基于混沌工程的自动化故障实验系统
来源:优秀文章 发布时间:2023-01-19 点击:
魏 星,李 京,童飞帆
1(中国科学技术大学,合肥 230000)2(上海随训通电子科技有限公司,上海 201100)
在数据爆炸式生长的时代,分布式系统[1]扮演着至关重要的角色,为互联网用户提供高可用、高可靠的计算或存储服务[2].但分布式系统的复杂度极高,实际运行环境中可能发生各种不可预测的突发事件[3],如节点宕机、网络分区、高并发导致的磁盘读写繁忙等等,各种故障的发生往往对分布式系统带来无法预料的灾难.
混沌工程(Chaos Engineering)[4-6]是一门“在分布式系统上进行实验的学科,目的是建立对系统承受生产环境中湍流条件能力的信心.”混沌工程技术主动地在分布式系统中模拟故障,制造出系统异常,以测试系统在故障下的稳定性表现,提前暴露出潜在问题并进行修复,避免实际运行过程中由于突发故障导致服务不稳定甚至服务不可用.
传统异常测试在给定预期输入输出后对系统的特定模块、代码逻辑等进行测试,检验系统反馈是否正常.传统异常测试的变量限制在各类用户或开发者的操作上,如用户输入超出规定长度的字符、开发者更改配置文件;
混沌工程的变量则反映各类现实的异常事件,如服务器死机、机房断网等.不同于传统异常测试,混沌工程直接对分布式系统进行破坏,随机模拟各种故障场景,并支持以可回放、持续性的故障演练验证系统稳定性.
基于混沌工程的故障实验系统可分为两类:一类以ChaosBlade[7]、Chaos Mesh[8]为代表,能面向不同的分布式系统提供故障实验能力,但前者仅支持指定机器下的单个故障注入,后者支持故障编排实验,但仅支持容器化[9]部署的机器.以上两者都不支持数据读写或验证,且实验粒度仅限于指定IP机器或指定ID的容器.一类以etcd Functional[10]为代表,由分布式系统开发者实现以支持某个特定系统的故障实验,但这类技术多内嵌于定制的系统框架,无法为其他分布式系统提供实验能力.综上,基于混沌工程的自动化故障实验技术面临以下问题:
1)故障实验编排指在实验中支持一系列故障持续发生,通过故障编排,可在系统日常迭代时进行一系列自动化故障实验,降低人力实验成本.现有技术大多专注于不同的底层故障实现,仅少数技术支持故障实验编排,而支持实验编排的技术对系统类型、部署环境等有较多限制.
2)分布式系统中进程根据职责分为不同的角色,角色运行在不同机器上,可能会在机器间动态迁移.现有技术实验粒度仅限于指定机器或指定容器,若系统发生角色迁移仍持续在原机器注入故障,无法实现精准的角色粒度实验.
3)在故障实验中,通过系统读写(或接口调用,非严格数据读写)和数据验证能实时验证系统功能的可用性、正确性.但现有技术的实验流程中仅支持故障操作,用户需手动进行系统数据读写及验证等操作,往往具有滞后性.而不同系统的读写及验证逻辑与系统本身强耦合,在故障实验中支持这类定制化操作具有挑战性.
针对上述问题,本文面向分布式系统创新性地提出了一种基于混沌工程的自动化故障实验技术.在该技术中,提出了一种自动化故障实验系统架构,定义了一套实验抽象模型和实验调度方法:1)支持通过一套标准的模型描述,对不同的故障及用户定制化操作进行自动化编排实验;
2)支持对分布式系统的角色粒度进行实验,并在角色迁移时能动态地将故障迁移至对应节点;
3)实验能力扩展,支持用户进行定制化操作开发如实现读写或数据验证.与现有技术相比,上述技术具有以下优势:1)自动化,支持故障实验编排,支持包含故障及读写验证的完整故障实验闭环;
2)灵活度高,实验中能动态地感知到分布式系统的角色动态迁移,支持对角色迁移后的机器进行精准故障实验;
3)开放度高,用户可扩展性地定制故障、读写、验证操作.
根据本文所实现的自动化故障实验系统在不同分布式系统上进行实验,结果表明相较于其他现有技术,本文技术能提供更自动化的故障实验编排,支持对系统的角色粒度进行动态实验,支持用户定制化操作并与实验流程耦合,解决了现有技术的缺陷.
基于混沌工程,研究者们提出了不同的技术支持分布式系统上的故障模拟,帮助开发者通过故障实验进行系统稳定性验证.
Netflix[11]的Chaos Monkey为首个基于混沌工程技术的开源项目.Chaos Monkey实现了在Netflix云平台中随机关闭服务实例的故障,从而验证服务整体在某部分实例失败的情况下是否仍正常工作.该技术仅支持关闭服务实例场景的自动化实验,提供的故障类型单一.
阿里巴巴的ChaosBlade系统提供丰富的故障类型,支持CPU、内存、网络、磁盘、进程等资源故障[12],Java、C++ 等代码级故障[13,14].ChaosBlade致力于提供丰富的故障场景,但未关注自动化实验编排,用户仅可进行单故障注入,无法利用该技术进行丰富的故障组合实验.
PingCAP提出的Chaos Mesh提供自动化故障实验能力,支持用户通过CRD(Custom Resource Definition)对象定义故障,包括故障行为、范围、时间频率等,故障根据用户定义自动发生.但Chaos Mesh的自动化程度有限,无法在实验流程中提供用户数据读写、数据验证等操作,且Chaos Mesh仅支持云原生部署的分布式系统.
etcd[15]是一个应用于分布式系统元数据的键值存储系统,为验证自身系统的稳定性,etcd团队提出了一个故障注入框架Functional Testing.该框架可以验证在各种系统故障、网络故障、代码故障下etcd是否能经受住考验.该框架支持etcd在故障实验中进行数据验证操作,但Functional Testing内嵌于etcd系统中,与etcd的其他模块紧密耦合,无法为etcd以外的分布式系统提供通用的自动化故障实验能力.
Gremlin[16]公司提出了一个面向分布式存储或计算系统的的“恢复能力即服务”(Resilience as a Service)平台——Gremlin,该平台提供自动化故障实验能力.Gremlin支持用户将不同故障进行编排实验,但实验流程中不支持进行读写、验证等操作,实验粒度也仅限于指定机器.
综上所述,现有自动化故障实验技术具有明显的局限性,无法灵活提供将不同故障组合的自动化实验,无法支持在实验中进行数据读写、数据验证等操作.同时,以上所有技术仅支持指定IP机器或指定ID容器粒度的实验操作,无法支持在分布式系统的角色迁移过程中进行动态的故障实验.
混沌工程,是一种提高分布式系统高可用、稳定性的复杂技术手段.其主要思想是主动地在分布式系统上进行故障实验,测试系统在面临故障时是否能经受考验,提前识别出潜在的风险项.若系统面临故障时出现异常,如服务不稳定或不可用,则认为实验成功,帮助用户发现了系统的潜在风险,以提前进行系统修复,避免未来实际运行中由于该故障造成更大的损失.最简单的故障实验,如在分布式系统的某一台机器上运行“kill-9”命令强制杀掉进程,以验证系统是否能在该进程被杀后正常运行.
混沌工程技术常用到以下术语:“故障实验”指在机器上模拟故障的发生从而进行实验的过程;
“故障注入”指机器上开始进行故障模拟,该词源于将流感疫苗“注入”人体内防止未来疾病的描述;
“故障释放”与“故障注入”相对,指在机器上停止故障模拟的过程;
“故障模型”描述单个故障模拟发生的过程,如:故障的具体行为表现、发生时长、执行频率等;
“编排”指对整体实验过程进行的预定义描述,如何时开始实验,发生哪些故障,故障间的先后次序等.
现有的混沌工程技术架构一般包括实验管理层及故障模块两部分,代表故障操作的故障任务模型提交至实验管理层后,由其解析目标机器并下发至分布式系统的目标机器中,机器中的预置的故障模块接收模型后进一步解析为相关指令,并对所在机器注入、释放对应故障.
4.1 系统总览
本文面向分布式系统提出的基于混沌工程的自动化故障实验系统架构如图1所示.该架构以“任务模型”和“编排模型”为输入,实验管理层根据用户模型创建实验并下发至第三方存储系统.实验调度中心从第三方存储中轮询实验状态,符合预期执行时间则解析实验模型,根据模型描述转换成任务注入、任务释放指令,将指令下发到目标角色所在节点中.节点中的故障模块或用户自定义插件模块接收指令并实施指令操作.调度中心将记录每次下发的指令,转换为实验执行详情,由第三方存储回传给管理层.
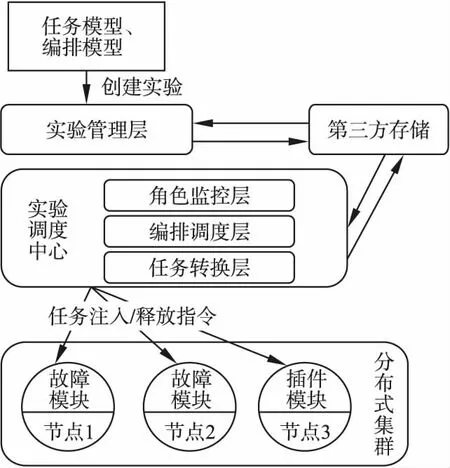
图1基于混沌工程的自动化故障实验系统架构
现有技术架构中,故障模块需对任务模型进行状态保存,任务解析及指令转换皆由故障模块实现.本文提出的架构则将以上职责交由实验调度中心,调度中心内部分为角色监控层、调度层、任务转换层.调度中心与第三方存储交互,监控层实时监控分布式系统中的角色迁移,并同步至第三方存储.调度层不断轮询存储中的模型,根据状态进行调度,若需要下发任务操作至分布式系统,则交由任务转换层.任务转换层将任务操作转换为具体指令,下发至分布式集群中的目标机器的故障模块、插件模块.本架构中提出的插件模块,可支持用户可通过操作扩展在实验中进行数据读写、一致性验证[17]等.
4.2 自动化故障实验编排
自动化故障实验能检验系统在一系列故障依次发生时的稳定性,但现有技术中需要用户手动进行“检验”操作.若实验流程中支持系统的读写测试及数据验证等操作,能实时验证故障下的系统稳定性,降低人力成本.本节在传统故障模型之上提出“任务模型”和“编排模型”.以任务模型的概念统一描述在故障实验中进行的故障、读写、数据验证等操作,通过编排模型将不同的操作进行组合,以提供自动化故障实验编排功能.
4.2.1 任务模型
任务:故障实验流程中的操作步骤,如发生磁盘故障、进行数据验证.
本技术中对任务定义如上,通过“任务”可将实验流程拆分为不同的原子操作.任务模型对任务具体操作内容进行抽象描述,根据操作内容的不同,将任务模型分为:
故障任务模型:描述故障操作的任务模型;
插件任务模型:描述用户自定义操作的任务模型,如读写系统数据、数据验证等操作.
故障任务和插件任务的具体操作在执行方式上大相径庭,但具有如下共同点:需指定操作的目标节点、需指定执行发生时长、支持周期性发生.任务模型抽象如表1所示,具有任务类型、任务目标、调度参数及操作执行具体参数等属性,通过任务模型定义的任务操作遵循“开始执行”、“停止执行”.

表1 任务模型
故障任务由系统中内置的故障模块所提供,根据故障类型的不同,将故障任务模型的行为属性扩展如表2所示.在分布式系统中,利用网络将服务分散在多台机器上,互相协作以提供存储、计算等功能,故网络故障发生时会对分布式系统带来可用性考验.常见的网络故障由物理线路故障、路由器故障、网络拥塞、网络请求密钥过期等引发,但不同故障在分布式系统中体现为3种:网络请求延时、网络请求拒绝、网络请求丢包.底层故障模块实现时,可采用iptables[18]技术通过修改机器配置模拟以上3种网络故障.网络故障任务模型中需指定请求下游,即发往该目标下游的请求会发生故障,可按“ip:port”或“cidr”[19]方式进行指定.“probability”属性帮助指定一个请求发生故障的概率,提供随机性.网络延时故障中需具有“延时时间”属性.
文件系统中提供不同的操作方法,如“open”打开文件,“read”读取文件内容,“sync”将修改过的文件内容由缓冲区写入磁盘.“methods”指定文件系统中的操作方法列表,仅列出的操作方法发生故障.文件系统中常发生的故障可分为返回错误码、操作延时,分别对应为“error_no”、“delay”属性,指定文件操作故障行为.
分布式系统若依赖时钟进行选举投票等操作,时钟跳变故障可帮助检验系统是否具有时钟依赖或系统是否能再正确应对时钟跳变.时钟跳变故障任务通过“offset”属性描述系统偏移时间,支持系统时钟向前或向后拨转.
CPU、磁盘等资源竞争会影响分布式系统中的服务稳定性.CPU故障任务和磁盘故障任务通过“utils”可指定该类资源竞争时的占用率.
此外某些故障可通过用户在机器上执行Linux指令实现,如通过“rm-rf”删除某机器上的数据文件.本文提出自定义指令故障,为保持“故障注入”、“故障释放”的逻辑,用户分别通过“start_cmd”及“stop_cmd” 描述该故障开始、结束时执行的指令,指令透传到目标机器上执行.
不同于故障任务,读写、验证等任务操作与分布式系统自身的数据结构、接口实现等紧密耦合.为支持用户在实验中进行故障以外的操作,本文提出“插件式任务”,其实现于4.4节介绍,此处仅介绍其任务模型.插件任务模型符合表1的通用任务模型定义,“params”属性为开放式接口定义.用户需根据插件式任务实现时设置的参数进行该属性扩展,如为etcd分布式系统开发的一个插件式读写任务中,可设置“op”参数表示操作类型,设置“counts”操作表示操作次数,则该插件模型定义时“params”字段下包括字符串类型的“op”及整数类型的“counts”两参数.
4.2.2 编排模型
编排:故障实验发生流程,包括一场实验中需执行的任务、任务先后次序等.本技术对编排定义如上,通过编排可将不同的任务进行组合,从而对一场故障实验的具体操作内容进行整体描述.编排模型对实验编排进行抽象,定义好的编排模型可作为实验模板执行,模型属性及规则如表3所示,实验运行时根据目标系统、实验周期、目标系统角色映射接口等属性进行调度.

表3 编排模型
“状态机”描述实验操作流程,状态机中定义多个状态s1、s2,代表实验流程的不同阶段.每个状态内部可定义t1、t2等多个任务,即处于该状态的实验阶段需进行的具体操作.通过状态机定义的编排模型实验流程如图2所示.不同状态按照定义次序串行流转,同个状态内的任务并发执行,当某状态下的所有任务执行完毕后才进入下一个状态阶段.

图2 状态机流程示例
本系统实现时定义的编排模型示例如表4所示,其中“role_url”为期望实验的分布式系统中提供角色查询的地址,实验过程中实时通过该地址获取系统中不同角色与所在节点IP的映射关系,从而实现角色粒度的动态故障实验.“schedule”表明该编排是否定时发生,可指定首次发生时长和执行周期.若不指定“schedule”字段,则该编排应由用户手动触发执行.“status_machine”描述任务发生流程,由该字段示例值描述的实验发生时,会先执行status1中的“network-reject”网络拒绝故障;
接着同时执行status2的“network-drop”和“cpu-burn”故障,两个故障都结束后,最后执行“consistency-check”一致性验证任务.

表4 编排模型示例
4.3 支持角色粒度的动态调度
在分布式系统中,将参与进程根据不同职责定义为“角色”,如Hadoop系统中管理元数据的进程角色为 “namenode”,负责数据存储的进程角色为“datanode”.不同的角色运行在集群各个机器之上,由于机器故障、选举、进程异常等原因,进程的角色会发生变化甚至消失,即角色在机器间“动态迁移”.故障实验中,故障效果应伴随角色迁移至对应的机器.
实验调度中心为无状态计算[20],即无主式的多节点部署[21],状态信息皆由第三方存储保存,可快速进行实验扩展,也能在某调度节点崩溃时由其他节点快速接任完成调度.每个调度节点上分别独立运行编排实例调度器、状态转换器、任务实例调度器等多个子模块.调度中心根据分布式系统角色信息进行动态实验的流程如图3所示,当某角色由节点1迁移至节点2时,角色监控器察觉到并更新存储系统的角色及节点映射关系,编排实例调度器轮询发现后通知任务实例调度器,解析后由任务转换器停止原节点的故障,并在新节点中重新开始执行.
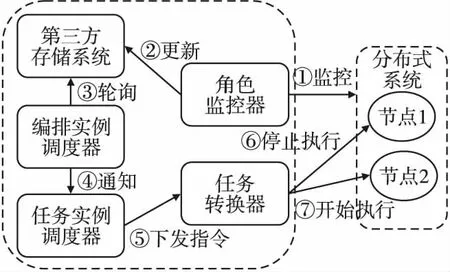
图3 故障动态转移流程
调度算法中设计主要对象包括编排实例及任务实例.编排实例对应正在运行的实验编排,如表5所示具有执行状态、最近角色信息等属性,其生命周期示意如图4(a)所示,从实验开始持续至所有状态的任务运行结束,由编排调度器管理.

表5 编排实例对象及规则
任务实例对应正在运行的任务,由任务实例调度器管理,如表6所示描述当前是否正在执行、最近执行的目标节点等信息.任务实例的生命周期示意如图4(b)所示,编排流转至该任务所属状态时,任务实例被创建即生命周期开始,当任务实例及所有并发实例超时(根据用户定义的任务运行时长),则实例被删除,结束生命周期.一个任务实例在其生命周期内,可能反复执行多次,如当用户设置10分钟内每2分钟执行30秒时,该任务实例将于生命周期内先后执行5次.

表6 任务实例对象及规则

图4 调度层实例生命周期
在故障实验中,调度算法将所有类型任务统一调度.但部分任务如用户定制的数据读写操作不具有幂等性[22],多个调度器同时拉取到该任务实例并执行,会带来不符合预期的语义操作.算法中通过任务唯一键保证单个任务不被多个调度器重复执行,采用“{flow-instance}/{status}/{task-instance}/{counts}”标志某个任务实例的某次具体执行.任务实例调度器对任务执行唯一键的操作逻辑如图5所示.当执行或停止执行任务失败时,需启用补偿机制,重新删除或创建该键,以便后续调度器根据键的存在状态重新尝试操作.

图5 任务实例调度器对任务唯一键的操作流程
4.4 支持定制读写、验证的能力扩展
现有混沌技术不支持用户进行定制化开发,无法将自定义故障、期望的其他自定义操作与故障实验流程相结合.考虑到分布式系统的读写模型、接口规范、数据语义等大相径庭,一般需要用户自行完成接口适配、代码编写.定制任务应由调度层进行统一调度,保持和其他任务相同的逻辑规范,即任务支持“开始执行”、“停止执行”操作.
为支持用户编程、统一任务调度,本技术以插件模块的形式实现为用户提供操作(读写、验证、自定义故障等)定制的能力扩展.插件模块可通过服务注册方式与系统耦合,其框架模板由实验系统统一提供,内置注册、解注册实现,为用户预留“开始执行”、“停止执行”方法接口.用户根据插件模块框架自由开发期望的任务操作逻辑,启动框架后该模块会自动注册至第三方存储,并同步至实验管理层.当启动的实验中需要运行插件任务时,调度逻辑与内置故障任务一致,但在下发至节点时需查询注册表中的预置参数及类型,将操作转换成对应指令下发至目标节点的插件模块.
为验证本文技术的有效性:支持自动化故障实验编排,支持基于角色粒度进行动态故障实验,支持用户进行数据读写、数据验证等插件任务开发并耦合至故障实验流程,本节进行系统实验如下.
5.1 实验设置
按照图1的实验架构实现自动化故障实验系统,其中实验管理平台及实验调度模块分别多实例部署在一个三节点集群中,为用户提供Web界面和API操作两种实验方式.系统参照现有的混沌技术实现了故障模块,该模块集成不同的底层技术,实现4.2.1节中提到的各种故障效果:网络拒绝/丢包/延时故障(iptables技术)、文件系统故障(fuse[23]、hookfs[24]技术)、磁盘读写繁忙(stress-ng[25])、时钟跳变、CPU繁忙、自定义指令故障.该系统包括故障模块将于GitHub上进行开源.
实验所面向的分布式系统选取Hadoop[26]及etcd.Hadoop部署于OpenStack[27]的10台虚拟机中,由一个namenode节点和多个datanode节点组成,启用HA[28]机制进行主备切换.etcd在5台虚拟机中进行部署,分为一个leader节点和4个worker节点.
5.2 故障效果及支持操作定制的自动化编排验证
为验证本系统支持操作定制的自动化编排功能及实际故障效果,设计编排流程如表7所示,首先开启系统读写,然后进行一系列故障注入,故障结束后对读写数据进行验证.

表7 自动化编排实验流程设计
读写及验证任务皆为插件任务,系统采用Golang-Gin[29]框架实现插件模块,为用户预留“开始执行”、“停止执行”两函数进行自定义代码开发,该模块由用户启动后自动注册于调度层.Hadoop读写任务于“开始执行”函数内调用10000次“hadoop fs-put”API即进行文件上传操作,文件内容为当次操作次数编号,调用结果记录至本地日志;
Hadoop验证任务于“开始执行”函数进行“hadoop fs-get”文件读取操作,验证文件最终内容并核对本地日志的调用成功次数.etcd读写任务于“开始执行”函数内调用10000次“etcdctl put”对指定键“etcd-chaos-test”进行写操作,写入值为操作次数编号,将操作结果记录本地日志;
etcd验证任务于“开始执行”函数内调用“etcdctl get”验证键值并核对日志记录的操作成功次数.读写及验证任务的代码逻辑于“开始执行”函数中执行完毕后即返回,无需“停止执行”函数主动停止,故以上任务的“停止执行”函数为空代码.将以上插件任务对应实现的模块分别于集群主节点启动,实验中由调度层触发执行.
根据编排流程通过API设置实验,根据任务效果创建任务模型后提交编排配置如图6所示,该配置为API提交时所需的JSON[30]格式.实验过程中监控各机器的各项系统指标.

图6 通过API实验的编排配置文件(Json)
Hadoop集群中的实验效果如图7(a)所示.status1的插件读写启动后于后台执行,状态立即流转至status2开始故障,该过程耗时为秒级,故从status2开启时为时间原点.在0-10分钟,由于网络丢包故障导致入请求减少,从节点datanode8所在机器出现持续十分钟的网络入流量低谷.10-20分钟,随机节点发生的磁盘繁忙故障在datanode3中发生,节点磁盘读写占用率都拉高至近100%.20-25分钟,文件系统故障导致datanode6及datanode8(图中仅显示datanode6效果)所在机器的文件读写延时超过200ms.25-35分钟,CPU繁忙故障导致namenode节点CPU占用率持续拉高近100%,该繁忙效果每隔1分钟发生1分钟.验证时发现,Hadoop集群中的文件上传操作均成功,即成功应对以上故障场景.

图7 自动化编排实验效果
etcd集群中故障效果表现如图7(b)所示.0-10分钟,从节点4发生网络入流量低谷;
10-20分钟,从节点2的磁盘繁忙率提升;
20-25分钟,从节点3的文件系统操作延时增大至200ms;
25-35分钟,leader节点的CPU占用率周期性升至100%.验证任务发现,etcd集群中的10000次写键操作均成功,面临以上故障场景时仍具有可用性.
若使用现有的混沌技术如ChaosBlade、Chaos Mesh进行上述实验等,用户需自行开发实验脚本,脚本中采用定时设置提交对应的故障任务.读写及验证任务需由用户开发后手动于故障实验前后开启,开发成本较高,且操作繁琐.
5.3 动态角色故障实验验证
为验证分布式系统中角色迁移时故障效果是否跟随迁移,设计实验编排如表8,在主节点(Hadoop集群的namenode角色、etcd集群的leader角色)持续注入2分钟CPU繁忙故障,实验开启1分钟后在Hadoop集群通过自定义指令故障中进行namenode主备切换,在etcd集群中通过网络丢包故障模拟etcd leader网络分区,使两集群发生角色迁移,并验证CPU故障效果是否发生转移.实验分别通过本系统及ChaosBlade进行,验证是否根据角色迁移进行故障转移.

表8 动态角色故障实验流程设计
本文实现系统对Hadoop集群的实验效果如图8(a)所示,实验开始时,namenode角色位于的test-hadoop-001机器CPU繁忙率达到100%,一分钟后由于主动切换namenode使得原namenode进入备用状态而test-hadoop-002的namenode角色激活,test-hadoop-001机器的CPU占用率恢复正常,但test-hadoop-002中的CPU占用率提升至100%.
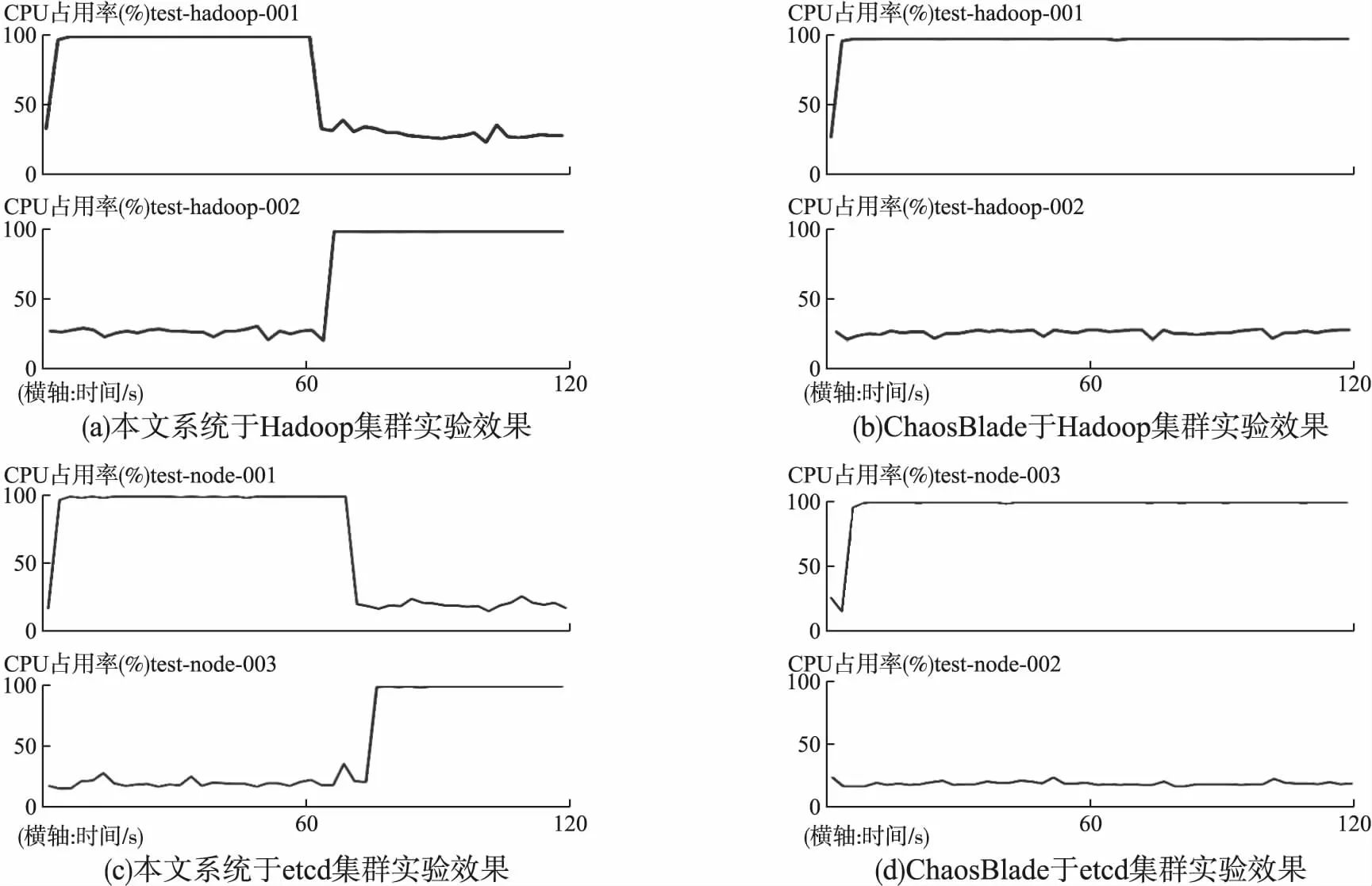
图8 动态角色实验效果
ChaosBlade系统对Hadoop集群的实验效果如图8(b)所示,实验开始时namenode角色位于的test-hadoop-001机器CPU繁忙率达到100%,后因启动HA机制激活test-hadoop-002的备份namenode角色,但namenode角色迁移完成后CPU故障仍持续发生在原节点test-hadoop-001,namenode所在新节点test-hadoop-002未发生CPU繁忙故障效果.
本文实现系统对etcd集群的实验效果如图8(c)所示,实验开始时leader角色位于test-node-001机器,CPU繁忙率达到100%,一分钟后该机器发生网络丢包故障,无法与各从节点通信.从节点发现主节点无响应后,集群leader角色空缺,test-node-001的CPU繁忙故障停止.集群重新选主后由test-node-003机器的etcd进程当选为leader,CPU繁忙故障重新发生在leader所位于的新节点test-node-003.
采用ChaosBlade系统进行的实验效果如图8(d)所示,leader角色位于节点test-node-003,该节点的CPU繁忙达到100%,1分钟后手动在该节点运行丢包故障.多个从节点发现主节点无响应后选取test-node-002机器的etcd进程为leader,但CPU繁忙故障继续发生在原节点test-node-003,新leader所在机器的CPU未出现繁忙效果.
结果表明本文实现的系统能通过感知用户实验系统中的角色迁移,将故障注入到角色迁移后的机器.而已有的工具不提供角色粒度的故障注入,仅能对指定IP机器进行实验.
采用混沌工程技术能通过模拟系统中的故障发生,提前检验系统面临故障时的可用稳定性.当现有的基于混沌工程的故障实验系统自动化程度有限,大多不提供故障实验编排能力,少数支持编排的系统不支持用户进行系统读写、数据验证等操作.且现有系统的故障实验都基于机器或容器粒度进行,无法支持根据分布式系统角色进行动态故障注入.
本文面向分布式系统,提出了一种基于混沌工程的自动化故障实验系统,相比于现有系统,具有以下优势:1)自动化,通过实验编排支持组合故障实验,支持包含故障及读写验证的完整故障实验闭环;
2)灵活度高,实验中可动态地感知到分布式系统的角色迁移,对角色迁移后的机器进行精准的故障实验;
3)开放度高,提供可扩展的实验能力,用户可进行定制化故障或定制化操作开发.
但利用混沌工程技术在分布式系统中进行故障注入是极具风险的操作,用户应评估风险和故障影响面后进行故障实验,笔者推荐对测试系统进行故障实验后再逐步于生产环境验证.此外,本文系统由实验调度层而非目标机器进行故障调度,当系统宕机时可能造成故障无法正确释放,可通过故障模块设置兜底时间等方式降低风险.
猜你喜欢 调度机器节点 基于智慧高速的应急指挥调度系统中国交通信息化(2022年9期)2022-10-28机器狗环球时报(2022-07-13)2022-07-13机器狗环球时报(2022-03-14)2022-03-14基于图连通支配集的子图匹配优化算法计算机应用与软件(2021年10期)2021-10-15基于增益调度与光滑切换的倾转旋翼机最优控制北京航空航天大学学报(2021年6期)2021-07-20结合概率路由的机会网络自私节点检测算法小型微型计算机系统(2020年5期)2020-05-14面向复杂网络的节点相似性度量*计算机与生活(2020年5期)2020-05-13采用贪婪启发式的异构WSNs 部分覆盖算法*火力与指挥控制(2020年1期)2020-03-27基于强化学习的时间触发通信调度方法北京航空航天大学学报(2019年9期)2019-10-26基于动态窗口的虚拟信道通用调度算法计算机测量与控制(2019年6期)2019-06-27推荐访问:混沌 故障 自动化