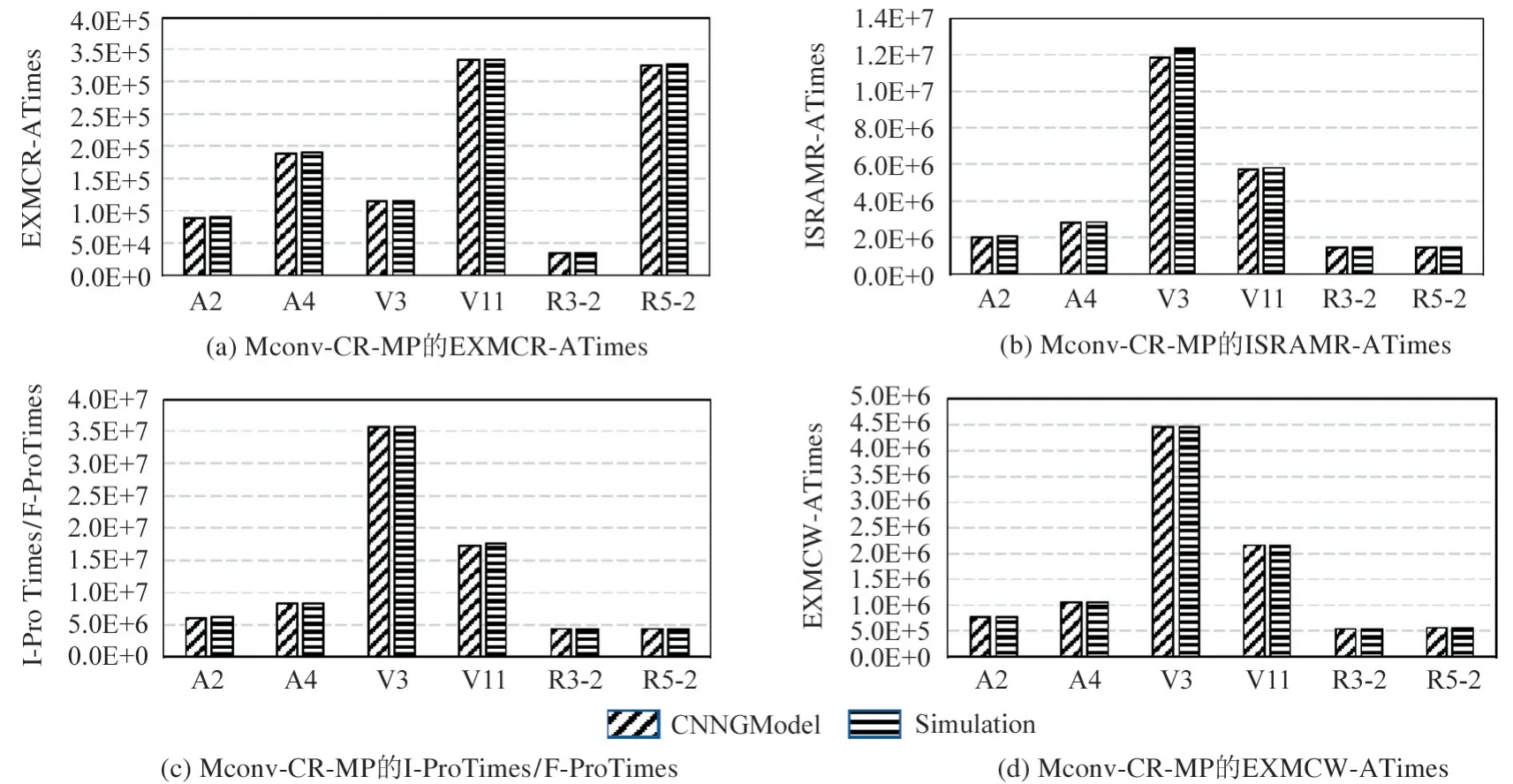
图13 Mconv-CR-MP 的中间输出
图14 给出了3 个加速器在处理6 个卷积层时的功率。可以看到CNNGModel 的结果与仿真综合结果相近,但始终比其小。造成该现象的原因是CNNGModel 只考虑了传输、计算以及NoC 消耗的动态功率,而RTL 级的综合还考虑了静态功率等。

图14 3 个加速器处理每个任务的功率
依据CNNGModel,本节从能耗和性能两方面给出了多项CNN 加速器优化策略。
5.1 能耗优化策略
在CNNGModel 中,CNN 加速器传输能耗的计算方式如式(20)所示。其中DRAM_E、SRAM_E以及Register_E代表单次访问每种存储结构时需要的能耗,ATimesDRAM、ATimesSRAM以及ProTimesRegister代表每种存储结被访问的总次数。

文献[4]给出了单次访问DRAM、SRAM 和Register 的能耗比为200 ∶6 ∶1。因此为了减少传输能耗,根据式(20),常用的方法为增加SRAM 以及Register 大小从而减少对DRAM 的访问次数。除此之外,根据式(20),通过减少ATimesDRAM、ATimesSRAM以及ProTimesRegister,CNNGModel 还可以从更多的角度对减少传输能耗提出相应的策略。
当ATimesDRAM通过式 (3)ATimes=计算时,可以选择增加相应存储的带宽从而减少ATimes,最终达到减少传输能耗的目的。例如选择使用多块DRAM 而不是一整块大面积DRAM,因为多块DRAM 可以被同时访问,通过增加channel 提高并行度的方式来增加带宽。
当ATimesSRAM通过式(2)ATimes=计算时,此时若想使ATimes 减半,可以将PE 阵列每次从SRAM 读取ifmaps 的位宽增加1 倍。例如可以将PE 阵列中Register 的个数增加1 倍,或用SRAM 代替Register 并将SRAM 写位宽按要求设置。当ATimesSRAM通过式 (5)ATimes=计算时,此时若想使ATimes 降低,可以通过增加每个PE 中计算单元MAC 的个数来达到需求。

在CNNGModel 中,CNN 加速器计算能耗的计算方式如式(21)所示。其中ComputeA为当前应用的计算量,Technology为加速器的工艺。因此根据式(21),可以通过提升加速器的工艺来减少因为计算产生的能耗。

5.2 性能优化策略
CNN 加速器的执行时间是由传输时间和计算时间两部分组成的。因为流水线的存在,加速器内部大部分由于数据传输所带来的时间可以被计算时间所覆盖。为了减少CNN 加速器的总执行时间,需要尽量减少不能被计算时间覆盖的数据传输时间。因此CNN 加速器在设计时需要尽量将片上的存储结构做双缓存处理,添加ifmaps 和filters 数据的预取机制。这样能减少流水线阻断情况的发生,保证每个卷积核的计算过程能够无缝迭代执行。
本文首先基于CNN 加速器的通用硬件结构,提出了加速器中数据传播路径的概念。其次提出了CNN 加速器性能与能耗通用评估模型(CNNGModel)。CNNGModel 的输入包括4 部分:CNN 加速器参数、CNN 加速器数据传播方式、CNN 加速器的数据传播路径以及NoC 评估模型。输出包括中间输出和最终输出两部分。CNNGModel 的核心部分为通用模型库。
实验结果证明,CNNGModel 的结果与真实的仿真值是十分接近的。最后本文从能耗和性能两方面给出了多项CNN 加速器优化策略。
猜你喜欢 下层数据量寄存器 基于大数据量的初至层析成像算法优化北京大学学报(自然科学版)(2021年3期)2021-07-16高刷新率不容易显示器需求与接口标准带宽电脑爱好者(2020年19期)2020-10-20Lite寄存器模型的设计与实现计算机应用(2020年5期)2020-06-07宽带信号采集与大数据量传输系统设计与研究电子制作(2019年13期)2020-01-14二进制翻译中动静结合的寄存器分配优化方法计算机研究与发展(2019年4期)2019-04-18折叠积雪读者·校园版(2019年3期)2019-01-28移位寄存器及算术运算应用电子技术与软件工程(2018年1期)2018-03-22积雪少年文艺·开心阅读作文(2017年1期)2017-02-24有借有还小天使·四年级语数英综合(2014年3期)2014-03-21Lx5280模拟器移植设计及实施科技视界(2011年5期)2011-08-22推荐访问:建模 加速器 优化设计