基于FPGA的量化推理CNN加速系统研究与设计
来源:优秀文章 发布时间:2022-11-18 点击:
何家俊,苏成悦,罗荣芳,施振华,陈堆钰,罗俊丰
(广东工业大学 物理与光电工程学院,广州 510006)
卷积神经网络(CNN)在图像处理分类、目标检测等卷积神经网络应用上有了较大的突破[1]。随着多种深层次卷积神经网络的提出[2],卷积神经网络的网络结构深度和网络层中参数量以及计算量也随之不断提高。将CNN在有限资源的嵌入式设备中计算资源高效得部署成为非常有意义的研究。
许多研究人员在优化神经网络中计算性能[3],提高外部内存访问效率方面提出了很多CNN硬件加速的方案,在实现方面只是考虑到小型网络的加速实现,对于大型网络的实现都缺乏有效的方案[4-6]。且多数网络加速只针对于卷积运算优化,少数网络在加速网络时针对网络全连接的优化[7],全连接的优化对于网络的参数影响[8]也占据着主要的位置。在推理方面提出了很多量化方案[9],采用的量化方案多数为定点数量化,在数据跨度比较大的情况下,采集的数据量不足导致损失率增加,降低算法识别率[10]。常用的动态量化推理INT8是通过人工设置值域范围,不能有效地确定推理量化范围[11]。取值范围过大,会过度采集量化数据,不能有效地抵抗异常参数数据导致量化结果与原函数偏差过大。取值范围过小,会导致数据采集不完整,也不能有效地量化拟合原始数据。
提出了一种结合DBSCAN密度聚类算法[12]的INT8动态量化推理算法,根据网络结构特性实现网络结构优化,设计一个基于多个CNN计算核心的硬件架构,优化加速器的内存访问速率、资源使用以及卷积神经网络计算效果,并以LetNet-5,VGG-16以及Resnet-50算法为例部署至FPGA平台进行验证。
1.1 CNN网络
CNN是由许多运算模块层组成,有卷积运算的功能模块层,激活数值功能模块层,最大值池化数值功能模块层和数据全连接运算功能模块层。CNN会由输入图像数据到第一层功能模块层开始,通过运算获得新的多通道图像特征数据并依次进行下一层功能模块层的操作,每层的卷积层可以用下式表达:

(1)
其中:j表示输入特征值,i表示输出特征值,nin和nout分别表示输入和输出的数量,gi,j应用于第j输入特征值和第i输出特征值的卷积核。激活层是选取特征值中大于零的数值,每层的激活计算层可以用下式表达:
(2)
最大值池化层是选取一个区域内最大的值作为输出特征值可以表示为:

(3)
其中:p是池化层内核的大小。这种非线性向下采样不仅减少了特征数的数量大小和后续计算功能模块的计算量,而且还可以提供一种形式的平移不变性,在不改变数据特性的情况下减少数据量。全连接层可以表示为:
fout=Wfin+b
(4)
其中:W是输入输出变化矩阵,b是偏移参数。在卷积运算后通常会使用激活运算层模块和池化运算模块层去除多余参数降低参数量。经过一次或多次的卷积激活、池化操作,数据以及降低并提取到一定的程度,接下来会使用全连接模块功能层使得数据相互通过权重参数和偏移参数算得结果并将其求和。
上述算法可以看出,卷积神经网络需要大量的乘法和加法运算。通过电路的形式并考虑FPGA可并行可串行的特性设计出算法需要做出相对应的分析,其中卷积运算需要考虑卷积核心的移动方法,以及不同深度神经网络算法中有不同的卷积层数、不同的卷积核数、输入通道数和输出通道数。需要设计出合理的数据缓存区提前将数据保存起来再进行卷积操作。在池化层和激活层不需要用到乘法器和加法器,但是用到比较器,且比较的范围不只是在同一行。
文中选用的3个网络分别LetNet-5网络两个卷积网络以及两个全连接网络的,略深层网络的13层卷积网络和3层全连接网络的VGG-16,以及包含49层全连接网络和1层全连接网络的Resnet-50。
1.2 网络参数与MACC计算量
由图1可以看出LeNet-5无论是参数量还是计算量都是最少的,而其余两个网络,VGG-16和Resnet-50的MACC卷积计算量以及全连接计算量和网络的卷积参数和全连接参数量都不小。图1和图2分别对网络中主要算子的参数分布和网络中主要的计算量分布进行了统计。

图1 各网络的参数总量(M)

图2 各网络参数的MACC计算总量(GFLOPs)
从图1可以看出VGG-16卷积算子权重参数少于Resnet-50的权重参数 ,而在全连接计算算子参数的总量中,VGG-16的算子参数远远多于Resnet-50的全部算子参数的总和,而且LeNet-5和VGG-16网络中全连接参数总量分别是卷积参数总量的12.5倍和8倍。
从图2可以看出每个神经网络的计算量都集中在卷积算子层,LeNet-5、VGG-16、Resnet-50中卷积计算分别为全连接计算的4.77倍,1.25倍和1 935倍,所有在卷积层中计算优化对整个CNN加速系统的影响占比更大。要做到优化好CNN加速系统模块,需要结合优化VGG-16这种需要优化大量全连接计算和ResNet-50这种需要大量卷积计算的特性,将全连接层可以看作是一个特殊的点乘运算,根据不同神经网络的特性设计一个专用的神经网络加速器尤为重要。
1.3 网络训练推理流程分析
目前大部分CNN的研究部署和训练都选择了GPU平台,平台对FP32浮点型数据计算提供了很好的并行运算开发生态有利于做大数据的图像识别训练,但是GPU其高功耗的特性导致其不能成为便携式移动设备的最优选择平台。FPGA同时拥有并行运算能力以及低功耗特性,并且具有灵活的结构为移动设备部署CNN提供了有效的解决方案[13]。CNN前推过程如图3表示。

图3 卷积神经网络前推过程
卷积神经网络需要大量的乘法和加法运算。通过电路的形式并融合FPGA拥有并行和串行的特性设计出算法需要做出相对应的分析,卷积运算需要考虑卷积核心的移动方法,以及考虑到不同的深度神经网络算法不同的卷积层数中有不同的卷积核数、输入通道数和输出通道数。需要设计出合理的数据缓存区需要提前将数据保存起来再进行卷积操作。池化层和激活层由比较器组成为主,且比较的范围不只是在同一行,如2×2的池化核需要第一行的图像数据与第二行的图像数据作对比,在电路设计上需要设计好缓冲区,保存第一行数据并且通过第二行数据输入后作对比。全连接层则只需要在其他计算完成后得到的数据输出的时候乘上权重和加上偏移值。训练过程如图4表示。

图4 深度网络训练流程图
深度神经网络训练需要构建训练网络,预设训练次数(EPOCH),打乱数据集,划分训练集和验证集。接下来设置每次训练所抓取的数据样本数量(BATCH SIZE)和学习率(LR),这两个参数影响深度学习的速度和识别率。获取训练集中图像数据,并使用归一化处理。将数据传入到构建好的训练网络,获得识别结果。将结果通过与标识好的结果做一个损失函数计算,再更新网络中的参数。重复第三步当经过EPOCH次训练后得到训练参数和识别率。
基于深度卷积神经网络的训练数据量庞大而且只需要训练一次的原因,使用可以高速且具有丰富深度学习开发方案的GPU平台成为首选。训练不需要考虑功耗问题,通过GPU训练出来的模型参数做处理后,部署到基于FPGA平台的CNN加速器当中。
1.4 网络优化分析
CNN加速研究中,常用的方法是通过压缩神经网络模型的方法达到缩小模型中数据体积大小和降低硬件的资源使用的效果,使得算法运算速率增加以及运行算法设备的功耗减少[14]。
通过将数据运算位数删减降低数据精度,有效地提高运算速度和降低功耗。使用在大规模的图像分类中,最为先进的CNN模型具有较深的网络层数和大量的神经网络权重参数和偏移参数。大量参数只能存储在外部存储器当中,运行算法时需要从外部参数读取并使用计算,加速性能需要和存储器读写的速度做匹配,在加速性能远大于储存器读写速率的情况下,存储器的读写带宽也就是储存器每次读写数据量的大小以及读写速率成为了CNN加速的性能瓶颈[15]。
2.1 网络量化
在FP32类型的数据下深度神经网络的参数都会集中在一个值域区间[16],使得FP32大部分的数据段都是处于空闲状态,这时可以通过有效截取数据段来使得参数数据压缩,那么就可以得到一个量化的参数模型,如图5是LeNet-5训练后的参数分布数据图。

图5 LeNet-5参数数据分布
从图5(a)和图5(b)可以得到神经网络的权重参数主要分布和偏移量参数主要分布在一定范围,我们可以合理地设置区间为这个综合范围的最大值和最小值映射到INT8类型数据的最大值和最小值,其中相差间隔很小的数据会合并映射到一个数值。
在FP32转向INT8的过程中需要去除小数点后的数,需要在映射到8位数据后进行舍入的操作。当存在少量远大于或小于大量数值参数的异常参数,则异常参数会影响整个量化过程,大量的正常参数才是在图像识别运算中起着重要的权重作用,合并到同一数值当中,减少了两个区域甚至多个区域中数据的可比性。合理选择量化的值域显得尤其重要。
2.1.1 量化FP32至INT8实现的计算公式
从输入图像数据转换成量化图像数据公式如下:

(5)
其中:Xf为输入图片特征数,Xq为Xf量化后的图片特征数,Sx为图片特征数量化放缩因子,Zx为图片特征数量化偏移值。量化放缩因子是通过输入数据的值域范围和需要量化的范围做一个比例计算,公式如下:
(6)
式(5)Zx是通过放缩因子,量化结果以及原数据做一个偏移计算获取,公式如下:
(7)
同理权重的参数量化如同输入图像特征数的量化,给出的3个公式如下所示:
(8)
(9)
(10)
其中:Wf为输入权重参数,Wq为Wf量化后的权重参数,Sw为权重参数量化放缩因子,Zw为权重参数量量化偏移值。量化计算使用在深度网络训练后得到参数进行量化推理调整。
2.1.2 量化中舍入公式:
量化中的舍入公式使用了随机离散舍入函数方法[17],我们可以定义为:
(11)
在CNN量化中,使用四舍五入的round方法会产生一定的误差,在大量的卷积运算会使得这种误差放大,导致图像识别的准确率降低。随机离散舍入函数方法中,采用随机因子,使得函数期望为x。有助于在量化过程中舍入后减少误差,减少算法损失率。
2.1.3 DBSCAN聚类算法
DBSCAN是基于密度的分类算法。算法通过设置中心点直径范围,和中心直径范围内数据量遍历出数据中心点的位置。将与中心相连的点位数据收集到同一数据集中,生成多个数据集。通过删除含有数据少的中心数据团,获取存在大量数据的中心数据团,从而确定量化参数大致分布区域,截取数据的值域区间,提高量化后与量化前的相似度。如图6是LeNet-5的两个卷积层量化前后对比图。

图6 卷积参数DBSCAN聚类算法处理数据图
从图6(a)以及图6(c)可以看出在训练后的卷积参数会出现异常数据。异常数据会导致在设置INT8推理的阈值过大,大部分的参数分布在0.1与0.2之间,如图4(a)出现了最大值9,若设置9为量化最大值则会出现0.2到9之间存在大部分不占据参数的空间稀释原本参数分布区域的精度参数从而导致量化后结果与原函数的相似度降低。
从图6(b)以及图6(d)可以看出经过DBSCAN聚类算法处理后相对于处理前的数据减少了很多异常数据,显示聚集密度大得数据集,可以直接截取数据集的最大值和最小值通过公式(6)计算出量化放缩因子,极大地去除异常数据,可以通过算法处理使得数据参数有效得并量化贴合,可以明显有效得去除了数据毛刺,有助于数据量化。
2.2 全连接优化计算公式
LeNet-5和VGG-16等深度神经网络中会存在多个全连接,全连接可以看作是两个矩阵的相乘,将第一层全连接的权重参数等价于W,第一层偏移量等价于B得到公式如下:
(12)
第一层全连接层的结果等价于H可以得到:
H=[h1h2…hm]T=W*X+B
(13)
其中:n为全连接输入数,m为输出通道数,h为全连接结果,x为输入特征值,w为权重参数,b为偏移参数。同理可将第二层全连接的权重参数等价于U,第二层全连接的偏移参数等价于D:
(14)
得到第二层全连接最后结果FC,公式如下:
FC=[fc1fc2…fck]T=U*H+D
(15)
其中:k为输出通道数,fc为全连接结果。若用式(13)的全连接带入到式(15)中的H中,可以将(13)、(15)两式融合成一式:
FC=U*(W*X+B)+D
(16)
将(16)中括号拆开,使第二层全连接权重参数与第一层全连接权重参数结合成为总的全连接权重参数,使第二层全连接参数结合第一层全连接偏移参数再加上第二层全连接偏移参数得到总的全连接的偏移参数,新成立的全连接权重矩阵和偏移矩阵分别是:
Wn=U*W
(17)
Bn=U*B+D
(18)
融合后全连接可以简单描述为:
F=Wn*X+Bn
(19)
选用LeNet-5和VGG-16全连接融合效果对比如表1所示。

表1 全连接层融合对比效果
可以看出LeNet-5 和 VGG-16在全连接融合后MACC计算总量的压缩率分别为52.9%和3.3%,全连接参数总量的压缩率分别为52.6%和3.3%。
拥有少量全连接参数和计算量的LeNet-5网络拥有很好的压缩效果。针对VGG-16全连接计算量占据大量参数和计算的特性,VGG-16在向前推算的参数量和计算量在全连接层融合压缩起到了明显的效果。
使用GPU平台进行Fashion MNIST(FM)和CIFAR-10(CR)的数据集的训练并获取各网络模型参数,将参数进行量化数据分析和融合全连接参数等操作得到最后使用到FPGA平台上CNN加速系统中。
基于以上量化理论,CNN加速系统需要考虑CNN网络在卷积运算的运算速率。CNN卷积网络数据在并行运算中表现较好,在设计加速电路中需要运用并行的电路设计。
通过对网络的分析,系统同时需要多个模块组合并按顺序执行计算。运用多个计算核心的方法组合加速系统,通过控制系统控制执行顺序可以灵活地调用硬件资源完成CNN深度加速。FPGA设计的CNN推理加速器模块设计如图7所示。
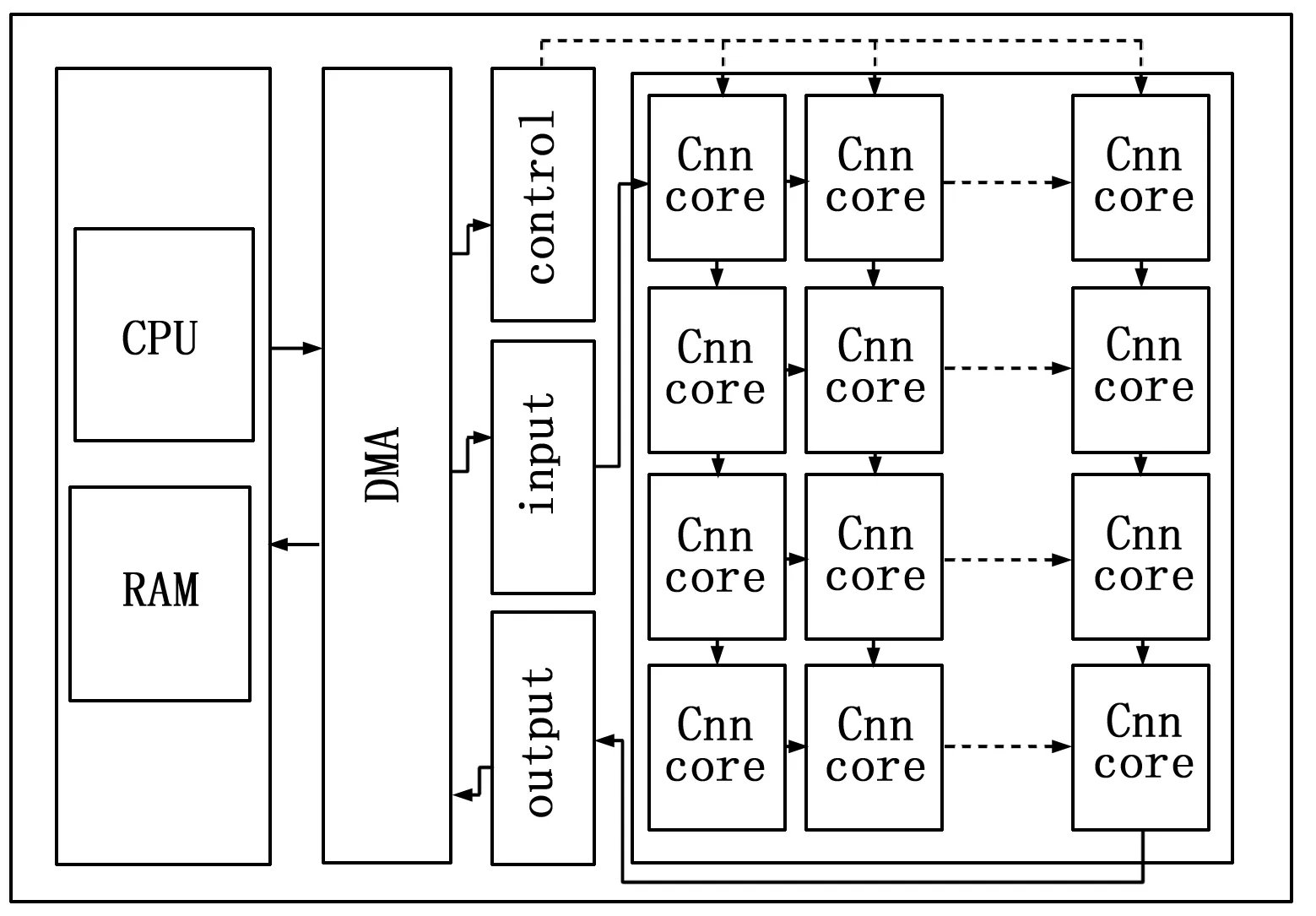
图7 深度神经网络推理加速器
加速器主要包含了片上系统控制中心模块、内存缓存模块、深度神经网络计算单元核心模块、单元核心控制仲裁模块和输入输出模块。使用C++代码实现深度神经网络的结构,通过系统控制中心模块调度内存缓存模块,将权重数据和偏移数据与图像数据以及神经网络单元核心的参数通过DMA传输进入深度神经网络计算模块中进行前推计算,最后输出数据返回到系统控制中心,完成整个深度神经网络加速过程。
3.1 内存缓存与数据传输
片上内存主要保存了当前神经网络的权重数据和偏移数据,数据传入神经网络模块传输设计如图8所示。

图8 神经网络模块传输图
考虑到卷积操作多数是以3×3的卷积核结构对特征图进行滑动操作,固神经网络模块数据首先读取数据的前三行,新的数据行替换旧的数据行。第一次卷积需要等待三次数据的读取,后续数据可以直接替换旧数据进行卷积,当此次卷积实现了输入特征数据面积数且没有新的数据输入时完成卷积并输出空闲状态。
上述电路实现卷积的运算读取内存中数据[18],每次时钟只需要读取一个数据量即可,并使用了流水线设计实现了加法树和乘法的功能优化了内存读写效率和在很短的等待时间内执行多条运行命令,提高了卷积计算的速度。
3.2 深度神经网络计算单元核心模块
计算单元核心模块是加速器的主要模块,其中有量化模块(Quantization)、控制模块(CORE CONTORL)、深度神经网络算子等计算模块,其结构如图9所示。

图9 神经网络计算单元核心模块
量化模块(Quantization)中随机数使用的是LFSR随机数产生电路生成随机因子作用于离散舍入计算得到量化放缩因子。模块输入数据后经过量化处理,将FP32数据乘以量化放缩因子并加上量化偏移值,得到最后的INT8数据,在卷积和全连接的计算中使用INT8计算,不需要使用浮点型的运算电路,减少加速系统对DSP使用的同时减少运算数据的位数达到电路系统在运行时降低功耗降低计算量。
控制模块(CORE CONTORL)通过代码控制图像数据输入到指定算子开始执行运算,并通过指定算子运行结束后输出结果,比如只需要数据从卷积计算到全连接,则控制使能卷积并输入数据,控制选择器将全连接的数据和计算完成标志输出结果(Result)。深度神经网络算子模块中的算子由卷积到全连接串联而成的计算模块,顺序是由卷积到全连接的计算顺序,因为每个模块之间都是通过先入先出队列模块FIFO(First Input First Output)做中间层衔接,每个模块之间的输入数据和输出数据都是规定为一个有利于每个模块间交叉衔接。
深度神经网络算子模块中的算子由卷积到全连接串联而成的计算模块,顺序是由卷积到全连接的计算顺序,因为每个模块之间都是通过先入先出队列模块FIFO(First Input First Output)做中间层衔接,每个模块之间的输入数据和输出数据都是规定为一个有利于每个模块间交叉衔接。卷积计算模块如图10表示。

图10 卷积模块设计
卷积计算模块的设计是由加法树和9个乘法器组成,由数据输入完成后将输入数据用乘法器相乘得到第一层数据,再通过加法器将数据相加得到第二层数据,进而再进行三次相加和两次数据平移,最后结果由最后两个数据相加得到。
激活层是当卷积数据输出时通过比较器与8位数据127值作对比,若比127大则可以认为在算法中大于0输出原值,若小于127则在算法中认为小于0输出数据0。
全连接层则是通过一个乘法器和一个加法器,实现单个数据通过FIFO输入后进行全连接的运算后通过FIFO输出。
3.3 单元核心控制仲裁多核加速
控制模块里面包含了多个单元核心仲裁器,每个仲裁核心会将处理数据优先级通过优先分配算法分配给空闲的神经网络运算单元核心进行卷积神经网络的运算,结构如图11所示。

图11 仲裁模块结构
当数据传入时,控制模块会查看当前空闲的神经网络单元核心算子,若当前仲裁卷积神经网络算子都处于繁忙阶段,则会将消息传输到下一个仲裁中,仲裁都处于繁忙阶段的情况下,则当前计算直接跳过,当一个神经网络算子完成当此计算,会将数据发到下一个神经网络算子,且让仲裁控制器控制当前数据是否要继续计算或再传送到下一个节点。通过将数据同时发送到多个子仲裁模块,实现数据并行运算。卷积运算中需要运算多个输出通道,可以按FPGA平台性能合理执行单次最大并行运算核心或通过自定义计时器和有限状态机FSM(Finite State Machine)控制数据的再传输和再计算实现单个计算核心组的多次使用。
利用GPU平台以及Pytorch软件框架可以有效地对深度卷积神经网络模型进行大规模的数据集训练,其中数据集使用了Fashion MNIST(FM)和CIFAR-10(CR)为数据集 。
因为要计算在量化深度网络结构在网络计算量和网络参数的压缩率与识别效果,需要在平台上记录不同网络、不同数据集、不同前推运算的条件下记录相关参数。通过计算量化前LeNet-5、VGG-16和ResNet-50的网络大小与量化后网络的面积计算压缩率,压缩效果和量化网络对数据集的识别效果见表2和表3。

表2 量化面积

表3 量化精度
可以看到LeNet-5的网络大小在量化前是1.66 M,量化网络后大小变成了0.41,压缩率为24.6%,因为LetNet-5网络有两层卷积层数和两层全连接层,通过量化计算参数数据,压缩卷积层中占大量计算的数据位数,由原来的FP32变成INT8在数据上减少了75%的位数据,在卷积层方面的压缩效果明显。通过融合全连接层,LetNet-5本来由原来的两层全连接网络,融合成一层全连接网络,在计算全连接上不仅在量化中减少了大量的数据,在全连接上减少了实际运算次数,达到明显的压缩效果。
从表中得知VGG-16网络的压缩效果是最明显的。由于VGG-16的全连接层的数据量大部分占据在全连接层,全连接层的层数是3个网络中层数最多的,在全精度的情况下VGG-16的网络大小是527 M而其中全连接的占比可以达到89%即469.3 M,全连接融合有效的将中间的全连接层数运算过程融合在了一起,将全连接的大小压缩到了15.55 M。因为全连接层的数量对准确率有一定的影响,但是全连接层的融合是经过训练后合并而成的,不会影响训练后用于前推的神经网络算法。
表中ResNet-50的压缩效果与LeNet-5的压缩效果相似。在ResNet-50中不只是在计算上,在层数上都是以卷积计算占据主要部分,并且全连接层只有一层,融合全连接的方法在ResNet-50中不起作用。ResNet-50中占据主要压缩优化效果的是由量化参数起作用,可以将原来98.1 M的网络大小压缩到24 M,优化方案适应于ResNet-50。
从表3可以看到量化后的网络在在识别准确率上都维持在1%以下的损失率。表明了在通过有效去除异常数据量化拟合和融合全连接层的方法可以有效地降低深度神经网络的网络大小而不会有过大的损失率,量化推理方案是有助于降低深度神经网络的复杂性并有助于降低电路设计相关深度神经网络算法电路的复杂性。
通过训练后的网络模型,在GPU平台下运行FP32全精度的识别Fashion MNIST(FM)和CIFAR-10(CR)的验证集测试并记录准确率。获取GPU平台下,网络训练模型中的参数,使用C++语言搭建前推深度计算网络模型,输入验证集。将编译好的bitstream文件导入到FPGA开发板中,可以得到加速器利用资源情况见表4。
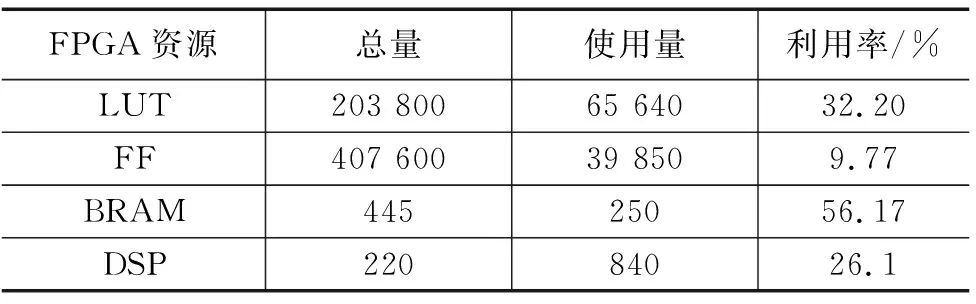
表4 加速器资源利用
本设计因为使用了多个深度神经网络计算单元核心模块,在一定程度上使用更多通道的并行运算上在,并且在经过推理量化后的计算不需要使用大量的DSP功能进行计算,本设计的CNN加速系统在计算性能上相比于其他同为8位计算的FPGA实现由较大的提升,其中峰值154.95 GOPS,性能提高了2倍,详细对比见表5。

表5 加速器对比效果
为了提高硬件移动设备上实现卷积深度神经网络(CNN)的运行性能和降低算法运算给设备带来的功耗问题,通过对CNN的网络结构以及计算流程特性,设计出使用DBSCAN聚类算法实现量化值域截取有效得截取INT8推理算法的阈值,改变阈值选取方法以及全连接融合减少具有大量全连接层的深度网络数据量,并针对FPGA硬件和深度神经网络运算特性,设计出多个深度神经网络计算单元核心模块加速器。在Fashion MNIST(FM)和CIFAR-10(CR)的验证集上进行了性能测试。实验结果表示,在量化后的神经网络中,损失率在1%以内,LeNet-5、VGG-16和ResNet-50压缩分别为原来的24.6%,13.3%和24.4%,设计的加速器最高性能可以达到154.95GOPS,提高了2倍。
猜你喜欢 算子卷积神经网络 基于全卷积神经网络的猪背膘厚快速准确测定农业工程学报(2022年12期)2022-09-09基于神经网络的船舶电力系统故障诊断方法舰船科学技术(2022年11期)2022-07-15基于人工智能LSTM循环神经网络的学习成绩预测中国教育信息化·高教职教(2022年4期)2022-05-13基于图像处理与卷积神经网络的零件识别计算技术与自动化(2022年1期)2022-04-15MIV-PSO-BP神经网络用户热负荷预测煤气与热力(2022年2期)2022-03-09Domestication or Foreignization:A Cultural Choice校园英语·上旬(2020年1期)2020-05-09基于深度卷积网络与空洞卷积融合的人群计数上海师范大学学报·自然科学版(2019年5期)2019-12-13三次样条和二次删除相辅助的WASD神经网络与日本人口预测软件(2017年6期)2017-09-23QK空间上的叠加算子卷宗(2017年16期)2017-08-30卷积神经网络概述中国新通信(2017年9期)2017-05-27推荐访问:量化 推理 加速